


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0x00 项目地址
https://github.com/cyber-word/Fuckcms
0x01 需求导向
在日常的渗透测试中,遇到什么网站最高兴呢?嘿嘿,想必是各种所谓的建站公司开发的网站,这种网站往往是基于现有框架和cms开发的,下面我们就基于这个需求,开发一种基于Web爬虫技术的web服务器信息探测工具,以获取获取域名相应服务器的标题、服务器名、服务器语言、服务器版本以及服务器的建站程序或框架等基本信息。新手之作,大佬轻喷。
0x02 设计过程
一、基本原理:
(1)HTTP简介
HTTP是一种超文本传输协议,是基于TCP协议之上的一种请求-响应请求协议,浏览器访问某个网站时发送的HTTP请求-响应,当浏览器希望访问某个网站时,浏览器和网站服务器之间先建立TCP连接,且服务器总是使用80端口和加密端口443,然后浏览器向服务器发送一个HTTP请求,服务器收到之后,返回一个HTTP响应,响应中包含了HTML的网页内容,浏览器解析HTML后就给用户显示网页。
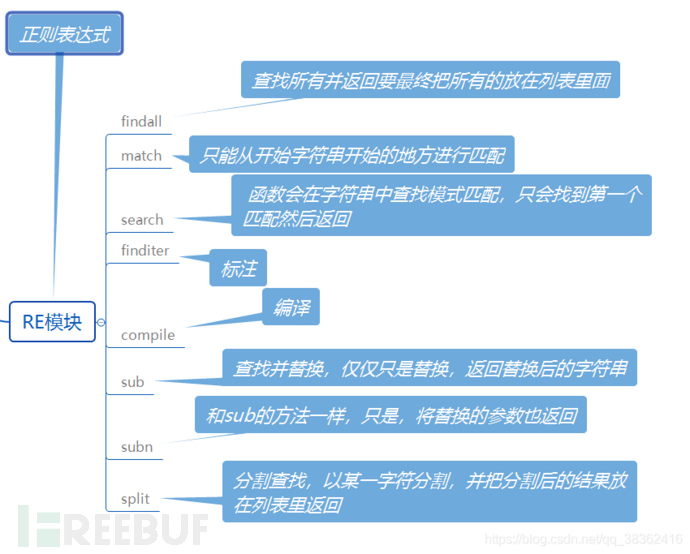
(2)python正则模块
Python中的re模块提供了一个正则表达式引擎接口,它允许我们将正则表达式编译成模式对象,然后通过这些模式对象执行模式匹配搜索和字符串分割、子串替换等操作。re模块为这些操作分别提供了模块级别的函数以及相关类的封装。re模块的主要函数及功能如下图所示:
(3)网站搭建语言及常见的网站服务器以及建站框架
| 建站框架 | 搭建语言 | 网站服务器 |
|---|---|---|
| javabean | JAVA | Servlet |
| Struts 2 | JAVA | Weblogic、Servlet... |
| Spring | JAVA | Servlet、Weblogic |
| Thinkphp | PHP | IIS、Tomcat、nginx、Apache... |
| discuz | PHP | IIS、Tomcat、nginx、Apache... |
| ... | ... | ... |
(4)web服务器识别方法:
常见的web服务器识别的方法无非就以下几种:
2.通过x-powered-by识别
3.通过访问特定具有一定稳定性的文件,判断该文件是否存在来确定,而存在的依据就是是返回的html中是否能匹配到特殊内容,以及该页面的MD5值
那么基于这个原理的识别方法可分为两步:首先第一步发送get请求,利用头部域指纹准确识别web服务器类型;然后,根据web服务器类型构造特定的http请求,利用状态码定位指纹可准确识别web服务器版本。
二、项目模块代码
我们开始编写获取服务器的项目工程,我们可以在pycharm上新建一个项目工程WebScan,其下建立4个文件,
fuckcms.py作为主文件来运行,GetCms.py作为功能文件,GetCmsFromTide.py,GetCmsFromCms.py作为从不同指纹库中识别建站程序或框架的功能文件。
fuckcms.py
``
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# author: jeremy
# github: https://github.com/cyber-word
# 公众号: 剑南道极客
import argparse
import GetCms
import sys
import threading
from threading import Thread # 引入多线程
from queue import Queue # 引入队列机制
import time
import banner
# Check py version
def CheckVersion():
PythonVersion = sys.version.split()[0]
if PythonVersion <= "3":
exit('Need Python3.x')
CheckVersion()
print(banner.banner())
# Get argparse
parser = argparse.ArgumentParser()
parser.description = 'please enter -u (required) -f (optional) -t (optional)'
parser.add_argument("-u", "--url", help="this is a url to be scanned", dest="url", type=str, default="no input url")
parser.add_argument("-f", "--file", help="this is a url list to be scanned", dest="path", type=str, default="no input "
"file")
parser.add_argument("-t", "--thread", help="this is the numeber of threads to be used", dest="ThreadNum", type=int,
default=10)
parser.add_argument("-d", "--dbs", help="this is the finger dbs that to be used", dest="FingerDbs", type=str,
default="all")
args = parser.parse_args()
