


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

- 关注
 本文由
创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
本文由
创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
*本文原创作者:fishyyh,本文属FreeBuf原创奖励计划,未经许可禁止转载
一、前言
本文结合自然语言处理技术,采用卷积神经网络算法训练SQL注入检测模型,主要包括文本处理、提取文本向量和训练检测模型三个部分。由于本人是初学者,也是通过前辈们的文章来学习这方面的知识,很多地方可能理解不够充分,请大家及时纠正。
二、训练数据
实验过程中的数据集主要分为三组训练集(用于训练检测模型的数据)、验证集(训练过程中验证模型的准确率)、测试集(测试训练完成后模型的准确率)。
训练集中正常样本24500条,SQL注入攻击样本25527条,XSS攻击样本25112条;验证集中正常样本10000条,SQL注入攻击样本10000条,XSS攻击样本10000条;测试中正常样本4000条,SQL注入攻击样本4000条,XSS攻击样本4000条。
正常样本数据格式如下:
code%3Dzs_000001%2Czs_399001%2Czs_399006%26cb%3Dfortune_hq_cn%26_%3D1498591852632SQL注入样本数据格式如下:
-9500%22%20WHERE%206669%3D6669%20OR%20NOT%20%284237%3D6337%29XSS注入样本数据格式如下:
site_id%3Dmedicare%22%3E%3Cscript%3Ealert%281337%29%3C/script%3E%2Casdf三、文本处理
训练过程中使用的数据基本都经过了URL编码,有的可能经过过了多重编码,因此需进行URL循环解码,并且为了减少数字和其他无关因素对数据样本的影响对数据进行范化处理,将数字替换为0,超链接替换为http://u。代码如下:
def URLDECODE(payload):
payload=payload.lower()
while True:
test=payload
payload=unquote(payload)
if test==payload:
break
else:
continue
#数字泛化为"0"
payload,num=re.subn(r'\d+',"0",payload)
#替换url为”http://u
payload,num=re.subn(r'(http|https)://[a-zA-Z0-9\.@&/#!#\?]+', "http://u", payload)
#分词
r = '''
(?x)[\w\.]+?\(
|\)
|"\w+?"
|'\w+?'
|http://\w
|</\w+>
|<\w+>
|<\w+
|\w+=
|>
|[\w\.]+
'''
return nltk.regexp_tokenize(payload, r) 未处理的数据样本如下:
1)))%252bAND%252b8941%25253d8941%252bAND
/yk10/?page=54%20LIMIT%201%2C1%20UNION%20ALL%20SELECT%22C%20NULL%2C%20NULL%23 处理后数据样本如下:
['0', ')', ')', ')', 'and', '0=', '0', 'and']
['yk0', 'page=','0', 'limit', '0', '0', 'union', 'all', 'select', 'null', 'null', 'null'] 四、训练词向量模型
Word2Vec是Google在2013年开源的一款将自然语言转化为计算机可以理解特征向量的工具。Word2Vec主要有CBOW(Continuous Bag-Of-Words)和Skip-Gram两种。CBOW模型训练过程是输入某一个词上下文相关的词对应的词向量,输出是这个词的词向量;而Skip-Gram与之相反,输入特定一个词的词向量,输出该特定词的上下文词向量。
将分词处理完的数据作为文本向量的训练数据,训练得到词向量模型,通过此模型,可将单词转化为计算机所能理解的向量,如单词select经过转化后如下:
[ 5.525984 -2.4446 -0.9985928 -1.6910793 1.8828514 2.8958166
0.90518814 -1.3623474 -1.8427371 0.5957503 -3.9347208 1.4152565
-0.0354603 -7.432402 -0.68348515 -4.0790896]
训练词向量模型的代码如下:
def train_word2vec():
sentences=MySentences(datadir)
cores=multiprocessing.cpu_count()
if os.path.exists(model_dir):
print ("Find cache file %s" % model_dir)
model=Word2Vec.load(model_dir)
else:
model=Word2Vec(size=max_features, window=5, min_count=10, iter=10, workers=cores)
model.build_vocab(sentences)
model.train(sentences, total_examples=model.corpus_count, epochs=model.iter)
model.save(model_dir)
print("save model complete!")
