


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

- 关注
 本文由
创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
本文由
创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
逆向调试战技101
此材料引入大量画图,查阅手册以及前置知识的铺垫,来帮助大家完成基础的逆向基础认知。
为今后蓝队方向:防御设备优质规则的调优,恶意软件分析。红队方向:漏洞挖掘与漏洞利用编写。打下一个良好的认知 ------ sec875
背景与认知
OST2设计的系统安全蓝图
https://ost2.fyi/System%20Security.html
此文章位于下图所示。也就是说,前面的三种工具的debug也是它的前置认知。请学习已完成基础性认知。
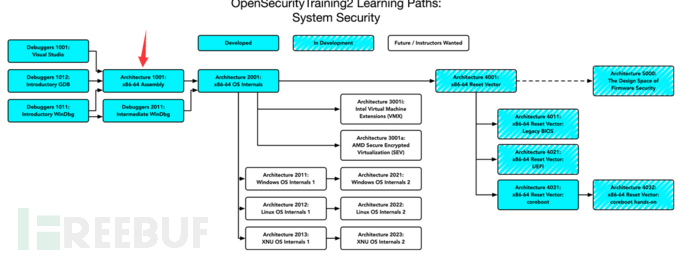
前置知识
注意下面的练习例子。
C语言
https://www.learn-c.org/
edx的c编程与linux课程 。中国大学MOOC,学堂在线,大学课程的C语言选两个学也行。
https://www.edx.org/professional-certificate/dartmouth-imtx-c-programming-with-linux
解除引用地址操作符还是定义指针变量? *
为了帮助大家生动形象的快速理解操作符 * ,这里单独提出来观察,帮助大家举一反三。
https://www.learn-c.org/en/Pointers
分别将这两段代码复制到IDE中编译观察。请尝试将操作符 * 删除,观察它输出的值是内存地址值还是变量本身数据的值
操作符 * 的结果就在下图的两种情况中。最后,不是内存地址就是数据。它这个结果还能跳到哪里去?
下图因为删除了 解除引用地址操作符 * ,所以它输出的地址值。(&a; 为取变量a的内存地址。)
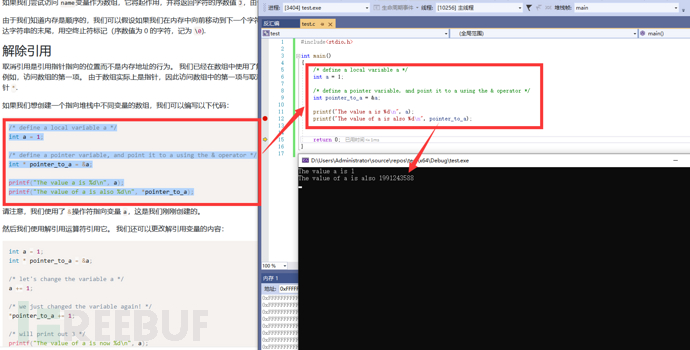
请注意 指针操作符 * 什么时候是指针,什么时候是解除引用指针。空格?没有空格就是解除?加了一个空格就是定义?请自行调试与观察。
看见了没?内存地址(pointer_to_n)的值是 &a 的内存地址而不是它的值 (1) ?
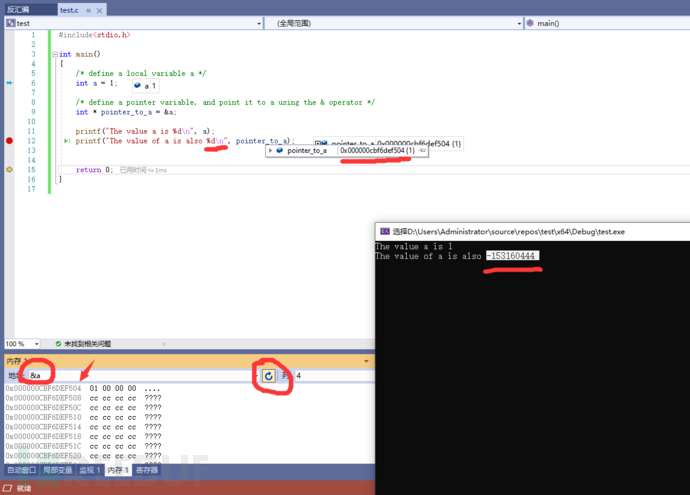
如果您完成了最基本的阅读任务,并耐心的投入时间进来调试这些猜测的地方,您就能快速掌握语言本身的语义或者语法。
如果您无法快速理解以下两行代码,则说明您要么没有耐心阅读与训练,要么就是真的学得挺艰难。。
int * pointer_to_n = &n; ### 存在空格:定义指针变量 pointer_to_n 赋值内存地址
*pointer_to_n += 1; ### 不存在空格:解除地址引用 内存地址内的数据值+1
总而言之:操作符 * 不是取内存地址,就是取内存地址的数据。而空格则控制着这两种情况的切换。
## 再练习一下理解能力?将内存地址传给指针变量p,解除地址引用读取数据++。就是这么简单
void move(point * p) {
(*p).x++;
(*p).y++;
}
以上方式的另一种写法如下所示: 这些往往卡着一堆人,所以单独提出来观察。
void move(point * p) {
p->x++;
p->y++;
}
环境部署
【如果您的VS code安装于物理机,则请确保一切实验之前您知晓自己正在做什么,不要在不之情的前提下盲目实验。有些实验具备破坏性,请及时备份数据。】
windows 10 试用版
https://www.microsoft.com/en-us/software-download/windows10ISO
或者这里 windows 10 1903版本
