


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

 JaQLine
JaQLine- 关注
 本文由
JaQLine 创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
本文由
JaQLine 创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
继续学习C++,在这过程中遇到了向上转型,感觉和Java的不太一样。真的就是每天一个C++小技巧
向上转型
我们的基本数据类型就拥有类型转换的功能,比如写一个代码
#include <cstdio>
main()
{
float a = 10;
printf("%f",a);
}
最后的输出结果是这样的 我们定义变量的时候是浮点型,但是赋值为整形,就进行了一个转型。
我们定义变量的时候是浮点型,但是赋值为整形,就进行了一个转型。
在C++中类也可以像这样,小类的对象赋值给大类的对象。这里说的大类就是基类,而小类是派生类。为什么这么说呢?因为C++中引入了"作用域"这个概念。我们画图来看一下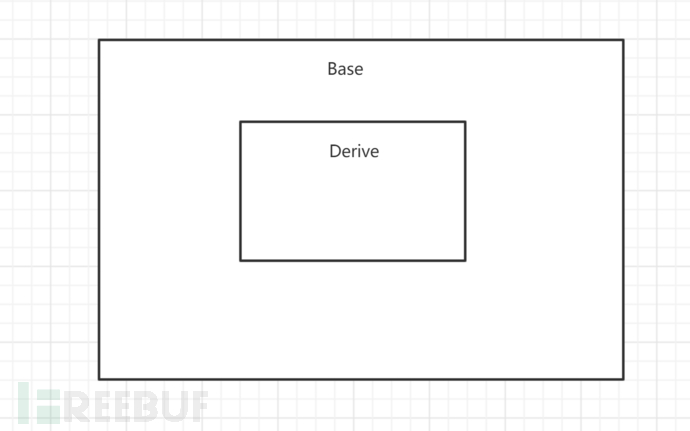 派生类的作用域被包含在了基类之中,那么我们再给它们附上一些变量。
派生类的作用域被包含在了基类之中,那么我们再给它们附上一些变量。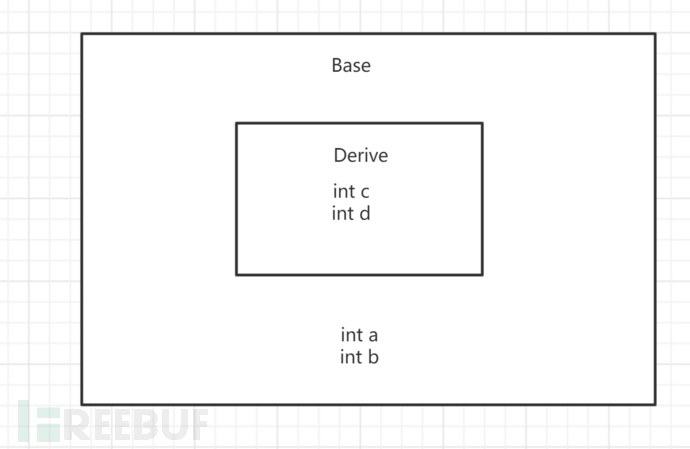 那么当我们创建了一个派生类的对象,想要访问它的对象a的时候,系统做了什么?我们可以这样抽象的理解:首先在派生类的作用域内寻找a,发现找不到a,于是去了它的基类的作用域下去寻找并且找到了变量a。这就是所谓的继承。
那么当我们创建了一个派生类的对象,想要访问它的对象a的时候,系统做了什么?我们可以这样抽象的理解:首先在派生类的作用域内寻找a,发现找不到a,于是去了它的基类的作用域下去寻找并且找到了变量a。这就是所谓的继承。
如何证明呢?方法很简单,当我们在派生类中定义了一个变量也叫a的时候,就会将基类的变量a覆盖掉
#include <iostream>
using namespace std;
class A
{
public:
int a = 10;
};
class B:public A
{
public:
int a = 20;
};
main()
{
B b;
cout << b.a;
}
 这就叫做覆盖,那么这种情况下如何访问基类的变量呢?我么只需要将b.a改成b.A::a就可以了,这样就不会有命名冲突
这就叫做覆盖,那么这种情况下如何访问基类的变量呢?我么只需要将b.a改成b.A::a就可以了,这样就不会有命名冲突 其实函数也是这样,出现同名函数也会导致命名冲突,然后将父类的函数覆盖掉。
其实函数也是这样,出现同名函数也会导致命名冲突,然后将父类的函数覆盖掉。
接下来开始聊向上转型,向上转型也就是让派生类赋值给基类,然后我们看看会发生什么情况。首先来代码
#include <iostream>
using namespace std;
class A
{
public:
A(int a1,int a2);
int m_a1,m_a2;
};
A::A(int a1,int a2):m_a1(a1),m_a2(a2){}
class B:public A
{
public:
B(int a1,int a2,int b);
int m_b;
};
B::B(int a1,int a2,int b):A(a1,a2),m_b(b){}
int main()
{
A a(3,4);
B b(5,6,7);
cout << a.m_a1 << "\n" << a.m_a2 << endl;
cout << b.m_a1 << "\n" << b.m_a2 << "\n" << b.m_b << endl;
return 0;
}
然后是输出结果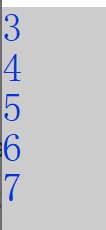 然后我们在输出语句前面加一句a=b
然后我们在输出语句前面加一句a=b 这也就是所谓的向上转型,我们会发现a的前两个成员变成了b的前两个成员。于是我们知道了派生类赋值给基类,共同拥有的成员变量才会被赋值,派生类多出来的变量会被舍弃掉。
