


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

 estalo
estalo- 关注
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
 本文由
estalo 创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
本文由
estalo 创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
前言
大家好,之前公司要求一定周期要交规定数量的漏洞,手动尝试了一下之后觉得不太现实,于是决定写个脚本结合一些项目来刷,适合刷src。
大致思路
既然需要批量扫描,我们需要的主要就是两个条件:
1.大量的扫描目标(需要fofa会员)
2.扫描器
我的扫描目标是利用github的一个开源项目获取的(需要fofa会员):fofamap
然后扫描器我选的是:nuclei
身为菜鸟的我只需要将fofa查询的结果进行处理后,导入到nuclei进行扫描即可
只需要从网上扒几个正则规则,然后进行匹配获取就能导入到nuclei进行扫描了。
正文
不想看代码的,只是想使用的可以直接跳过正文部分,看使用说明
先放出shell脚本代码
#!/bin/bash
OLDIFS="$IFS" #将for循环的分隔符设为换行符(默认是空格)
IFS=$'\n'
cd /root/scan/FofaMap-1.1.3/
for keyword in $(cat /root/keyword.txt) #遍历需要fofa查询的内容,并将每次需要查询的内容带入keyword变量
do
rm scan_list_ip #删除上次扫描产生的所有文件
rm scan_list_url
cd /root/scan/FofaMap-1.1.3/
#fofa查询语句,查询keyword内容,后面的是只查200状态码和限定国内ip的语句
python3 fofamap.py -q "$keyword && status_code=\"200\" && country=\"CN\" && region!=\"TW\" && region!=\"HK\" && region!=\"MO\" " #出fofamap.log
python3 scan_repeat.py #出scan_list_url和scan_list_ip
nuclei -es info,low -l scan_list_url >> /root/scan_result #出scan_result
done
填写fofa搜索关键词
keyword.txt格式就是我们平时搜fofa用的语句格式,将其放至/root/keyword.txt
如:
title="xxx" && after="2022-1-6"
title="xxx" && after="2022-1-10"
填写配置
我们将fofamap的配置文件fofa.ini中email和key填写(最好是旧高级会员账号的key),以及根据自己的需求填写其他配置内容即可,而logger一定要设置为on,因为我们就是从日志文件fofamap.log中提取扫描目标的。
然后扫描关键词在/root目录下放在keyword.txt文件内即可
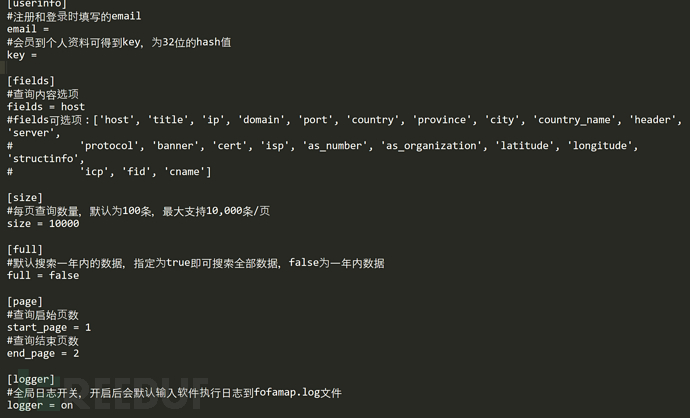
fofamap搜索后获取的结果格式如下:
正则匹配url和ip
我们只需要进行正则匹配其中的ip和url将其提取出来即可
scan_repeat.py代码如下:
import re
import os
re_ip = re.compile("(25[0-5]\.|2[0-4]\d\.|1?[1-9]?\d\.|10\d\.){3}(25[0-5]|2[0-4]\d|1?\d?[0-9])(\:(\d)*)?")
re_ip_http = re.compile("https?://(25[0-5]\.|2[0-4]\d\.|1?[1-9]?\d\.|10\d\.){3}(25[0-5]|2[0-4]\d|1?\d?[0-9])(\:(\d)*)?")
