


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

 FreddyLu666
FreddyLu666- 关注
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
本文由安全研究人员hugsy于2024年03月26日更新并发表于blahcat博客上,本文主要记录了其在进行内存安全和模糊测试任务时发现的一些技术实现方式,主要讨论的是仿真环境下内存转储分析和模糊测试方法。本文旨在为红队和蓝队研究人员提供新的思路,仅出于安全教育目的撰写和发布。
介绍
What-The-Fuzz是我个人非常喜欢的一款工具(0vercl0k库),除了其本身的强大功能之外,我更喜欢该工具创建时背后的故事。除此之外,0vercl0k库中的各种其他组件也是我非常喜欢的,比如说kdmp-parser、symbolizer和bochscpu等等。如果你了解并使用过这些工具库,那么你肯定非常熟悉内存转储和模糊测试的相关内容。在这篇文章中,我将跟大家分享一种仿真环境下内存转储分析和模糊测试的方法。
在此之前,我一般会将内存转储作为在程序崩溃前访问程序崩溃条件和执行上下文的最后一种方式。内存转储一般会用于调试或崩溃分析模糊测试,有时还会用于DFIR。据我所知,What-The-Fuzz是第一个使用它们来进行基于快照的模糊测试工具。
就我个人而言,我比较喜欢使用Python来完成我自己的工作任务,主要原因有以下几点:
1、Python是一种用于快速原型设计的语言,附带了一个很棒的REPL(交互式编程环境),同时PyPI也给Python提供了一个强大的生态环境;
2、具有与低级别机器代码交互的强大能力;
3、我个人非常喜欢这门语言;
但我马上就遇到了问题,bochscpu一开始是使用Rust开发的,而kdmp-parser和udmp-parser则是用C++写的,只有kdmp-parser有一个还未开发完成的Ptyhon绑定(很多API都没有,PyPI也未上架)。所以,我似乎找到了一个方向:
1、自己创建umdp-parser和bochscpu的Python绑定;
2、升级kdmp-parser现有的Python绑定;
目前来说,任何人都可以使用“pip install”命令来安装上述包,并直接在Python解释器v3.8+环境中直接使用,因此我们也可以直接使用下列命令直接重新生成上述包:
pip install udmp-parser kdmp-parser bochscpu-python
完全配置好整个实验环境之后,我们就可以开始使用下列方法进行深入挖掘和研究:
1、使用udmp-parser解析用户模式进程转储;
2、使用kdmp-parser解析内核内存转储;
3、使用这些信息重建一个可行的环境(内存布局和CPU上下文等),以便bochspu运行我们选择的任何代码;
整个过程中我们需要确保每一项设置都能够正常工作,并时刻拥有绝对的执行控制权。
我们接下来会单独研究每一个测试用例,但首先我们需要进一步研究手头上的代码库。
代码库快速浏览
Bochs/BochsCPU
众所周知,Bochs模拟器具有极其强大的检测功能,并且被认为非常适用于x86 ABI实现(包括最新的扩展)。另一方面,yrp的BochsCPU是一个Rust库,它封装了Bochs CPU代码,并通过Rust API(以及通过FFI的C++)公开Bochs的所有指令点(包括上下文切换、中断、异常等)。这些所有的特点注定了Bochs会是一个非常有用的工具,适用于开发任何X86模式的代码、处理非常旧的任务关键型软件以及协助逆向和漏洞研究等任务。
udmp-parser/kdmp-parser
udmp-parser和kdmp-parser都是跨平台的C++解析库,由0vercl0k开发,专门用于WIndows内存转储场景。这两款工具分别针对的是用户模式(WinDbg中使用.dump /m)和内核模式(WinDbg中使用.dump /f|/ka)转储。最重要的是,这两个工具都提供了Python3绑定,允许我们快速制作原型。
Windows内核模式仿真
在这些工具库的帮助下,想要实现从Windows内核转储运行模拟器,就相对比较简单了,因为转储只不过是在给定时间内操作系统状态的快照罢了。
首先,从KdNet会话开始,我们可以轻松创建一个转储。在寻找有价值的攻击面时,我一般喜欢使用我自己的IRP监控工具CFB,但对于我们的场景来说,任何其他的工具也能够实现:
kd> bp /w "@$curprocess.Name == \"explorer.exe\"" nt!NtDeviceIoControlFile [...] Breakpoint 0 hit nt!NtDeviceIoControlFile: fffff807`4f7a4670 4883ec68 sub rsp,68h
获取转储的方式之一就是使用.dump命令:
kd> .dump /ka c:\temp\ActiveKDump.dmp
但更好的做法是使用yrp的bdump.js脚本:
kd> .scriptload "C:\bdump\bdump.js" [...] kd> !bdump_active_kernel "C:\\Temp\\ActiveKDump.dmp" [...] [bdump] saving mem, get a coffee or have a smoke, this will probably take around 10-15 minutes... [...] [bdump] Dump successfully written [bdump] done!
