


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

- 关注
在Web2.0的时代下,图像、视频等各类异构数据每天都在以惊人的速度增长。如何在茫茫图库中方便、快速、准确地找到所需图像?你是否还在为如何检索到真正想要获取的图像的关键字而苦苦烦恼?你是否发现目前基于文本描述的图像搜索结果在大规模图像中结果往往差强人意?
追根溯源,这是由于基于文本的图像检索在外来的图像入库时离不开人工的干预。文本描述的特征依赖于人工标注的介入,导致图库受到标注者的认知水平、言语使用以及主观判断等的影响,造成图像的文字描述存在差异。同时,标注费时费力,这类方法并不适用于海量图像库的检索。
背景介绍
针对这一系列问题,基于内容的图像检索(CBIR,Content Based Image Retrieval)充分发挥了计算机擅长于处理重复任务的优势。它能够根据用户给定的查询图像,提取有效图像视觉特征,衡量图像之间的相似性,并从一个大规模数据库中快速找到与给定图像内容相关或相似的图像,并按相关的排序返回给用户,将人们从耗费大量人力、物力和财力的人工标注中解放出来。
目前,基于内容的图像检索技术已经深入到了许许多多的领域,在电子商务、皮革布料、版权保护、医疗诊断、公共安全、街景地图等工业领域得以成功应用,为人们的生活生产提供了极大的便利。
本文从图像检索流程出发,结合网易易盾团队在数字风控“内容安全”中的实践经验,介绍构建基于内容的图像检索系统所涉及的一些典型算法。
检索系统的搭建
一个典型的基于内容的图像检索基本框架如图1所示,整个框架分为2大部分:offline离线部分以及online在线部分。
offline部分主要包括了检索图像库、特征提取、特征库以及检索结构。
检索图像库:一个用于存放待查询的图像数据库。在实际项目中,这个检索图像库是一个动态变化的图像数据库。
特征提取:图像特征的表达能力即利用计算机提取图像中属于特征性的信息的方法及过程。图像的任何统计量都可以作为图像的特征,哪怕是图像本身的像素信息。在实际项目中,我们通常使用如颜色、结构等传统视觉特征和基于深度学习的底层/中层/高层语义特征作为图像特征。
特征库:用于存放需要查询的图像库中提取的图像特征。
构建索引结构:这一步骤的目的就是对高维度特征的检索性能进行优化。虽然直接采用暴力检索一一比对这样的方法检索的精度是最高的,但代价是检索的时间也是最长的,为了在检索精度和检索速度之间找到一个平衡点,因此常见的方法有查找优化以及向量优化。在实际业务中,也常常采用两种方式相结合的方法。
online部分主要是完成对query图像的特征提取操作,在这一步操作中,值得注意的是,特征提取方法需要和offline中相保持一致。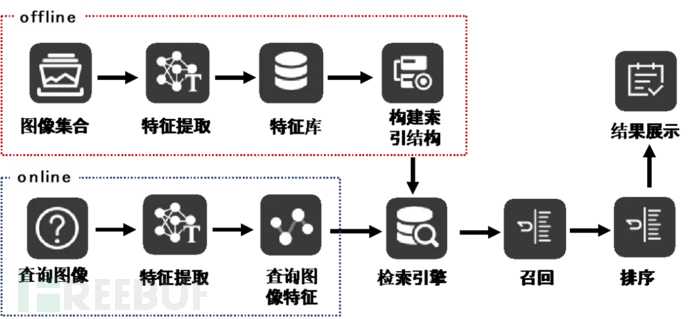
图1 | 基于内容的图像检索基本框架
从上图可以看出,图像特征提取是整个检索系统的基础,检索结构的设置是整个检索系统性能的关键。下面就对这两部分进行详细介绍。
01 特征提取
从图1可以清晰地看出,检索系统的性能在很大程度上依赖于特征提取方法。理想情况下,特征提取方法应具有识别能力强、鲁棒性好、特征维度低三个特点,图2给出了特征提取算法在鲁棒性方面的示例效果。
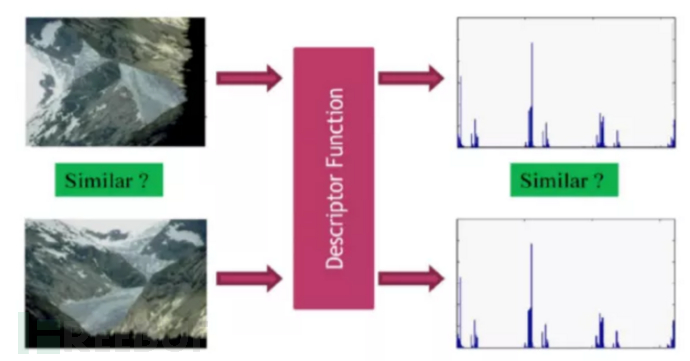
图2 | 特征提取算法在鲁棒性方面的示例效果
但在实际情况下,由于计算机所“看到”的图像像素层面表达的低层次信息与人所理解的图像多维度高层次信息内容之间有很大的差距,因此如何准确、高效、精准地提取图像特征是我们所要做的工作。从提取的方式上来看特征提取算法,大致可以分为(1)基于手工设计的传统视觉特征;(2)基于CNN(卷积神经网络)的深度视觉特征这两类,如图3所示。
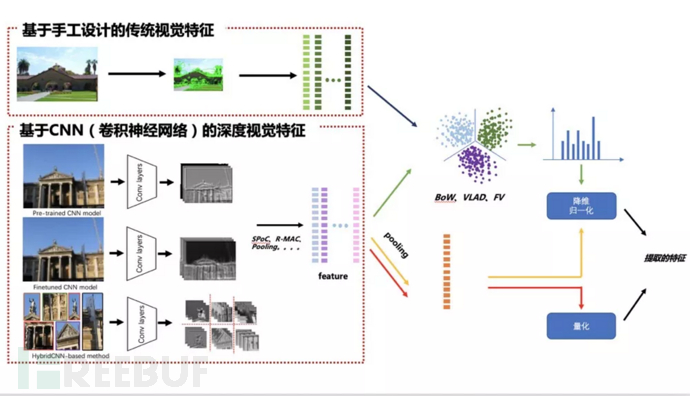
图3 | 特征提取方法
1.1 基于手工设计的传统视觉特征