re_url=re.compile("([\w-]*\.)*[\w-]*\.[a-z]{2,}(\:(\d)*)?(?=\x20)")
re_url_http=re.compile("https?://([\w-]*\.)*[\w-]*\.[a-z]{2,}(\:(\d)*)?(?=\x20)")
ip_list_http=[]
url_list_http=[]
ip_list=[]
url_list=[]
def ip_repeat():
r1 = open('fofamap.log' , 'r' ,encoding='utf-8')
for line in r1.readlines():
s1 = re.search(re_ip_http,line)
if s1:
if s1 not in ip_list_http:
ip_list_http.append(s1.group())
with open('scan_list_ip' , 'a' ,encoding='utf-8') as a:
for j in ip_list_http:
a.write(j+'\n')
r1.close()
with open('fofamap.log' , 'r' ,encoding='utf-8') as r1:
with open('scan_list_ip' , 'r' ,encoding='utf-8') as r:
temp = r.read()
for lines in r1.readlines():
s1_1 = re.search(re_ip,lines)
if s1_1:
re_group=str(s1_1.group())
test = re.search(re_group,temp)
if not test:
ip_list.append(s1_1.group())
with open('scan_list_ip' , 'a' ,encoding='utf-8') as a:
for j in ip_list:
a.write(j+'\n')
def url_repeat():
r2 = open('fofamap.log' , 'r' ,encoding='utf-8')
for line in r2.readlines():
s2 = re.search(re_url_http,line)
if s2:
if s2 not in url_list_http:
url_list_http.append(s2.group())
with open('scan_list_url','a',encoding='utf-8') as a:
for j in url_list_http:
a.write(j+'\n')
r2.close()
with open('fofamap.log' , 'r' ,encoding='utf-8') as r2:
with open('scan_list_url' , 'r' ,encoding='utf-8') as r:
temp = r.read()
for line in r2.readlines():
s2_1 = re.search(re_url,line)
if s2_1:
re_group=str(s2_1.group())
test = re.search(re_group,temp)
if not test:
url_list.append(s2_1.group())
with open('scan_list_url','a',encoding='utf-8') as a:
for j in url_list:
a.write(j+'\n')
ip_repeat()
url_repeat()
个脚本scan_repeat.py将其中的url和ip匹配并分别导出为两个文件:
scan_list_url和scan_list_ip
放入扫描器扫描
然后就可以直接导入nuclei进行扫描,这里我们是使用了nuclei官方默认的poc进行扫描并去掉了低危和信息部分:
nuclei -es info,low -l scan_list_url >> /root/scan_result
如果要导入其他被动扫描器,记得dos2unix,我这里只扫了url部分,因为很容易查归属单位,如果有人要查权重,可以将url的根域名利用查权重的接口进行查询然后再扫描,这里我就不写了
扫描后结果会导出到/root/scan_result中,看得出数量挺多的,keyword.txt关键词可以多放点,这样就能扫很久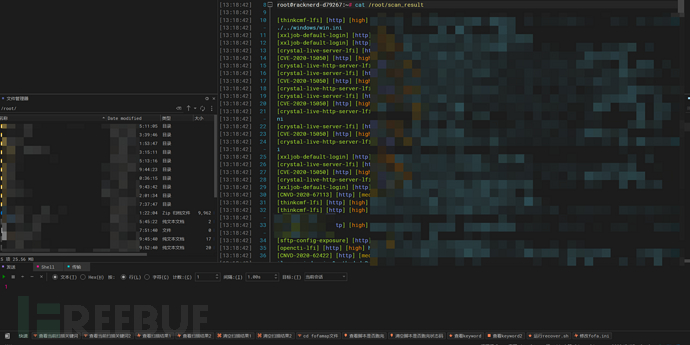
使用说明
我把文件放在我的github项目文档内了:bug_scan
把scan文件放到/root下即可,放好之后scan的目录是/root/scan
环境配置
python3 :
这个自行安装,我用的python3.8和3.11都能运行,其他应该也没啥问题
nuclei:
去官方下载nuclei,这里我只讲单文件版本配置方式,github的nuclei官方项目:nuclei
进入release,选择适合自己的版本,这里我用的是amd64的,解压出来然后使用chmod u+x nuclei给予执行权限,然后mv nculei 环境变量目录,就可以直接使用了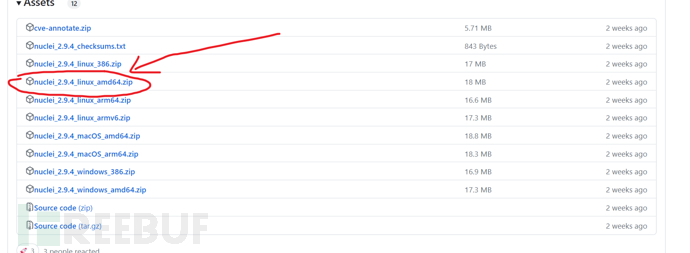
然后是fofamap的环境配置
我会放在requirements.txt内,大家下载好后进入requirements所在目录内执行命令即可安装依赖:
pip3 install -r requirements.txt
使用步骤
给予bug_scan.sh执行权限
scan文件下载好放到/root文件下,进入/root/scan文件内,给予执行权限chmod u+x bug_scan.sh
keyword.txt(搜索关键词文件)放到/root目录下
keyword内容为我们要搜索的语句的内容
keyword.txt内容格式与fofa查询语句格式一致:
title="xxx" && after="2022-1-6"
title="xxx" && after="2022-1-10"
填写fofa配置(需要fofa会员)
我们将fofamap的配置文件fofa.ini中email和key填写(最好是旧高级会员账号的key),以及根据自己的需求填写其他配置内容即可,而logger一定要设置为on,因为我们就是从日志文件fofamap.log中提取扫描目标的。
最后一步
执行/root/scan/bug.scan.sh文件,就会开始循环keyword.txt内搜索关键词进行扫描,最后输出结果放在/root/scan_result内,cat /root/scan_result即可
一开始scan_result是没东西的,要扫描出来才有,还有如果是服务器建议用screen跑,这样断开会话还能继续扫
声明
本工具仅提供给安全测试人员进行合法安全测试使用 用户滥用造成的一切后果与作者无关 使用者请务必遵守当地法律 本程序不得用于商业用途,仅限学习交流
题外话
不要太沉迷于刷洞哦,要实打实的提升自己的技术。
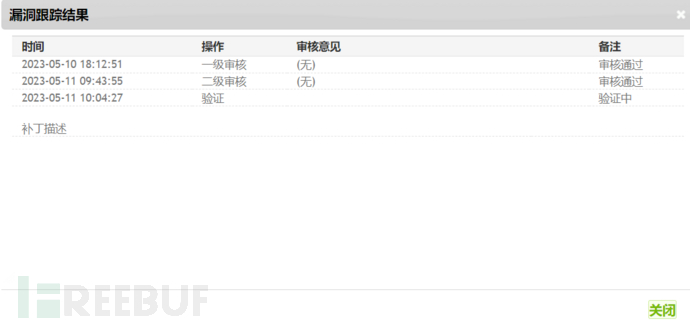
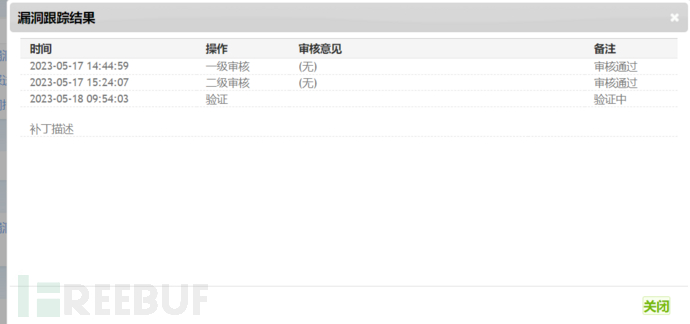
关键词搜的好,cnvd证书也不在话下(我的三个还在验证XD)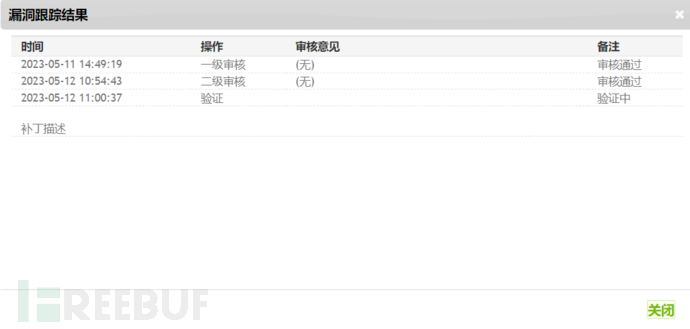
已在FreeBuf发表 1 篇文章
如需授权、对文章有疑问或需删除稿件,请联系 FreeBuf 客服小蜜蜂(微信:freebee1024)






- 1 文章数
- 2 关注者