


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

 菜鸡CaiH
菜鸡CaiH- 关注
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
曾记得某位大佬说过“渗透测试的本质就是信息收集”,那么信息收集,我们到底该收集啥?
还记得当初学完最基本的漏洞的时候,抑制不住内心的激动,想着终于能大展身手了。

拿起一个网站看见输入框就用sqlmap扫一扫,看见搜索框就输入xss载荷,可想而知,一无所获。相信这也是大部分初学者的状态,虽然学习了基本的漏洞类型,但是一拿起网站来实战却一无所获,找不到任何漏洞,师父看见我这德性

告诫我说“渗透测试的本质是信息收集,真正的高手80%的时间的都花在信息收集。”瞬间明白,原来我与高手之间差的就是这80%的时间啊。
由此可见信息收集是多么重要,那么我们信息收集到底该收集什么呢?下面我以收集某高校教务处网站的信息为例,讲一下我这个菜鸡对信息收集的理解。
网站所展示的信息
我们打开这个教务处网站的首页,列出里面所有的重要要素。

URL
二维码
验证码
注册用户
忘记密码
网页源码
用户名和密码
我们需要对上面的所有的要素进行信息收集。
URL
我们需要收集这个域名下的二级域名、ip以及C段、旁站,可以使用工具进行收集,常见的工具有Layer、webroot、御剑等,也可以使用在线查询网站如webscan(http://www.webscan.cc/)等;也可以使用搜索引擎语法进行子域名的收集site:xxx.edu.cn,同时需注意是否存在像robots.txt这样的敏感文件。大家挑选最适合自己的方法既可。这里再啰嗦一下,解释C段和旁站的概念。
C段:由于ip地址是有段分的,比如1.1.1.1 最后一个1是c段 如1.1.1.0/1.1.1.255 这个C段为255256个ip地址 B段就是1.1.0.0/1.1.255.255 中间有65535个ip地址 。
旁站:与这个网站在同一个服务器上面的网站。
二维码
这里要求我们使用相应的APP扫码登录,下载这个apk文件,放到kali下面
解压apk客户端安装包:
#apktool d xxx.apk
使用正则表达式提取过滤出APK的ip地址:
grep -E “([0-9] {1,3}[\.]){3}[0-9]{1,3}" -r xxx --color=auto
使用正则表达式提取过滤出APK的域名:
grep -E "https?://[a-zA-Z0-9\.\/_&=@$%?~#-]*" -r xxx --color=auto
验证码
这里主要看的是能不能绕过验证码,我们需要关注以下几个点
1、登录失败的时候验证码是否会刷新
2、验证码是否足够复杂,能被PKAV HTTP FUzzer等工具识别
3、验证码是否由本地js生成、js验证
4、验证码是否能在前端获取。
5、验证码是否会定时改变
注册用户
注册用户这个功能在高校是关闭的,如果能够注册用户那真是太好不过了,就省得去找可以登录的账号和密码了。

找回密码
找回密码处我们可以瞅瞅是否存在逻辑漏洞,从而更改别人的密码,如果是使用短信验证码进行找回密码,可以尝试对验证码进行爆破或者进行逻辑绕过。
网页源码
注意观察源代码里面是否会有开发者预留的相关信息,有时候开发者为图方面会将测试账号密码、默认管理员账号密码写在前端。同时查看源代码里面的一些相对路径的文件和绝对路径的文件,可能会存在未授权访问漏洞。
用户名和密码
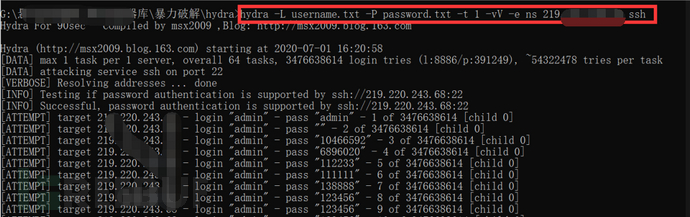
我们只有登录进教务处的网站才能进行进一步的渗透。这里教职工和学生使用的都是同一个登录口,我们需要收集教师和学生的账号和密码。观察账号的命名规则,一般学生账号的命名都是有规律的,找到这个规律写个脚本生成大量的账号。在此高校中,教职工号一般都是4到6位数,尝试不同位数的账号进行登录,通过观察网页是否提示账号不存在信息,确定教职工号的位数,也可以使用百度语法intext:xxx教职工号或者QQ群等途径,查找教职工号由于这个网站有验证码,且验证码会不断地动态更新,我们并不能对这个网站进行爆破,需要另辟蹊径,可以试着找找这个高校别的网站没有验证码的登录口,进行爆破。但是现在没有验证码的网站太少了。

