


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

FreeBuf快速同步语雀文章
 r0bepr
r0bepr- 关注
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
FreeBuf快速同步语雀文章
1. 背景
日常笔记使用语雀记录文章,想要快速同步内容至FreeBuf,寻找已有工具无果,遂写了个工具方便快速同步文章。
2. 工具
# coding=utf-8
import re
import requests
from urllib.parse import urlparse
import os
import urllib3
import time
import random
from requests.adapters import HTTPAdapter
from requests.packages.urllib3.util.ssl_ import create_urllib3_context
# 禁用所有 SSL 相关的警告
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
class JA3Adapter(HTTPAdapter):
"""
自定义 HTTPAdapter 用于随机化 JA3 指纹
"""
def init_poolmanager(self, *args, **kwargs):
context = create_urllib3_context()
# 随机化 TLS 指纹
context.set_ciphers(':'.join([
'ECDHE-ECDSA-AES128-GCM-SHA256',
'ECDHE-RSA-AES128-GCM-SHA256',
'ECDHE-ECDSA-AES256-GCM-SHA384',
'ECDHE-RSA-AES256-GCM-SHA384',
'ECDHE-ECDSA-CHACHA20-POLY1305',
'ECDHE-RSA-CHACHA20-POLY1305',
'DHE-RSA-AES128-GCM-SHA256',
'DHE-RSA-AES256-GCM-SHA384',
]))
kwargs['ssl_context'] = context
return super().init_poolmanager(*args, **kwargs)
def upload_img(img_file):
"""
上传图片到指定服务器
"""
up_url = 'https://www.freebuf.com/fapi/frontend/upload/image'
auth = "Bearer eyJhbGc"
headers = {
"Accept": "application/json, text/plain, */*",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.0 Safari/537.36",
"X-Client-Type": "web",
"Origin": "https://www.freebuf.com",
"Sec-Fetch-Site": "same-origin",
"Sec-Fetch-Mode": "cors",
"Sec-Fetch-Dest": "empty",
"Referer": "https://www.freebuf.com/write",
"Accept-Encoding": "gzip, deflate",
"Accept-Language": "zh-CN,zh;q=0.9",
"Authorization": auth
}
# 使用自定义 JA3Adapter
session = requests.Session()
session.mount('https://', JA3Adapter())
try:
with open(img_file, 'rb') as file:
files = {'file': file}
response = session.post(up_url, headers=headers, verify=False, files=files)
response.raise_for_status() # 检查请求是否成功
print(f"已完成图片 {img_file} 的上传")
return response.json().get('data').get('url')
except Exception as e:
print(f"上传图片 {img_file} 失败: {e}")
return None
def replace_img(img_url):
"""
下载图片并上传到服务器
"""
try:
# 使用自定义 JA3Adapter
session = requests.Session()
session.mount('https://', JA3Adapter())
response = session.get(img_url, verify=False)
response.raise_for_status() # 检查请求是否成功
file_name = get_file_name(img_url)
file_all_name = os.path.join("./files", file_name)
os.makedirs("./files", exist_ok=True) # 确保目录存在
