


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

 cc_work
cc_work- 关注
什么是MQ?
MQ全称为Message Queue,即消息队列。是一种用于在分布式系统中传递消息的中间件。它通过在生产者和消费者之间引入一个中间层——消息队列,来解耦两者,使得它们可以独立地生产和消费消息。MQ 可以有效地解决系统之间的异步通信、流量削峰填谷和数据解耦等问题,是现代分布式系统和微服务架构中的重要组成部分。
典型的模式
生产者、消费者模型。
这种模式MQ本身就相当于一个中间件,用于生产方通过MQ与消费方之间的交互作用。
AMQP 协议
AMQP,即Advanced Message Queuing Protocol (高级消息队列协议),一个提供统一消息服务的应用层标准高级消息队列协议,是应用层协议的一个开放标准,为面向消息的中间件设计。基于此协议的客户端与消息中间件可传递消息,并不受客户端/中间件不同产品,不同的开发语言等条件的限制。Erlang中的实现有RabbitMQ等。2006年,AMQP 规范发布。
主要特性
1.高性能:采用高效的消息传递引擎,能够处理大量的并发消息,适用于高吞吐量的应用场景。
2.可扩展性:支持分布式部署,通过集群和分片技术,可以轻松扩展系统容量,适应业务的快速增长。
3.高可用性:通过主备切换、数据冗余和故障转移机制,确保系统的高可用性和数据的可靠性。
4.多协议支持:支持多种消息协议(如 AMQP、MQTT、STOMP),方便不同类型的应用集成。
5.灵活的消息路由:支持多种消息路由模式(如直连、广播、主题),满足不同业务场景的需求。
6.消息持久化:提供强大的消息持久化功能,确保消息在系统崩溃或重启时不会丢失。
7.安全性:支持多种安全机制(如身份认证、权限控制、数据加密),保障消息传递的安全性。
8.监控与管理:提供丰富的监控和管理工具,方便运维人员实时监控系统状态和性能指标。
模式
存储转发(多个消息发送者,单个消息接收者)
分布式事务(多个消息发送者,多个消息接收者)
发布订阅(多个消息发送者,多个消息接收者)
基于内容的路由(多个消息发送者,多个消息接收者)
文件传输队列(多个消息发送者,多个消息接收者)
点对点连接(单个消息发送者,单个消息接收者)
RabbitMQ
RabbitMQ 是一个开源的消息代理软件,最初由 Pivotal Software 开发,现为 VMware 旗下。RabbitMQ 实现了高级消息队列协议(AMQP),并且支持多种消息协议(如 MQTT、STOMP)。它广泛应用于分布式系统和微服务架构中,提供高性能、可靠的消息传递服务。
主要特性
1.多协议支持:支持 AMQP、MQTT、STOMP 等多种消息协议。
2.丰富的消息路由功能:支持直连交换机(Direct Exchange)、扇出交换机(Fanout Exchange)、主题交换机(Topic Exchange)和头交换机(Headers Exchange)。
3.消息持久化:支持将消息持久化到磁盘,确保消息在 RabbitMQ 崩溃或重启时不会丢失。
4.高可用性:通过集群和镜像队列提供高可用性和故障转移功能。
5.插件系统:支持多种插件,如管理插件、监控插件和安全插件。
6.管理和监控:提供 Web 界面和命令行工具,方便用户进行管理和监控。
RabbitMQ作用和场景
1. 微服务架构中的解耦
在微服务架构中,服务之间的直接调用会导致强耦合,难以维护和扩展。通过引入消息队列,服务之间可以进行异步通信,从而实现解耦。
示例:
订单处理系统:订单服务生成订单后,将订单信息发送到消息队列。支付服务从消息队列中读取订单信息并进行支付处理,支付成功后再将支付结果发送到消息队列,由订单服务更新订单状态。
