


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

 非典型产品经理笔记
非典型产品经理笔记- 关注
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
目录
- 目录
- 0、 前言
- 1、什么是GPT
- 2、GPT之技术演进时间线
- 3、GPT之T-Transformer(2017)
- 4、GPT(Generative Pre-Training)-2018年6月
- 5、GPT-2(2019年2月)
- 6、GPT-3(2020年5月)
- 7、Instruction GPT(2022年2月)
- 8、ChatGPT(2022年11月)
- 9、小结
- 10、未来将来(GPT-4 or ?)
- 部分参考资料
0、 前言
11月30日,OpenAI推出了一个名为ChatGPT的AI聊天机器人,可以供公众免费测试,短短几天就火爆全网。
从头条、公众号上多个宣传来看,它既能写代码、查BUG,还能写小说、写游戏策划,包括向学校写申请书等,貌似无所不能。
本着科(好)学(奇)的精神,抽了一些时间对ChatGPT进行了了测试验证,并且 **梳理了一下ChatGPT为什么能这么"强"**。
最终,关于ChatGPT本次会分为两篇:
由于笔者并没有专业学过AI,同时精力受限,所以 短时间内就不会再有AI-003类似更深入到技术的篇章了,了解 001、002就已经超出普通吃瓜群众的范畴了。
本篇会有较多技术名词,我会尽量降低其理解难度。
同时,由于非AI专业出身,如有错漏、敬请指出。
致谢:非常感谢X同学、Z同学两位大牛的审稿,尤其感谢X同学的专业性堪误
1、什么是GPT
ChatGPT里面有两个词,一个是Chat,指的是可以对话聊天。另外一个词,就是GPT。
GPT的全称,是Generative Pre-Trained Transformer(生成式预训练Transfomer模型)。
可以看到里面一共3个单词,Generative生成式、Pre-Trained预训练、和Transformer。
有读者可能会注意到,我上面没有给Transformer翻译中文。
因为Transformer是一个技术专有名词,如果硬翻译 ,就是变压器。但是会容易失去本意,还不如不翻译。
在下面第3章节会再讲解一下Transformer。
2、GPT之技术演进时间线
GPT从开始至今,其发展历程如下:
2017年6月,Google发布论文《Attention is all you need》,首次提出Transformer模型,成为GPT发展的基础。 论文地址: https://arxiv.org/abs/1706.03762
2018年6月,OpenAI 发布论文《Improving Language Understanding by Generative Pre-Training》(通过生成式预训练提升语言理解能力),首次提出GPT模型(Generative Pre-Training)。论文地址: https://paperswithcode.com/method/gpt 。
2019年2月,OpenAI 发布论文《Language Models are Unsupervised Multitask Learners》(语言模型应该是一个无监督多任务学习者),提出GPT-2模型。论文地址: https://paperswithcode.com/method/gpt-2
2020年5月,OpenAI 发布论文《Language Models are Few-Shot Learners》(语言模型应该是一个少量样本(few-shot)学习者,提出GPT-3模型。论文地址: https://paperswithcode.com/method/gpt-3
2022年2月底,OpenAI 发布论文《Training language models to follow instructions with human feedback》(使用人类反馈指令流来训练语言模型),公布Instruction GPT模型。论文地址: https://arxiv.org/abs/2203.02155
2022年11月30日,OpenAI推出ChatGPT模型,并提供试用,全网火爆。见:AI-001-火爆全网的聊天机器人ChatGPT能做什么
3、GPT之T-Transformer(2017)
在第1小节中,我们说到Transformer是没有合适的翻译的。
但是Transfomer却是GPT(Generative Pre-Training Transfomer)中最重要、最基础的关键词。
(注:GPT的Transformer相比google论文原版Transformer是简化过的,只保留了Decoder部分,见本文4.3小节)
3.1、重点在好,还是重点在人?
就像好人,最关键的是好,还是人?

读者们,是好吗?
一个稍稳妥的答复是:既不是好,也不是人;既是好,也是人。
唔,有点绕,那么说人话一点,展开: 语义上,重点在好; 基础和前提上,重点在人。
3.2、对不起,你是个好人
再延展一下,那"对不起,你是个好人"呢?

