


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

- 关注
作者:京东科技 张宪波、张静、李东江
基于NLP技术对运维日志聚类,从日志角度快速发现线上业务问题
日志在IT行业中被广泛使用,日志的异常检测对于识别系统的运行状态至关重要。解决这一问题的传统方法需要复杂的基于规则的有监督方法和大量的人工时间成本。我们提出了一种基于自然语言处理技术运维日志异常检测模型。为了提高日志模板向量的质量,我们改进特征提取,模型中使用了词性(PoS)和命名实体识别(NER)技术,减少了规则的参与,利用 NER 的权重向量对模板矢量进行了修改,分析日志模板中每个词的 PoS 属性,从而减少了人工标注成本,有助于更好地进行权重分配。为了修改模板向量,引入了对日志模板标记权重的方法,并利用深度神经网络(DNN)实现了基于模板修正向量的最终检测。我们的模型在三个数据集上进行了有效性测试,并与两个最先进的模型进行了比较,评估结果表明,我们的模型具有更高的准确度。
日志是记录操作系统等 IT 领域中的操作状态的主要方法之一,是识别系统是否处于健康状态的重要资源。因此,对日志做出准确的异常检测非常重要。日志异常一般有三种类型,即异常个体日志、异常日志序列和异常日志定量关系。我们主要是识别异常个体日志,即包含异常信息的日志。
一般来说,日志的异常检测包括三个步骤: 日志解析、特征提取和异常检测。解析工具提取的模板是文本数据,应将其转换为数字数据,以便于输入到模型中。为此,特征提取对于获得模板的数字表示是必要的。在模板特征提取方面,业界提出了多种方法来完成这一任务。独热编码是最早和最简单的方法之一,可以轻松地将文本模板转换为便于处理的数字表示,但是独热编码是一种效率较低的编码方法,它占用了太多的储存空间来形成一个零矢量,而且在使用独热编码时,忽略了日志模板的语义信息。除了这种方便的编码方法外,越来越多的研究人员应用自然语言处理(NLP)技术来实现文本的数字转换,其中包括词袋,word2vec 等方法。虽然上述方法可以实现从文本数据到数字数据的转换,但在日志异常检测方面仍然存在一些缺陷。词袋和 word2vec 考虑到模板的语义信息,可以有效地获得单词向量,但是它们缺乏考虑模板中出现的每个模版词的重要性调节能力。此外,深度神经网络(DNN)也被用于模板的特征提取。
我们的模型主要改进特征提取,同时考虑每个标记的模版词语义信息和权重分配,因为标记结果对最终检测的重要性不同。我们利用两种自然语言处理技术即PoS和命名实体识别(NER),通过以下步骤实现了模板特征的提取。具体来说,首先通过 FT-Tree 将原始日志消息解析为日志模板,然后通过 PoS 工具对模板进行处理,获得模板中每个词的 PoS 属性,用于权重向量计算。同时,通过 word2vec 将模板中的标记向量化为初始模板向量,并利用权值向量对初始模板向量进行进一步修改,那些重要的模版词的 PoS属性将有助于模型更好地理解日志含义。