2. 流量削峰填谷
在高并发场景中,系统瞬时流量可能会非常高,导致系统负载过大。消息队列可以缓冲高峰期的请求,平滑系统负载,防止系统崩溃。
示例:
秒杀系统:在秒杀活动中,用户请求量会在短时间内激增。通过消息队列,系统可以将用户请求排队,逐个处理,避免数据库和应用服务器的瞬时过载。
3. 异步处理
一些任务可能需要较长时间才能完成,通过消息队列可以将这些任务异步化,避免阻塞主流程,提升系统响应速度。
示例:
邮件通知:用户注册成功后,系统需要发送欢迎邮件。可以将邮件发送任务放入消息队列,由专门的邮件服务异步处理,主流程无需等待邮件发送完成。
4. 日志收集
在分布式系统中,日志收集和分析是非常重要的。消息队列可以用于集中收集和传输日志,实现日志的统一管理和分析。
示例:
日志系统:各个服务将日志信息发送到消息队列,日志处理服务从消息队列中读取日志信息,进行存储和分析。
5. 事件驱动架构
在事件驱动架构中,系统通过事件来驱动业务流程。消息队列可以用于事件的发布和订阅,实现事件的分发和处理。
示例:
用户行为跟踪:用户在网站上的操作(如点击、浏览、购买)会触发事件,这些事件通过消息队列传递给数据分析系统,进行实时分析和处理。
6. 数据同步
在多系统或多数据中心环境中,数据的一致性和同步是一个挑战。消息队列可以用于不同系统之间的数据同步,确保数据的一致性。
示例:
数据库同步:主数据库的更新操作通过消息队列传递给从数据库,从数据库根据消息进行数据更新,确保主从数据库的一致性。
7. 任务调度
消息队列可以用于任务的分发和调度,协调多个工作节点的工作,提高系统的并行处理能力。
示例:
分布式任务调度:任务生成系统将任务放入消息队列,多个工作节点从消息队列中读取任务并进行处理,实现任务的并行调度和处理。
8. 事务处理
在分布式系统中,实现分布式事务是一个难题。通过消息队列,可以实现最终一致性的事务处理。
示例:
订单和库存系统:订单服务生成订单后,将订单信息发送到消息队列,库存服务从消息队列中读取订单信息并更新库存。通过消息队列的确认机制,确保订单和库存的一致性。
9. 缓存更新
在使用缓存时,当数据发生变化时,需要更新缓存。消息队列可以用于通知缓存系统更新缓存数据。
示例:
缓存更新通知:当数据库中的数据发生变化时,将更新信息发送到消息队列,缓存系统从消息队列中读取更新信息并更新缓存。
10. 延迟任务
消息队列可以用于实现延迟任务,即在指定时间后处理任务。
示例:
订单超时取消:用户下单后,如果在一定时间内未完成支付,系统自动取消订单。可以将订单信息放入消息队列,设置延迟时间,延迟时间到后由系统自动取消订单
RabbitMQ的缺点
1.系统可用性降低:由于引入了外部依赖,系统的稳定性会变差。一旦RabbitMQ宕机,可能会对业务产生影响。
2.系统复杂度提高:引入RabbitMQ后,系统的复杂度会大大提高。原本的服务之间同步的服务调用会变成异步调用,数据链路会变得更复杂,并且还会带来一系列问题。
3.消息一致性问题:在多系统之间进行消息传递时,需要考虑消息的一致性问题。例如,如果B系统成功处理了消息而C系统失败,需要有一种机制来处理这种情况以保持消息的一致性。
4.数据丢失风险:如果使用不可靠的网络或者不恰当的配置,可能会导致消息在传输过程中丢失。
5.性能瓶颈:虽然RabbitMQ支持水平扩展,但如果生产者和消费者的处理能力不匹配,可能会导致消息积压和性能问题。
6.学习曲线陡峭:对于初学者来说,RabbitMQ的概念和用法可能比较复杂,需要花费一定的时间和精力来学习和掌握。
7.安全性问题:虽然RabbitMQ提供了一些安全特性,如用户认证和访问控制,但如果没有正确配置或管理,可能会存在安全风险。
#RabbitMQ基本概念
基础名词
