


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

- 关注
刚了解进程的同学,可能对进程和程序的区别都知道。但是上课的时候老师讲的有点生涩,自己看完一些资料以后再来复习一下相关的知识。也转化为实例来讲解一下具体的操作系统下的进程相关的知识
什么是进程?
按照书上所说,进程是程序运行的一个实例。进程是动态的,程序是静态的。那么我就这样来比喻一下:有一个高中生小A,他学习六门课分别是语数外理化生。他的老师将会留下六门课的作业,然后他靠脑子记不过来就记在了小本子上(其实这些记在小本子上面的作业就是所谓的程序)。
他回到家以后,需要拿出小本子再来看一下作业是什么,然后一门一门的开始做(从他拿出小本子看作业都有啥的时候,这就是一个进程的开始,可以简单理解为将磁盘中的代码读入内存中)。然后他拿出相应科目的练习册开始写,按照语数外理化生的顺序一门一门写完(先写什么,按什么顺序写,一次写多少这都可以理解为进程调度。由于桌子空间有限,可以放的书数量有限,简单理解就是计算机执行进程时硬件资源有限,对资源的占用也有限)。每当他写完一门以后,都会将该科目的书放回到书包(可以理解为释放资源,因为桌子一共就那么大,不可能一次把所有的书都放在桌子上)。
到了第二天,他把作业交给了老师(老师其实就属于一个用户。输入任务,然后让学生去做;学生完成了作业,最后把成品输出给老师)
虽然举的例子可能稍微有些不恰当,但是也是比较形象的比较了程序和进程之间的关系。说白了,程序就是交给计算机的任务;而进程就是计算机完成该任务的全过程。
进程号和父进程号
我们初步了解了什么是进程。由于一台计算机的进程有很多,所以操作系统就给每个进程一个编号,该编号是唯一的。当我们进程间相互通信的时候,或者是在执行系统调用的时候,都有可能使用到进程号。
还有一些相关的函数可以获取到进程号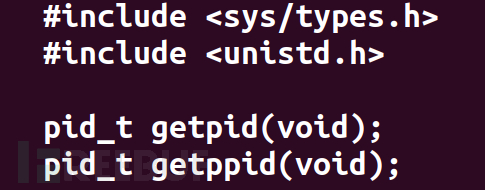
其中getpid是获取进程号,而getppid是获取父进程号。pid_t数据类型是专门用来描述进程号的数据类型,可以简单理解为整形。
在linux系统中,进程号一般最大为32767,不同的系统可能不一样。在分配的进程号未达到最大值的时候,给进程分配的进程号为下一个可用的进程号。简单来说就是进程号在未达到最大以前,只会一直增加。而当进程号达到最大值以后,进程号的计数器将会被重置为300(因为300一下都是一些守护进程,基本上从开机开始就执行)。重置以后由于不可能之前所有的进程都在执行,因此继续上一轮的循环。也就是继续分配下一个可用的进程号。
进程号的上限存放在/proc/sys/kernel/pid_max下面,我们可以进行更改以此来让计算机运行更多的进程。
每一个进程都有自己的父进程,当然除了最开始的进程。老版本的linux最初始的进程为init进程,但是随着版本的更新init进程基本上退出了历史舞台,现在的初始进程为systemd进程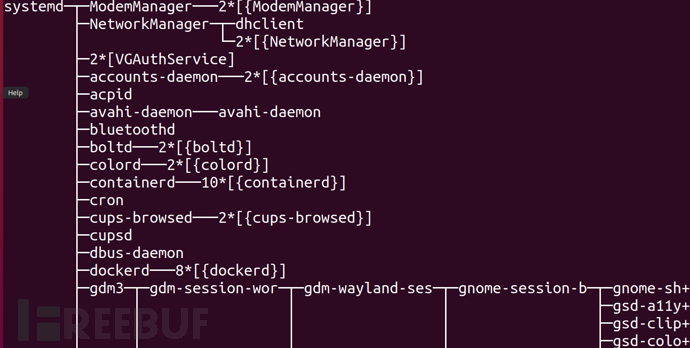
使用pstree指令可以看到进程以树的形式打开。最开始的进程就是所有进程的祖先。子进程被父进程衍生,但是如果父进程被终止,子进程就成为了孤儿,我们叫它孤儿进程。所有的孤儿进程都会被初始进程收养,于是初始进程就成为了孤儿进程的父进程。由于初始进程的是最开始的进程,所以进程号为1