对于标记完 PoS 属性的模版词,词对异常信息识别的重要性是不同的,我们使用 NER 在模版的 PoS属性中找出重要性高的模版词,并且被 NER 识别为重要的模版词将获得更大的权重。然后,将初始模板向量乘以这个权重向量,生成一个复合模板向量,输入到DNN模型中,得到最终的异常检测结果。为了减少对日志解析的人力投入,并为权重计算做准备,我们采用了 PoS 分析方法,在不引入模板提取规则的情况下,对每个模版词都标记一个 PoS 属性。
解析模板的特征提取过程是异常检测的一个重要步骤,特征提取的主要目的是将文本格式的模板转换为数字向量,业界提出了各种模板特征提取方法:
One-hot 编码:在 DeepLog 中,来自一组 k 模板ti,i∈[0,k)的每个输入日志模板都被编码为一个One-hot编码。在这种情况下,对于日志的重要信息ti 构造了一个稀疏的 k 维向量 V = [ v0,v1,... ,vk-1] ,并且满足j不等于i, j∈[0,k),使得对于所有vi= 1和 vj = 0。
**自然语言处理(NLP):**为了提取日志模板的语义信息并将其转换为高维向量,LogRobust 利用现成的 Fast-Text 算法从英语词汇中提取语义信息,能够有效地捕捉自然语言中词之间的内在关系(即语义相似性) ,并将每个词映射到一个 k 维向量。使用 NLP 技术的各种模型也被业界大部分人使用,如 word2vec 和 bag-of-words 。
**深度神经网络(DNN):**与使用 word2vec 或 Fast-Text 等细粒度单元的自然语言处理(NLP)不同,LogCNN 生成基于29x128codebook的日志嵌入,该codebook是一个可训练的层,在整个训练过程中使用梯度下降进行优化。
**Template2Vec:**是一种新方法,基于同义词和反义词来有效地表示模板中的词。在 LogClass 中,将经典的加权方法 TF-IDF 改进为 TF-ILF,用逆定位频率代替逆文档频率,实现了模板的特征构造。
一段原始日志消息是一个半结构化的文本,比如一个从在线支付应用程序收集的错误日志读取为: HttpUtil-request 连接失败,Read timeout at jave.net。它通常由两部分组成,变量和常量(也称为模板)。对于识别个体日志的异常检测,目的是从原始日志解析的模板中识别是否存在异常信息。我们的模型使用 PoS 分析以及 NER 技术来进行更精确和省力的日志异常检测。PoS 有助于过滤标记有不必要的 PoS 属性的模版词,NER的目标是将重要性分配给所有标记为重要的 PoS 属性的模版词。然后通过模板向量和权向量的乘积得到复合模板向量。
我们的日志异常检测模型包括六个步骤,即模板解析、 PoS分析、初始向量构造、基于NER的权重计算、复合向量和最终检测。检测的整个过程如图1所示:
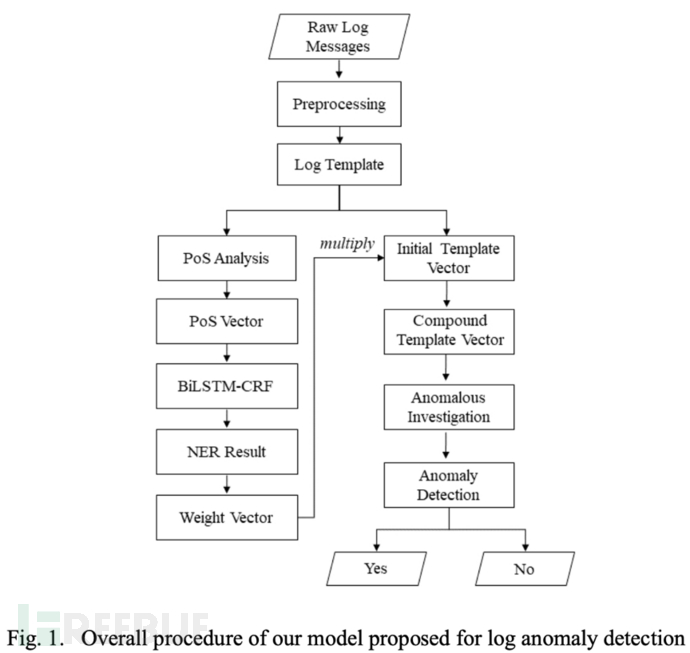
第一步:模板解析