Channel(信道):多路复⽤连接中的⼀条独⽴的双向数据流通道。信道是建⽴在真实的TCP连接内的虚拟连接,复⽤TCP连接的通道。
Producer(消息的⽣产者):向消息队列发布消息的客户端应⽤程序。
Consumer(消息的消费者):从消息队列取得消息的客户端应⽤程序。
Message(消息):消息由消息头和消息体组成。消息体是不透明的,⽽消息头则由⼀系列的可选属性组成,这些属性包括routing-key(路由键)、priority(消息优先权)、delivery-mode(是否持久性存储)等。
Routing Key(路由键):消息头的⼀个属性,⽤于标记消息的路由规则,决定了交换机的转发路径。最⼤长度255 字节。
Queue(消息队列):存储消息的⼀种数据结构,⽤来保存消息,直到消息发送给消费者。它是消息的容器,也是消息的终点。⼀个消息可投⼊⼀个或多个队列。消息⼀直在队列⾥⾯,等待消费者连接到这个队列将消息取⾛。需要注意,当多个消费者订阅同⼀个Queue,这时Queue中的消息会被平均分摊给多个消费者进⾏处理,⽽不是每个消费者都收到所有的消息并处理,每⼀条消息只能被⼀个订阅者接收。
交换(交换路由器):提供生产者和队列之间的匹配,接收生产者发送的消息,并根据路由规则将这些消息转发到消息队列柱。交换用于转发消息。它不会存储消息。如果没有绑定到exchange的队列,它将直接丢弃生产者发送的消息。交出交换机有四种消息调度策略(将在下一节中介绍),即扇出、直接、主题和头。
Binding(绑定):⽤于建⽴Exchange和Queue之间的关联。⼀个绑定就是基于Binding Key将Exchange和Queue连接起来的路由规
则,所以可以将交换器理解成⼀个由Binding构成的路由表。Binding Key(绑定键):Exchange与Queue的绑定关系,⽤于匹配Routing Key。最⼤长度255 字节。
Broker:RabbitMQ Server,服务器实体。
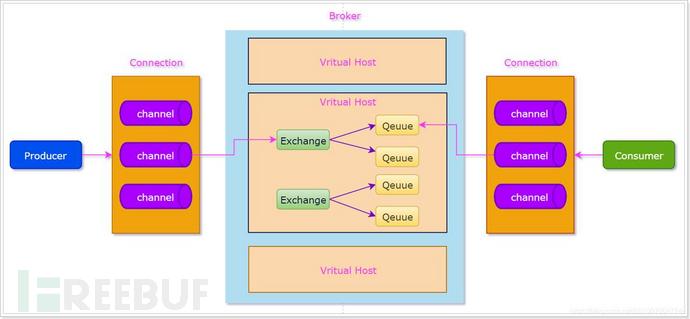
工作流程
生产者发送消息:生产者通过RabbitMQ的客户端库创建消息,并使用指定的交换机和路由键将消息发送到RabbitMQ服务器。
交换机接收并路由消息:交换机接收到生产者的消息后,根据配置的路由规则和路由键将消息分发到相应的队列中。
消费者消费消息:消费者连接到RabbitMQ服务器,并监听指定的队列。当队列中有新消息时,消费者从队列中获取并处理消息。处理完成后,消费者可以选择发送确认消息给RabbitMQ服务器,以表示消息已被成功处理。
在整个工作流程中,RabbitMQ服务器充当了消息代理的角色,负责在生产者和消费者之间进行消息的传递和路由。通过使用队列、交换机和路由键等核心概念,RabbitMQ实现了高效、可靠和灵活的消息传递机制。
需要注意的是,RabbitMQ还支持一些高级特性和扩展,如消息持久化、事务、集群和镜像队列等。这些特性和扩展可以进一步提高RabbitMQ的可用性、可靠性和扩展性。
消费模式
简单消费模式

最直接的方式,P端发送一个消息到一个指定的queue,中间不需要任何exchange规则。C端按queue方式进行消费。
在上图的模型中,有以下概念:
Producer:生产者,也就是要发送消息的程序
Consumer:消费者:消息的接受者。
Queue:消息队列,图中红色部分。可以缓存消息;生产者向其中投递消息,消费者从其中取出消息。
一个生产者、一个消费者,不需要设置交换机(使用默认的交换机)。
工作队列或者竞争消费者模式
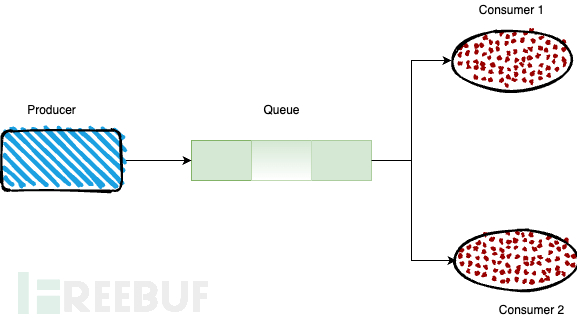
与简单模式相比,多了一个或一些消费端,多个消费端共同消费同一个队列中的消息。一个消息只会被一个消费者消费。