https://msdn.itellyou.cn/
windows VM
https://p.ost2.fyi/courses/course-v1:OpenSecurityTraining2+Lab_Setup_x86-64_Windows+2021_v1/about
VS code
https://p.ost2.fyi/courses/course-v1:OpenSecurityTraining2+Dbg1001_VS_IDE+2021_v1/about
实验源码
https://gitlab.com/opensecuritytraining/arch1001_x86-64_asm_code_for_class
学习材料
请不要登录并提交修改它们,除非您有很大的把握性。
https://gitlab.com/opensecuritytraining/arch100x_slides_and_subtitles
https://gitlab.com/opensecuritytraining/arch1001_x86-64_asm_slides_and_subtitles
书籍阅读
https://www.amazon.com/gp/product/1484921909/ref=as_li_tl?ie=UTF8&camp=1789&creative=390957&creativeASIN=1484921909&linkCode=as2&tag=opensecuinfo-20&linkId=EPDXM3AQYTVSJEET
这里可以寻找两到三本类似的中文版或者其他PDF,视频之类的。。提前将前置知识准备一些。。
http://library.bagrintsev.me/ASM/Introduction%20to%2064bit%20Intel%20Assembly%20Language%20Programming%20for%20Linux.2011.pdf
扩展阅读:恶意软件威胁情报与指纹,旨在告诉我们各种安全设备规则特征是怎么编写来的。
https://www.blackhat.com/presentations/bh-usa-06/BH-US-06-Bilar.pdf
扩展阅读:用于优化系统软件的 x86-64 指令集分析,旨在告诉我们实际上学的指令集没那么多。
https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.407.5071&rep=rep1&type=pdf
微软手册
https://software.intel.com/content/www/us/en/develop/articles/intel-sdm.html
意识与思维
如果您跳过了前置知识,那么就在调试前把代码弄清楚。
您应该知道C语言的代码大致是做什么功能的。使用IDE调试一步,观察一步,各种窗口(寄存器?内存?等)发生了什么变化
内存、寄存器读取大小端
数据如何存储到内存中,引入了大小端两种说法
存放的单位是:一个字(word)或者更大的单位。word,是英特尔很多年初级开发16位架构时代的一个叫法。那时候将16位视为一个整体,将它叫做word
关于内存存放,以及网络发送大小端就两种说法。以后忘了,两种情况都考虑与调试。不是小端就是大端。
POSIX一般指UNIX系统。就别纠结,这里说得不对了。它指在UNIX上软件而定义的接口?这有意思吗?咱能像生活中那样好好交流吗?: )
大小端:适用于内存(不是寄存器),字节,字(word)
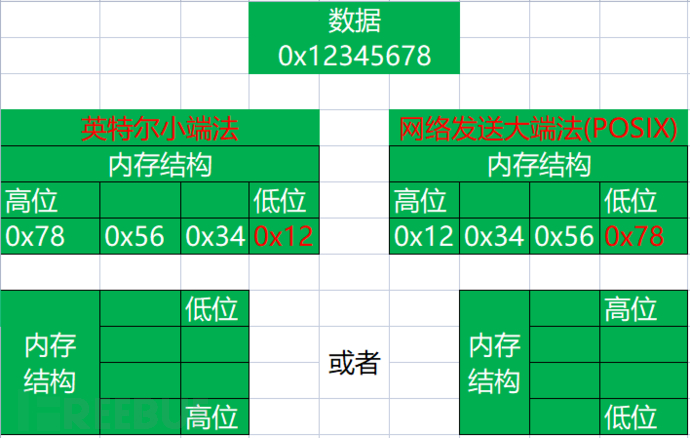
**术语word:**16位架构时代的一个叫法。如下图所示,叫word ( 16bit )

它这里的内存结构低位在最下面

英特尔手册:近5000页!我建议读个目录先。。
https://software.intel.com/content/www/us/en/develop/articles/intel-sdm.html