初始日志是半结构化的文本,它们包含一些不必要的信息,可能会造成混乱或阻碍日志检测。因此,需要预处理来省略变量,比如一些数字或符号,并提取常量,即模板。以前面提到的日志消息为例,原始日志HttpUtil-request 连接[wx/v1/pay/prepay]的模板失败,Read timeout at jave.net。可以提取为: HttpUtil 请求连接 * 失败读取时间为 * 。我们使用简单而有效的方法 FT-Tree 来实现日志解析,我们没有引入复杂的基于规则的规则来去除那些不太重要的标记,比如停止词。
第二步:PoS 分析
上一步的模版解析结果只有英语单词、短语和一些非母语单词保留在解析好的模板中,这些模版词具有各种 PoS 属性,例如 VB 和 NN。根据我们对大量日志模板的观察,一些 PoS 属性对于模型理解模板所传达的意义很重要,而其他属性可以忽略。如图3所示,解析模板中的单词“ at”在理论上是不必要的,相应的 PoS 属性“ IN”也是不必要的,即使去掉 IN 的标记,我们仍然可以判断模板是否正常。因此,在我们得到了 PoS 向量之后,我们可以通过去掉那些具有特定 PoS 属性的模版词来简化模板。剩余的模版词对于模型更好地理解模板内容非常重要。
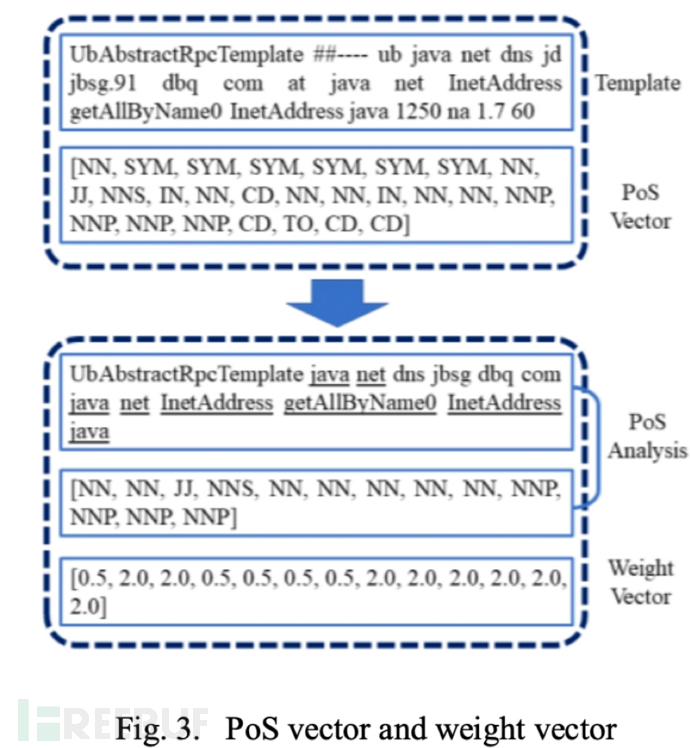
第三步:初始模板向量构造
在获得 PoS 矢量的同时,模板也被编码成数字向量。为了考虑模板的语义信息,在模型中使用 word2vec 来构造模板的初始向量。该初始向量将与下一步得到的权重向量相乘,得到模板的复合优化表示。
第四步: 权重分析
首先对模板中的模版词进行 PoS 分析处理,剔除无意义的模版词。至于其余的模版词,有些是关键的,用于传达基本信息,如服务器操作、健康状态等。其他的可能是不太重要的信息,比如动作的对象、警告级别等等。为了加大模型对这些重要模版词的学习力度,我们构造了一个权重向量来突出这些重要的模版词。为此,我们采用了 NER 技术,通过输入已定义的重要实体,学习挑选标记为重要实体的所有模版词。该过程如图所示:
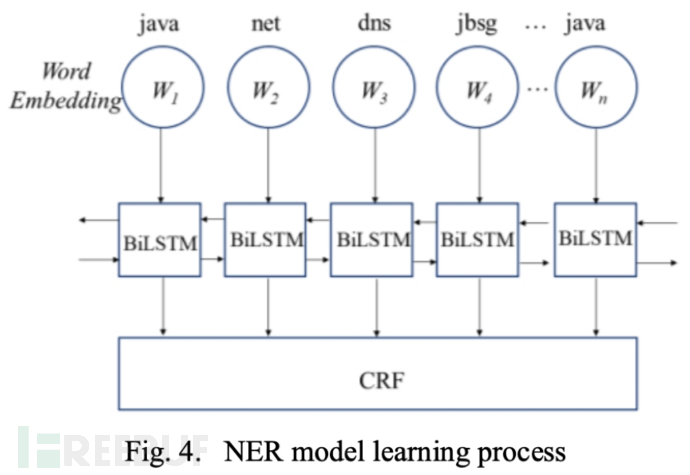
CRF 是 NER 通常使用的工具,它也被用于我们的模型识别模版词的重要性。也就是说,通过向模型提供标记为重要的模版词,模型可以学习识别那些未标注的日志的重要的模版词。一旦模板中的模版词被 CRF 识别出来,相应的位置就会赋予一个权重值(2.0)。因此,我们得到一个权向量 W。
第五步:复合向量
在获得权重向量 W 之后,通过将初始向量 V’乘以权重向量 W,可以得到一个表示模板的复合优化向量 V。重要的模版词分配更大权重,而其他的模版词分配更小的。
第六步:异常检测
将第五步得到的复合矢量 v 输入到最终全连接层中,以便进行异常检测。完全连通层的输出分别为0或1,表示正常或异常。
•模型评估
我们通过实验验证了该模型对日志异常检测的改进效果。采用了两个公共数据集,以及一套我们内部数据集,来验证我们模型的实用性。我们将自己的结果与业界针对日志异常检测提出的两个Deeplog 和 LogClass模型进行了比较。
