


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

 CDra90n
CDra90n- 关注
在线社交网络 (OSN) 正在面临复杂的网络威胁,这些威胁通常使用虚假或篡改的个人资料。自动化代理(又名社交机器人)是一类复杂的现代威胁实体,负责各种现代武器化信息相关攻击,例如 错误信息传播和垃圾邮件。检测社交机器人是一项具有挑战性且至关重要的任务,因为它们具有模仿人类行为的欺骗性特征。
本研究提出了一种注意力感知的深度神经网络模型 DeepSBD,用于检测 OSN 上的社交机器人。 DeepSBD 使用个人资料、时间、活动和内容信息对用户的行为进行建模。它使用双向长短期记忆 (BiLSTM) 和卷积神经网络 (CNN) 架构联合建模 OSN 用户的行为。它将个人资料、时间和活动信息建模为序列,这些信息被馈送到两层的 BiLSTM,而内容信息被馈送到深度 CNN。
0x01 基础知识
A. LSTM
循环神经网络 (RNN) 是一种人工神经网络,用于处理序列数据以对时间动态行为进行建模。 RNN 由循环的隐藏状态组成,其值取决于先前的状态。长短期记忆(LSTM)是一种包含记忆块而不是自连接隐藏单元的RNN。因此,LSTM 解决了梯度消失问题。在 LSTM 中,记忆块由记忆单元组成,这使得神经网络能够智能地决定记住什么和忘记什么,使其能够学习远程上下文信息。早期的 LSTM 单元由三个组件组成,即输入门、输出门和单元状态。现在,一个标准的 LSTM 单元由四个组件组成,包括遗忘门。在时间 t 的输入门,它通过逐点加法来控制单元格中的值流,以将单元格状态更新为新值。使用等式 1 将更新的信息写入单元状态。忘记门在时间 t 的输出 ft 确定要擦除的信息量,如等式 2 中所定义。候选单元值 C∼t,基于当前输入使用等式 3 确定。当前单元状态 Ct 使用 C∼t、it、ft 和先前的单元状态 Ct-1 使用等式 4 更新。LSTM 单元的最终输出 ht 使用等式 6 计算,其中ot 表示输出门的输出,如等式 5 中所定义。
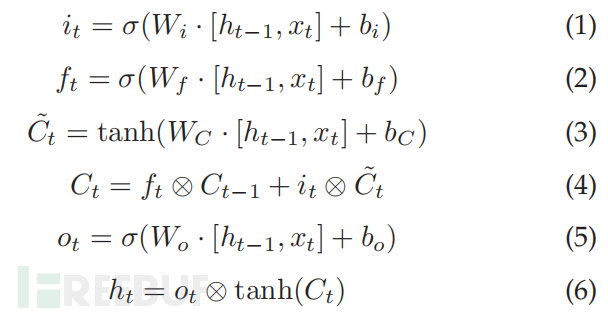
在这些等式中,W 和 b 分别代表权重和偏置向量。 σ() 和 tanh 分别表示 sigma 和双曲正切函数,⊗ LSTM 表示逐元素乘法。经典LSTM只包含来自序列的历史信息,完全忽略了序列中前面的信息。双向 LSTM (BiLSTM) 通过结合序列的后向和前向上下文信息解决了这个问题。此外,深度 RNN 学习更好的低级特征表示和更高的模型复杂度。因此,在本文中使用了堆叠的 BiLSTM 来结合顺序数据的前后上下文信息,并具有更好的低级特征表示。
B. 卷积神经网络
卷积神经网络 (CNN) 是一类人工神经网络,用于处理以网格格式组织的数据,例如以矩阵形式组织的图像和文本。经典的 CNN 通常由两层组成——卷积和池化。卷积层使用称为卷积的线性数学运算从输入表格数据中提取高级特征图,而池化层应用池化操作从特征图中提取重要特征。尽管 CNN 最初是为处理图像而开发的,但由于其强大的特征提取能力,它现在被广泛用于各种自然语言处理和文本分类任务。
C. 注意力机制