构建BochsCPU会话
我们可以使用kdmp_parser.KernelDumpParser来解析转储,因此转储的解析工作就交给它了。对于BochsCPU的运行来说,拿到一个PF句柄回调是非常关键的,这也是一个基础需求。完整的内存转储可能会有几个GB,所以将其全部映射到主机上似乎不是非常合理,尤其是我们只需要其中一小部分的时候,因此我们可以这样处理:
dmp = kdmp_parser.KernelDumpParser(pathlib.Path("/path/to/dumpfile.dmp"))
def missing_page_cb(pa: int):
gpa = bochscpu.memory.align_address_to_page(pa)
if gpa in dmp.pages: # do we already have the page in the dump?
# then create & copy the page content, resume execution
hva = bochscpu.memory.allocate_host_page()
page = dmp.read_physical_page(gpa)
bochscpu.memory.page_insert(gpa, hva)
bochscpu.memory.phy_write(gpa, page)
sess = bochscpu.Session()
sess.missing_page_handler = missing_page_cb这为我们提供了第一次解决缺失页面的机会,而CPU触发的PageFault异常(例如PageFault -> BX_PF_EXCEPTION (14))将为我们提供第二次分析页面故障的机会,因为工具将会填充错误代码,而我们可以使用英特尔手册的“Intel 3A - 4.7”部分检查故障原因。
接下来,我们必须给CPU提供一个bochscpu.State状态,指示其初始上下文,其中包括CR、GPR、标志寄存器和段寄存器等。需要注意的是,我们可以在bochscpu.cpu中找到几个有用的组件来加快整个进程:
regs = json.loads(pathlib.Path("/path/to/regs.json").read_text())
state = bochscpu.State()
bochscpu.cpu.set_long_mode(state)
[...]
state.cr3 = int(regs["cr3"], 16)
state.cr0 = int(regs["cr0"], 16)
state.cr4 = int(regs["cr4"], 16)
[...]
state.rax = int(regs["rax"], 16)
state.rbx = int(regs["rbx"], 16)
state.rcx = int(regs["rcx"], 16)
state.rdx = int(regs["rdx"], 16)
[... snip for brievety]
sess.cpu.state = state最后,我们还需要对剩下的可挂钩事件定义Bochs回调:
def before_execution_cb(sess: bochscpu.Session, cpu_id: int, _: int):
state = sess.cpu.state
logging.info(f"Executing RIP={state.rip:#016x} on {cpu_id=}")
hook = bochscpu.Hook()
hook.before_execution = before_execution_cb
hooks = [hook,]最后,直接使用一个简单的调用触发整个操作即可:
sess.run(hooks) sess.stop()
$ python kdump_runner.py Executing RIP=0xfffff80720a9d4c0 on cpu_id=0 Executing RIP=0xfffff80720a9d4c4 on cpu_id=0 Executing RIP=0xfffff80720a9d4cb on cpu_id=0 Executing RIP=0xfffff80720a9d4d0 on cpu_id=0 Executing RIP=0xfffff80720a9d4d4 on cpu_id=0 Executing RIP=0xfffff80720a9d4dc on cpu_id=0 Executing RIP=0xfffff80720a9d4e1 on cpu_id=0 Executing RIP=0xfffff80720a9d4e8 on cpu_id=0 Executing RIP=0xfffff80720a9d4ec on cpu_id=0 [...]