寄存器大小端
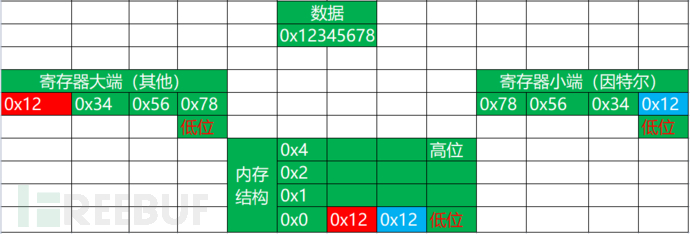
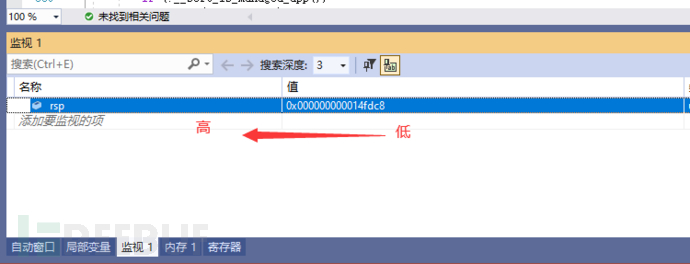
IDE中的低高位。列 1 2 4调试观察一下。

IDE中监视的寄存器
内存层级结构
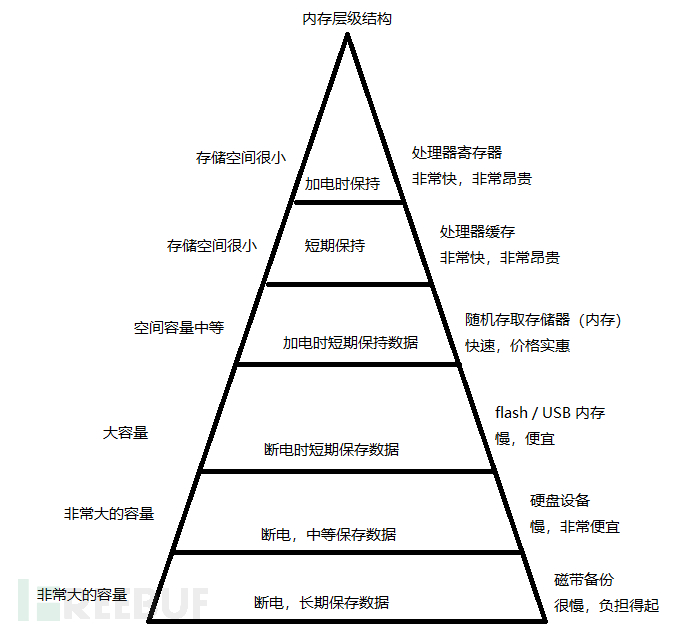
为了防止大家对于磁带的疑惑,这里单独观察一下

x86-64 general purpose registers 通用寄存器
备忘单
https://ost2images.s3.amazonaws.com/Arch101_x86-64_Asm/CheatSheet_x86-64_Registers.pdf
历史演变
8bit时代
16bit时代,word时代
32bit时代
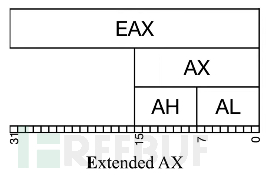
64bit时代
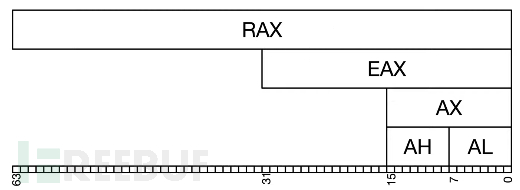
64bit时代还导致了新的命名规则的变化
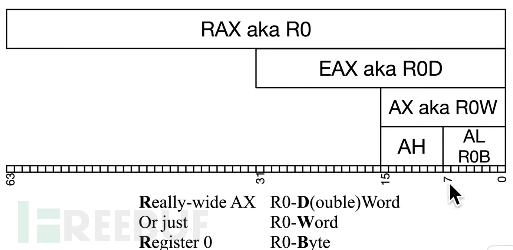
通用寄存器的作用,这个搜一下,不需要逐一讲。举一个例子,来让大家可以举一反三:rsp寄存器,用于堆栈操作的PUSH/POP时,将它们作为基址寄存器

以上寄存器的通用作用仅限于,约定俗成的用途方法。编译器可以将它们用于任何功能,目的都行。
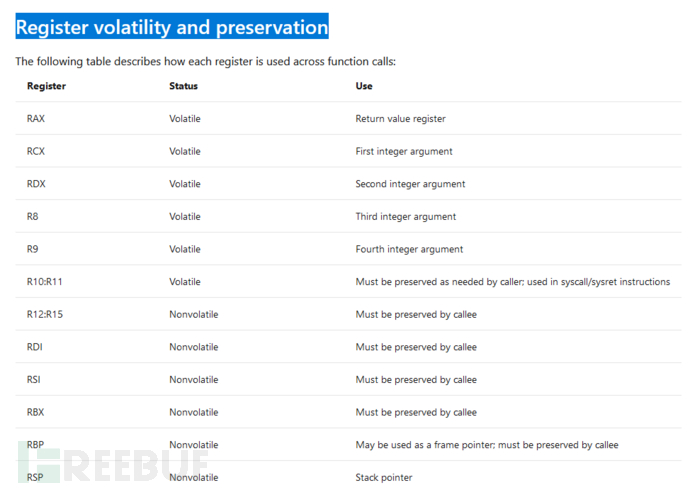
微软编译器于寄存器的用途约定
https://docs.microsoft.com/en-us/cpp/build/x64-software-conventions?view=msvc-160
寄存器不必以这些方式使用,但如果你看到它们被这样使用,你就会知道为什么。
有时候,您看见了寄存器确实用于下面的情况,有时候情况又不同。
很多的编译器并没有倾向于这些用途约定。
rax :存储返回的函数结果值 rbx:指向数据部分的基指针 rcx:字符串和循环操作的计数器
rdx:I/O 指针 RSI:源索引指针于字符串操作 RDI:目标所有指针于字符串操作
RSP:栈顶指针 RBP:栈基指针 RIP:指向要执行的下一条指令的指针(“指令指针”)
指令:无操作 NOP
NOP:No-Operation
没有寄存器,没有值,什么都没有
只是为了填充/对齐字节,或延迟时间
攻击者使用它来让简单的漏洞利用更可靠
一字节的 NOP 指令是 XCHG (E)AX, (E)AX指令的别名助记符
它说XCHG是交换指令,该指令代替三个 MOV 指令,将**(E)AX交换给(E)AX**,其实就是啥也没干。无操作。自己填充自己。延迟时间。
有了这个例子后,我们就能再次的举一反三。哦。原来,我可以为了完成一个功能,增加点别的东西进来混淆。“不直接喝水。将水拿起来,放下去。拿起来,倒入到杯子里,喝水。”而这个特性,往往只有它具备。特征值来了。混淆的思维也来了。攻防对抗来了。
说不定,下一次的 NOP 功能又变成了其他指令哦。很有趣。

NOP 指令在1-9个字节中的操作数会发生变化,2字节时是0x90,其他情况时为0x0F

本小节已举一反三的形式,讲解关于指令NOP的各种情况。大家可以举一反三的,来学习其他指令。
基于这里的统计,我们实际上只需要再学学下面最常见的指令即可。不需要每一个都学习。
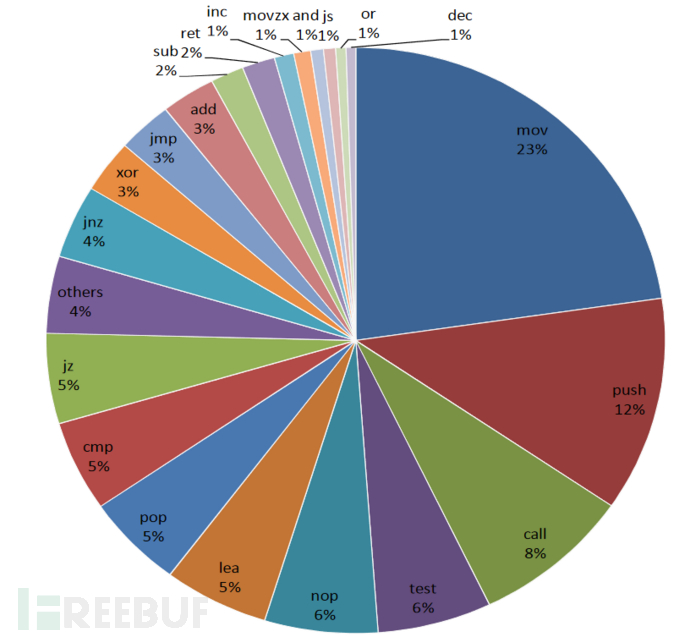
堆?栈?堆栈?
栈?堆栈?都在表达着同一个东西,就是 Stack。您可以将其翻译成栈或者堆栈。
但是堆,表达的是另一个东西,就是heap。您可以将其翻译成堆。
当您从别的地方看见堆栈时,意识思维就要知道,是在讲一个stack?还是在说一个heap?还是意指这两个?