Attention意味着专注于一个或多个组件而忽略其他组件。专注于特定单元使机器学习模型更加智能。通常,基于神经网络的分类系统将数据建模为由低级特征组成的数字向量,其中所有特征都被分配相同的权重,而不管它们对数据进行概念化的潜力如何。使用注意力机制解决了对所有特征进行同等相关分配的问题,该机制根据不同特征的重要性为不同特征分配可变权重。注意力机制可以应用于不同的粒度级别,如单词、短语和句子。
此外,注意力机制使神经模型能够根据特征的相关性对特征进行排名。这种机制背后的主要思想是计算输入特征的权重分布,以将更高的值分配给具有更高等级的那些特征。注意层由对齐层、注意权重和上下文向量组成。首先,对齐层计算编码向量 h = {h1, h2,...,hn} 和顶点向量 v 之间的对齐分数。此后,通过对 h 的所有 n 个元素进行归一化,应用 softmax 来计算概率分布 αi , 其中 i = 1, 2,...,n,如等式 7 所示。较大的 αi 意味着 hi 为 v 贡献了重要信息。注意力机制的输出 O 是编码向量中所有元素的加权和h,在公式 8 中给出。
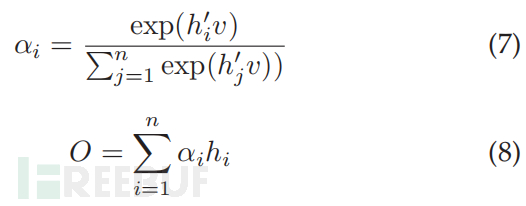
D. 词嵌入
词的分布表示是生成包含上下文信息的数字向量表示的最新和流行的方法。文本内容的数字向量表示可以在不同的粒度级别上生成,例如单词、短语、句子或段落。此外,像加法、减法和连接这样的向量运算可以在较小成分(单词、短语或句子)的向量上进行,以获得较大成分(句子、段落或文档)的向量表示。在分布式表示中,词嵌入的每个维度代表一个潜在概念,该概念基于该词与语料库中其他词的共现。在本文中使用了免费提供的预训练 200 维 GloVe 词向量,在 20 亿条推文的语料库上进行训练。
0x02 DeepSBD
本节介绍了所提出的 DeepSBD 模型的架构,它由四层组成,即(i)输入层,(ii)低级特征表示层,(iii)用户表示层和(iv)输出层,如图所示。
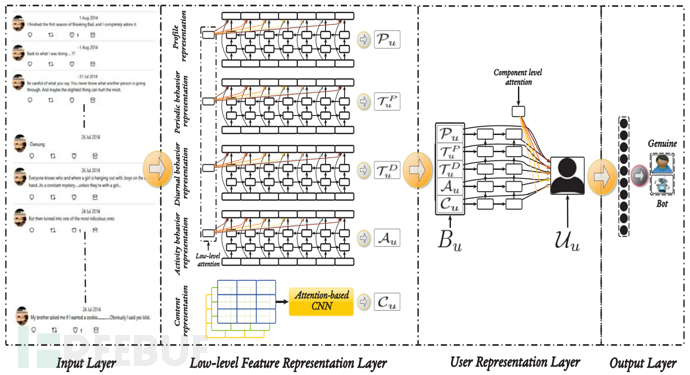
A. 输入层
由于用户通常基于身份和行为在现实世界中进行表征,因此 DeepSBD 使用个人资料和行为特征对 OSN 用户进行建模。为此,DeepSBD 的输入层用于读取个人资料、推文和相关元数据信息以学习用户表示,如下小节所述。
B. 低级特征表示层
在现实世界中,个人/社区在物理特征和行为方面彼此不同。这种身份和行为的差异也存在于 OSN 上。社区内的用户通常在身体和行为特征方面具有凝聚力。同样,在 OSN 上,社交机器人和良性用户在个人资料信息、状态发布行为和话题倾向方面有所不同。低级特征表示层使用代表用户行为的神经网络技术从个人资料、时间、活动和内容信息中提取细粒度特征。以下小节详细介绍了学习用户的不同行为表示。
(1)个人资料表示
根据现实世界的身份,用户在 OSN 上拥有不同的个人资料信息。然而,社交机器人没有任何真实世界的身份,并使用手动或自动创建的虚假个人资料信息,如用户名、描述。为了躲避检测系统,攻击者通常手动创建个人资料以使其看起来真实。另一方面,自动创建的社交机器人在其个人资料信息中显示出规律性。为了检测社交机器人在其个人资料信息中的规律性,DeepSBD 使用 12 个基本特征对用户的身份相关信息进行建模——状态数、关注者数、朋友数、收藏数、列表数、帐户年龄(以天为单位)、关注率、好友率、状态率、关注者与好友的比率、默认个人资料状态以及是否启用地理位置。追随者率表示用户每天获得的追随者数量。其他与平均值相关的特征也是按天计算的。使用了可以直接从用户个人资料中提取(或几乎不需要计算)的简单特征,以避免手动制作复杂的特征。个人资料特征向量 Pu 被传递给基于注意力的两层堆叠 BiLSTM,以学习基于个人资料的低级表示 Pu。
