


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

 天下第一
天下第一- 关注
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
在说编码之前我先简单说下伪协议。
伪协议是什么?
伪协议不同于因特网上所有广泛使用的如http://,https://,ftp://,在URL中使用,用于执行特定的功能
这里我以以下两种伪协议为例:
Data伪协议:
data:text/html;base64,PHNjcmlwdD5hbGVydCgxKTs8L3NjcmlwdD4=
JavaScript伪协议:
javascript:alert("1")
可以看到通过data伪协议,通过base64编码的方式可以去传输我们想要去传输的数据放在url当中。
通过javascript伪协议,通过javascript标签来去做一个伪协议内容的声明。
其实我们知道不同的浏览器对伪协议支持力度是不一样的,也就是说并不是所有的伪协议在各个浏览器中
都能够去成功地执行。就拿Safari浏览器和Chrome浏览器做对比,访问以上链接:
会发现只有第一个js伪协议链接点击能触发弹窗,后面两个都不行,由此可知,Chrome浏览器对于data伪协议没有内置的默认支持的。
而用Safari浏览器访问点击三个链接都能触发弹窗,说明该浏览器对这两种伪协议都支持。
简单说完伪协议接下来是编码的讲解了。
Unicode编码
ISO(国际标准化组织)指定包括地球上所有文化、所有字母和符号的编码,使用两个字节表示一个字符,Unicode只是一个符号集,它只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储。
具体存储就由:UTF-8、UTF-16等实现。
Unicode编码我们就简单称其为JavaScript编码(当然JS还有八进制、十六进制等编码,但是常用就是unicode编码,这里只讨论Unicode编码,后面JS编码都是默认Unicode编码)。
&#x、\u都可以用来表示一串Unicode编码。%XX可以用来表示URL编码
以下我用"test"这个单词来举例编码(我在后面备注了是哪种编码):
\u0074\u0065\u0073\u0074 (Javascript编码也是Unicode编码)
t e s t (Javascript编码也是Unicode编码)
t e s t (Javascript编码也是Unicode编码)
t e s t (HTML实体编码)
%74%65%73%74 (URL编码)
第一、二、三行都有&#x、\u这种相关字,所以就是Javascript编码,也是Unicode编码。第四个就是HTML编码,最后一个比较常见,发起GET请求时,url地址栏都是被URL编码传递。
浏览器编码:
解析一篇HTML文档时主要有三个处理过程:HTML解析,URL解析和JavaScript解析。每个解析器负责解码和解析HTML文档中它所对应的部分,且顺序也有所区别。
接下来详细说一下各种解码(我用前端代码和浏览器解析截图分别说明,注意并不是所有显示高亮的链接都能点击触发弹窗的):
HTML解码:
以javascript:alert(1)为例子: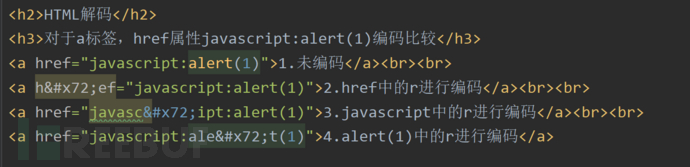
 1.未编码:可以弹窗。
1.未编码:可以弹窗。
2.href中的r进行编码:不会弹出,变成文本文档。(因为这种编码会整个格式的一个解析,导致解析器没办法构建自己的DOM树,没办法编码解析。)
3.javascript中r进行编码:可以弹窗。
4.alert(1)中的r进行编码:可以弹窗。
URL解码:
同样以javascript:alert(1)为例子: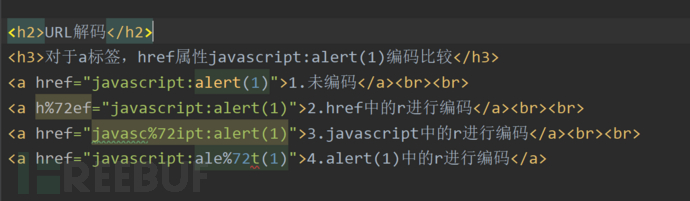

1.未编码:可以弹窗
2.href中的r进行编码:不可以弹窗。 (URL编码破坏了DOM树结构)
3.javascript中r进行编码:不可以弹窗。(URL编码破坏了协议类型)
4.alert(1)中的r进行编码:可以弹窗。
JavaScript编码:
同样以javascript:alert(1)为例子: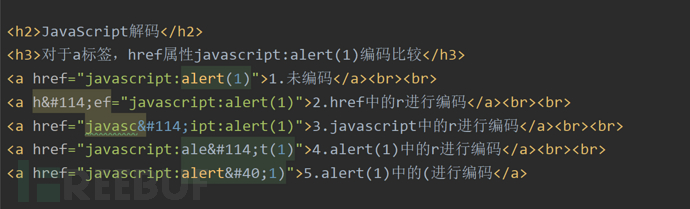
 1.未编码:可以弹窗
1.未编码:可以弹窗
2.href中的r进行编码:不可以弹窗。 (DOM树结构被JS编码破坏)
3.javascript中r进行编码:不可以弹窗。(协议类型被JS破坏了)
4.alert(1)中的r进行编码:可以弹窗。
5.alert(1)中的(进行编码:不可以弹窗。(不能对控制字符编码)
在了解了以上三种基础编码之后,得出非常重要的知识点结论:
一个html文档解码顺序是:JS<URL<HTML
也就是说最先进行HTML解码,再URL解码,最后是JS解码。
原理:当浏览器接收到一个
HTML文档的时候,他要先解析文档本身,然后去构建自己的DOM树结构,构建好之后,对内容第一次解析,解析肯定围绕HTML文档本身展开的,解析HTML编码成功之后,再去解析各个标签的属性,比如a标签,img标签等。这些标签内部可能它有属性是url属性的,这时候会尝试url解码,url里面可能会有伪协议,他最后去执行一个伪协议的解码。所以解码顺序就出来了。
有了上面的理解,接下来说一下二层混淆编码:
同样对于javascript:alert(1):
 1.alert(1)中的r进行js编码,后url编码:可以弹窗
1.alert(1)中的r进行js编码,后url编码:可以弹窗
2.alert(1)中的r进行js编码,后html编码:可以弹窗
3.alert(1)中的r进行url编码,后html编码:可以弹窗
原理:根据解码顺序:JS<URL<HTML,第一个没有HTML编码,只有js和url,那就先对js编码,再url编码,刚好和解码顺序相反。符合,所以可以弹窗。同理二和三都可以。
最后,来一下三层混淆解码:
同样对于javascript:alert(1):