本文默认堆栈为stack,堆为heap。
堆栈是后进先出(LIFO)的数据结构。而heap则是另一种数据结构类型,比如二叉树。
push 压入,pop 弹出。
堆与堆栈是内存中的概念。程序启动时,操作系统来指定它。
不同的操作系统根据自己的约定在不同的地址启动它,又或者使用地址空间布局随机化(ASLR)
按照惯例。注意是通常情况。堆栈向低地址增长,堆向高地址增长。如下图所示。
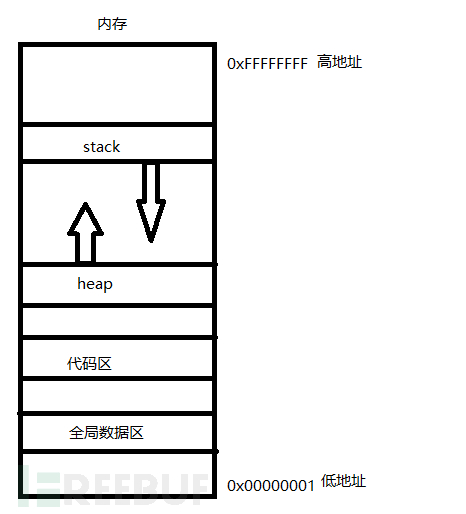
所以。堆和堆栈会存在碰撞。程序会出错。
寄存器rsp是stack的指针,它指向堆栈的顶部。
数据将存在于堆栈顶部以外的地址,但它被认为是未定义的。
局部变量,函数调用的返回地址,都在堆栈中。您会在其他地方看见顶部与底部相反的情况,但请以微软手册为准。
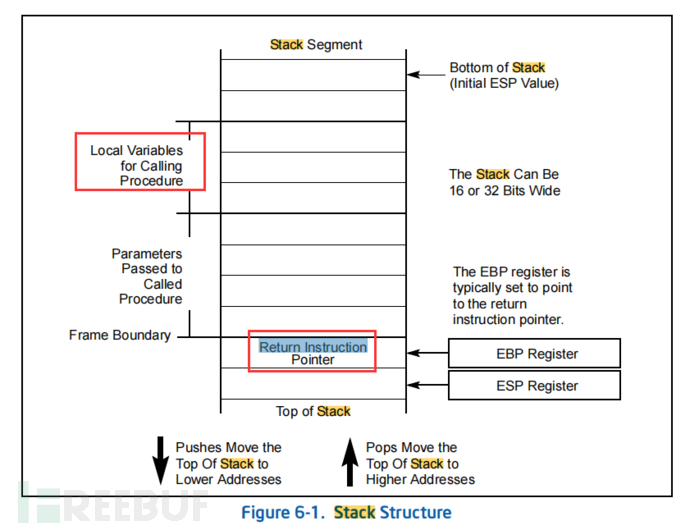
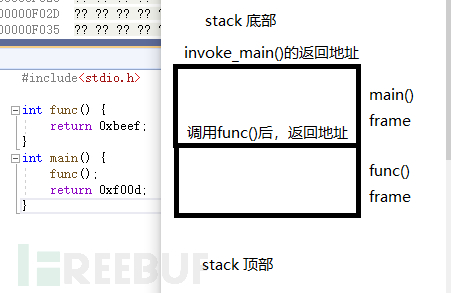
frame 边界的概念,如同所示
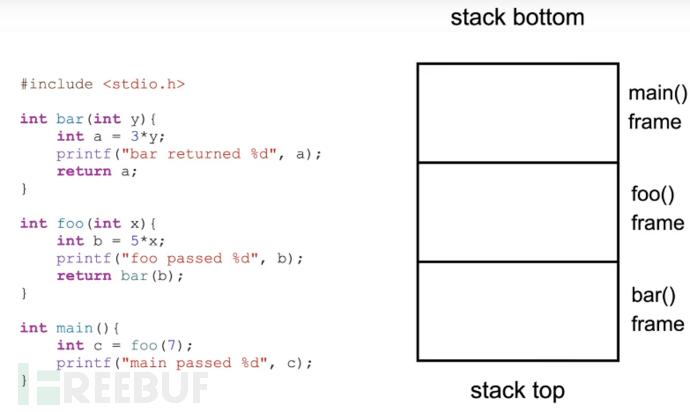
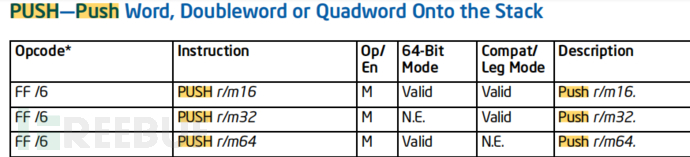
PUSH和POP指令
VS code 调试代码及其断点设置如下所示
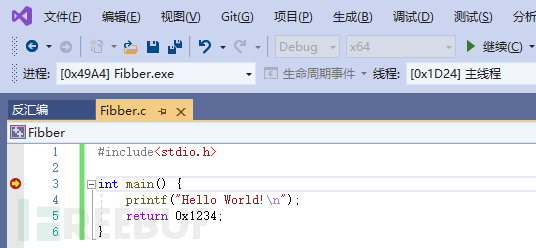
有时候看不见PUSH指令,但它已其他指令改变了rsp寄存器的堆栈值来实现的PUSH操作
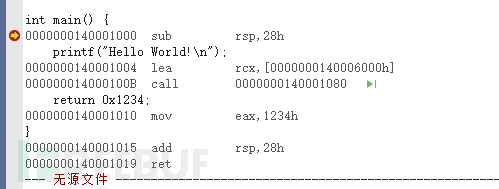
GDB调试如下,载入二进制文件,切换为因特尔汇编语法,开始运行并设置入口点为断点,显示汇编。linux上面,显示了PUSH和POP指令
为什么GCC/Clang有,但是VS code没有PUSH和POP指令?
push指令自动递减rsp,这是8bit字节的情况。但64bit 寄存器又是不同版本的情况。这里先掌握使用r/m X的形式是为了内存地址寻址即可。请将r/m X 视为不同的内存地址寻址方式。
在 intel 语法中,方括号[]表示将其中的值视为内存地址,并获取该地址处的值(类似于解除引用指针 *p 取得地址里面的值)
r/mX 可以有 4 种内存寻址形式
1.寄存器:rbx
2.内存,基址 [rbx]
3.内存,基址+索引*因子[rbx+rcx*A]A = 1,2,4或者8