print("\033[35m""*"*50+"\033[0m")
print("\033[33m""url: "+args.url+"\033[0m")
print("\033[33m""file path: "+args.path+"\033[0m")
print("\033[33m""scanThreadNum: "+str(args.ThreadNum)+"\033[0m")
print("\033[33m""Finger dbs: "+args.FingerDbs+"\033[0m")
print("\033[35m""*"*50+"\033[0m")
if args.path == "no input file":
if args.url != "no input url":
if args.FingerDbs == "all":
queue = Queue()
queue.put(args.url)
for i in range(1, args.ThreadNum):
thread = Thread(target=GetCms.GetWebInfo, args=(queue,args.FingerDbs))
thread.start()
queue.join()
else:
print("请重新输入")
else:
queue = Queue()
txt_path = args.path # 要扫描的网站存放路径
f = open(txt_path)
data_lists = f.readlines() # 读出的是str类型
start_time = time.time()
for data in data_lists:
data1 = data.strip('\n') # 去掉开头和结尾的换行符
queue.put(data1) # 将url读取到queue中
# getinfo.GetWebInfo(data1)
for i in range(1, args.ThreadNum):
thread = Thread(target=GetCms.GetWebInfo, args=(queue,args.FingerDbs))
thread.start()
queue.join()
print("\033[32m""扫描完毕共花费了:" + str(time.time() - start_time) + "秒""\033[0m")
我们主要用到了requests,user_agent,argparse,GetCms,sys共五个库,各个库的作用如下表所示:
| 包名 | 功能 |
|---|---|
| queue | 提供多线程间的队列通信机制 |
| argparse | 实现用户交互,通过命令行中输入形如”-u url”的形式来传递参数 |
| GetCms | 自定义文件,用来实现对响应包中特定内容的读取 |
| time | 确定程序运行时间,提高用户可阅读性 |
| sys | 确定用户的python版本 |
| threading | 提供多线程机制 |
GetCms.py(实现信息收集)
``
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import requests
import user_agent
from bs4 import BeautifulSoup
import lxml
import urllib
from urllib.parse import urlparse
import re
import sqlite3
import time
# 创建一个WebInfo类用来存储扫描到的信息
class WebInfo:
def __init__(self, domain, title, http_server, language, set_Cookie, X_Powered_By, cms, body, header):
self.header = header
self.body = body
self.set_Cookie = set_Cookie
self.X_Powered_By = X_Powered_By
self.language = language
self.http_server = http_server
self.domain = domain
self.title = title
self.cms = cms
def print(self):
print("\033[32m""domain:" + self.domain+"\033[0m")
print("\033[33m""title:" + self.title + "\033[0m")
print("\033[34m""http_server:" + self.http_server + "\033[0m")
print("\033[35m""language:" + self.language + "\033[0m")
print("\033[36m""X-Powered-By:" + self.X_Powered_By + "\033[0m")
print("-"*50)
# print(self.__dict__) 原本用作遍历输出所有属性
# Match_rule是要多线程运行的函数,对于同一个url,需要多个不同的key执行相同的Match_rule操作
global cms1
cms1 = "未识别出cms"
def Match_rule(key, title, header, body):
re_header = re.compile(r'header="(.*)"')
re_body = re.compile(r'body="(.*)"')
