


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

 Padishah
Padishah- 关注
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
 本文由
Padishah 创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
本文由
Padishah 创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
概述
SecretScraper是一个网络爬虫及敏感信息泄露检测工具,通过DOM结构和正则两种方式从Web响应中提取URL,并用正则检测响应中的敏感信息,支持Hyperscan模式以提高正则匹配效率。
Repo地址:https://github.com/PadishahIII/SecretScraper
联系作者:350717997@qq.com
运行流程如下: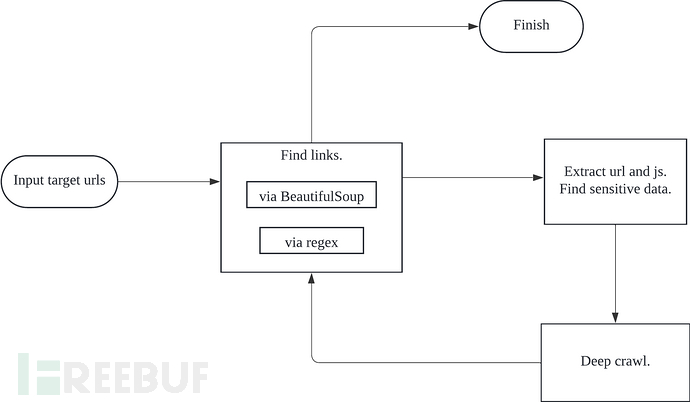
特性
SecretScraper是一个高度可配置的网络抓取工具,可以抓取链接,提取目标网站的子域,并使用正则表达式查找敏感数据。SecretScraper的功能包括:
网络爬虫:通过DOM层次结构和正则表达式提取链接
支持域名白名单和黑名单
支持多个目标,从文件中输入目标URL
支持本地文件扫描
可定制性强:请求头, 代理, 超时, cookie, 抓取深度, 跟随重定向等
内置正则表达式搜索敏感信息,并支持自定义正则
Yaml格式配置文件
以CSV格式保存结果
运行环境
操作系统:在MacOS、Ubuntu和Windows上测试通过。
Python版本 >= 3.9
安装及使用
安装
pip install secretscraper
升级
pip install --upgrade secretscraper
基本使用
单目标:
secretscraper -u https://scrapeme.live/shop/
多目标:
secretscraper -f urls
http://scrapeme.live/1
http://scrapeme.live/2
http://scrapeme.live/3
http://scrapeme.live/4
http://scrapeme.live/1
配置文件:secretscraper会从当前文件夹寻找settings.yml,如果没有找到,则自动生成。
输出示例: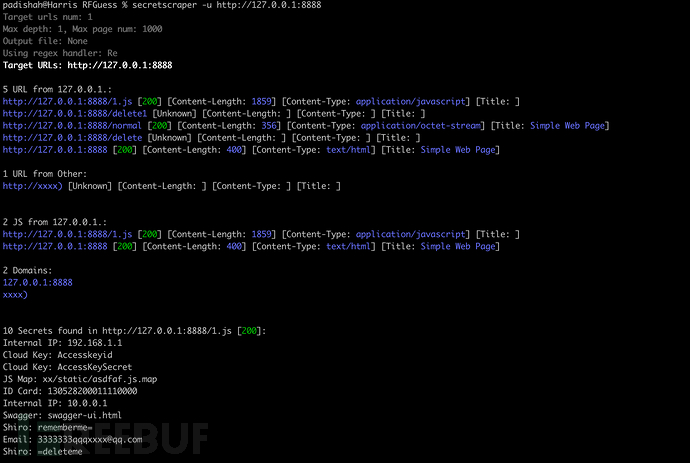
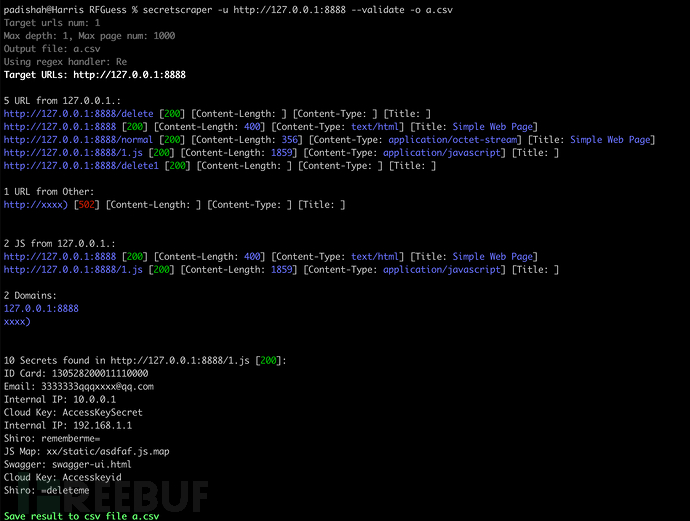
运行选项:
> secretscraper --help
Usage: secretscraper [OPTIONS]
Main commands
Options:
-V, --version Show version and exit.
