


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

一、java SPI
1.1 什么是SPI
SPI (Service Provider Interface),是一种将服务接口与服务实现实现分离的机制,以达到解耦的目的,大大提高了项目的可拓展性。
例如在数据库的产品中,有各式各样的数据库产品,而如果每一个产品都有一个各自的配置类,那么在使用中无疑是非常麻烦的,例如我要使用mysql需要调用mysql的相关配置类,而在调用oracle数据时则需要调用oracle相关类。如果本来使用mysql,而现在需要换成oracle,如果采用这种方式的话则需要修改代码,耦合性很高。
所以java就关于数据库连接驱动有一个固定接口,各大数据库厂商只需要在提供jar包时实现其接口,对用户来说就可以只通过修改配置来完成更换的操作。
1.2 如何使用SPI
那么java SPI是如何使用的呢?
约定在 Classpath 下的 META-INF/services/ 目录里创建一个以服务接口命名的文件,然后文件里面记录的是此 jar 包提供的具体实现类的全限定名。
可以看一下Mysql的jar包
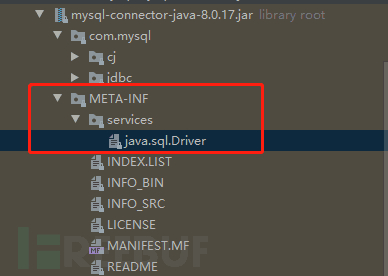
其中的内容为:
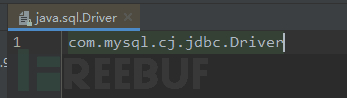
该文件的意思是,该mysql的jar包提供了一个关于接口“java.sql.Driver”的实现“com.mysql.cj.jdbc.Driver”。
那么java在运行过程中就会收集到这个信息,后续哪里需要调用的时候,就根据需求找到该实现类。
1.3 SPI实践
例如我们现在有一个接口,两个实现类。
public interface StuService {void getName();}public class Stu1 implements StuService{@Overridepublic void getName() {System.out.println("Alice");}}public class Stu2 implements StuService{@Overridepublic void getName() {System.out.println("Bob");}}public class SpiDemo {public static void main(String[] args) {ServiceLoader<StuService> stus = ServiceLoader.load(StuService.class);Iterator<StuService> iterator = stus.iterator();while (iterator.hasNext()) {StuService stu = iterator.next();stu.getName();}}}
我们在项目的/Resource/META-INF/services/com.example.demo.dubbo.StuService中根据命名规则定义:
com.example.demo.dubbo.Stu1com.example.demo.dubbo.Stu2
运行结果如下:
AliceBob
可以看到,我们首先获取了接口的ServiceLoader,然后获取了他的迭代器,然后获取每个实现类,并执行了其中的接口方法。
1.4 SPI实现源码
从获取迭代器的源码开始分析:ServiceLoader.load(StuService.class);
public static <S> ServiceLoader<S> load(Class<S> service) {ClassLoader cl = Thread.currentThread().getContextClassLoader();return ServiceLoader.load(service, cl);}public static <S> ServiceLoader<S> load(Class<S> service,ClassLoader loader){return new ServiceLoader<>(service, loader);}private ServiceLoader(Class<S> svc, ClassLoader cl) {service = Objects.requireNonNull(svc, "Service interface cannot be null");loader = (cl == null) ? ClassLoader.getSystemClassLoader() : cl;acc = (System.getSecurityManager() != null) ? AccessController.getContext() : null;reload();}public void reload() {providers.clear();lookupIterator = new LazyIterator(service, loader);}
可以看到就是创建了一个迭代器并返回了。需要注重看一下迭代器对应重写的hasNext()与next()方法。
public boolean hasNext() {if (acc == null) {return hasNextService();} else {PrivilegedAction<Boolean> action = new PrivilegedAction<Boolean>() {public Boolean run() { return hasNextService(); }};return AccessController.doPrivileged(action, acc);}}
可以看到最终调用的是这个方法hasNextService()
private boolean hasNextService() {if (nextName != null) {return true;}if (configs == null) {try {//其中PREFIX就是"META-INF/services/",也就是我们约定的地方获取类名String fullName = PREFIX + service.getName();if (loader == null)configs = ClassLoader.getSystemResources(fullName);elseconfigs = loader.getResources(fullName);} catch (IOException x) {fail(service, "Error locating configuration files", x);}}while ((pending == null) || !pending.hasNext()) {if (!configs.hasMoreElements()) {return false;}//解析文件,对应我们的代码应该有两项pending = parse(service, configs.nextElement());}//当第一次执行该方法时,因为有两个实现类,所以此时该值不为空nextName = pending.next();return true;}
代码还是非常简单的,总结来说就是首先去我们约定好的地方获取我们要加载的类,对应我们的demo也就是去获取"/Resource/META-INF/services/com.example.demo.dubbo.StuService"这个文件,然后读取文件流加载文本中的内容,并对有多项的实现类进行缓存。
然后就是next():
public S next() {if (acc == null) {return nextService();} else {PrivilegedAction<S> action = new PrivilegedAction<S>() {public S run() { return nextService(); }};return AccessController.doPrivileged(action, acc);}}
可以看到跟上面很类似的也是调用nextService():