传统的视觉特征在发展早期主要是利用颜色、纹理、形状、结构特征等全局特征,这些特征计算简单、表示直观,但这些特征往往因维度较高使得其计算量较大,同时这些全局图像特征易受图像中的光照条件、位移、遮挡、截断等因素影响。随后更细致的局部特征描述逐步出现,例如经典的SIFT(ScaleInvariant Feature Transform)、SURF、ORB、BRISK等。这类算法相对简单,无需学习与训练,仅需简单计算与统计,也有较好的稳定性,对旋转、尺度缩放、亮度变化有较好的稳定性,不易受视角变化、仿射变换、噪声的干扰[1],但由于这类特征极大程度上依赖于人为的设计,因此有时候并不能准确地表征图像特征,进而对检索性能造成一定影响。
1.2 基于CNN(卷积神经网络)的深度视觉特征
由于手工设计的传统视觉特征其表示能力有限,检索性能也往往面临很大的局限性。2014年后,以卷积神经网络为代表的深度学习逐渐替代了传统手工特征的检测与描述方法,各类CNN模型层出不穷,如AlexNet、VGGNet、GoogleNet、RetinaNet、ResNet等。神经网络的深层级具有较强语义信息;浅层级特征中保存了包含图像边缘、纹理、颜色等信息。这类方法主要分为:(1)Pre-trained CNN model;(2)Finetuned CNN model;(3)Hybrid CNN-based method[2]。
方法一:Pre-trained CNN model
在Pre-trained CNN model中,常见的做法有2种:
(1)直接使用全连接层作为全局特征描述作为单张图像的特征。这是一种最直接,也是最简单快捷方便的想法。首先FC层的输出可以看成是一种天然的向量形式,因此可以直接作为图像的特征向量,其次,FC层的输出实际上是对图像整体语义的表示,具有全局表示性,因此可以被视作是一种图像的全局特征。通过实验也表明其在能产生较好的检索精度,若使用指数归一化也可提高检索精度。
(2)使用卷积层特征作为单张图像的特征。由于FC层本质上是其中的每一个神经元都和前一层所有神经元相连接,这使得提取的特征在一定程度上丢失了空间信息,同时对于如裁剪、遮挡等变换的鲁棒性也会降低。而卷积层由于其仅仅与输入的feature map中的局部区域相关联,确保了提取的特征中包含了更多的局部特征,鲁棒性更强,因此提出了使用卷积层代替全连接层,实验表明从不同层提取的特征表现出不同的检索性能,高层网络的泛化能力要低于较低层的网络。
这类方法通常是使用一个现成开源分类识别模型作为一个特征提取器。这些开源模型通常会在ImageNet上这类数据集较大的数据上进行训练,而当实际业务数据与ImageNet数据分布差异过大时,模型提取的特征不一定非常适合图像检索任务,因此。源域和目标域之间的重叠程度在检索中起着至关重要的作用。
方法二:Finetuned CNN model
为了使模型具有更高的可扩展性和更有效的检索,可以采用finetuned CNN model的方法,根据具体场景的特点大致可以分为如下2种方法:(1)监督学习方法;(2)无监督学习方法。
(1)基于有监督学习finetune模型
当有足够的充足的有标签业务数据时,基于有监督学习的方法来进行finetune模型是一个不错的选择。图4给出了方法的部分示例网络结构。这类方法主要分为2种[3]:
一是,基于纯分类模型进行finetune。这类方法的思想很简单,即在新的数据上对分类模型进行重新训练,这类方法虽然在一定程度上拉近了源域和目标域之间的距离,但这类方法存在一个问题:对于学习区分特定物体的类内之间的差异能力不强。
二是,基于分类+度量学习(metric learning)进行finetune。这类方法是在上述方法上进行了改进,通过引入度量学习旨在学习一种低维空间,在这个空间内将同类样本之间的距离拉近,异类样本之间的距离拉远。这种方法既关注了类间样本,也关注了类内样本。这类方法从网络结构的形式上大致可以分为基于Siamese网络[4]和基于triplet networks[5]网络,两者最大的区别就在于输入图像对的组成情况,前者输入图像是由正或负样对组成,如图4(b)、(c)所示,后者则是anchor图像与相似和不相似的样本配对,如图4(d)、(e)、(f)所示。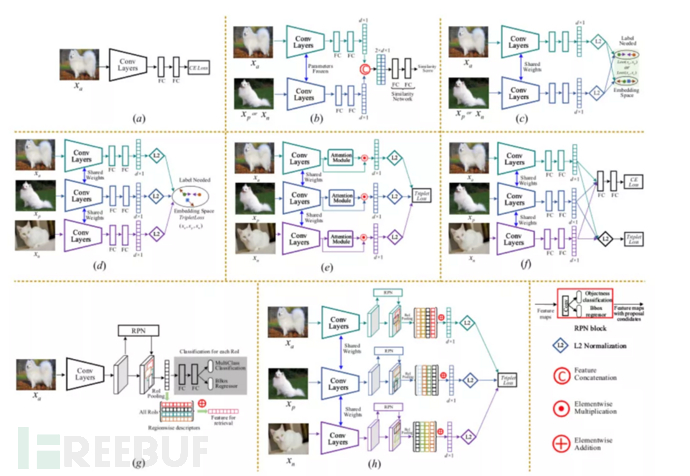
图4 | 基于有监督学习finetune模型
(2)基于无监督学习finetune模型
但在实际业务中,千万级数据的标注任务就显得不现实,既费时又费力,同时成本高。基于上述种种限制,基于无监督学习的方法应运而生。该方向目前存在以下2个主要的分支:
分支一,流形学习(Manifold learning)+度量学习。这类方法[6]主要是通过流形学习来挖掘图像在流形空间上的相似性,进而选择相对应的正负样本进行度量学习。这类方法与前述基于分类+度量学习进行finetune方法最大的不同就在于,该方法的正负样本选择是通过流形学习,而非根据给定的有监督的标签信息。
分支二,基于AutoEncoder的无监督框架。这类方法[7]利用输入图像本身作为输出结果标签,通过编码器对输入图片进行编码,然后利用解码器将编码后的特征尽可能重建原始输入图像。在提取图像特征时,只需要将图像输入编码器即可,另外由于编码器输出的特征维度往往较低,这也达到一个降维的效果。这类方法本质上是通过一种非线性的变换函数完成特征提取。
方法三:Hybrid CNN-based method
前面的2种方法都只将图像输入到网络中一次来获取描述符,目前也有一些是将图像多次输入到网络中,基于局部表示聚合的方法先设法从输入图像中提取一系列的局部区域,之后分别将这些局部区域前馈网络生成对应的局部表示,最后通过特定编码方法将这些局部表示聚合为最终表示,这类方法的弊端在于需要前馈网络多次。
02 特征增强
在检索过程中,图像特征的表达能力在一定程度上决定检索性能的优劣,因此在提取特征图像特征后,往往为了获得更强可辨识性的特征,通常会采用图像聚合、嵌入映射、特征融合的方式。
2.1 特征聚合
当提取的特征是从卷积层输出时,通常获得一个H*W*C的特征,利用池化(pooling)操作可以在某种程度上实现特征的聚合,从而提高特征的表达能力。sum/average pooling和max pooling是两种常用的特征聚合手段(如图7中的MAC方法),sum/average pooling 考虑了卷积层的所有激活输出,削弱了高度激活特征的影响,而max pooling特别适用于稀疏特征,这两种聚合特征可以认为是当前feature map的全局特征。除上述方法之外,在pooling操作之前引入其他的一些操作,如构建Spatial权重和Channel权重(CroW方法[8])、对feature map某一块区域进行pooling操作(R-MAC[9])等方式提高感兴趣区域特征信息或引入局部特征信息来提高特征的表达能力。
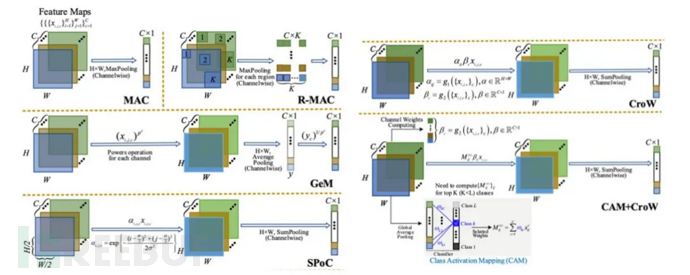
图5 | 特征聚合
2.2 嵌入映射
除上述操作之外,还可以将特征嵌入到高维空间中以获得紧凑的特征,尤其是当提取的特征为局部特征(如SIFT)时,我们就需要对局部特征进行聚合,作为图像的全局表示。目前常见的方法有VLAD[10]、BoW[11]、FisherVector(FV)[12]等等。
2.3 特征融合
发展至今,特征融合的方法多种多样,主要可以分为以下两种:(1)单模型层级融合;(2)模型级融合。
在单模型层级融合中,考虑到同一个模型的不同feature map所关注的图像特征不同,融合不同层的特征可以充分利用高层语义特征和低层细节特征,这样可以在度量语义相似度时进行相互补充,在一定程度上保证了检索的性能。
众所周知,在相同数据集上对不同模型进行训练,模型的特征提取能力不尽相同,既然如此,如果可以找到一种方式来充分发挥各个模型之间的优势,是不是有利于提高检索的性能?毋庸置疑,答案是肯定。
对于这两种融合策略,关键问题是什么特征是最好的组合?在现有的深度模型的基础上,已经对回答这个问题进行了一些探索[13][14]。
除深度特征之间融合之外,我们在实际业务中尝试发现将CNN特征与传统的特征相互补充,相辅相成,也可以实现更为精准、更为全面的图像检索特征。
上述三大类特征增强的方法,每种方式的侧重点不同,因此具体使用哪一种或哪几种方法视每个业务的情况而定。
03 构建结构索引
影响整个检索系统性能除图像的特征表达能力之外就是检索过程了。整个检索过程中最核心的是计算两个特征向量之间的相似性后进行排序,获得查询结果。这时候能想到最简单粗暴方法就是暴力(brute-force)搜索方法:通过与查询库中特征向量对标,一一计算相似性并排序,这种方法实现起来相对容易、检索精度高,但在大规模图像库上,这种搜索的方式并不友好,主要存在如下问题:
一是,内存占用过大:虽然提取的特征已经比直接保存图像小了很多,但当数据量仍然庞大,这些向量的存储成为一个大问题。