--debug Enable debug.
-a, --ua TEXT Set User-Agent
-c, --cookie TEXT Set cookie
-d, --allow-domains TEXT Domain white list, wildcard(*) is supported,
separated by commas, e.g. *.example.com,
example*
-D, --disallow-domains TEXT Domain black list, wildcard(*) is supported,
separated by commas, e.g. *.example.com,
example*
-f, --url-file FILE Target urls file, separated by line break
-i, --config FILE Set config file, defaults to settings.yml
-m, --mode [1|2] Set crawl mode, 1(normal) for max_depth=1,
2(thorough) for max_depth=2, default 1
--max-page INTEGER Max page number to crawl, default 100000
--max-depth INTEGER Max depth to crawl, default 1
-o, --outfile FILE Output result to specified file in csv format
-s, --status TEXT Filter response status to display, seperated by
commas, e.g. 200,300-400
-x, --proxy TEXT Set proxy, e.g. http://127.0.0.1:8080,
socks5://127.0.0.1:7890
-H, --hide-regex Hide regex search result
-F, --follow-redirects Follow redirects
-u, --url TEXT Target url
--detail Show detailed result
--validate Validate the status of found urls
-l, --local PATH Local file or directory, scan local
file/directory recursively
--help Show this message and exit.
高级用法
验证URL状态
使用—validate选项验证结果URL的状态,可以减少结果中的无效URL:
secretscraper -u https://scrapeme.live/shop/ --validate --max-page=10
深度爬取
通过—-max-depth选项限制最大爬取深度,默认为1(只爬取输入的URL而不做延伸),该选项不建议设置大于2的值。或者更安全的,可以通过-m 2进行深度爬取,-m 1为深度为1的普通爬取(默认)。
secretscraper -u https://scrapeme.live/shop/ -m 2
将结果保存为CSV文件
secretscraper -u https://scrapeme.live/shop/ -o result.csv
域名黑白名单
可以设置域名黑/白名单,支持通配符(*),白名单:
secretscraper -u https://scrapeme.live/shop/ -d *scrapeme*
黑名单:
secretscraper -u https://scrapeme.live/shop/ -D *.gov
隐藏正则提取的结果
-H选项可以隐藏敏感信息泄露的结果,只显示爬虫结果:
secretscraper -u https://scrapeme.live/shop/ -H
从本地文件中提取敏感信息
secretscraper -l <dir or file>
使用Hyperscan提高正则匹配速度
我分别用hyperscan和re库实现了敏感信息匹配模块,默认使用re库,如果你想要更快的正则匹配速度,可以在配置文件settings.yml中设置handler_type为hyperscan,但是在使用hyperscan之前,你需要了解hyperscan的缺点:
不支持正则group:你不能在正则中使用圆括弧提取内容,hyperscan会直接忽略这个语法
语法变化:hyperscan和
re库的正则语法有些差异,主要体现在预分析语法上
所以最好为这两个模式分别编写正则。
自定义配置
使用-i settings.yml指定自定义配置文件,默认配置如下:
verbose: false
debug: false
loglevel: critical
logpath: log
handler_type: re
proxy: "" # http://127.0.0.1:7890
max_depth: 1 # 0 for no limit
max_page_num: 1000 # 0 for no limit
timeout: 5
follow_redirects: true