with open(file_all_name, 'wb') as file:
for chunk in response.iter_content(chunk_size=8192): # 每次读取 8 KB 数据
file.write(chunk)
print(f"文件 {file_all_name} 已完成下载")
return upload_img(file_all_name)
except Exception as e:
print(f"下载或上传图片失败: {e}")
return None
def get_file_name(img_url):
"""
从 URL 中提取文件名
"""
parsed_url = urlparse(img_url)
return os.path.basename(parsed_url.path)
def replace_md(md_file):
"""
替换 Markdown 文件中的图片链接
"""
try:
with open(md_file, 'r', encoding='utf-8') as f:
content = f.read()
urls = re.findall(r'https://cdn.nlark.com/yuque[\w/-]+.png', content)
for url in urls:
time.sleep(1) # 配置延时避免速率太快被拦截
replace_url = replace_img(url)
if replace_url:
content = re.sub(re.escape(url), replace_url, content)
output_file = md_file + '_modify.md'
with open(output_file, 'w', encoding='utf-8') as fo:
fo.write(content)
print(f"已完成图片上传,复制新 md 内容至 freebuf 即可: {output_file}")
except Exception as e:
print(f"处理 Markdown 文件失败: {e}")
if __name__ == "__main__":
# 配置 markdown 文件名
replace_md('upload.md')
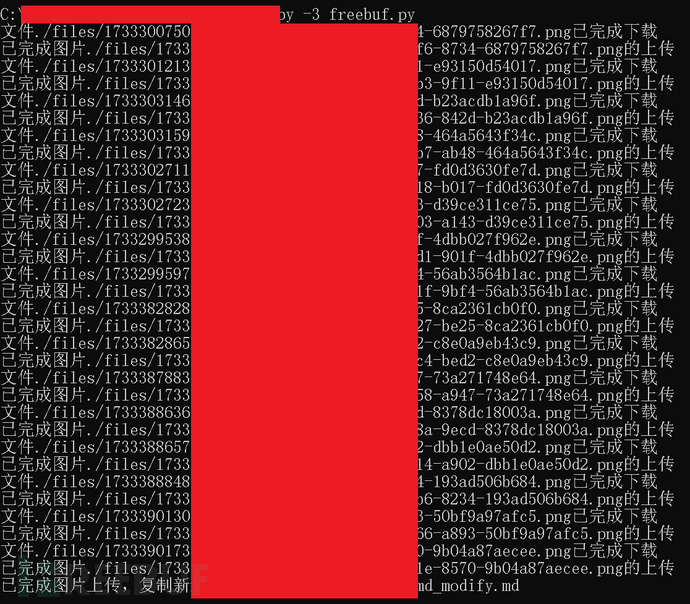
3.开发思路
1.对语雀到处markdown文件进行分析,发现语雀文档内容缓存在cdn.nlark.com。直接粘贴至freebuf的markdown编辑器不解析图片。于是怀疑对域名做了过滤。
2.因此想的是,只需要把链接替换成freebuf地址或者其他存储桐即可。这里由于存储桶需要另外花钱,因此pass。于是开始分析FreeBuf上传接口。任意上传一张图片并且抓包
功能点:
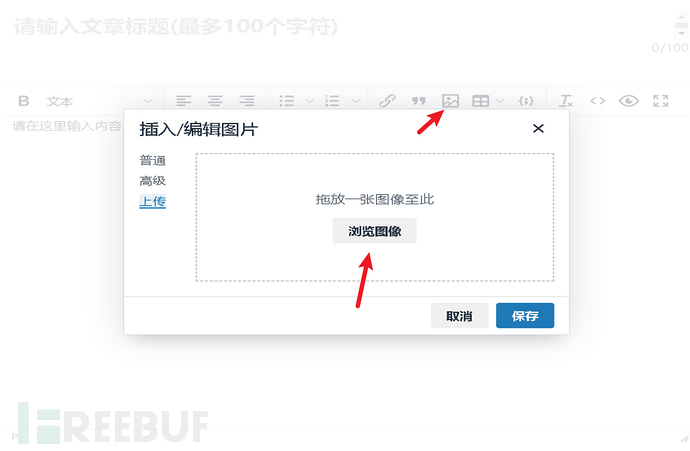
请求包:
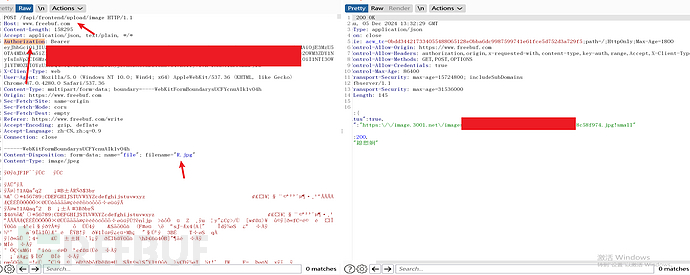
3.经过分析得出,上传认证只需要Authorization即可,利用该接口即可把本地图片传到云端。故而脚本开发流程如下:
- 正则匹配md内语雀资源url获取url列表
- 依次下载url资源至本地并且命名不变
- 使用FreeBuf上传接口依次上传图片,并且抓取返回的新url(这里暂时叫做new_url)
- 依次替换md中的url为new_url并且报错内容为xx_modify.md。
4.使用过程
1.语雀选择文章,点击导出Markdown格式
2.生产后把md文件放到freebuf.py同一个目录。并且本地创建一个files目录
3.配置py脚本,需要配置
auth="Bearer" #登录freebuf后,F12打开浏览器NETWORK并刷新,点击请求包即可获取请求头部参数。
replaceMd('upload.md')
4.python3 freebuf.py生成新的xx_modify.md文件,并且把新生成的md文件粘贴复制进入FreeBuf markdown编辑器即可。
备注
有的人可能文档资源在本地,也可以在该脚本基础上删除下载资源函数,并且修改正则匹配方法,即可获得本地上传脚本,这里就不多赘述了。
免责声明
1.一般免责声明:本文所提供的技术信息仅供参考,不构成任何专业建议。读者应根据自身情况谨慎使用且应遵守《中华人民共和国网络安全法》,作者及发布平台不对因使用本文信息而导致的任何直接或间接责任或损失负责。
2. 适用性声明:文中技术内容可能不适用于所有情况或系统,在实际应用前请充分测试和评估。若因使用不当造成的任何问题,相关方不承担责任。
3. 更新声明:技术发展迅速,文章内容可能存在滞后性。读者需自行判断信息的时效性,因依据过时内容产生的后果,作者及发布平台不承担责任。
本文为 r0bepr 独立观点,未经授权禁止转载。
如需授权、对文章有疑问或需删除稿件,请联系 FreeBuf 客服小蜜蜂(微信:freebee1024)
如需授权、对文章有疑问或需删除稿件,请联系 FreeBuf 客服小蜜蜂(微信:freebee1024)
被以下专辑收录,发现更多精彩内容
+ 收入我的专辑
+ 加入我的收藏
相关推荐





r0bepr LV.1
这家伙太懒了,还未填写个人描述!
- 7 文章数
- 6 关注者
学习SOAR从W5开始
2025-03-06
学习SOAR | w5进阶学习
2025-03-06
跟着白帽学习fake captcha
2025-03-06