4.内存,基址+索引*因子+移位[rbx+rcx*A+B]B = 1个字节(0-2^8) 或者 4个字节(0-2^32)
在64bit模式下,指令结果值可以POP弹出到64bit寄存器中;也可以POP弹出进入内存地址,已r/mX 的复杂机制寻址
约定中的rbp在顶部,rsp在底部
这仅仅只是约定。您非常有可能遇到高低位,顶低部相反的情况。
顶部是真正的方向,而非内存意义上的低位生长。
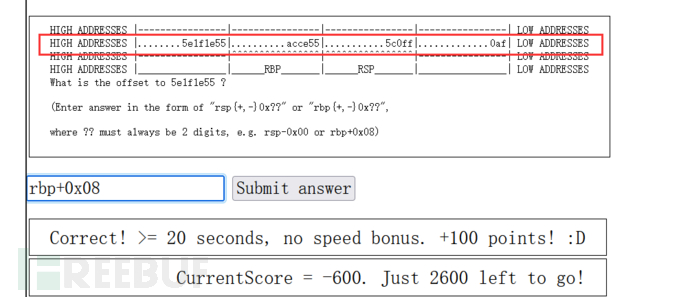
基于rbp或者rsp为参考点的偏移量表示法(64bit = 8字节 = 0x08)如下图所示
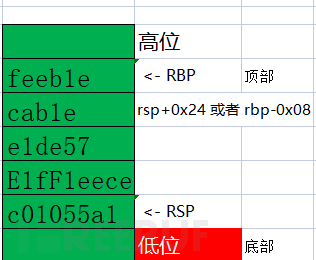
请练习随机分布的地址值与偏移量,确保自己已掌握并感受到。四个章节练习,对应着很多不同场景的内存布局,请完成全部练习,而不是其中之一。
https://p.ost2.fyi/courses/course-v1:OpenSecurityTraining2+Arch1001_x86-64_Asm+2021_v1/courseware/7746741e5e7246c39376e878362141eb/54462f07853740b48cb1164d99f27bc9/?child=first
请注意最后一个水平的内存结构,内存地址只分布成了一行
指令:call、ret、mov、add、sub
CALL
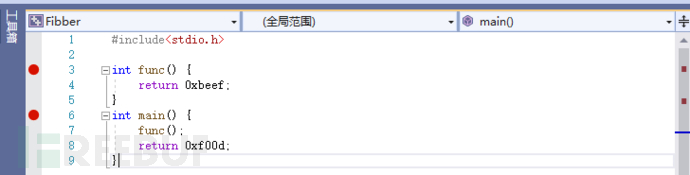
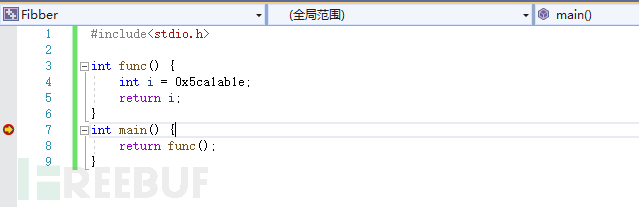
调试源代码
#include<stdio.h>
int func() {
return 0xbeef;
}
int main() {
func();
return 0xf00d;
}
VS code 反汇编

call 指令将控制权转移到不同的函数; 以某种方式可以在以后从停止的地方恢复控制
首先它将下一条指令的地址压入堆栈,这里是压入下一条地址值到RSP中,在处理完了以后让ret指令来使用
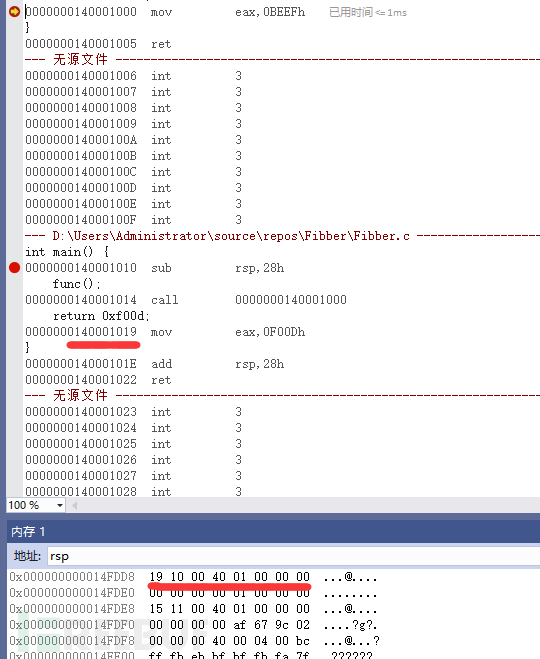
然后它将 RIP 更改为指令中给出的地址
call 的目标地址可以通过多种方式指定
绝对地址
相对地址(这个相对性的参考物可以是call指令的结束,或其他一些寄存器)
ret :返回call的两种情况
pop 顶部到 RIP(记住,pop 隐式递增栈指针,RSP) 。