其中/proc/进程号/status文件下存放了进程相关的一些信息
Name: bash
Umask: 0002
State: S (sleeping)
Tgid: 2627
Ngid: 0
Pid: 2627
PPid: 2618
TracerPid: 0
Uid: 1000 1000 1000 1000
Gid: 1000 1000 1000 1000
FDSize: 256
Groups: 4 24 27 30 46 116 126 999 1000
NStgid: 2627
NSpid: 2627
NSpgid: 2627
NSsid: 2627
VmPeak: 24596 kB
VmSize: 24596 kB
VmLck: 0 kB
VmPin: 0 kB
VmHWM: 5632 kB
VmRSS: 5632 kB
RssAnon: 1796 kB
RssFile: 3836 kB
RssShmem: 0 kB
VmData: 1820 kB
VmStk: 132 kB
VmExe: 1040 kB
VmLib: 2488 kB
VmPTE: 92 kB
VmSwap: 0 kB
HugetlbPages: 0 kB
CoreDumping: 0
THP_enabled: 1
Threads: 1
SigQ: 0/15435
SigPnd: 0000000000000000
ShdPnd: 0000000000000000
SigBlk: 0000000000010000
SigIgn: 0000000000380004
SigCgt: 000000004b817efb
CapInh: 0000000000000000
CapPrm: 0000000000000000
CapEff: 0000000000000000
CapBnd: 0000003fffffffff
CapAmb: 0000000000000000
NoNewPrivs: 0
Seccomp: 0
Speculation_Store_Bypass: thread vulnerable
Cpus_allowed: ffffffff,ffffffff,ffffffff,ffffffff
Cpus_allowed_list: 0-127
Mems_allowed: 00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000001
Mems_allowed_list: 0
voluntary_ctxt_switches: 502
nonvoluntary_ctxt_switches: 83
进程的内存布局和管理
当程序运行起来以后,会被装载入虚拟内存空间。此时就应该叫做一个进程。一个进程在虚拟内存中分为几个部分,我们称之为段,英文为segment。
首先为.text段,也称为代码段。代码段具有可读可执行的权限。由于多个进程可以都使用同一个程序,因此代码段是可以共享的。一份程序代码的拷贝可以映射到所有相应进程的虚拟空间中。
然后是.rodata段,该段也被称为初始化数据段,存放的是已经被初始化过的全局变量和静态变量。