re_title = re.compile(r'title="(.*)"')
global cms1
if "title=" in key:
if re.findall(re_title, key)[0].lower() in title.lower():
cms1 = re.findall(re_title, key)[0]
if "header=" in key:
if re.findall(re_header, key)[0].lower() in header.lower():
cms1 = re.findall(re_header, key)[0]
if "body=" in key:
if re.findall(re_body, key)[0].lower() in body.lower():
cms1 = re.findall(re_body, key)[0]
if cms1 !="未识别出cms":
return cms1
def Get_rule(title, header, body, cms):
start_time = time.time()
conn = sqlite3.connect('cms_finger.db')
cursor = conn.cursor()
cursor.execute("SELECT keys FROM `tide` ")
global cms1
for i in range(1, 1001):
result = cursor.fetchone()
if cms1 == "未识别出cms":
Match_rule(result[0], title, header, body)
if cms1 != "未识别出cms":
str1 = "cms识别结果:"+Match_rule(result[0], title, header, body)
print("\033[33m"+str1+"\033[0m")
cms1 = "未识别出cms"
break
print("\033[32m""运行了"+str(time.time() - start_time)+"秒""\033[0m")
def GetWebInfo(url):
headers = {
'User-Agent': user_agent.generate_user_agent()
}
try:
r = requests.get(url=url, headers=headers, timeout=5)
print("-"*50)
print(url)
r.encoding = 'unicode'
# print(r.text)
header = re.compile(r'header="(.*)"')
headers = str(r.headers)
bodys = r.text
body = re.compile(r'body="(.*)"')
try:
title = BeautifulSoup(bodys, 'lxml').title.text.strip()
except Exception as error:
title = "暂未识别出title"
try:
Cookie = r.headers['Coolie']
except Exception as error:
Cookie = "暂未识别,可能是当前页面没有cookie"
try:
Server = r.headers['Server']
except Exception as error:
Server = "暂未识别出当前页面服务器"
domain = urlparse(url).netloc
domain = domain.replace('www.', '')
ThisWebInfo = WebInfo(domain, title, Server, "暂未识别当前页面语言", Cookie,
"未识别出x-powered-by", "未识别出cms,但可能x-powered-by中有", bodys, headers)
try:
Get_rule(title, headers, bodys, "cms")
except Exception as error:
pass
# 识别网站语言
if 'X-Powered-By' in r.headers:
ThisWebInfo.X_Powered_By = r.headers['X-Powered-By']
if 'set-Cookie' in r.headers:
ThisWebInfo.set_Cookie = r.headers['Set-Cookie']
if 'Cookie' in r.headers:
ThisWebInfo.set_Cookie = r.headers['Set-Cookie']
if "PHPSSIONID" in ThisWebInfo.set_Cookie:
ThisWebInfo.language = "PHP"
if "JSESSIONID" in ThisWebInfo.set_Cookie:
ThisWebInfo.language = "JAVA"
if "ASP.NET" in ThisWebInfo.X_Powered_By or "ASPSESS" in ThisWebInfo.set_Cookie or "ASP.NET" in ThisWebInfo.set_Cookie:
ThisWebInfo.language = "ASP.NET"
if "JBoss" in ThisWebInfo.X_Powered_By:
ThisWebInfo.language = "JAVA"
if "Servlet" in ThisWebInfo.X_Powered_By:
ThisWebInfo.language = "JAVA"
if "Next.js" in ThisWebInfo.X_Powered_By:
ThisWebInfo.language = "NODEJS"
if "Express" in ThisWebInfo.X_Powered_By:
ThisWebInfo.language = "NODEJS"
if "PHP" in ThisWebInfo.X_Powered_By:
ThisWebInfo.language = "PHP"
if "JSF" in ThisWebInfo.X_Powered_By:
ThisWebInfo.language = "JAVA"
if "WP" in ThisWebInfo.X_Powered_By:
ThisWebInfo.language = "PHP"
if "enduro" in ThisWebInfo.X_Powered_By:
ThisWebInfo.language = "NODEJS"
ThisWebInfo.print()
except Exception as error:
print("连接不到该网站")
在这个文件中,我们对应用系统特定字段信息,页面关键字、特殊链接或者文件和路径、框架、插件、服务器版本、编写语言类型等这些特征信息进行收集,共用到了requests,user_agent,BeautifulSoup,lxml,urllib,urlparse,time,re,sqlite3共九个库,它们的作用如下:
| 包名 | 功能 |
|---|---|
| user_agent | 实现请求头中的user_agent的随机,保证爬虫能够正常爬取到数据 |
| BeautifulSoup | 实现便捷地通过解析文档提供需要抓取的数据 |
| lxml | 实现HTML和XML的解析,支持XPath解析方式,而且解析效率非常高 |
| urllib | 操作网页 URL,并对网页的内容进行抓取处理。 |
| urlparse | 对url进行解析,获取到url中我们想要提取的部分 |
| requests | 实现网络爬虫的请求与接受数据包,并且获取相响应包中的内容 |
| re | 通过正则表达式提取目标数据 |
| sqlite3 | 导入数据库文件 |
| time | 确定扫描所需时间,提高用户可阅读性 |
同时我们建立了一个WebInfo对象,用来存储搜集到的网站信息:
``
class WebInfo:
def __init__(self, domain, title, http_server, language, set_Cookie, X_Powered_By):
self.set_Cookie = set_Cookie
self.X_Powered_By = X_Powered_By
self.language = language
self.http_server = http_server
self.domain = domain
self.title = title
def print(self):
....
对网站使用语言,框架信息,服务器信息的识别主要通过与预先建立好的信息进行比对而得出结果。
GetCmsFromTide.py
``
import re
import sqlite3
import time
cms1 = "未识别出cms"
def Match_rule_for_tide(key, title, header, body):
re_header = re.compile(r'header="(.*)"')
re_body = re.compile(r'body="(.*)"')
re_title = re.compile(r'title="(.*)"')
global cms1
if "title=" in key:
if re.findall(re_title, key)[0].lower() in title.lower():
cms1 = re.findall(re_title, key)[0]
if "header=" in key:
if re.findall(re_header, key)[0].lower() in header.lower():
cms1 = re.findall(re_header, key)[0]
if "body=" in key:
if re.findall(re_body, key)[0].lower() in body.lower():
cms1 = re.findall(re_body, key)[0]
if cms1 !="未识别出cms":
return cms1
def Get_rule_from_tide(title, header, body):
start_time = time.time()
conn = sqlite3.connect('cms_finger.db')
cursor = conn.cursor()
cursor.execute("SELECT keys FROM `tide` ")
global cms1
for i in range(1, 1001):
result = cursor.fetchone()
if cms1 == "未识别出cms":
Match_rule_for_tide(result[0], title, header, body)
if cms1 != "未识别出cms":
str1 = "cms识别结果(指纹库:tide):"+Match_rule_for_tide(result[0], title, header, body)