(2)时间行为表示
在设计社交机器人时,通常使用一些调度算法来确定活动时间。活动时间不是完全随机的,而是遵循一定的分布。因此,自动化账户在活动时间上具有一定程度的规律性。相比之下,人类的活动时间通常是随机的和不可预测的。为了观察账户的规律性和自动化,推文时间的建模至关重要。因此对推文时间进行时间分析,以观察用户帐户的自动化。通常,机器人被编程为处于活动状态: (i) 在一天中的特定时间代表昼夜模式,(ii) 或在代表周期性模式的某些特定时间间隔之后。因此,DeepSBD 使用从用户 u 的时间轴中提取的 30 天推文(如果可用)或至少 100 条推文的时间信息对用户 u 的两种类型的时间行为进行建模。以下段落中描述的昼夜和周期性时间建模使用所有四种类型的推文活动的时间信息——普通推文、转发、引用推文和回复。
1)昼夜行为表示
如前所述,机器人可以编程为在一天中的特定时间处于活动状态,代表昼夜模式。使用推特活动的时间信息对这些机器人进行建模。为此,将用户 u 的 Twitter 时间线划分为天,其中每天 d ∈ D 被划分为 1 分钟的时间间隔序列,假设 τ = {τ1, τ2,...,τ1440} 因为1 天=24×60 分钟,其中 |D|表示 u 的第一个和最后一个爬取的推文之间的天数。此外,将 u 在一天中特定分钟内的推文活动数分配给一天中的相应分钟向量 du。例如,如果 u 在凌晨 1 点 30 分到凌晨 1 点 31 分之间(即第 i 天 di 的第 91 分钟)执行 2 次转发活动,发布 1 条推文,并回复了一条推文,则第 i 天的第 91 个索引第一天时间向量 diu 被赋值为 4。最后, diu 的日时间行为表示为 {dvi1 , dvi2, . . . , dvi1440 },其中 dvi1表示 u 在 di 的第一分钟执行的活动数。类似地,如果存在推文,则为 30 天中的每一天构建昼夜时间向量;否则,生成零向量。最后将 u 的每一天的日时间向量连接起来,以创建最终的日时间向量 Du。此后,将 Du 向量传递给基于注意力的两层堆叠 BiLSTM,以提取基于昼夜行为的低级特征 TDu。
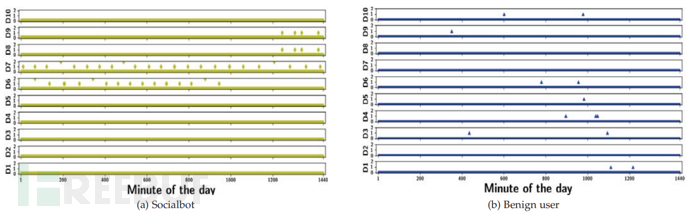
上图(a) 和 2(b) 分别显示了随机抽样的社交机器人和良性用户的昼夜时间行为,以及 10 天内一天中每一分钟执行的推文活动的数量。在图中X 轴代表一天中的分钟,Y 轴代表一天中特定分钟内执行的推文活动的数量。由于可见性问题,仅将一分钟内最多 2 条推文的推文计数可视化。从图(a) 可以看出,社交机器人显示出一种昼夜模式,并被激活以在一天中的某些特定时间执行推特活动。此外,机器人还会在一分钟内多次执行 2 次活动,例如在第 6 天执行 3 次,这是可疑的。图(b) 显示,良性用户在推文时间的时间分布上是相当随机的,并且没有表现出任何昼夜行为。