相应的是.BSS段,该段被称为未初始化数据段。存放的是未被初始化的全局变量和静态变量。而这又涉及到了另外一个问题,那就未被初始化的数据在磁盘上存储的时候没有必要分配存储空间。ELF文件只需要记录未初始化数据段的位置以及大小,直到程序运行的时候才由程序加载器分配相应的空间
栈,也叫做stack。存放的是局部变量。这个在之前的ROP中已经有介绍过
堆,也叫做heap。当我们动态分配内存的时候,就会分配到堆。这个也在堆利用中有过介绍。
也有一些特殊情况,例如如果我们的编译器经过优化,可能不会将常用的局部变量存放入栈,也有可能直接放入寄存器中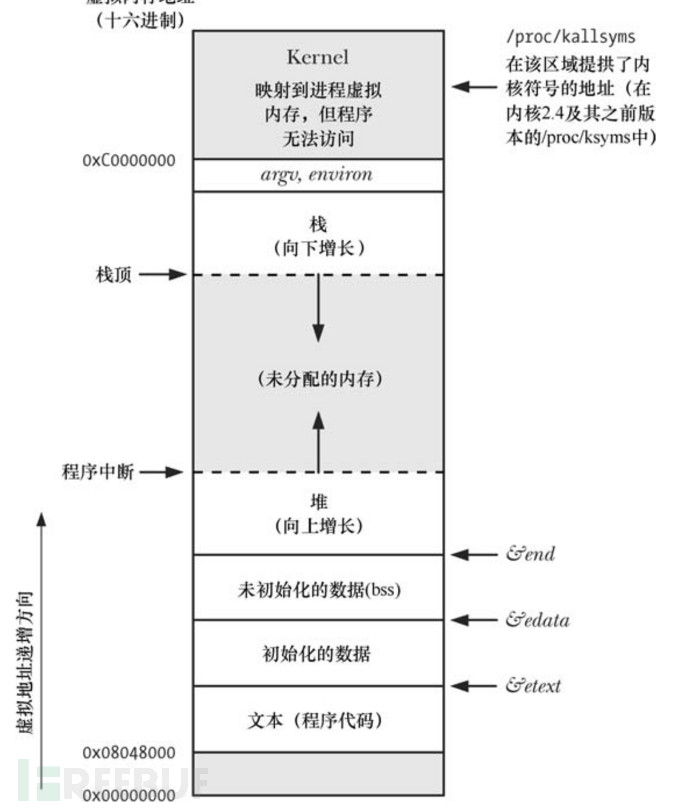
这是32位的虚拟内存分布。了解完内存分布以后我们还要另外了解一下进程内存的管理。
Linux为了高效使用CPU和物理内存,大多数的程序都倾向于访问最近访问过内存地址附近的内存,这是因为指令是顺序执行的缘故。我们也称这种特性为空间局部性。另外程序还倾向于访问不久前已经访问过的内存(循环语句的使用),我们称这种性质为时间局部性。
由于这两个局部性,我们的程序一般也不会一次性全部加载入内存而是只放一部分指令装载入内存。剩下的那一部分存储在磁盘中,那一部分的磁盘被称为交换区。
为了方便寻址,虚拟内存会将每个程序使用的内存分成一个一个小块,我们称之为页。Linux中默认一个页空间为4KB。相应的把RAM中的空间页分为同等大小的块,我们称之为页帧。而留在交换区的那部分程序到了用的时候,进程将会访问相应的内存空间。但是由于还没有将交换区的程序映射到物理内存,因此访问的时候会发生段错误。那么内核就会将该进程挂起并且从磁盘中将该页面装载入物理内存中。这一过程就被称为缺页中断。
由于页的出现,内核就需要为每个进程都维护一张页表。该页表描述了每个页在虚拟内存中的地址。页表中的每个条目需要指出虚拟页面在RAM中所在的位置,或者该页面未被载入内存而是留在交换区中。
虚拟内存有4G,但是我们的进程可能根本不需要这么多的空间,因此并不是所有地址范围都需要页表的条目。那么如果我们访问了一个在页表中根本不存在的地址空间,那么程序将直接被发送信号并且中断
虚拟内存地址需要映射到物理内存空间,是需要一个具体的实现的。实现的工作就交给了一个硬件被称为分页内存管理单元(MMU).它要把访问的每个虚拟内存地址转换成物理内存地址,如果虚拟内存页在物理内存中没有映射的话就要发送页错误给操作系统。
main函数的参数
每一个程序都有一个入口函数也就是main函数,我们会发现main函数是没有参数的。但是大家应该使用过linux中的ls之类的工具。有一个选项是ls -a。这就是命令函参数。命令行参数其实就是main函数的参数。
一般情况下main函数有两个参数,int argc和char *argv[]。其中argc表示命令行参数的个数,而argv则表示具体的命令行参数。我们可以发现argv其实是一个char类型的指针数组。大家可以将其理解为多条字符串。argv[0]也就是第一个参数其实就是我们的程序名称。还用ls举例子的话ls就是命令行参数的第一天命令。其中每个参数最后都是以'\0'结尾,argv这一指针数组是以NULL结尾。
#include <stdio.h>
int main(int argc,char **argv){
for(int i = 0;i<argc;i++)