二是,响应时间过长:消耗巨大的计算资源,且单次查询的响应时间会随样本数目N成线性增长。
因此,为了在实际业务中落地,就必须在尽可能保持搜索精度的前提下,降低搜索空间的空间复杂度与时间复杂度。通常采用构建索引的方法将暴力匹配(精确搜索)转化为近似搜索来近一步提升搜索速度、节省内存占用空间。业内也提出了不少检索算法,虽然应对不同数据维度和分布有不同算法,其核心思想可归为3大类:
(1)空间划分法。这类方法的核心是将检索的数据集所在的特征空间分成多个子空间,把“挨得近”的数据点放在同一个子空间中,这样在检索时可以快速定位到这些子空间,减少需扫描的数据量的个数,提高检索的速度。常用的算法有KD-Tree[15]、聚类检索等,但这类算法对于高维特征,如维度达到几百时,这类算法的性能会急剧下降。
(2)空间编码和转换法。这类算法可以看作是一种对特征的编码操作,实现将高维空间数据映射到低维空间,实现数据的压缩,进而减少扫描的数据点的计算量。ProductQuantization(PQ)算法[16]就是其中一个典型代表。
(3)邻居图法。以HNSW[17]为代表,这类算法有一个重要的前提:认为邻居的邻居仍为邻居。整个算法核心是基于图结构完成整个检索,首先根据特征库中所有特征预先构建一张关系图,检索时直接在关系图上进行游走遍历,最终获得检索结果。这类方法速度快、精度高,但临界点存储浪费内存,增加存储空间的开销。
结语
本文从基于内容的图像检索基本框架出发,结合内容安全业务的实际特点,重点介绍了“特征检索”最重要的两大部分:图像特征的表达能力以及检索结构的设计,其中图像特征的表达能力是整个检索系统的基础,而检索结构的设计则是决定整个检索系统性能的关键。
进化后的图像检索技术,助力平台“以图找图”,将图像风险特征提取出来,从图片海洋中快速打捞同一类违规内容,有效管控内容生态。
【参考文献】
[1] Dubey S R. A decade survey of content based image retrieval using deep learning[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2021.
[2] Zheng L, Yang Y, Tian Q. SIFT meets CNN: A decade survey of instance retrieval[J]. IEEE transactions on pattern analysis and machine intelligence, 2017, 40(5): 1224-1244.
[3] Wan J, Wang D, Hoi S C H, et al. Deep learning for content-based image retrieval: A comprehensive study[C]//Proceedings of the 22nd ACM international conference on Multimedia. 2014: 157-166.
[4] Chopra S, Hadsell R, LeCun Y. Learning a similarity metric discriminatively, with application to face verification[C]//2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR'05). IEEE, 2005, 1: 539-546.
[5] Wang J, Song Y, Leung T, et al. Learning fine-grained image similarity with deep ranking[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2014: 1386-1393.
[6] Donoser M, Bischof H. Diffusion processes for retrieval revisited[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2013: 1320-1327.