如需获取更加详细和完整的示例,可以参考bochscpu-python库【传送门】中提供的“examples/long_mode_emulate_windows_kdump.py”。
Windows用户模式仿真
在Windows上获取进程快照的方法不止一种(如WinDbg、Task Manager、procdump、processhacker等),所以这部分我打算直接跳过,并假设你已经准备好了快照。
在BochsCPU上模拟用户模式代码比内核模式稍微复杂一些:内核转储包括一个几乎完整的操作系统快照,包括MMU正常工作所需的所有内核部分,然而我们需要的只在需要时将这些页面映射到Bochs。
Windows上的用户模式转储不包括任何这些信息,而只包括与用户模式进程本身相关的信息。我们必须记住的是:BochsCPU只是CPU,这意味着它可以执行任何事情,但它需要设置所有内容,如处理器模式和映射页面等。但是,如果进程以受保护模式运行的话,通过MMU的内存访问也必须正确关闭,以确保VirtualAddress→ PhysicalAddress翻译有效。因此,我们需要为整个流程构建我们自己爹页面表。这一部分网上也有很多方法,因此这里不再赘述。
还记得之前说过,bochscpu-python库能够帮助我们加快整个流程吧?示例如下:
dmp = udmp_parser.UserDumpParser()
assert dmp.Parse(dmp_path)
pt = bochscpu.memory.PageMapLevel4Table()
pa = PA_START_ADDRESS
# Collect the memory regions from the Windows dump
# For each region, insert a new PT entry
for _, region in dmp.Memory().items():
if region.State == MEM_FREE or region.Protect == PAGE_NOACCESS:
continue
start, end = region.BaseAddress, region.BaseAddress + region.RegionSize
for va in range(start, end, PAGE_SIZE):
flags = convert_region_protection(region.Protect)
if flags < 0:
break
pt.insert(va, pa, flags)
hva = bochscpu.memory.allocate_host_page()
bochscpu.memory.page_insert(pa, hva)
print(f"\bMapped {va=:#x} to {pa=:#x} with {flags=}\r", end="")
pa += PAGE_SIZE
# Commit all the changes, resulting in a valid PT setup for the VM
for hva, gpa in pt.commit(PML4_ADDRESS):
bochscpu.memory.page_insert(gpa, hva)接下来,就像对内核转储所做的事一样,我们还需要倒入所有寄存器,包括GPR和标志寄存器。另一件事则需要取决于线程的选择:当VM执行即将恢复时,CPU不能在不依赖段寄存器的情况下工作,段寄存器是根据CS、DS、SS段寄存器中设置的值和状态中获取的。值得庆幸的是,这些值可以直接从转储中检索得到:
threads = dmp.Threads() tids = list(threads.keys()) tid = tids[0] # whatever teh first thread is, but TID can be hardcoded too switch_to_thread(state, threads[tid]) def switch_to_thread(state: bochscpu.State, thread: udmp_parser.Thread): # build CS _cs = bochscpu.Segment() _cs.base = 0 _cs.limit = 0xFFFF_FFFF _cs.selector = thread.Context.SegCs _cs_attr = bochscpu.cpu.SegmentFlags() _cs_attr.A = True _cs_attr.R = True _cs_attr.E = True _cs_attr.S = True _cs_attr.P = True _cs_attr.L = True _cs.attr = int(_cs_attr) state.cs = _cs # do the same for the others (obvisouly adjusting values/flags)
同样的,Windows也需要FS和GS寄存器。现在,我们已经构建了Windows仿真环境所需的一切了,接下来我们就要好好想想我们需要执行什么任务了。
PGTFO
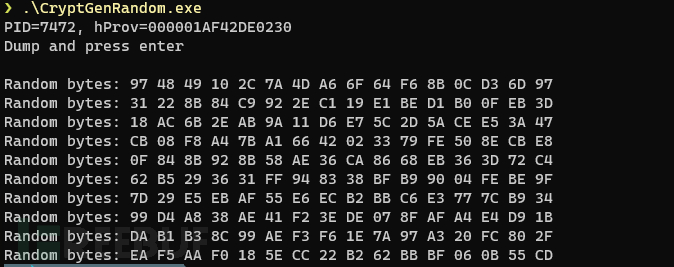