语义的重点,变成是对不起。但是语义的前提,还是人。

3.3、回归正题,Transfomer是什么
这篇《十分钟理解Transfomer》( https://zhuanlan.zhihu.com/p/82312421 ) 可以看一下。
看懂了可以忽略我接下来关于Transfomer的内容,直接跳到第4章节。如果没太看懂,可以看下我的理解,对你或许有一定参考作用。
3.3.1、上一代RNN模型的重大缺陷
在Transformer模型出来前,RNN模型(循环神经网络)是典型的NLP模型架构,基于RNN还有其他一些变种模型(忽略其名字,Transformer出来后,已经不再重要了),但是都存在相同的问题,并没能很好解决。
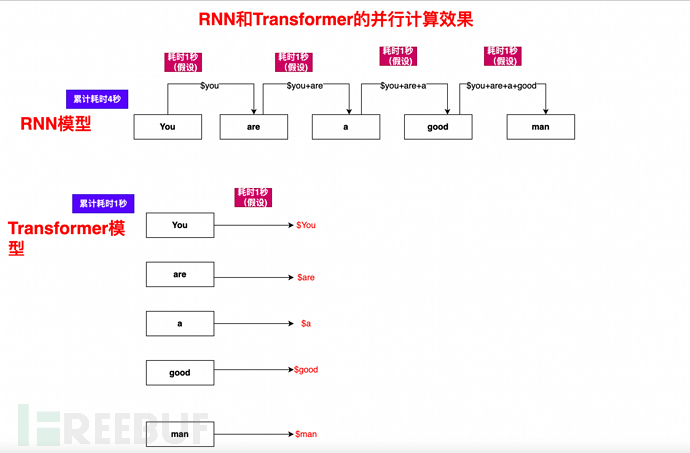
RNN的基本原理是,从左到右浏览每个单词向量(比如说this is a dog),保留每个单词的数据,后面的每个单词,都依赖于前面的单词。
RNN的关键问题:前后需要顺序、依次计算。可以想象一下,一本书、一篇文章,里面是有大量单词的,而又因为顺序依赖性,不能并行,所以效率很低。
这样说可能大家还是不容易理解,我举一个例子(简化理解,和实际有一定出入):
在RNN循环中,You are a good man这句话,需要如何计算呢?
1)、You和You are a good man计算,得到结果集$You
2)、基于$You的基础上,再使用Are和You are a good man,计算得出$Are
3)、基于$You、$Are的基础,继续计算$a
4)、依此类推,计算$is、$good、$man,最终完成You are a good man的所有元素的完整计算
可以看到,计算过程是一个一个、顺次计算,单一流水线,后面的工序依赖前面的工序,所以非常慢
3.3.2、Transformer之All in Attention
前面我们提到,2017年6月,Google发布论文《Attention is all you need》,首次提出Transformer模型,成为GPT发展的基础。 论文地址: https://arxiv.org/abs/1706.03762
从其标题《Attention is all you need》你就能知道,Transfomer其实主张是"All in Attention"。
那么什么是Attention(注意力)呢?
在《Attention is all you need》论文中,可以看到其定义如下:
自我注意(self-Attention),有时称为内部注意,是一种将单个序列的不同位置联系起来的注意力机制,以便计算序列的表示。自我注意已成功地应用于阅读理解、抽象概括、语篇包含和学习任务无关的句子表示等多种任务中

简单理解,就是单词与单词之间的关联度,通过注意力(Attention) 这个向量来描述。
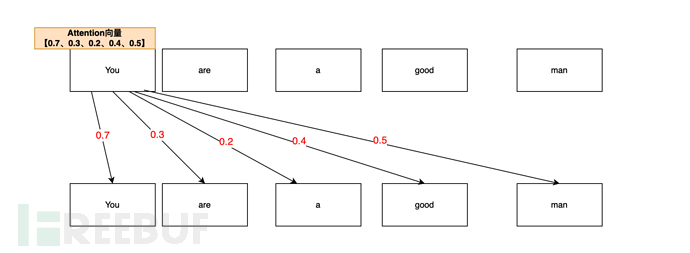
比如说You are a good man(你是个好人),AI在分析You的注意力向量时,可能是这么分析的:
从Your are a good man这句话中,通过注意力机制进行测算,You和You(自身)的注意力关联概率最高(0.7,70%),毕竟 你(you)首先是你(you);于是You,You的注意力向量是 0.7
You和man(人)的注意力关联其次(0.5,50%),你(you)是个人(man),,于是You,man的注意力向量是0.5
You和good(好)的注意力关联度再次(0.4,40%),你在人的基础上,还是一个好(good)人。于是You,good的注意力向量值是0.4
You,are向量值是 0.3;You,a的向量值是0.2。
于是最终You的注意力向量列表是【0.7 、 0.3、0.2、0.4、0.5】(仅本文举例)。
3.4、论文中对attention和Transfomer的价值描述
在论文中,google对于attention和transfomer的描述,主要强调了传统模型对顺序依赖存在,Transformer模型可以替代当前的递归模型,消减对输入输出的顺序依赖。