private S nextService() {if (!hasNextService())throw new NoSuchElementException();String cn = nextName;nextName = null;Class<?> c = null;try {//获取要加载的classc = Class.forName(cn, false, loader);} catch (ClassNotFoundException x) {fail(service,"Provider " + cn + " not found");}if (!service.isAssignableFrom(c)) {fail(service,"Provider " + cn + " not a subtype");}try {//通过反射创建class对应实例S p = service.cast(c.newInstance());providers.put(cn, p);return p;} catch (Throwable x) {fail(service,"Provider " + cn + " could not be instantiated",x);}throw new Error(); // This cannot happen}
以上就是java SPI的源码了,总结来说就是会分为两步,首先会去约定的位置获取文件信息,然后获取文本中的实现类,并通过反射的方式获取实例。
二、Dubbo SPI
2.1 Dubbo SPI与java SPI区别
那么为什么java已经有了SPI机制,Dubbo还要进行重写呢。
其实在上面的使用过程中我们就会发现,假如说我们一个接口有多个实现类,而我们只想要其中一个类时。
因为加载器只会返回一个迭代器,我们只能通过遍历迭代器来加载我们的实现类,因此会实例化很多无用的类,而当这些类加载又比较耗时时,就会造成无用的资源浪费。
2.2 Dubbo SPI配置
同样的,Dubbo SPI也有约定的存放文件配置的位置:
META-INF/services/ 目录:该目录下的 SPI 配置文件是为了用来兼容 java SPI 。
META-INF/dubbo/ 目录:该目录存放用户自定义的 SPI 配置文件。
META-INF/dubbo/internal/ 目录:该目录存放 Dubbo 内部使用的 SPI 配置文件。
在java中,SPI的配置文件是以换行为区分有多个实现类的,而Dubbo中则是以键值对的形式来存储配置。
例如:
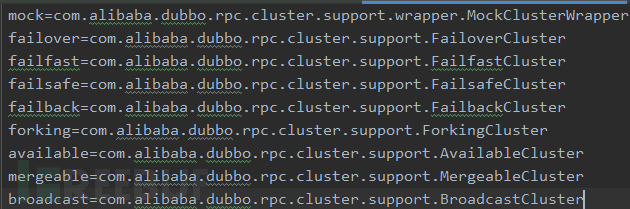
2.3 SPI实例
还是基于我们刚刚的实例:
@SPIpublic interface StuService {void getName();}
注意此处加上了@SPI注解
我们在"/Resource/META-INF/dubbo/com.example.demo.dubbo.StuService"新建文件,内容如下:
stu1 = com.example.demo.dubbo.Stu1stu2 = com.example.demo.dubbo.Stu2
main方法添加dubbo获取spi
public static void main(String[] args) {ServiceLoader<StuService> stus = ServiceLoader.load(StuService.class);Iterator<StuService> iterator = stus.iterator();while (iterator.hasNext()) {StuService stu = iterator.next();stu.getName();}ExtensionLoader<StuService> extensionLoader = ExtensionLoader.getExtensionLoader(StuService.class);StuService stu1 = extensionLoader.getExtension("stu1");stu1.getName();StuService stu2 = extensionLoader.getExtension("stu2");stu2.getName();}
输出结果:
AliceBob21:58:45.480 [main] INFO com.alibaba.dubbo.common.logger.LoggerFactory - using logger: com.alibaba.dubbo.common.logger.slf4j.Slf4jLoggerAdapterAliceBob
可以看到,我们的Dubbo SPI也能够正常获取实现类。
2.4 Dubbo SPI源码
同样我们从获取的地方入手:
//获取ExtensionLoaderExtensionLoader<StuService> extensionLoader = ExtensionLoader.getExtensionLoader(StuService.class);//获取加载对象StuService stu1 = extensionLoader.getExtension("stu1");
首先看extensionLoader.getExtension("stu1");
public T getExtension(String name) {Holder<Object> holder = cachedInstances.get(name);if (holder == null) {cachedInstances.putIfAbsent(name, new Holder<Object>());holder = cachedInstances.get(name);}Object instance = holder.get();if (instance == null) {synchronized (holder) {instance = holder.get();if (instance == null) {//创建对象instance = createExtension(name);holder.set(instance);}}}return (T) instance;}
createExtension(name)
private T createExtension(String name) {//1.获取classClass<?> clazz = getExtensionClasses().get(name);if (clazz == null) {throw findException(name);}try {T instance = (T) EXTENSION_INSTANCES.get(clazz);if (instance == null) {//2.通过反射实例化对象EXTENSION_INSTANCES.putIfAbsent(clazz, clazz.newInstance());instance = (T) EXTENSION_INSTANCES.get(clazz);}injectExtension(instance);Set<Class<?>> wrapperClasses = cachedWrapperClasses;if (wrapperClasses != null && !wrapperClasses.isEmpty()) {for (Class<?> wrapperClass : wrapperClasses) {instance = injectExtension((T) wrapperClass.getConstructor(type).newInstance(instance));}}return instance;} catch (Throwable t) {throw new IllegalStateException("Extension instance(name: " + name + ", class: " +type + ") could not be instantiated: " + t.getMessage(), t);}}
可以看到主要有两步:
- 获取class