一个生产者、多个消费者(竞争关系),不需要设置交换机(使用默认的交换机)。
发布订阅模式
在订阅模型中,多了一个 Exchange 角色,而且过程略有变化: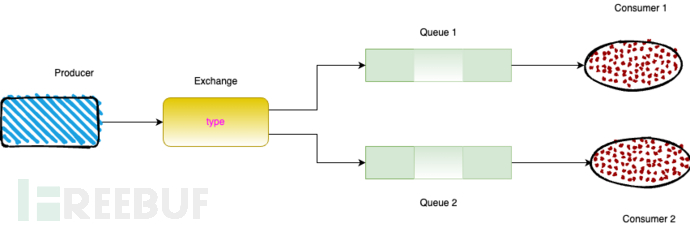
Producer:生产者,也就是要发送消息的程序,但是不再发送到队列中,而是发给X(交换机)
Consumer:消费者,消息的接收者
Queue:消息队列,接收消息、缓存消息Exchange:交换机(X)。一方面,接收生产者发送的消息。另一方面,知道如何处理消息,例如递交给某个特别队列、递交给所有队列、或是将消息丢弃。到底如何操作,取决于Exchange的类型。
Exchange(交换机)只负责转发消息,不具备存储消息的能力,因此如果没有任何队列与 Exchange 绑定,或者没有符合路由规则的队列,那么消息会丢失!producer只负责发送消息,至于消息进入哪个queue,由exchange来分配。
发布订阅模式与工作队列模式的区别:
1.工作队列模式不用定义交换机,而发布/订阅模式需要定义交换机
2.发布/订阅模式的生产方是面向交换机发送消息,工作队列模式的生产方是面向队列发送消息(底层使用默认交换机)
3.发布/订阅模式需要设置队列和交换机的绑定,工作队列模式不需要设置,实际上工作队列模式会将队列绑 定到默认的交换机
使用场景:
所有消费者获得相同的消息,例如天气预报。
Exchange有常见以下3种类型:
Fanout-发布订阅模式(广播)
Fanout:广播,将消息交给所有绑定到交换机的队列,交换机需要与队列进行绑定,绑定之后;一个消息可以被多个消费者都收到。
在广播模式下,消息发送流程是这样的:
可以有多个消费者
每个消费者有自己的queue(队列)
每个队列都要绑定到Exchange(交换机)
生产者发送的消息,只能发送到交换机,交换机来决定要发给哪个队列,生产者无法决定。
交换机把消息发送给绑定过的所有队列
队列的消费者都能拿到消息。实现一条消息被多个消费者消费
Direct-发布订阅模式(定向)
Direct:定向,把消息交给符合指定routing key 的队列
在定向模式下,消息发送流程是这样的:
1.有选择性的接收消息
2.在广播模式中,生产者发布消息,所有消费者都可以获取所有消息。在定向模式中,我们将添加一个功能 - 我们将只能订阅一部分消息。
3.在定向模型下,队列与交换机的绑定,不能是任意绑定了,而是要指定一个RoutingKey(路由key)
4.消息的发送方在向Exchange发送消息时,也必须指定消息的routing key。
Topic-发布订阅模式(通配符)
Topic:通配符,把消息交给符合routing pattern(路由模式) 的队列
Topic类型与Direct相比,都是可以根据RoutingKey把消息路由到不同的队列。只不过Topic类型Exchange可以让队列在绑定Routing key 的时候使用通配符
重点概念
事务
RabbitMQ 提供了事务机制来确保消息的可靠性传递。使用事务机制时,可以在发送消息之前开启一个事务,在事务内发送消息并进行确认提交,以确保消息被正确地发送到 RabbitMQ 中。
下面是使用 RabbitMQ 事务机制发送消息的一般步骤:
开启事务:通过 tx_select() 方法开启一个事务。
发送消息:在事务内使用 basic_publish() 方法发送消息到指定的 Exchange 和队列。
提交事务:通过 tx_commit() 方法提交事务,确保在事务内的操作生效。
回滚事务(可选):如果发送消息过程中出现异常或错误,可以通过 tx_rollback() 方法回滚事务,撤销事务内的操作。