这也就是所谓的向上转型,我们会发现a的前两个成员变成了b的前两个成员。于是我们知道了派生类赋值给基类,共同拥有的成员变量才会被赋值,派生类多出来的变量会被舍弃掉。
那么成员函数会怎么样呢?我们再对代码做一下改变
#include <iostream>
using namespace std;
class A
{
public:
A(int a1,int a2);
void show();
int m_a1,m_a2;
};
A::A(int a1,int a2):m_a1(a1),m_a2(a2){}
void A::show()
{
cout << "this is Func of A" << endl;
}
class B:public A
{
public:
B(int a1,int a2,int b);
void show();
int m_b;
};
B::B(int a1,int a2,int b):A(a1,a2),m_b(b){}
void B::show()
{
cout << "this is Func of B" << endl;
}
int main()
{
A a(3,4);
B b(5,6,7);
a = b;
a.show();
b.show();
cout << a.m_a1 << "\n" << a.m_a2 << endl;
cout << b.m_a1 << "\n" << b.m_a2 << "\n" << b.m_b << endl;
return 0;
}
 我们会发现成员变量还是各自调用各自的。
我们会发现成员变量还是各自调用各自的。
通过指针实现的向上转型
代码大体不变,就是单纯的做了一些小小的改变。我们只改变main函数
int main()
{
A *a = new A(3,4);
B *b = new B(5,6,7);
a = b;
a->show();
b->show();
cout << a->m_a1 << "\n" << a->m_a2 << endl;
cout << b->m_a1 << "\n" << b->m_a2 << "\n" << b->m_b << endl;
return 0;
}
最后看结果 我们可以发现结果和上面一样。然后大家可以自己编写一下代码,一般的IDE都有代码补全功能,我用的是code blocks,首先看一个图片
我们可以发现结果和上面一样。然后大家可以自己编写一下代码,一般的IDE都有代码补全功能,我用的是code blocks,首先看一个图片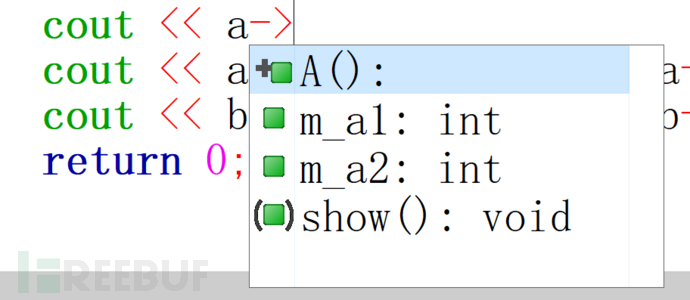 看到了吗?我们进行的是指针的赋值,但是代码补全中没有出现b的成员变量。这就说明虽然我们进行了指针的赋值,但是我们依旧不能使用派生类的成员。同样的,我们的成员函数还是各自调用各自的,这里的问题就比较多了,我们后面都会讲到。
看到了吗?我们进行的是指针的赋值,但是代码补全中没有出现b的成员变量。这就说明虽然我们进行了指针的赋值,但是我们依旧不能使用派生类的成员。同样的,我们的成员函数还是各自调用各自的,这里的问题就比较多了,我们后面都会讲到。
通过引用给基类赋值
除了以上两种方式,还可以通过引用的方式来给基类传值。引用的本质是一种特殊的指针,那么我们可以先估计一下,情况应该和指针传值差不多。然后我们直接看代码
int main()
{
B b(5,6,7);
A &a = b;
a.show();
b.show();
cout << a.m_a1 << "\n" << a.m_a2 << endl;
cout << b.m_a1 << "\n" << b.m_a2 << "\n" << b.m_b << endl;
return 0;
}
只改变main函数,其它都不变,我们看一下运行结果

我们会发现和指针的几乎一样。我们的a只能使用它自己的成员函数。
总结:向上转型可以通过直接传值,指针传值和传递引用的方式,传值以后对象访问只能访问自己类型里面有的成员变量,派生类中多出来的变量无法使用。调用成员函数的时候各自类型调用各自的成员函数
解惑
首先有这么几个问题:成员函数到底如何进行的调用?传指针的时候明明传的是地址,为什么还是有些成员变量无法访问?