2)周期性行为表示
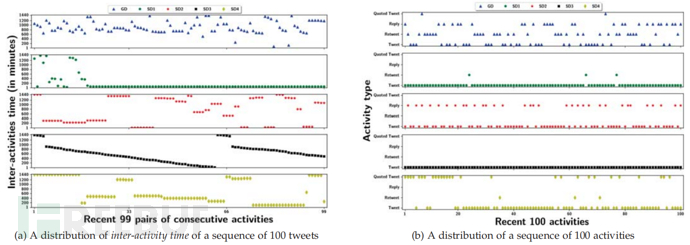
机器人可以被编程为在固定的时间间隔内活动,并具有一些不规则性,代表推文间时间的周期性模式。在本节中对用户的此类行为进行建模,以将社交机器人与良性用户区分开来。为此,计算每对连续推文之间的交互活动时间。在这个行为建模中考虑了所有四种类型的推文的时间戳序列,没有分组。给定用户 u,如果 T1 和 T2 分别表示推文 t1 和 t2 的发布时间,则 ΔT(1,2) = T2 - T1 表示 t1 和 t2 之间的交互时间。同样,计算每对连续推文之间的 ΔT。使用 ΔTu 表示 u 的一组 N 个推文上的所有交互活动时间的集合。此后,将 ΔTu 赋予基于注意力的两层堆叠 BiLSTM,以提取基于周期性行为的低级特征 TuP。调查了社交机器人和良性用户的交互活动时间分布,并观察到非常不同的行为。下图(a) 显示了一组四个随机选择的社交机器人的交互活动时间分布,四个社交机器人数据集中各有一个,以及一个良性用户。
在这个图中,下面的四个子图代表社交机器人的行为,最上面的子图代表良性用户的行为。 X 轴和 Y 轴分别代表活动对和交互时间。对下面四个子图的分析表明,四个社交机器人根据其使用者设计的自动化策略显示出一定的周期性模式。从下图(a) 底部的第二个子图中可以看出,第二个社交机器人显示出强烈的周期性模式,其交互活动时间分布呈衰减趋势。该图还表明,第三个社交机器人使用了一些复杂的调度算法来模仿随机行为,但其交互活动时间分布虽然不强,但仍呈现出适度的格局。相比之下,该图最上面的子图显示,良性用户在发帖中没有表现出任何周期性模式。所有这些分析都揭示了社交机器人对调度算法的使用。
(3)活动序列行为表示
在 OSN 中,不同的社交机器人根据其攻击者的需要执行不同的活动。有些机器人被注入转发推文,而一些机器人回复查询(通常在良性机器人的情况下)。尽管社交机器人可以执行所有可能的活动,如推文、转发和回复,但它们遵循特定的分布,即接下来要执行的推文活动类型。因此,活动顺序是社交机器人检测的一个很好的指标。 DeepSBD 使用所有四种活动(推文、转发、回复和引用推文)对用户的活动序列行为进行建模。为每个用户选择 100 条推文来编码他们的活动序列行为。为每个用户选择相同数量的活动,以确保所有用户的编码行为表示的长度相等。在活动序列表示中,四个活动中的每一个都使用唯一编号进行编码 - 普通推文为 0,转发为 1,回复为 2,引用推文为 3。例如,给定来自某个时间轴的最近 100 个活动用户 u,其基于活动的行为可以编码为 {01, 12, 13, 04,..., 2100},其中 13 表示 u 的第三个活动是转推。还对活动序列进行了可视化分析,以识别社交机器人和良性用户的行为差异。上图(b)表示一组四个随机选择的社交机器人(每个社交机器人数据集中一个)和一个良性用户的示例活动序列。在该图中,下面的四个子图代表社交机器人的行为,而最上面的子图代表良性用户的行为。该图显示社交机器人的活动序列遵循一定的模式,其中第二个和第四个社交机器人只发布推文,不执行其他活动。对底部第三个子图的一个观察是,相应的社交机器人会定期发布一些推文,然后进行回复。相反,良性用户的活动序列表现出非常随机的行为。此外,将用户 u 的编码活动序列作为输入提供给基于注意力的两层堆叠 BiLSTM,以学习基于低级活动序列的特征表示 Au。