五、训练检测模型
卷积神经网络结构如图所示,由三个卷积层、三个池化层组成,最后连接全连接层:
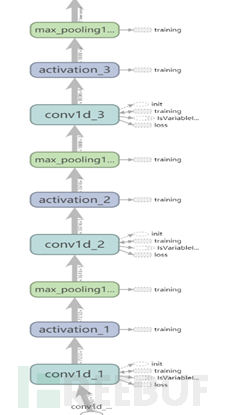
实现代码如下:
def train_cnn():
forline in open("./file/INPUT_SHAPE"):
input_shape=int(line)
print(input_shape)
INPUT_SHAPE=(input_shape,16)
forline in open("./file/len"):
lens=int(line)
print(lens)
data_size=ceil(lens//(BATCH_SIZE*NB_EPOCH))
print(data_size)
forline in open("./file/valid_len"):
valid_lens=int(line)
print(valid_lens)
valid_size=ceil(valid_lens//(BATCH_SIZE*NB_EPOCH))
print(valid_size)
model= CNN.build(input_shape=INPUT_SHAPE, classes=3)
print('1')
model.compile(loss="categorical_crossentropy",optimizer=OPTIMIZER,
metrics=["accuracy"])
print('2')
call=TensorBoard(log_dir=log_dir+"cnn",write_grads=True)
checkpoint= ModelCheckpoint(filepath='bestcnn',monitor='val_acc',mode='auto',save_best_only='True')
next_batch=data_generator(BATCH_SIZE,input_shape,"./file/x_train")
next_valid_batch=data_generator(BATCH_SIZE,input_shape,"./file/x_valid")
model.fit_generator(batch_generator(next_batch,data_size),steps_per_epoch=data_size,
epochs=NB_EPOCH,callbacks=[call,checkpoint],validation_data=batch_generator(next_valid_batch,data_size),
nb_val_samples=valid_size)
print('3')
model.save('cnn')
print("modelsave complete!")
对测试集的4000个SQL注入攻击样本进行测试结果如下,准确率为0.97,误报率0.03
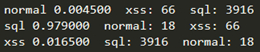
对测试集的4000个XSS攻击样本进行测试结果如下,准确率0.98,误报率0.02
![M(6{`S8TK5[3AWF~R]F3MDF.png](https://image.3001.net/images/20180705/1530771558191.png!small)
对测试集的4000个正常进行测试结果如下,准确率0.98,误报率0.02
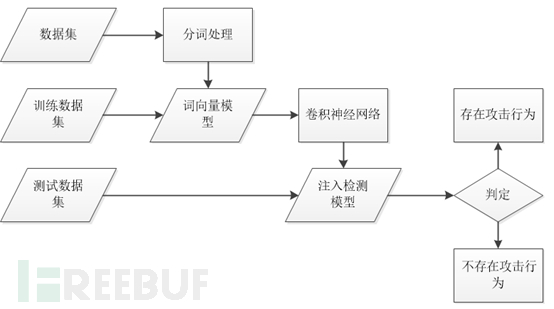
 六、系统运行流程
六、系统运行流程
首先将三组数据集进行分词范化处理,并通过训练得到词向量模型。然后将训练集通过词向量模型转化为向量,使用卷积神经网络训练检测模型。最后使用注入检测模型对测试集数据进行检测是否存在攻击。
参考文章
http://www.freebuf.com/news/142069.html
https://www.cnblogs.com/bonelee/p/7978729.html
刘焱. Web安全之深度学习实战 [M]. 机械工业出版社,2017.
代码托管:
https://github.com/fishyyh/CNN-SQL.git
*本文原创作者:fishyyh,本文属FreeBuf原创奖励计划,未经许可禁止转载
已在FreeBuf发表 0 篇文章
如需授权、对文章有疑问或需删除稿件,请联系 FreeBuf 客服小蜜蜂(微信:freebee1024)
- 0 文章数
- 0 关注者