事务机制会对性能产生一定的影响,因为它需要进行额外的操作来维护事务的一致性。在高并发场景下,使用事务可能会导致性能下降。因此,在选择使用事务机制时,请根据实际需求和性能要求进行权衡。
总的来说,事务机制提供了一种确保消息传递可靠性的方法,但在实际应用中需要慎重考虑其对性能的影响。在大部分情况下,使用确认机制(Publisher Confirm)已经能够满足消息传递的可靠性要求,并且对性能影响较小。
消息确认机制(ACK)
RabbitMQ通过 publisher confirm 机制来实现的消息发送端确认。生产者将信道设置成confirm(确认)模式,一旦信道进入confirm 模式,所有在该信道上⾯面发布的消息都会被指派一个唯一的ID(从 1 开始),一旦消息被投递到所有匹配的队列之后 (如果消息和队列是持久化的,那么确认消息会在消息持久化后发出),RabbitMQ 就会发送一个确认(Basic.Ack)给生产者(包含消息的唯一ID),这样生产者就知道消息已经正确送达了。
整个过程需要保证消费者、RabbitMQ自己和消费者都不能丢消息。
** RabbitMQ 消息确认机制分为两大类**
消息发送确认,又分为:
生产者到交换机的确认;
交换机到队列的确认。消息接收确认。
消息发送确认
RabbitMQ 的消息发送确认有两种实现方式:ConfirmCallback 方法、ReturnCallback 方法。
1)ConfirmCallback方法
ConfirmCallback 是一个回调接口,用于确认消息否是到达交换机中。
2)ReturnCallback方法
ReturnCallback 也是一个回调接口,用于确认消息是否在交换机中路由到了队列。
消息接收确认
消费者确认发生在 监听队列的消费者处理业务失败,如:发生了异常、不符合要求的数据等。这些场景就 需要我们手动处理消息,比如:重新发送消息或者丢弃消息。
RabbitMQ 的 消息确认机制(ACK) 默认是自动确认的。自动确认会 在消息发送给消费者后立即确认,但 存在丢失消息的可能。如果消费端消费逻辑抛出了异常,假如我们使用了事务的回滚,也只是保证了数据的一致性,消息还是丢失了。也就是消费端没有处理成功这条消息,那么就相当于丢失了消息。
消息的确认模式有三种:
AcknowledgeMode.NONE:自动确认。(默认)
AcknowledgeMode.AUTO:根据情况确认。
AcknowledgeMode.MANUAL:手动确认。(推荐)
消费者收到消息后,手动调用 Channel 的 basicAck()/basicReject()/basicNack() 方法后,RabbitMQ 收到消息后,才认为本次投递完成。
basicAck():用于确认当前消息。
basicReject():用于拒绝当前消息,可以自定义是否重回队列。
basicNack():用于批量拒绝消息(这是 AMPQ 0-9-1 的 RabbitMQ 扩展)。
持久性
持久化,即将原本存在于内存中的数据写入到磁盘上永久保存数据,防止服务宕机时内存数据的丢失。
RabbitMQ 的持久化
持久化是消息队列系统中的一个重要特性,它确保消息在系统崩溃或重启时不会丢失。RabbitMQ 提供了多种持久化机制来保证消息的可靠性,包括队列持久化、消息持久化和交换机持久化。以下是对 RabbitMQ 持久化机制的详细介绍。
队列持久化
队列持久化是指将队列的元数据(如队列名称、属性等)保存到磁盘中。持久化队列在 RabbitMQ 重启后仍然存在,能够继续接收和传递消息。
声明持久化队列的示例:
import pika
# 创建连接和频道
connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connection.channel()