3.5、Transformer机制的深远意义
Transformer问世后,迅速取代循环神经网络RNN的系列变种,成为主流的模型架构基础。
如果说 可以并行、速度更快都是技术特征,让行外人士、普罗大众还不够直观,那么从 当前ChatGPT的震憾效果就可以窥知一二。
**Transformer从根本上解决了两个关键障碍,其推出是变革性的、革命性的**。
3.5.1、摆脱了人工标注数据集(大幅降低人工数量 )
这个关键障碍就是:过往训练我们要训练一个深度学习模型,必须使用大规模的标记好的数据集合(Data set)来训练,这些数据集合需要人工标注,成本极高。
打个比方,就是机器学习需要大量教材,大量输入、输出的样本,让机器去学习、训练。这个教材需要量身制定,而且需求数量极大。

好比 以前要10000、10万名老师编写教材,现在只需要10人,降低成千上万倍。 
那么这块是怎么解决的呢?简单描述一下,就是通过Mask机制,遮挡已有文章中的句段,让AI去填空。
好比是一篇已有的文章、诗句,挡住其中一句,让机器根据学习到的模型,依据上一句,去填补下一句。
如下图示例:


这样,很多现成的文章、网页、知乎问答、百度知道等,就是天然的标注数据集了(一个字,超省钱)。
3.5.2、化顺序计算为并行计算,巨幅降低训练时间
除了人工标注之外,在3.3.1小节中提到RNN的重大缺陷,就是顺序计算,单一流水线的问题。
Self-Attention机制,结合mask机制和算法优化,使得 一篇文章、一句话、一段话能够并行计算。
还是以You are a good man举例,可以看到,计算机有多少,Transformer就能有多快:


4、GPT(Generative Pre-Training)-2018年6月
接下来,就到了ChatGPT的前世-GPT(1)了。
2018年6月,OpenAI 发布论文Improving Language Understanding by Generative Pre-Training》(通过生成式预训练提升语言理解能力),首次提出GPT模型(Generative Pre-Training)。论文地址: https://paperswithcode.com/method/gpt 。
4.1、GPT模型的核心主张1-预训练(pre-training)
GPT模型依托于Transformer解除了顺序关联和依赖性的前提,提出一个建设性的主张。
先通过大量的无监督预训练(Unsupervised pre-training),
注:无监督是指不需要人介入,不需要标注数据集(不需要教材和老师)的预训练。
再通过少量有监督微调(Supervised fine-tunning),来修正其理解能力。

4.1.1、打个比方
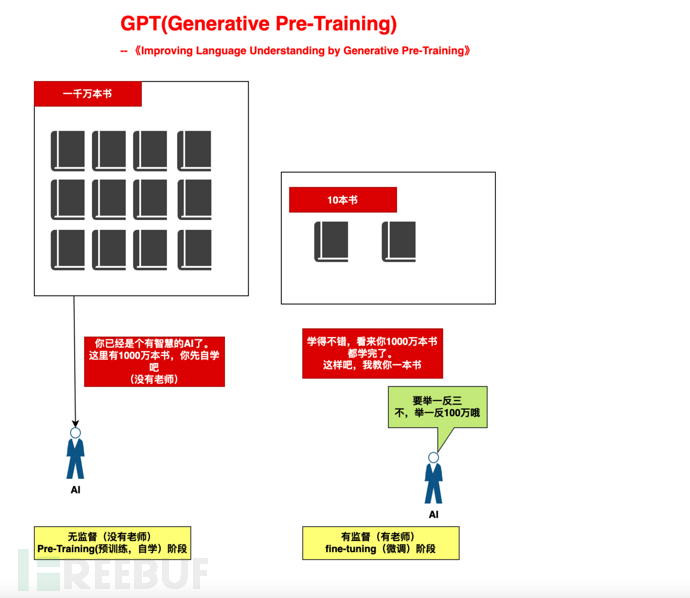
打个比方,就好像我们培养一个小孩,分了两个阶段:
1)、大规模自学阶段(自学1000万本书,没有老师):给AI提供充足的算力,让其基于Attention机制,自学。
2)、小规模指导阶段(教10本书):依据10本书,举一反"三"