print("\033[33m"+str1+"\033[0m")
cms1 = "未识别出cms"
break
print("\033[32m""运行了"+str(time.time() - start_time)+"秒""\033[0m")
在这个文件中,我们通过python正则库,将目标网站的特定信息与指纹库进行对比碰撞,如果碰撞成功,则认为CMS识别任务完成,识别流程如下:

GetCmsFromCms.py
``
import re
import sqlite3
import time
import hashlib
import requests
import user_agent
cms2 = "未识别出cms"
def GetMd5(content):
md5 = hashlib.md5()
md5.update(content)
return md5.hexdigest()
def Match_rule_for_cms(url, cms_name, path, match_pattern, options):
global cms2
headers = {
'User-Agent': user_agent.generate_user_agent()
}
res = requests.get(url=url + path, headers=headers, timeout=5)
res.encoding = "utf-8"
contents = res.content
body = res.text
if res.status_code == 200:
if options == "md5":
if match_pattern == GetMd5(contents):
cms2 = cms_name
print(url+path)
if cms2 != "未识别出cms":
return cms2
if options == "keyword":
if match_pattern in body:
print("响应码:"+str(res.status_code))
cms2 = cms_name
# print("keyword" + cms2)
print(url+path)
if cms2 != "未识别出cms":
return cms2
if cms2 != "未识别出cms":
return cms2
def Get_rule_from_cms(url):
# body : r.text
# contents : r.content
start_time = time.time()
conn = sqlite3.connect('cms_finger.db')
cursor = conn.cursor()
cursor.execute("SELECT cms_name,path,match_pattern,options FROM `cms` ")
global cms2
for i in range(1, 1001):
result = cursor.fetchone()
# result =[cms_name, path, match_pattern, options]
if cms2 == "未识别出cms":
Match_rule_for_cms(url, result[0], result[1], result[2], result[3])
if cms2 != "未识别出cms":
str1 = "cms识别结果(指纹库:cms):" + cms2
print("\033[33m" + str1 + "\033[0m")
cms2 = "未识别出cms"
break
在这个文件中,我们主要采用了基于特殊文件的关键词搜索以及MD5比对的方法来识别框架,其原理是基于许多框架或者建站程序固有的文件本身不易被修改,以及MD5算法的不可逆性,因此可以通过这些未修改文件的签名属性以及文本属性来实现框架的识别。该方法识别流程图如下:

0x03 结果分析
1.对单个url进行识别
命令:python webscan.py -u 指定的url
实验:
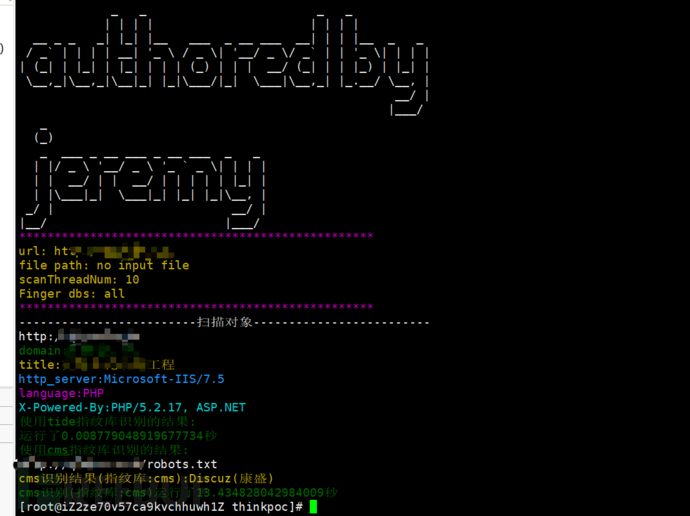
实验结果:
| 属性 | 结果 |
|---|---|
| x-powered-by | PHP/5.2.17,ASP.NET |
| language | PHP |
| http_server | Microsoft-IIS/7.5 |
| domain | qlwhdm.com |
| title | 齐鲁文化动漫工程 |
| set-Cookie | 当前页面未设置Cookie |
某网站扫描器的扫描结果:

可以看出扫描的结果较为准确,且相较于该网站扫描器,实现了cms的识别。
2.对多个url进行识别:
命令:python webscan.py -f 存放多个url的文本文件的路径
实验结果:

0X04 总结
不接触开发,不懂开发难,之前觉得写一个扫描器很容易,自己亲自写了以后才发现,从实现最基本的需求,到满足进一步的速度要求,再到输出的结果的可阅读性,以及交互友好性,不是想想中的那么简单,(仅针对本人安全新手而言,大佬不在此列),总的来说,基本上实现了获取获取域名相应服务器的标题、服务器名、服务器语言、服务器版本等基本信息。但是还有着需要改进的一些问题,如对更多的开源web指纹库进行分析,提高cms框架识别的准确率;尝试加入漏洞检测,poc利用等功能。
再放一次GitHub地址 https://github.com/cyber-word/Fuckcms
如需授权、对文章有疑问或需删除稿件,请联系 FreeBuf 客服小蜜蜂(微信:freebee1024)






- 1 文章数
- 0 关注者