# 声明持久化队列
channel.queue_declare(queue='persistent_queue', durable=True)
在上述代码中,通过设置durable=True参数来声明一个持久化队列。
消息持久化
消息持久化是指将消息内容保存到磁盘中。持久化消息在 RabbitMQ 重启后仍然存在,可以继续传递给消费者。消息持久化需要生产者在发送消息时指定消息的持久化属性。
发送持久化消息的示例:
import pika
# 创建连接和频道
connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connection.channel()
# 声明持久化队列
channel.queue_declare(queue='persistent_queue', durable=True)
# 发送持久化消息
message = "Hello, Persistent World!"
channel.basic_publish(exchange='',
routing_key='persistent_queue',
body=message,
properties=pika.BasicProperties(delivery_mode=2)) # 设置消息持久化属性
print(" [x] Sent 'Hello, Persistent World!'")
在上述代码中,通过设置delivery_mode=2参数来发送持久化消息。
交换机持久化
交换机持久化是指将交换机的元数据(如交换机名称、类型、属性等)保存到磁盘中。持久化交换机在 RabbitMQ 重启后仍然存在,能够继续接收和路由消息。
声明持久化交换机的示例:
import pika
# 创建连接和频道
connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connection.channel()
# 声明持久化交换机
channel.exchange_declare(exchange='persistent_exchange', exchange_type='direct', durable=True)
在上述代码中,通过设置durable=True参数来声明一个持久化交换机。
持久化的注意事项
性能影响:持久化操作会增加磁盘 I/O,可能会影响 RabbitMQ 的性能。在高并发场景下,需要权衡持久化带来的可靠性和性能之间的关系。
消息确认:为了确保消息被成功持久化,消费者需要发送消息确认(Acknowledgment)。RabbitMQ 在收到消息确认后才会将消息从队列中移除。
镜像队列:在高可用性场景下,可以使用镜像队列(Mirrored Queue)来实现队列的高可用。镜像队列会将消息复制到多个节点,确保在节点故障时消息不会丢失。
镜像队列的配置示例:
# 使用 RabbitMQ 管理插件配置镜像队列策略
rabbitmqctl set_policy ha-all "" '{"ha-mode":"all"}'
在上述命令中,ha-all是策略名称,""是匹配模式,{"ha-mode":"all"}是策略定义,表示将所有队列配置为镜像队列。
总结
RabbitMQ 提供了多种持久化机制来确保消息的可靠性,包括队列持久化、消息持久化和交换机持久化。通过合理配置持久化机制,可以在系统崩溃或重启时确保消息不丢失。然而,持久化操作会增加磁盘 I/O,需要在可靠性和性能之间进行权衡。在高可用性场景下,可以使用镜像队列来实现队列的高可用,进一步提升系统的可靠性。
如需授权、对文章有疑问或需删除稿件,请联系 FreeBuf 客服小蜜蜂(微信:freebee1024)





- 16 文章数
- 3 关注者