成员函数
成员函数存放在代码段,当创建一个对象的时候,对象各自创建自己的成员变量并且共享存放在代码段中的成员函数。而当我们调用函数的时候,并不是通过指针来调用函数,所以即便改变指针也不会改变它所对应的成员函数。成员函数的调用很明显是通过作用域来调用的。也就是说我们定义的数据类型为A的话,就会调用A作用域下的成员函数。
如何去证明呢?我们可以把函数声明但是不进行定义 看一下报错信息,很明显编译器能分得清我们调用的是哪个成员函数。并且将作用域标了出来,我们把b.show()改成b.A::show()就调用的是A的成员函数。换句话说就是成员函数的调用是看数据类型的。
看一下报错信息,很明显编译器能分得清我们调用的是哪个成员函数。并且将作用域标了出来,我们把b.show()改成b.A::show()就调用的是A的成员函数。换句话说就是成员函数的调用是看数据类型的。
指针传值
我们进行了指针传值,但是还是有些成员无法访问。为什么呢?首先先来做一个小实验
#include <iostream>
using namespace std;
class A
{
public:
A(int a);
int m_a;
};
A::A(int a):m_a(a){}
class B
{
public:
B(int b);
int m_b;
};
B::B(int b):m_b(b){}
class C:public A,public B
{
public:
C(int a,int b,int c);
int m_c;
};
C::C(int a,int b,int c):A(a),B(b),m_c(c){}
main()
{
A *a = new A(1);
B *b = new B(2);
C *c = new C(3,4,5);
a = c;
b = c;
cout << a << "\n" << b << "\n" << c;
}
然后我们输出一下看一看 我们确实同时给a和b赋值为c,但是最后却不一样。我们先来画一下继承关系
我们确实同时给a和b赋值为c,但是最后却不一样。我们先来画一下继承关系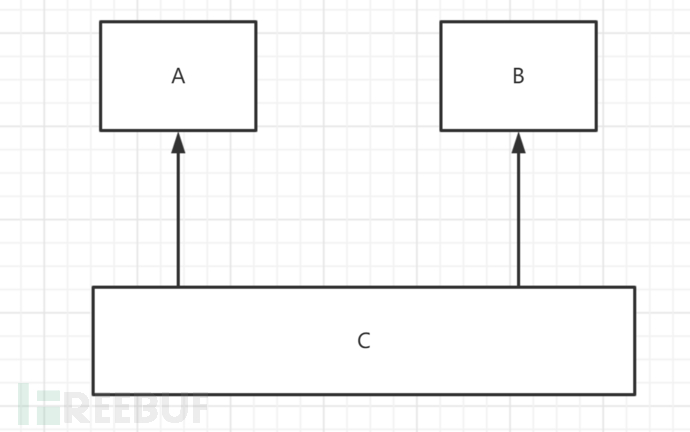 这样的继承关系意味着什么呢?之前我已经讲解过不同继承的内存分配模型,对于C来讲,内存是这样的
这样的继承关系意味着什么呢?之前我已经讲解过不同继承的内存分配模型,对于C来讲,内存是这样的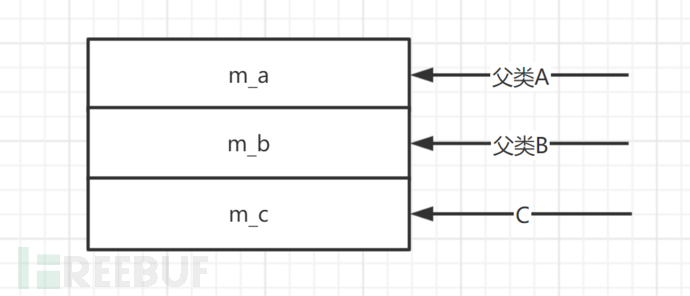 我们之前都知道,派生类赋值给基类,共同的值会被基类保存,而多余的值会被舍弃。这里也是这样的:我们将c给了b和a,于是a和b就被赋予了c的值(多余的值就被舍弃掉)。我们前面也说过,不管是哪种赋值方式,只能访问本类中存在的变量。那么编译器在这个过程中就会插手。
我们之前都知道,派生类赋值给基类,共同的值会被基类保存,而多余的值会被舍弃。这里也是这样的:我们将c给了b和a,于是a和b就被赋予了c的值(多余的值就被舍弃掉)。我们前面也说过,不管是哪种赋值方式,只能访问本类中存在的变量。那么编译器在这个过程中就会插手。
由于m_a是A和C共有的成员变量,所以a的地址和c相同;但是B类中是没有m_a的,它只有m_b,根据只能访问本类中拥有的成员变量的原则,编译器就会调整b的值,让其只能访问到它所拥有的变量也就是m_b。
总结:成员函数的调用不根据指针来调用,而是根据作用域来调用。一个类只能使用自己的成员函数。传值的本质就是往内存中写入数据,但是在这过程中编译器会插手,只让你看到自己应该看到的。
继续我的C++之路,真的就是每天一个C++小技巧
已在FreeBuf发表 40 篇文章
如需授权、对文章有疑问或需删除稿件,请联系 FreeBuf 客服小蜜蜂(微信:freebee1024)
 Linux系统编程
Linux系统编程





- 40 文章数
- 10 关注者