(4)内容行为表示
现有文献已使用推文内容中的规律性进行社交机器人检测 [7]。 DeepSBD 通过使用 GloVe 词嵌入以矩阵形式对推文进行编码,从推文内和推文间内容中提取模式。假设用户 u 发布了 N 条推文,例如 t1, t2,...,tN ,首先,推文按时间顺序排序。此后,每条推文 ti 使用空白空间进行标记,并且使用 GloVe 向量将每个标记(单词)w ∈ W 替换为维度 d 的单词的相应分布表示。因此,u 的 i thtweet ti 表示为矩阵 mui ∈ R|W|×d。类似地,u 的 N 条推文中的每一条都被建模为 2D 词嵌入矩阵。最后,将所有矩阵连接起来并表示为 3D 矩阵 Mu ∈ RN×|W|×d,该矩阵通过包含 2 个最大池化层的深度 CNN,放置在第 2 和第 4 卷积层之后。每个卷积层包含 k 个过滤器 F = f1, f2,...,fk,每个大小为 s×s。在这项工作中,将推文组织为 3D 矩阵,以学习推文内部和推文间的规律。 CNN 的输出通过注意力层来学习基于内容的低级上下文特征表示 Cu。
(5)低级注意力
前面的小节介绍了如何学习不同的低级行为表示(细粒度特征)。然而,并非特定行为表示的每个特征都同样重要。因此,使用注意力机制根据上下文重要性为特定行为表示的所有低级特征分配可变权重。例如,u的个人资料向量Pu;如果特征 f∈Pu 的隐藏状态表示为 hf ,则将其传递到全连接层以学习其隐藏表示 hf ,如等式 9 所示,其中 w 和 b 分别表示权重和偏差。此后,计算 h f 和表示 f∈Pu 重要性的顶点向量 vf 之间的相似度。还使用等式 10 计算 f 的归一化重要性得分。特征级上下文向量 vf 在训练过程中被随机初始化和联合学习。最后,一个特定行为的注意力感知表示,比如个人资料,被学习并表示为 Pu。它被计算为每个特征 f∈P 的隐藏表示的加权和,如等式 11 中给出的。类似地,计算 u 的其余四个行为方面的注意力感知表示 TDu、TPu、Au 和 Cu。
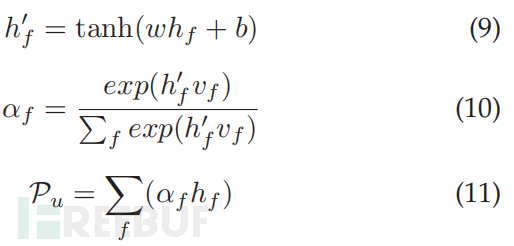
C. 用户表示层
本节首先结合上一节中学习的低级特征表示,使得 Bu = {Pu, TDu, TPu, Au, Cu}。为了给五个行为组件 Bcu∈Bu 中的每一个分配一个权重,还使用等式 12 和 13 应用组件级别的注意力,其中 vc 代表组件级别的上下文向量。 u 的最终表示 Uu 是五个分量的加权和,如等式 14 所示。
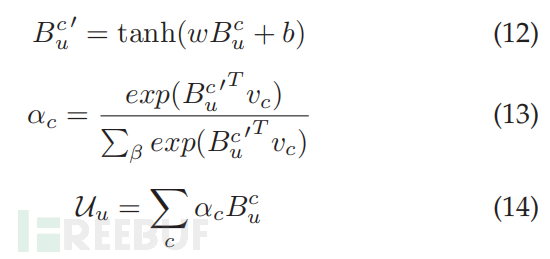
D. 输出层(机器人分类层)
Uu 是从低级表示中学习到的高级用户表示。最后,DeepSBD 将 Uu 通过一个全连接层,然后通过柔性最大化函数将 u 分类为社交机器人或良性用户。
0x03 实验设置和结果
A. 数据集预处理