那么,进行下一个操作,猜密码!!!在该高校官网上可以找到转专业、奖学金名单,这个名单有学号、姓名,甚至有电话号码。最开始可以尝试12345678等一些常见弱口令,但是随着高校信息安全意识的提高,都会强制要求学生将密码改成数字+字母的形式。通过猜解人的思维定式,我们可以尝试学号+名字缩写、电话号码+名字缩写、1314+名字缩写、520+名字缩写这样子的密码组合。对于教职工号和密码,可以在高校二级学院的网站下面找到研究生导师介绍,里面一般都有教师的电话和邮箱、工号,我们可以尝试名字缩写+邮箱、名字缩写+电话号码、123456+名字缩写等密码组合。
猜密码是一个非常需要毅力的工作,有些人可能猜了几个常见的密码就放弃了,但是也看见过有些大佬用了一个下午的时间猜出了一个密码。有社工库的话,可以将名字扔进社工库,查找密码。如果还是没有找到能登录的账号和密码,那么我们就只能尝试社工了,如下:


网站背后的信息
收集一个网站的信息,当然不能仅仅收集这种表面的信息,后面更深层次的内容等着我们去探索。我们还得对整站信息、web指纹信息、开发者信息进行收集。
整站信息
整站信息包括服务器类型、网站容器、脚本类型、数据库类型、端口。这些信息一般都比较好找,使用工具扫一扫就能出来,这里推荐使用Goby这个工具,界面简洁,可操作性及易用性都很强。
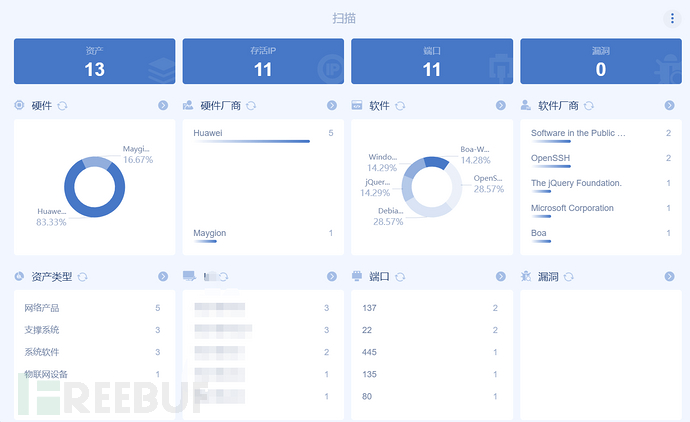
另外像御剑、北极熊等这些工具也比较实用,大家都可以试一试,总有一款适合您哦。其中我们收集到web服务器是什么类型的(Apache/Nginx/Tomcat/IIS),还要继续探测web服务器的具体版本,比如IIS6.0会有文件名解析漏洞、IIS7.0有畸形解析漏洞,不同的web服务器存在着不同的漏洞。查看服务器开放了哪些端口,看是否有端口可以进行利用,比如20、21端口,可用于文件的上传下载,看看是否可以采取匿名登录ftp服务器。再比如22、3389等用于远程连接和登录的端口,可以使用hydra进行爆破。
web指纹信息
收集web指纹信息的时候,我们可以使用云悉、whatweb等网站进行收集。或者可以通过自己的经验去判断,比如看见微笑脸这个页面

就知道使用了thinkphp框架等。然后查看对应框架系统爆出过的漏洞,逐个进行尝试。
开发者信息
有些时候高校的网站并不是自己开发的,而是外包给公司开发的,这就需要收集开发者的信息,可以在乌云镜像、国家信息安全漏洞共享平台、各大安全社区等等去看看这个厂商开发的系统有没有存在什么漏洞,然后逐一进行尝试。
最后当然是要将我们的目标网丢到Nessus、AWVS这些扫描工具里面去扫一扫,看看有没有什么漏洞,说不定会有大大的惊喜。
最后
还是那句话,“渗透测试的本质是信息收集”,越了解我们的目标,渗透测试就越容易下手,正所谓“知己知彼,百战不殆”。
如需授权、对文章有疑问或需删除稿件,请联系 FreeBuf 客服小蜜蜂(微信:freebee1024)







- 3 文章数
- 9 关注者