4.1.2、论文开篇的描述
所谓开宗明义,从开篇introduction中,也可看到GPT模型对于监督学习、手动标注数据的说明。

4.2、GPT模型的核心主张2-生成式(Generative)
在机器学习里,有判别式模式(discriminative model)和生成式模式(Generative model)两种区别。
GPT(Generative Pre-Training)顾名思义,采用了生成式模型。
生成式模型相比判别式模型更适合大数据学习 ,后者更适合精确样本(人工标注的有效数据集)。要**更好实现预训练(Pre-Training)**,生成式模式会更合适。
注:本小节重点在于上面一句话(更适合大数据学习),如果觉得理解复杂,本小节下面可不看。
在wiki生成式模型的材料里( https://en.wiki敏pedia感.org/wiki/Generative_model ) ,举了一个如下说明两者的区别:

单看上面可能不容易看懂,这里补充解释下。
上面的意思是说,假设有4个样本:
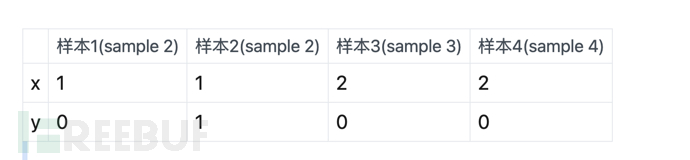
那么生成式(Generative Model)的特征就是概率不分组(计算样本内概率,除以样本总和),以上表为例,发现x=1,y=0的总共有1个,所以会认为x=1,y=0的几率为1/4(样本总数为4)。
同样的,x=2,y=0的总共有2个,则x=2,y=0的概率 为2/4.

而判别式(Discriminative Model)的特征则是**概率分组计算(计算组内概率 ,除以组内总和)**。 以上表为例,x=1,y=0一共有1个,同时x=1的分组一共有2个sample,所以其概率为 1/2。
同样的,x=2,y=0的总共有2个。且同时x=2的分组共有2个sample,则x=2,y=0的概率 为2/2=1(即100%)。

4.3、GPT相比原版Transfomer的模型改进
下面是GPT的模型说明,GPT训练了一个12层仅decoder的解码器(decoder-only,没有encoder),从而使得模型更为简单。
注1:google论文《Attention is all you need》原版Transformer中,包含Encoder和Decoder两部分,前者(Encoder)对应的是 翻译,后者(Decoder)对应的是 生成。
注2:google以Encoder为核心,构建了一个BERT(Bidirectional Encoder Representations from Transformers,双向编码生成Transformer)模型。里面的双向(Bidirectional),是指BERT是同时使用上文和下文预测单词,因此 BERT 更擅长处理自然语言理解任务 (NLU)。
注3:本小节要点,GPT基于Transformer,但是相比Transformer又简化了模型,去掉了Encoder,只保留了Decoder。同时,相比BERT的上下文预测(双向),GPT主张仅使用单词的上文预测单词(单向),从而使模型更简单、计算更快,更适合于极致的生成,并因此GPT更擅长处理自然语言生成任务 (NLG),也就是我们在AI-001-火爆全网的聊天机器人ChatGPT能做什么发现的,ChatGPT很擅长写"作文"、编瞎话。 理解本段后,本小节后面的可不看。
注4:从模拟人类来看,GPT的机制得更像真实人类。因为人类也是根据上文(前面说的)来推测下文(即说后面的),所谓说出去的话就像泼出去的水,人类也是没办法根据后面说的话,来调整前面说的话的,即使说错了,恶语伤人心,也只能基说出去的话(上文)进行补救、解释。