pop 顶部到 RIP 中,并将恒定数量的字节添加到 RSP 。
如您所见,它只有一个指令。但确实是隐式的做了很多事情。再注意到前面调试源码中的返回值硬编码return 0xf00d; 我们才能从汇编中知道这些事情。这种硬编码思维,形如windows API的地址。
在这种形式中,指令写为“ret 0x8”,或“ret 0x20”等:RSP以前是D8 +0x8 =E0
intel语法 与 AT&T 语法
intel:目标 <-- 源 windows
AT&T:源 --> 目标 unix/gnu %寄存器 $立即数
MOV
可以移动的形式
寄存器到寄存器
内存到寄存器,寄存器到内存
立刻到寄存器,立刻到内存
绝不是内存到内存!!!
内存地址寻址可能总是以 r/m X 的形式来书写

ADD 和 SUB 加减指令
微软的x86体系中,不允许从内存到内存的传输 。源和目标不能同时出现 r/m X
sub rax, [rbx*2]视为r/m X内存寻址。去rbx*2的内存地址中取出值
Stack frame single-step 堆栈单步调试
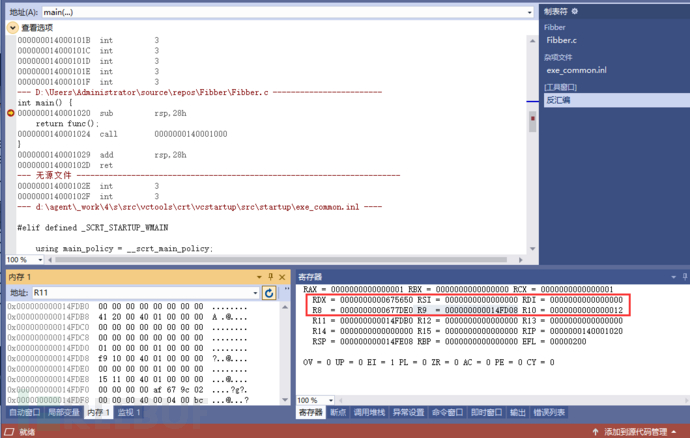
调试源码于练习材料的此处
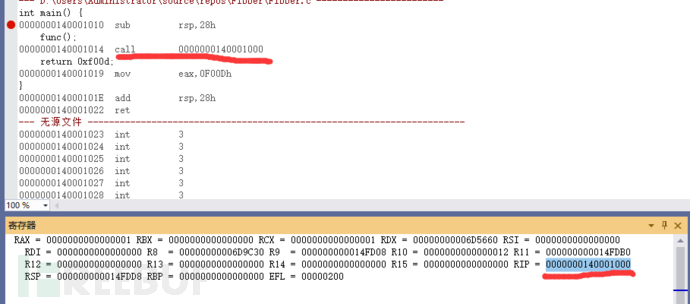
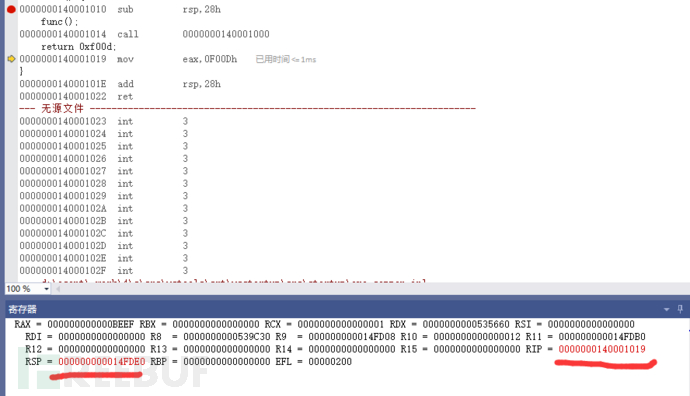
注意每一次单步调试观察寄存器与内存的变化情况,sub rsp,28h还没有执行
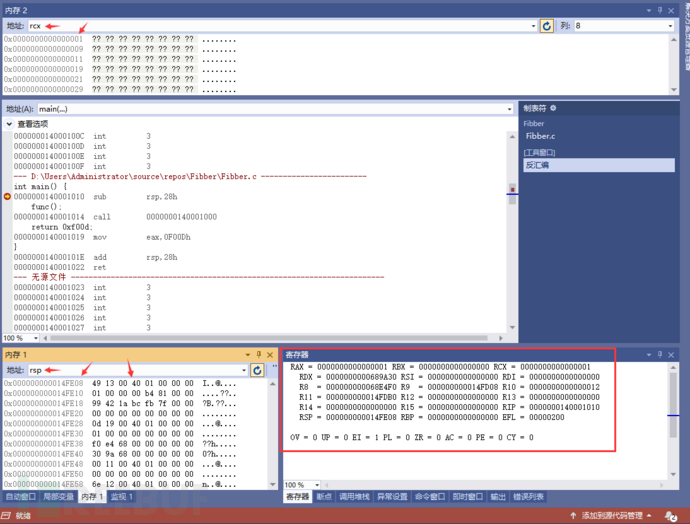
sub rsp,28h 执行完之后。我们发现rsp确实是减少28h,例外call之前,将地址值 1014压入了rip寄存器之中,这也很好理解:保存这个地址调用完了子函数之后才能找得回来嘛。但这里的rip显然是每执行一步就压入下一步内存地址的指令执行指针。还在依照约定在使用它而已。地址压入到rip是顺便,返回值保存到哪儿呢?在下一步中吗?调试继续观察即可。
rsp(FE08 - 28h = FDE0)
注意这些观察意识:每执行一步,观察寄存器,地址值的变化情况,能看见或者推测一些隐式的操作。比如它处理了内存地址到什么地方,它隐式增加了一点值到最后的显示结果中等。
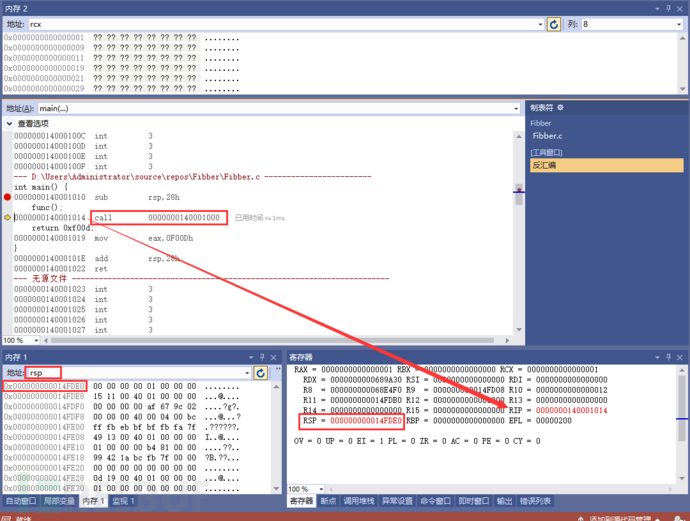
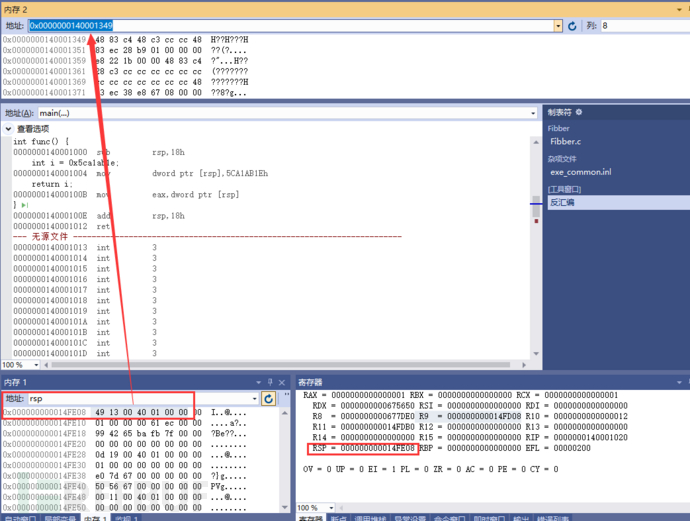