CANet 的框架是用 PyTorch 构建的,我们在35个训练周期中选择新加坡随机梯度下降(SGD)作为优化器。学习速度设定为2e4。所有的超参数都是从头开始训练的。
**(1)数据集:**我们选取了两套公共集和一套公司内部数据集进行模型评估,BGL 和 HDFS 都是用于日志分析的两个常用公共数据集:**HDFS:是从运行基于 Hadoop 的作业的200多个 Amazon EC2节点收集的。它由11,175,629条原始日志消息组成,16,838条被标记为“异常”。BGL:**收集自 BlueGene/L 超级计算机系统 ,包含4,747,963条原始日志消息,其中348,469条是异常日志。每条日志消息都被手动标记为异常或者正常。**数据集 A:**是从我们公司内部收集来进行实际验证的数据集。它包含915,577条原始日志消息和210,172条手动标记的异常日志。
**(2)base模型:**我们将自己的模型在三个数据集上,与两个业界最先进的模型(DeepLog和LogClass)进行比较:DeepLog:是一个基于深度神经网络的模型,利用长短期记忆(LSTM)来实现检测。DeepLog 采用一次性编码作为模板向量化方法。LogClass:LogClass 提出了一种新的方法——逆定位频率(ILF) ,在特征构造中对日志文字进行加权。这种新的加权方法不同于现有的反文档频率(IDF)加权方法。
**(3)模型评估结果:**我们从Precision、Recall和F1-score三个方面评估两个base模型和我们的模型的异常检测效果,在 HDFS 数据集上,我们的模型获得了最高的 F1得分0.981,此外,我们的模型在召回方面也表现最好。LogClass 在Precision上取得了最好的成绩,比我们的稍微高一点。在第二套数据集BGL上,我们的模型在召回率Recall(0.991)和 F1-score (0.986)方面表现最好,但在Precision上略低于 LogClass。在第三套数据集 A 上三个模型的性能,我们的模型实现了最佳性能,其次是 LogClass。
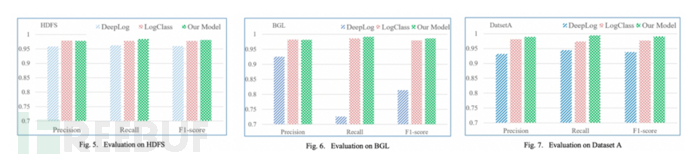
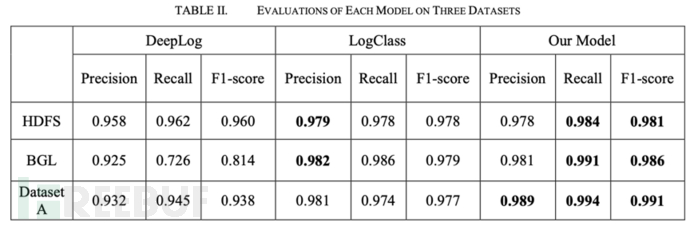
在所有的数据集中,我们的模型具有最好的 F1得分和最高的召回率,这意味着我们的模型造成的不确定性更小。
•Natural Language Processing-based Model for Log Anomaly Detection. SEAI.
•**ieeexplore检索:**https://ieeexplore.ieee.org/abstract/document/9680175

•Themis智能运维平台智能文本分析功能视图:(http://jdtops.jd.com/)
如需授权、对文章有疑问或需删除稿件,请联系 FreeBuf 客服小蜜蜂(微信:freebee1024)
- 0 文章数
- 0 关注者