4.3.1、架构图对比
下图为Transfomer模型架构和GPT模型架构的对比(分别来自论文《Attention is all you need》和《Improving Language Understanding by Generative Pre-Training》)
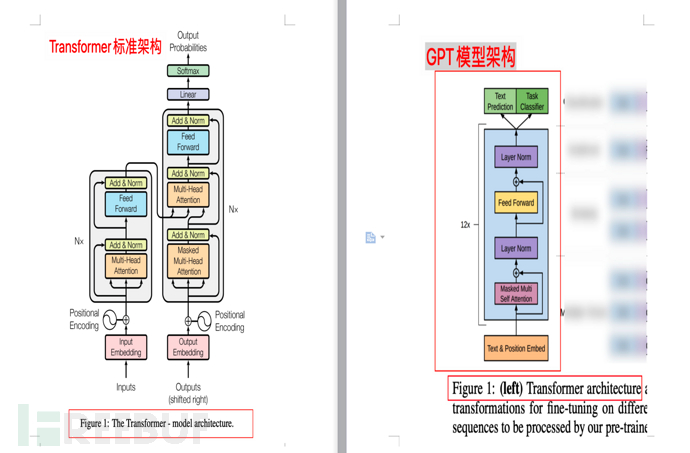
4.4、GPT模型的训练规模
前面提到生成式模式更有利于大数据集的Pre-Training预训练,那么GPT使用了多大规模的data set(数据集)呢?
论文中有提到,它采用了一个名为BooksCorpus的数据集,包含了超过7000本未发表书籍。

5、GPT-2(2019年2月)
2019年2月,OpenAI 发布论文《Language Models are Unsupervised Multitask Learners》(语言模型应该是一个无监督多任务学习者),提出GPT-2模型。论文地址: https://paperswithcode.com/method/gpt-2
5.1、GPT-2模型相比GPT-1的核心变化
前面提到,GPT的核心主张有Generative(生成式)、Pre-Training。同时,GPT训练有两步:
1)、大规模自学阶段(Pre-Training预训练,自学1000万本书,没有老师):给AI提供充足的算力,让其基于Attention机制,自学。
2)、小规模指导阶段(fine-tuning微调,教10本书):依据10本书,举一反"三"
GPT-2的时候,OpenAI将有监督fine-tuning微调阶段给直接去掉了,将其变成了一个无监督的模型。
同时,增加了一个关键字**多任务(multitask)**,这点从其论文名称《Language Models are Unsupervised Multitask Learners》(语言模型应该是一个无监督多任务学习者)也可看出。

5.2、为什么这么调整?试图解决zero-shot问题
GPT-2为什么这么调整?从论文描述来看,是为了尝试解决**zero-shot(零次学习问题)**。
zero-shot(零次学习)是一个什么问题呢?简单可理解为推理能力。就是指面对未知事物时,AI也能自动认识它,即具备推理能力。
比如说,在去动物园前,我们告诉小朋友,像熊猫一样,是黑白色,并且呈黑白条纹的类马动物就是斑马,小朋友根据这个提示,能够正确找到斑马。
5.3、multitask多任务如何理解?
传统ML中,如果要训练一个模型,就需要一个专门的标注数据集,训练一个专门的AI。
比如说,要训练一个能认出狗狗图像的机器人,就需要一个标注了狗狗的100万张图片,训练后,AI就能认出狗狗。这个AI,是专用AI,也叫single task。
而multitask多任务,就是主张不要训练专用AI,而是喂取了海量数据后,任意任务都可完成。
5.4、GPT-2的数据和训练规模
数据集增加到800万网页,40GB大小。

而模型自身,也达到最大15亿参数、Transfomer堆叠至48层。简单类比,就像是模拟人类15亿神经元(仅举例,不完全等同)。

6、GPT-3(2020年5月)
2020年5月,OpenAI 发布论文《Language Models are Few-Shot Learners》(语言模型应该是一个少量样本(few-shot)学习者),提出GPT-3模型。论文地址: https://paperswithcode.com/method/gpt-3
6.1、GPT-3的突破式效果进展
论文中对于效果是这么描述的:
1、GPT-3在翻译 、问题回答和完形填空中表现出强大的性能,同时能够解读单词、句子中使用新单词或执行3位数算订。
2、GPT-3可以生成新闻文章的样本,人类已然区分不出来。
如下图:

6.2、GPT-3相比GPT-2的核心变化
前面提到GPT-2在追求无监督、zero-shot(零次学习),但是其实在GPT-2论文中,OpenAI也提出结果不达预期。这显然是需要调整的,于是GPT-3就进行了相关调整。 从标题《Language Models are Few-Shot Learners》(语言模型应该是一个少量样本(few-shot)学习者)也可看出。
说白了,zero-shot(零次学习)不靠谱。