printf("argv[%d] = %s\n",i,argv[i]);
return 0;
}
这一段代码会输出命令行参数。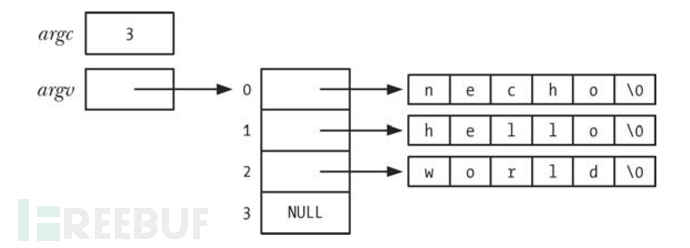
这个就是命令行参数的排列形式。我们获取命令行还有一种方式那就是读取/proc/PID/cmdline文件,该文件中记录了任一进程的命令行参数
我们可以选择读自己进程的命令行参数。但是这样的话可移植性就会下降。
环境变量
概念
这个大家应该经常配置但是又不是很懂到底是什么意思。我们透过现象来看本质,环境变量其实就是个变量。举个例子来说,我们运行一个.jar文件,那么我们知道.jar文件需要用java的jdk打开。但是计算机是不知道的,这时环境变量就起了作用。当我们点击.jar文件的时候系统会查询环境变量看看哪个文件用来运行.jar文件。然后跟着jdk的路径找到了jdk并且运行了.jar文件。在linux中,我们使用ls命令,然后shell就会使用解释器,然后查询环境变量进行递归查找ls程序,最后将其运行。
每一个进程都需要环境变量,并且当进程启动的时候将会继承其父进程的环境变量。环境将会以name=value的样式,排列成多行,类似于一个表。我们也称其为环境列表。当子进程继承其父进程的环境变量以后,它们两者的环境变量就再也没有关系了。即便修改子进程的环境变量对齐父进程没有影响,反过来同理。
命令行中的使用
我们在命令行中可以使用export NAME=VALUE的形式添加环境变量。比如说我想更改自己的家目录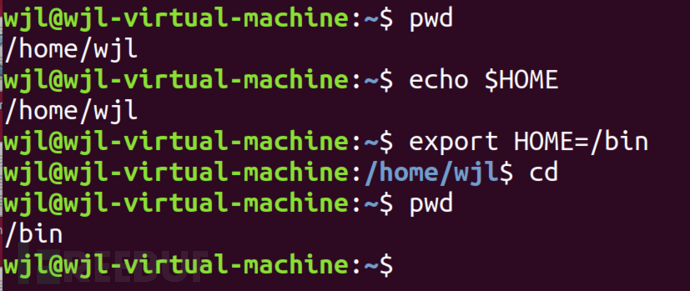
看一下,最开始我的家目录,然后我将家目录更改为/bin,然后使用cd回到家目录。也就是说当我使用export命令以后我的shell进程的环境变量就被改了。当然如果我终止这个shell进程重新打开一个shell进程,那么新的进程家目录还是/home/wjl。因为export只负责改本进程的环境。
我们也可以单纯使用NAME=+VALUE的形式来添加环境。使用printenv命令来输出当前的环境变量。linux中/proc/PID/envrion存放着进程的环境变量
环境变量的内存分布和argv差不多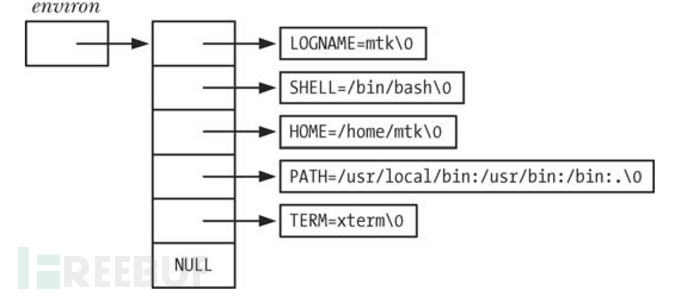
程序中的使用
访问环境变量内容
我们也可以在编程期间去访问环境变量。有一个全局变量environ,我们声明的时候使用extern char** environ,当然也可以将其作为main函数的参数main(int argc,char **argv,char **environ),那么我们如果这样使用environ变量作用域就是main函数中了。
还有一些函数可以用来访问进程中的环境变量。我们一个一个来看一下。

首先是getenv函数,该函数需要传入一个字符串,name就是我们拥有的环境变量。最后将会返回相关的环境变量指针
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
#include <stdlib.h>
int main(){
puts("hello \x0a world");
printf("%d",getpid());