workers_num: 1000
headers:
Accept: "*/*"
Cookie: ""
User-Agent: Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.87 Safari/537.36 SE 2.X MetaSr 1.0
urlFind:
- "[\"'‘“`]\\s{0,6}(https{0,1}:[-a-zA-Z0-9()@:%_\\+.~#?&//={}]{2,250}?)\\s{0,6}[\"'‘“`]"
- "=\\s{0,6}(https{0,1}:[-a-zA-Z0-9()@:%_\\+.~#?&//={}]{2,250})"
- "[\"'‘“`]\\s{0,6}([#,.]{0,2}/[-a-zA-Z0-9()@:%_\\+.~#?&//={}]{2,250}?)\\s{0,6}[\"'‘“`]"
- "\"([-a-zA-Z0-9()@:%_\\+.~#?&//={}]+?[/]{1}[-a-zA-Z0-9()@:%_\\+.~#?&//={}]+?)\""
- "href\\s{0,6}=\\s{0,6}[\"'‘“`]{0,1}\\s{0,6}([-a-zA-Z0-9()@:%_\\+.~#?&//={}]{2,250})|action\\s{0,6}=\\s{0,6}[\"'‘“`]{0,1}\\s{0,6}([-a-zA-Z0-9()@:%_\\+.~#?&//={}]{2,250})"
jsFind:
- (https{0,1}:[-a-zA-Z0-9()@:%_\+.~#?&//=]{2,100}?[-a-zA-Z0-9()@:%_\+.~#?&//=]{3}[.]js)
- '["''‘“`]\s{0,6}(/{0,1}[-a-zA-Z0-9()@:%_\+.~#?&//=]{2,100}?[-a-zA-Z0-9()@:%_\+.~#?&//=]{3}[.]js)'
- =\s{0,6}[",',’,”]{0,1}\s{0,6}(/{0,1}[-a-zA-Z0-9()@:%_\+.~#?&//=]{2,100}?[-a-zA-Z0-9()@:%_\+.~#?&//=]{3}[.]js)
dangerousPath:
- logout
- update
- remove
- insert
- delete
rules:
- name: Swagger
regex: \b[\w/]+?((swagger-ui.html)|(\"swagger\":)|(Swagger UI)|(swaggerUi)|(swaggerVersion))\b
loaded: true
- name: ID Card
regex: \b((\d{8}(0\d|10|11|12)([0-2]\d|30|31)\d{3})|(\d{6}(18|19|20)\d{2}(0[1-9]|10|11|12)([0-2]\d|30|31)\d{3}(\d|X|x)))\b
loaded: true
- name: Phone
regex: "['\"](1(3([0-35-9]\\d|4[1-8])|4[14-9]\\d|5([\\d]\\d|7[1-79])|66\\d|7[2-35-8]\\d|8\\d{2}|9[89]\\d)\\d{7})['\"]"
loaded: true
- name: JS Map
regex: \b([\w/]+?\.js\.map)
loaded: true
- name: URL as a Value
regex: (\b\w+?=(https?)(://|%3a%2f%2f))
loaded: false
- name: Email
regex: "['\"]([\\w]+(?:\\.[\\w]+)*@(?:[\\w](?:[\\w-]*[\\w])?\\.)+[\\w](?:[\\w-]*[\\w])?)['\"]"
loaded: true
- name: Internal IP
regex: '[^0-9]((127\.0\.0\.1)|(10\.\d{1,3}\.\d{1,3}\.\d{1,3})|(172\.((1[6-9])|(2\d)|(3[01]))\.\d{1,3}\.\d{1,3})|(192\.168\.\d{1,3}\.\d{1,3}))'
loaded: true
- name: Cloud Key
regex: \b((accesskeyid)|(accesskeysecret)|\b(LTAI[a-z0-9]{12,20}))\b
loaded: true
- name: Shiro
regex: (=deleteMe|rememberMe=)
loaded: true
- name: Suspicious API Key
regex: "[\"'][0-9a-zA-Z]{32}['\"]"
loaded: true
- name: Jwt
regex: "['\"](ey[A-Za-z0-9_-]{10,}\\.[A-Za-z0-9._-]{10,}|ey[A-Za-z0-9_\\/+-]{10,}\\.[A-Za-z0-9._\\/+-]{10,})['\"]"
loaded: true
如需授权、对文章有疑问或需删除稿件,请联系 FreeBuf 客服小蜜蜂(微信:freebee1024)
 利器
利器





- 2 文章数
- 0 关注者