并且,在训练过程中会对比Zero-shot零次学习 ;One-shot(单一样本学习)、Few-shot(少量样本学习),以及fine-tuning人工微调的方式。
最后在多数情况下,few-shot(少量样本)的综合表现,是在无监督模式下最优的,但稍弱于fine-tuning微调模式。
从下述论文表格、图形中,也可看出few-shot是综合表现仅弱于fine-tuning微调的。
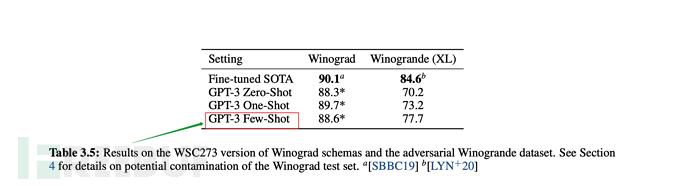
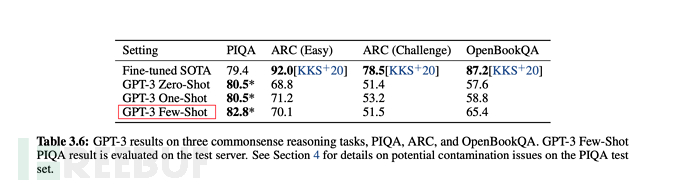
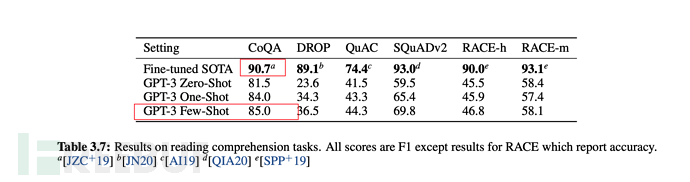
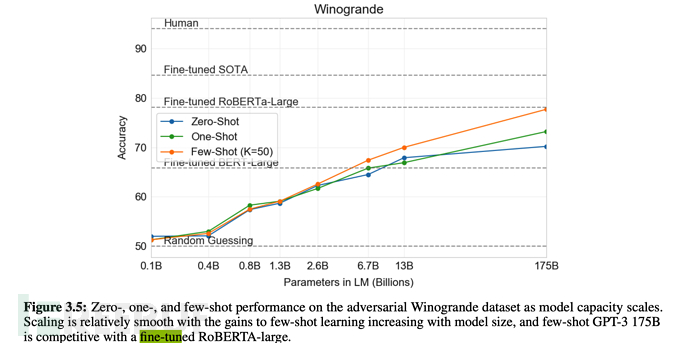
6.3、GPT-3的训练规模
GPT-3采用了过滤前45TB的压缩文本,并且在过滤后也仍有570GB的海量数据。

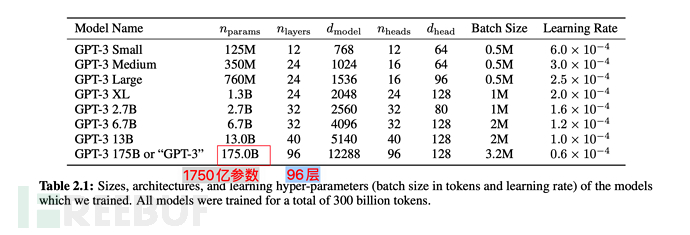
在模型参数上,从GPT-2的15亿,提升到1750亿,翻了110多倍;Transformer Layer也从48提升到96。
7、Instruction GPT(2022年2月)
2022年2月底,OpenAI 发布论文《Training language models to follow instructions with human feedback》(使用人类反馈指令流来训练语言模型),公布Instruction GPT模型。论文地址: https://arxiv.org/abs/2203.02155
7.1、Instruction GPT相比GPT-3的核心变化
Instruction GPT是基于GPT-3的一轮增强优化,所以也被称为GPT-3.5。
前面提到,GPT-3主张few-shot少样本学习,同时坚持无监督学习。
但是事实上,few-shot的效果,显然是差于fine-tuning监督微调的方式的。
那么怎么办呢? 走回fine-tuning监督微调?显然不是。
OpenAI给出新的答案: 在GPT-3的基础上,基于人工反馈(RHLF)训练一个reward model(奖励模型),再用reward model(奖励模型,RM)去训练学习模型。
天啦噜,夭寿了。。要用机器(AI)来训练机器(AI)了。。