注意。观察 call 1000这个指令与RSP值的变化(FDE0 - FDD8 = 8)好家伙,rsp的值默默减了一个0x08。这在指令中可是没有的。是基于观察得到的。它为啥这么干?看看此刻rsp中的值是啥就知道了。原来它这么偷偷的做,是为了保存下一条指令的地址值进来啊。
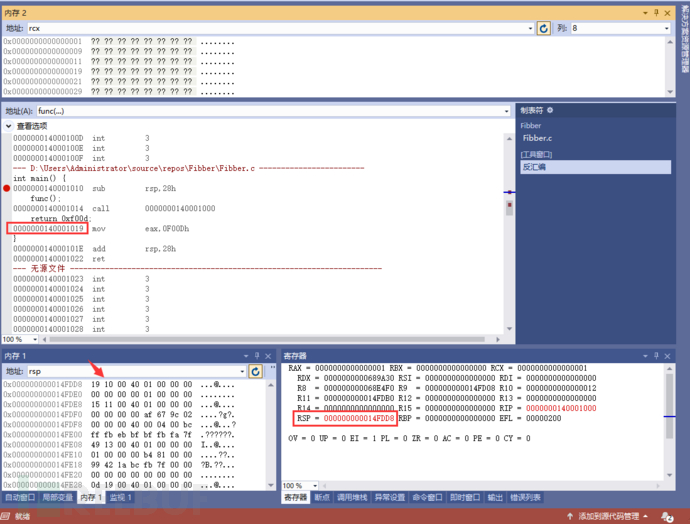
mov eax,0BEEFh 指令,这个观察很简单。自己看看就懂了。
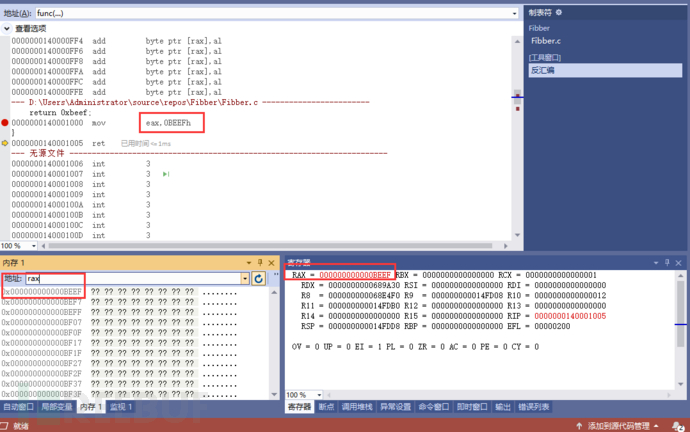
ret
默认返回到rsp FDD8地址中的值1019后,rsp 隐式的默认加了一个 0x08 给它还原回去了。
此刻rsp内存地址中的值也重置为 01`00000000 了
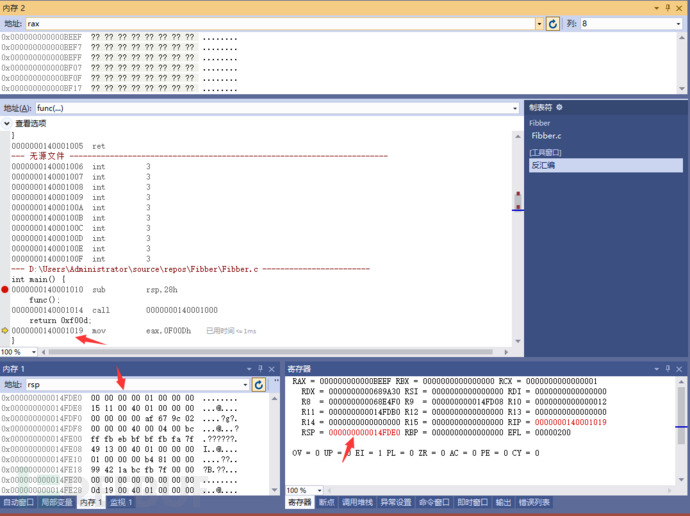
mov eax,0F00Dh 这个也非常简单,自己看看吧。rax地址里的值未定义。mov 覆盖的是rax的地址值
因为这个eax,是32位的。把0F00Dh值放进去,其他地方用的是0填充。这仅适用于写入寄存器,不适用于内存 。
如果将 32 位值写入64 位内存位置,仍然只有 32 位会被更改。 没有0填充的情况。
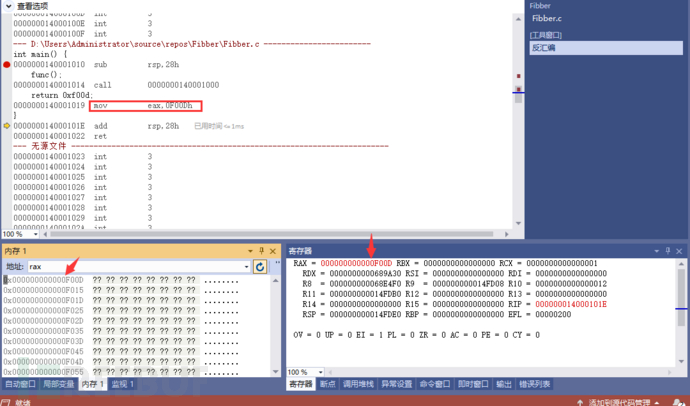
add rsp,28h 观察变化值,跟踪内存地址值中具体保存的值,都观察的非常清楚了。
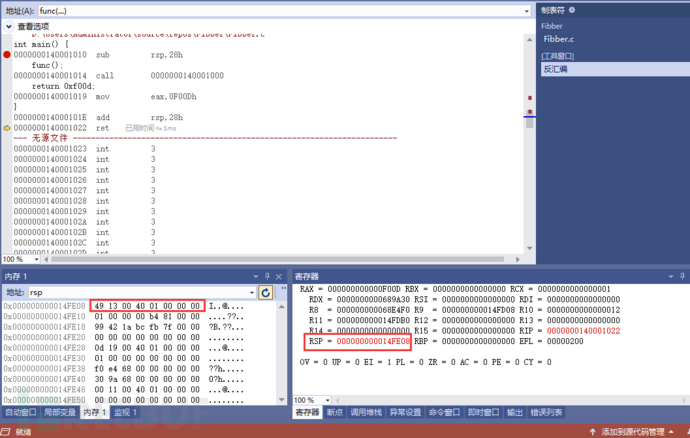
ret 整个主文件都调试完了。它都跳出文件本身,到调用main函数的文件中去了。运行main函数时将invoke_main()函数的地址压入到rsp中,于是才调用的main函数,才有了main的堆栈空间。
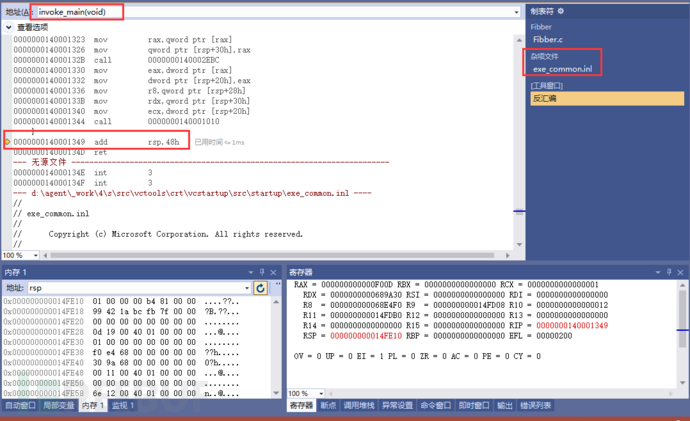
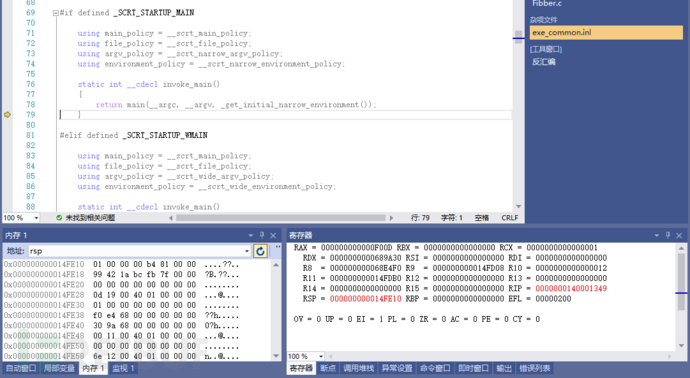
因为这些硬编码的返回值都没有具体做什么事情,所以在编译器中打开优化功能时,它们将被删除,不利于学习。因为这些过程确实存在,但编译器将这些东西处理掉,导致我们以为没这些。但是编译器毕竟不是人,它也会出现,它自以为没用可实际却真的有用的情况时,误判与误删就发生了。
总结一下上面的情况
为什么GCC/Clang 有PUSH/POP指令,VS code却没有?
main() 中的 sub/add 0x28 是怎么回事?