在由两个主要数据集构建的五个数据集上评估 DeepSBD,其中一个是基准数据集,第二个是生成的。基准数据集包含 4 个数据集,即社交垃圾邮件机器人 #1 (SD1)、社交垃圾邮件机器人 #2 (SD2)、社交垃圾邮件机器人 #3 (SD3) 和真实账户 (GD)。 DeepSBD 分别在三个社交机器人数据集上进行评估,以观察其对不同类型社交机器人的效果。还在 2016 年 1 月 6 日至 2016 年 2 月 2 日期间通过 Twitter 上的社交机器人注入实验构建了一个数据集。
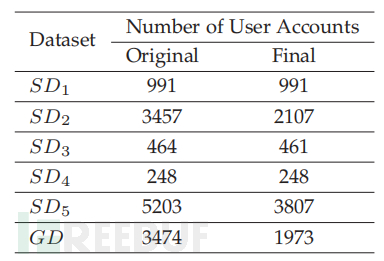
在实验中注入了 98 个社交机器人,他们被 2907 名用户关注,其中包括两类关注者。第一类包括在被社交机器人关注后又关注社交机器人的用户,而第二类包括发起与社交机器人的连接的用户(即他们首先关注社交机器人)。在这 2907 个用户中,有 1248 个和 1659 个分别与第一类和第二类用户相关。在本文中只关注第二类,因为已建立的注释方法仅将第二类用户视为可能的机器人。最后选择了一组 248 个被 Twitter 暂停的用户作为第四个数据集 SD4。现有文献有三类方法来创建机器人的基本事实。在第一类方法中,使用基于某些行为特征的某些准则手动将个人资料注释为机器人或人类,正如提供基准数据集所使用的那样。第二类方法创建蜜罐个人资料以吸引用户并将其进一步标记为机器人。如果被底层 OSN挂起,第三类方法将个人资料标记为机器人。基于第二种和第三种方法将 SD4 的 248 名用户标记为机器人,因为这些用户首先与注入的社交机器人建立了联系(第二种方法),然后 Twitter 暂停了它们(第三种方法)。此外,为了评估 DeepSBD 针对不同类型社交机器人的鲁棒性,汇总了所有四个社交机器人数据集以创建第五个评估数据集 SD5。这样做是因为大多数现有的机器人检测方法在检测特定类别的社交机器人方面表现出良好的性能,但在其他类别的社交机器人上却失败了。在五个评估数据集中的每一个中,从真正的数据集 GD 中选择了负类用户(良性)。评估数据集的最终版本仅包括那些拥有超过或等于 100 条推文的用户。在实验评估中,DeepSBD 使用来自每个用户的 100 条推文。下表给出了所有五个社交机器人数据集和一个真实数据集的简要统计数据,其中原始列表示提供的数据集版本中的用户数量,最后一列表示选择的具有超过 100 条推文的评估用户的数量。
B. 训练详情
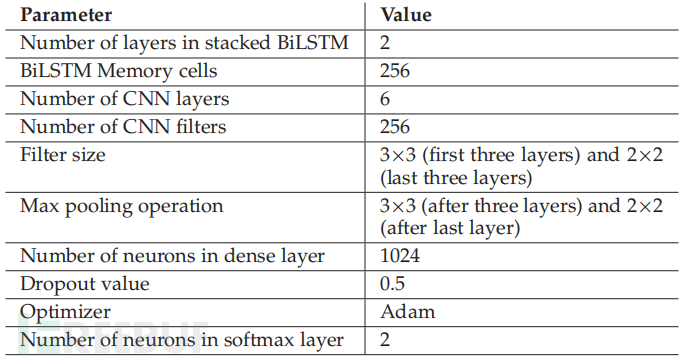
对于实验评估,使用 80% 的数据进行训练,其余 20% 的数据用于验证目的。使用了一个两层堆叠的 BiLSTM,每层有 256 个记忆单元来学习个人资料、时间和基于活动的行为表示。此外使用了一个六层 CNN,前三层有 256 个大小为 3×3 的过滤器,然后是大小为 3×3 的最大池化操作。在最后三层,使用了另外 256 个大小为 2×2 的过滤器,然后是大小为 2×2 的最大池化操作。在 CNN 中像图像一样执行 2D 操作,因为用户的推文内容被映射到类似于图像表示的 3D 矩阵。内容的 3D 表示从推文内和推文间表示中捕获了更好的隐藏特征。用户表示层连接到具有 1024 个神经元的全连接层。对全连接层进行了0.5的dropout操作,以减少过拟合的影响。全连接层之后是一个有 2 个用于分类的神经元的 softmax 层,并使用 adam 作为优化器。本文介绍的所有实验都是在配备 Intel Xeon 处理器和 64 GB RAM 的 Linux 机器上进行的。下表列出了建议模型中使用的参数。此外,DeepSBD 是使用 Python Keras 实现的。