7.2、Insctruction GPT的核心训练步骤
Instruction GPT一共有3步:
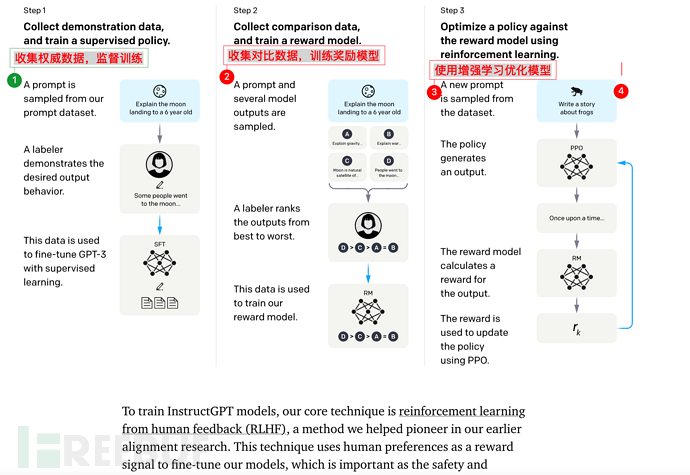
1)、对GPT-3进行**fine-tuning(监督微调)**。
2)、再训练一个Reward Model(奖励模型,RM)
3)、最后通过增强学习优化SFT