调试代码与画堆栈图
调试源码如下
开始前观察一下这些寄存器的初始值什么情况。大部分地址里面的值都是0或者未定义或者没发现有什么含义。但是观察到了rsp地址中的值有它的含义。
前面说过,这是调用main函数时,invoke_main()函数的返回地址。在调用main()函数之前,先把返回地址保存到RSP中。
这里要分配0x28个空间地址了,sub rsp,28 堆栈向低地址增长28。rsp保存的又是返回地址的值。如果现在减少28,返回地址又没有转移到其他地方保存。如何返回? add rsp,28h很好的回答了这件事情。此时,rsp地址里面的值还处于未定义。
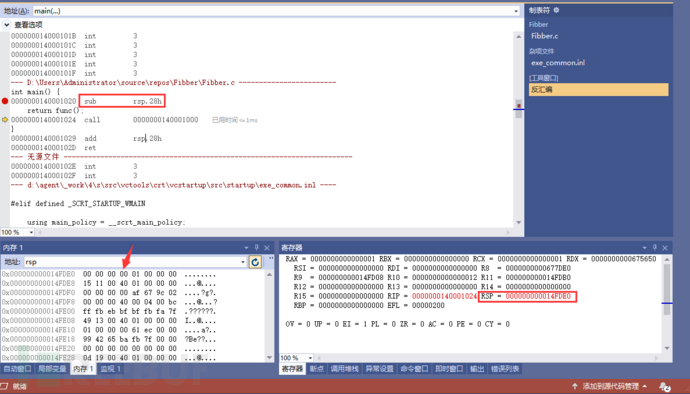
执行完call指令来到到func函数入口点。rsp此刻的地址值,又保存了一个值进去。而我们画的图已经是这样的了。后面的观察是一样的,请大家自己完成。停止处的箭头是还没有执行的指令。因此这个rsp的变化是在main()中发生的。
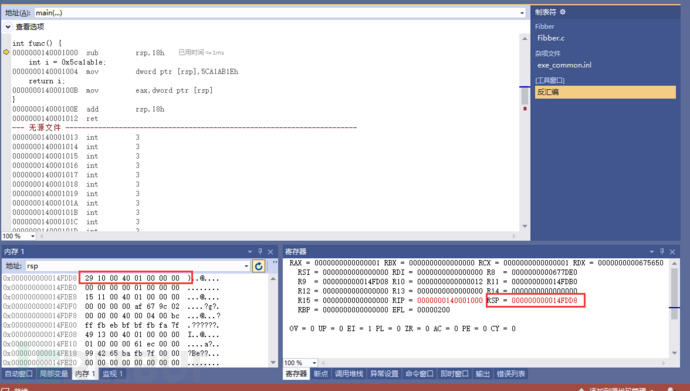

word前面讲过是16bit时代的叫法。dword就是32bit,所以放入到低位32bit的eax中。

4个字节(32位)的值移动到64位内存中,可以发现没有任何填充行为,只是覆盖了低位的32bit
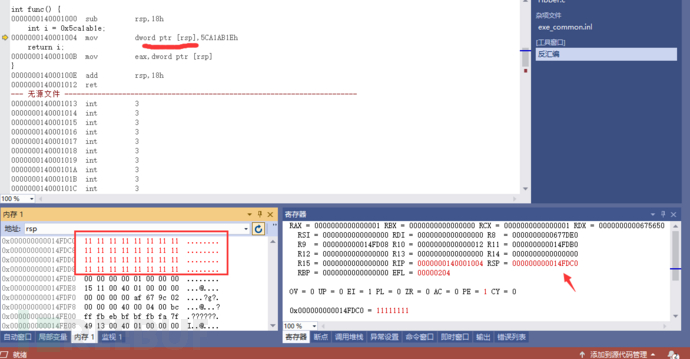
前面说过,微软是小端法,8bit位一个整体:放进去,取出来。这不是局部变量的 i 的值吗?所以说局部变量在堆栈中。当调用完之后,sub add rsp重置了堆栈,外面的代码就找不到局部变量的rsp内存地址了。
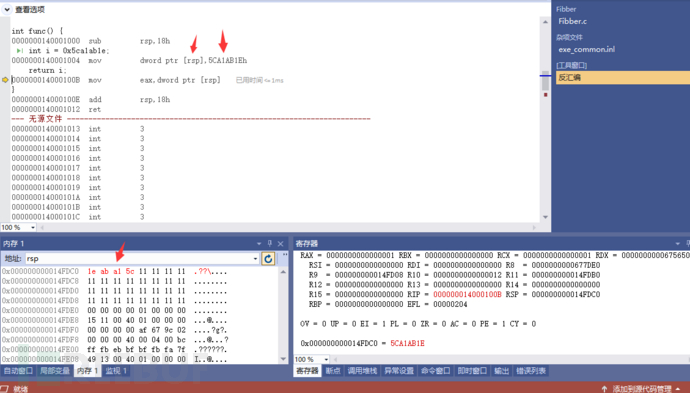
画类似这样的堆栈图
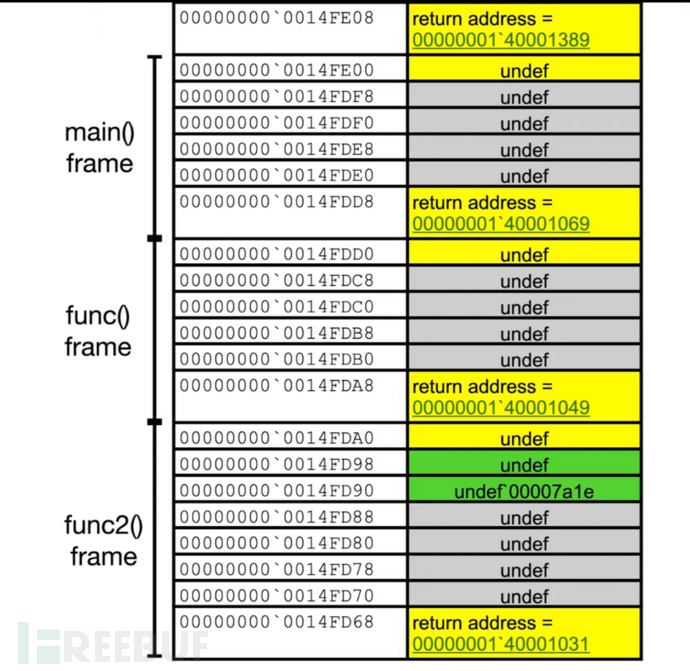
关于堆栈分配 sub rsp,18h 28h 38h的扩展阅读。这里不展开讲。是为了地址尾数为0的对齐的16字节填充。
https://docs.microsoft.com/en-us/cpp/build/stack-usage?view=msvc-160
走到这里。最重要的观察点,意识思维的推敲点都已经出来了。剩下了来的事情就是自己继续跟下去学,好好考虑一下未来的方向。是否现在就定位,还是多等一些时间让自己的认知全一点再来定方向。
总结
总而言之:那些值不是代表地址本身,就是代表地址里面的具体的值。
每执行一步,观察一步:观察寄存器中地址值的变化,内存中继续观察寄存器地址值保存的值是什么。
画堆栈图。
基于以上的方式来整体学习反汇编,您会发现中间存在很多隐式的操作以及一些无法理解的情况出现。
这个时候就需要翻阅微软手册和微软官方的解释来多处借鉴才能推测。
逆向与反汇编需要长时间的积累,没有什么速成。技巧与方法并不能取代日常性的阅读和练习。
以上教程仅仅只是开始,不能将它视为一劳永逸的良方。
感谢师傅们很有耐心的阅读到了这里。
我们还会再见面的。
共勉。
已在FreeBuf发表 0 篇文章
如需授权、对文章有疑问或需删除稿件,请联系 FreeBuf 客服小蜜蜂(微信:freebee1024)
- 0 文章数
- 0 关注者