printf("%s",getenv("SHELL"));
getchar();
}
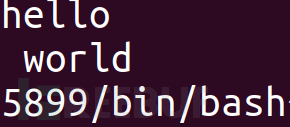
如果我们传入的name在环境变量中根本不存在,那么将会返回NULL。会发现返回环境变量相关的字符串,其实是危险的。如果我们接收到该字符串那么我们对这个字符串进行改变,那么环境变量也就会随之改变。因为返回的指针直接指向环境中的环境变量字符串,而不是拷贝一个副本然后返回。
修改环境变量的内容
修改环境我们可能会使用到putenv函数(这里使用的添加可以理解为覆盖原来的环境变量)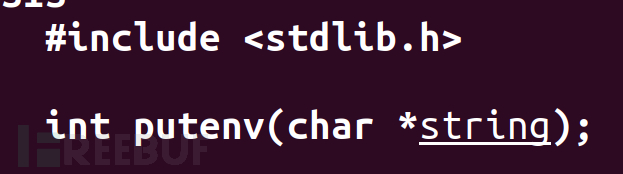
我们传入的是一个字符串,其中字符串的形式应该以name=value的形式。如果环境变量不存在将会将其添加,如果不存在则会创建新的环境变量。如果探究该函数的本质,其实该函数是直接设置环境变量相关的指针指向我们的string。而不是先将string进行拷贝然后再将其添加为环境变量。因此如果我们后续将string改变的话,环境变量也会跟着改变。那么如果我们将string放在栈中,如果栈进行变动也有可能会改变环境变量。所以我们需要很小心的设置string的位置。
putenv还有一个功能,当string没有一个"="的时候,将会删除以string命名的环境变量。
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
#include <stdlib.h>
int main(){
puts("hello \x0a world");
printf("%d\n",getpid());
printf("%s\n",getenv("HOME"));
putenv("HOME=/bin");
printf("%s\n",getenv("HOME"));
putenv("HOME");
printf("%s\n",getenv("HOME"));
getchar();
}
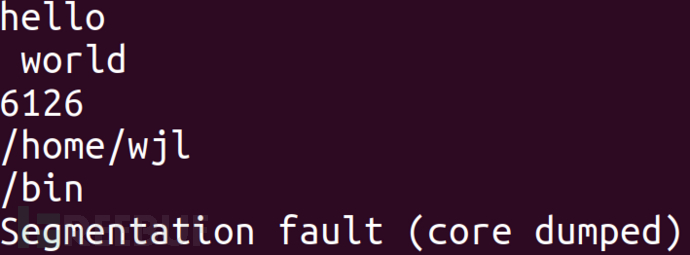
看一下这些变化,最后访问NULL结果报段错误。
为了安全和方便,我们还有另外一对函数。
其中name和value就是环境中的name和value。并且和putenv不同的是该函数会首先为两个参数分配一块缓冲区,然后将参数复制到缓冲区上以此来添加一个环境。如果name是环境变量中存在的,并且overwrite参数不等于等于0,那么该函数将改变环境。反之则不改变环境。而如果name本身就不存在,那么直接添加环境并且与overwrite无关。另外一个unsetenv就是删除一个环境变量。
我们还可能需要用到清空环境变量的函数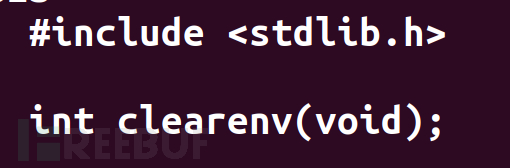
该函数会将environ直接指向NULL
总结:我们了解了进程是什么,进程的内存分布,进程的入口及其参数,进程的环境变量。我感觉对于进程来说应该比较细节了,后面还可能会讲进程内存的分配,其实在堆利用中讲过。我准备再从开发的角度学习一下进程内存的分配
如需授权、对文章有疑问或需删除稿件,请联系 FreeBuf 客服小蜜蜂(微信:freebee1024)
- 0 文章数
- 0 关注者