alert(1)中的r进行js编码,后url编码,再html编码:可以弹窗。
原理:编码顺序和解码顺序恰好相反,并且1:1对应。
最后来做个综合利用:
javascript:%5c%75%30%30%36%31%5c%75%30%30%36%63%5c%75%30%30%36%35%5c%75%30%30%37%32%5c%75%30%30%37%34%28%32%33%32%33%29
将以上编码还原出来:
我们依次做解码,按照解码顺序:JS<URL<HTML。
先进行HTML解码: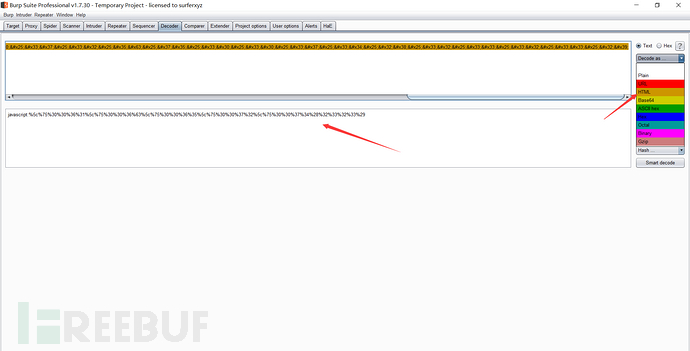
javascript:%5c%75%30%30%36%31%5c%75%30%30%36%63%5c%75%30%30%36%35%5c%75%30%30%37%32%5c%75%30%30%37%34%28%32%33%32%33%29
这个“%”看出是url编码标识,所有再进行URL解码: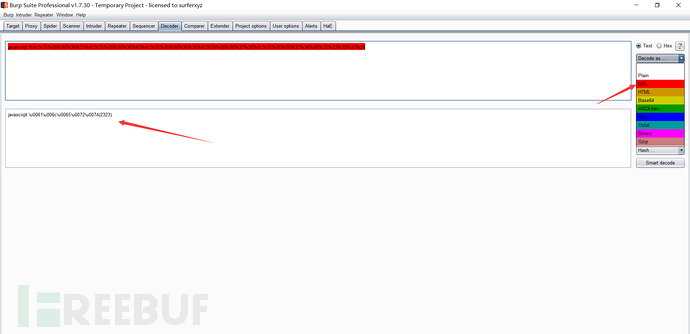 \u006a\u0061\u0076\u0061\u0073\u0063\u0072\u0069\u0070\u0074\u0028\u0032\u0033\u0032\u0033\u0029
\u006a\u0061\u0076\u0061\u0073\u0063\u0072\u0069\u0070\u0074\u0028\u0032\u0033\u0032\u0033\u0029
”\u“是unicode编码标识,再进行Unicode解码: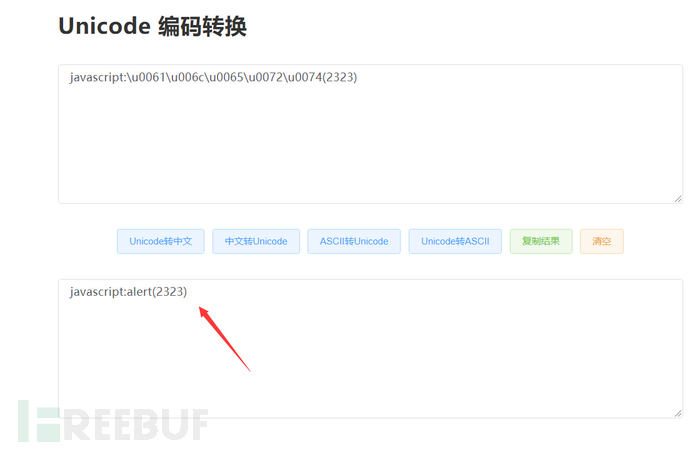 javascript(2323)
javascript(2323)
以上就是结果,最后要说的是,首先要对编码和解码有清晰的了解,其次对各种编码的特征有概念,在这个情况下才能快速定位当前编码的状态以及如何解码,关于编码解码工具线上有很多,使用很方便,希望这次教程能给大家打下一点基础。
如需授权、对文章有疑问或需删除稿件,请联系 FreeBuf 客服小蜜蜂(微信:freebee1024)





- 6 文章数
- 7 关注者