由于获取进程快照之后,我们能够获取到目标进程PRNG的当前状态,因此我们可以使用仿真来发现下列值:
#include <windows.h>
#include <wincrypt.h>
#include <stdio.h>
#pragma comment(lib, "advapi32.lib")
int main()
{
HCRYPTPROV hCryptProv;
CryptAcquireContext(&hCryptProv, NULL, NULL, PROV_RSA_FULL, CRYPT_VERIFYCONTEXT);
printf("PID=%lu, hProv=%p\nDump and press enter\n", GetCurrentProcessId(), (void *)hCryptProv);
getchar(); // We break here and snapshot the process
for (int i = 0; i < 10; i++)
{
BYTE randomBytes[16] = {0};
CryptGenRandom(hCryptProv, sizeof(randomBytes), randomBytes)
printf("Random bytes: ");
for (int i = 0; i < sizeof(randomBytes); i++)
printf("%02X ", randomBytes[i]);
printf("\n");
}
CryptReleaseContext(hCryptProv, 0);
return 0;
}
继续执行模拟器,我们将能够直接调用转储中的任何函数/:
logging.debug(f"Resolving 'cryptbase!SystemFunction036'") fn_start = resolve_function(fn_sym) fn_end = fn_start + 0x1C # hardcode the end address of the function for now state.rcx = temp_buffer_va state.rdx = 16 state.rip = fn_start hook = bochscpu.Hook() hook.before_execution = lambda s, _: s.cpu.state.rip == fn_end and s.stop() sess.run([hook,])
现在我们就能够成功转储所有的值了:
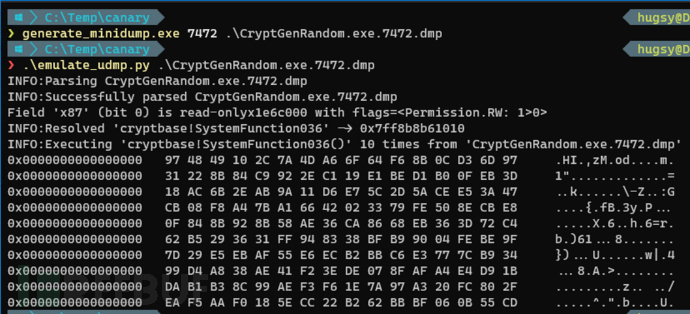
OK,全部搞定!
Linux该怎么办呢?
俗话说的好...

在lief工具的帮助下,我们能够解析并输入内存布局:
/**
* For demo purpose, compiled with `-static`
*/
#include <stdlib.h>
#include <stdio.h>
#include <stdint.h>
#include <time.h>
void generate_random_buffer(uint8_t* buf, size_t sz)
{
for(int i=0; i<sz; i++)
buf[i] = rand() & 0xff;
}
int main()
{
srand(time(NULL));
uint8_t buf[0x10] = {0};
generate_random_buffer(buf, sizeof(buf));
getchar(); // get a coredump
for(int i=0; i<sizeof(buf); i++)
printf("%02x ", buf[i]);
puts("");
return 0;
}编译代码:
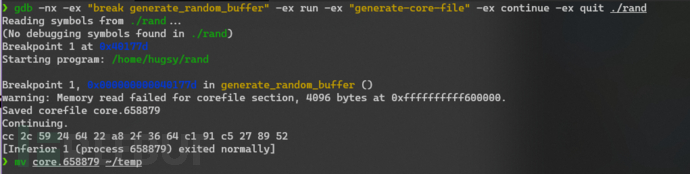
然后运行:
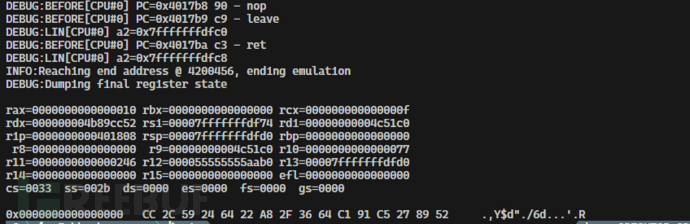
不出所料,结果是一样的!
总结
本文详细介绍了内存转储中需要注意的事项,以及一些新的方法,希望可以给广大红队和蓝队研究人员提供一些新的思路。
参考资料
https://github.com/bochs-emu/Bochs
https://github.com/yrp604/bochscpu
https://github.com/0vercl0k/wtf
https://github.com/0vercl0k/kdmp-parser
https://github.com/0vercl0k/udmp-parser
参考链接
https://blahcat.github.io/posts/2024/01/27/tapping-into-the-potential-of-memory-dump-emulation.html
如需授权、对文章有疑问或需删除稿件,请联系 FreeBuf 客服小蜜蜂(微信:freebee1024)


![[Meachines][Easy]Perfection](https://image.3001.net/images/20240419/1713520118_66223df63ab44f36217d8.png)



- 68 文章数
- 24 关注者