[7] Krizhevsky A, Hinton G E. Using very deep autoencoders for content-based image retrieval[C]//ESANN. 2011, 1: 2.
[8] Kalantidis Y, Mellina C, Osindero S. Cross-dimensional weighting for aggregated deep convolutional features[C]//European conference on computer vision. Springer, Cham, 2016: 685-701.
[9] Tolias G, Sicre R, Jégou H. Particular object retrieval with integral max-pooling of CNN activations[J]. arXiv preprint arXiv:1511.05879, 2015.
[10] Jégou H, Douze M, Schmid C, et al. Aggregating local descriptors into a compact image representation[C]//2010 IEEE computer society conference on computer vision and pattern recognition. IEEE, 2010: 3304-3311.
[11] Sivic J, Zisserman A. Video Google: A text retrieval approach to object matching in videos[C]//Computer Vision, IEEE International Conference on. IEEE Computer Society, 2003, 3: 1470-1470.
[12]Jaakkola T S, Haussler D. Exploiting generative models in discriminative classifiers[J]. Advances in neural information processing systems, 1999: 487-493.
[13] Xuan H, Souvenir R, Pless R. Deep randomized ensembles for metric learning[C]//Proceedings of the European Conference on Computer Vision (ECCV). 2018: 723-734.
[14] Chen B C, Davis L S, Lim S N. An analysis of object embeddings for image retrieval[J]. arXiv preprint arXiv:1905.11903, 2019.
[15] Bentley J L. Multidimensional binary search trees used for associative searching[J]. Communications of the ACM, 1975, 18(9): 509-517.
[16] Jegou H, Douze M, Schmid C. Product quantization for nearest search[J]. IEEE transactions on pattern analysis and machine intelligence, 2010, 33(1): 117-128.
[17] Malkov Y A, Yashunin D A. Efficient and robust approximate nearest search using hierarchical navigable small world graphs[J]. IEEE transactions on pattern analysis and machine intelligence, 2018, 42(4): 824-836
- 0 文章数
- 0 关注者