值得注意的是,第2步、第3步是完全可以迭代、循环多次进行的。
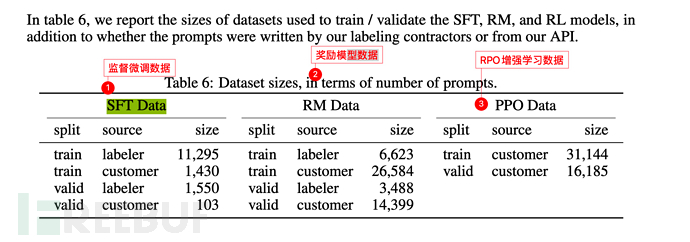
7.3、Instruction GPT的训练规模
基础数据规模同GPT-3(见6.3小节),只是在其基础上增加了3个步骤(监督微调SFT、奖励模型训练Reward Model,增强学习优化RPO)。
下图中labeler是指OpenAI雇佣或有相关关系的**标注人员(labler)**。
而customer则是指GPT-3 API的调用用户(即其他一些机器学习研究者、程序员等)。
本次ChatGPT上线后据说有百万以上的用户,我们每个人都是其customer,所以可以预见,未来GPT-4发布时,其customer规模至少是百万起。
8、ChatGPT(2022年11月)
2022年11月30日,OpenAI推出ChatGPT模型,并提供试用,全网火爆。
见:AI-001-火爆全网的聊天机器人ChatGPT能做什么
8.1、ChatGPT和Instruction GPT
ChatGPT和InstructionGPT本质上是同一代际的,仅仅是在InstructionGPT的基础上,增加了Chat功能,同时开放到公众测试训练,以便产生更多有效标注数据。
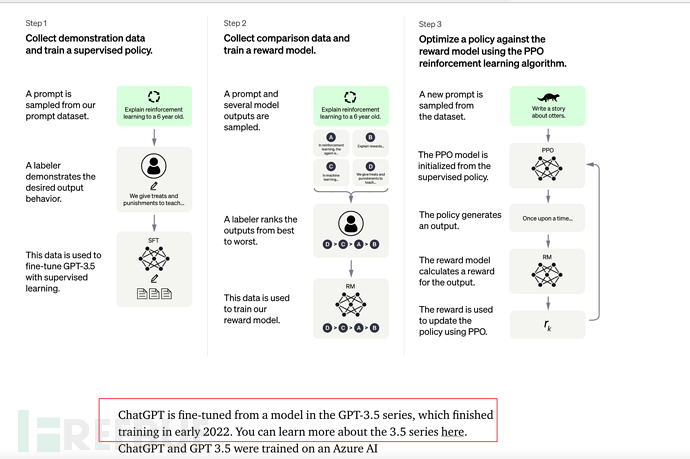
8.2、【重要,建议浏览下面推荐的视频】从人的直观理解上,补充解释一下ChatGPT的核心原理
可参考 台大教授李宏毅的视频《ChatGPT是怎么炼成的?GPT社会化过程》,讲得很好。
https://www.inside.com.tw/article/30032-chatgpt-possible-4-steps-training
GPT是单向生成,即根据上文生成下文。
比如说有一句话:
向GPT模型给出输入 你好,下面一个字是接你好吗?你好帅?你好高?你好美?等等,GPT会计算出一个概率,给出最高的那个概率作为回答。
依此类推,如果给出一个指令(或称为Prompt),ChatGPT也会依据上文(prompt)进行推算下文(回答),同时选择一个最大概率的上文进行回答。
如下图:
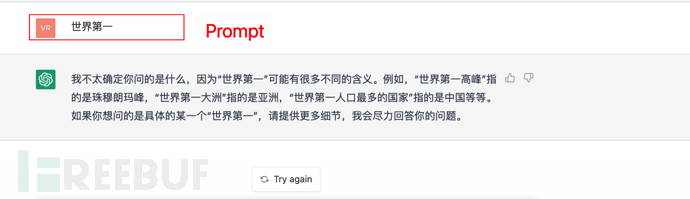
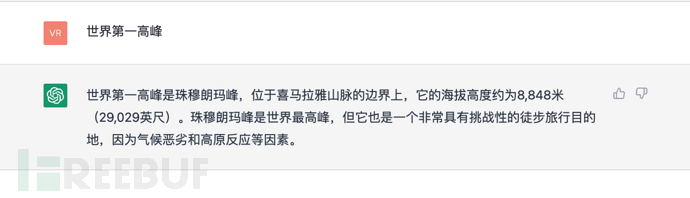
9、小结
总结:
1)、2017年,谷歌发布论文《Attention is all you need》,提出Transformer模型,为GPT铺就了前提。
2)、2018年6月,OpenAI发布了GPT生成式预训练模型,通过BooksCorpus大数据集(7000本书)进行训练,并主张通过大规模、无监督预训练(pre-training)+有监督微调(fine-tuning)进行模型构建。
3)、2019年2月,OpenAI发布GPT-2模型,进一步扩大了训练规模(使用了40GB数据集,最大15亿参数(parameters))。同时在思路上,去掉了fine-tuning微调过程,强调zero-shot(零次学习)和multitask(多任务)。但是最终zero-shot效果显著比不上fine-tuning微调。
4)、2020年5月,OpenAI发布GPT-3模型,进一步扩大了**训练规模(使用了570GB数据集,和1750亿参数)**。同时采取了few-shot(少量样本)学习的模式,取得了优异效果。 当然,在实验中同步对比了fine-tuning,比fine-tuning效果略差。
5)、2022年2月,OpenAI发布Instruction GPT模型,此次主要是在GPT-3的基础上,增加了监督微调(Supervised Fine-tuning)环节,并且基于此,进一步加入了Reward Model奖励模型,通过RM训练模型来对学习模型进行RPO增强学习优化。
6)、2022年11月30日,OpenAI发布ChatGPT模型,可以理解为一个多轮迭代训练后的InstructionGPT,并在此基础上增加了Chat对话聊天功能。
10、未来将来(GPT-4 or ?)
从种种迹象来看,GPT-4或许将于2023年亮相?它会有多强大呢?
同时ChatGPT的效果,牵引了业界众多目光,想必接下来更多基于GPT的训练模型及其应用,会更加百花齐放。
未来将来,拭目以待。
部分参考资料
ai.googleblog.com/2017/08/transformer-novel-neural-network.html
https://arxiv.org/abs/1706.03762
https://paperswithcode.com/method/gpt
https://paperswithcode.com/method/gpt-2
https://paperswithcode.com/method/gpt-3
https://arxiv.org/abs/2203.02155
https://zhuanlan.zhihu.com/p/464520503
https://zhuanlan.zhihu.com/p/82312421
https://cloud.tencent.com/developer/article/1656975
https://cloud.tencent.com/developer/article/1848106
https://zhuanlan.zhihu.com/p/353423931
https://zhuanlan.zhihu.com/p/353350370
https://juejin.cn/post/6969394206414471175
https://zhuanlan.zhihu.com/p/266202548
https://en.wiki敏pedia感.org/wiki/Generative_model
https://zhuanlan.zhihu.com/p/67119176
https://zhuanlan.zhihu.com/p/365554706
https://cloud.tencent.com/developer/article/1877406
https://zhuanlan.zhihu.com/p/34656727
https://zhuanlan.zhihu.com/p/590311003
如需授权、对文章有疑问或需删除稿件,请联系 FreeBuf 客服小蜜蜂(微信:freebee1024)






- 19 文章数
- 52 关注者