可以看到入参是我们传入的stu1,而class已经变成我们配置文件中对应的class文件了。
那么dubbo是如何进行转换的呢?
getExtensionClasses()方法中主要是先调用缓存,如果缓存中没有的话会加载类,也就是loadExtensionClasses()
private Map<String, Class<?>> loadExtensionClasses() {final SPI defaultAnnotation = type.getAnnotation(SPI.class);if (defaultAnnotation != null) {String value = defaultAnnotation.value();if ((value = value.trim()).length() > 0) {String[] names = NAME_SEPARATOR.split(value);if (names.length > 1) {throw new IllegalStateException("more than 1 default extension name on extension " + type.getName()+ ": " + Arrays.toString(names));}if (names.length == 1) cachedDefaultName = names[0];}}//初始化返回结果Map<String, Class<?>> extensionClasses = new HashMap<String, Class<?>>();//从"META-INF/dubbo/internal/"路径中加载class文件loadDirectory(extensionClasses, DUBBO_INTERNAL_DIRECTORY);//从"META-INF/dubbo"路径中加载class文件loadDirectory(extensionClasses, DUBBO_DIRECTORY);//从"META-INF/services"路径中加载class文件loadDirectory(extensionClasses, SERVICES_DIRECTORY);return extensionClasses;}
可以看到会从以下三个约定好的路径下加载配置文件
loadDirectory()会加载loadResource()
private void loadResource(Map<String, Class<?>> extensionClasses, ClassLoader classLoader, java.net.URL resourceURL) {try {//读取文件流BufferedReader reader = new BufferedReader(new InputStreamReader(resourceURL.openStream(), "utf-8"));try {String line;while ((line = reader.readLine()) != null) {final int ci = line.indexOf('#');if (ci >= 0) line = line.substring(0, ci);line = line.trim();if (line.length() > 0) {try {String name = null;//解析 “=” 号int i = line.indexOf('=');if (i > 0) {//获取前面的key值name = line.substring(0, i).trim();//获取后面的classline = line.substring(i + 1).trim();}if (line.length() > 0) {//将key与class加载到返回结果中loadClass(extensionClasses, resourceURL, Class.forName(line, true, classLoader), name);}}}}}}}

总结来说,会以文本的方式去解析文件中的内容,分别获取其key值与class值,并将其加载到结果中。在获取到class后,最后以反射的方式进行实例化对象。
2.5 从源码角度上来看Dubbo为何要重写SPI
java SPI在获取到接口名称后,会返回一个迭代器,如果我们想要加载某一个实现类则需要通过循环迭代的方式实例化对象,会加载很多不需要的资源,比较浪费。
而Dubbo SPI则通过键值对的形式,让我们在获取实现类时可以直接通过key值获取到要加载的对象,而不需要再遍历生产所有的实现类,效率相对来说比较高。
作者:韩国凯
如需授权、对文章有疑问或需删除稿件,请联系 FreeBuf 客服小蜜蜂(微信:freebee1024)







- 51 文章数
- 3 关注者