C. 评价结果
使用四个标准指标,即检测率 (DR)、精度 (Pr)、F-Score (F1) 和准确度 (Acc),对五个社交机器人数据集进行了 DeepSBD 评估。下表的第一行展示了 DeepSBD 在所有五个数据集上的性能评估结果。从该表中可以看出,DeepSBD 在所有数据集上始终表现出良好的性能,除了 SD4。尽管 DeepSBD 没有表现出明显优于 SD4 的性能,但它仍然具有检测非常复杂的社交机器人(如 SD4 中存在的社交机器人)的竞争力。从该表中也可以看出,DeepSBD 在 Pr 方面表现出优于 SD1 的完美性能。总体而言,DeepSBD 在所有四个评估指标方面都表现出优于 SD1 的性能,如下表的第一行所示。

(1) 社交机器人和良性用户不同比例的结果
在所有五个数据集中,社交机器人和良性用户的比例并不平衡。例如,SD1 中社交机器人与良性用户的比例约为 1:2,而 SD4 中则接近 1:8。此外,在 Twitter 和 Facebook 等 OSN 中,与良性用户相比,社交机器人的百分比通常较低。为了研究 DeepSBD 在类似真实网络的情况下的效果,本节展示了社交机器人和真实用户的不同比例(即 1:1、1:2 和 1:5)的评估结果。对这三个数据集的比率重复了实验评估,并观察了各自的评估结果,分别是 DR、Pr 和 F1。
用户比例为 1:1 的数据集具有相同数量的社交机器人和良性用户,而比例为 1:2 的数据集每个社交机器人有两个良性用户。在调查中观察到 DeepSBD 的性能受到社交机器人和良性用户比例的不利影响,尽管并不显着。下表显示,当增加所有五个数据集的社交机器人和良性用户的比例时(即当真正用户的数量增加时),DeepSBD 的性能下降,在 SD4 的情况下这一点很重要。基于这些分析得出结论,不平衡的数据集将会对社交机器人检测方法的性能产生不利影响。

(2)行为消融分析
本节使用行为消融分析评估五个行为组件中的每一个的贡献。为了观察特定行为的影响,将其潜在的行为向量从模型中排除,各自的结果代表该行为的影响。例如,为了研究个人资料特征的影响,将其特征向量从模型中排除,并观察修改后模型的性能,如下表的第三行所示。对所有行为向量重复了类似的实验观察它们对模型性能的影响。在该表中,对性能影响最大的行为分量对应的评估结果以粗体显示。可以观察到,个人资料特征在 SD4 上显示出最高的区分能力,而在其余数据集上显示出中等的区分能力。同样,内容特征对 SD3 和 SD5 具有良好的区分能力,对其余数据集影响不大。同样,周期性时间行为在不同数据集上也显示出良好和中等的性能。在五个行为组件中,昼夜行为对 DeepSBD 性能的影响最小。该分析的一个有趣观察是,不同的行为组件在不同的数据集上表现出不同的性能,强调了使用不同的行为特征进行社交机器人检测的重要性,这是现有行为建模和基于深度学习的方法的限制。它还支持这样一个事实,即社交机器人出于不同的原因被注入 OSN,因此它们的操作行为和其他特征是由它们的使用者设计的。因此,使用一套全面的行为特征对于对不同类别的社交机器人进行建模是必不可少且有效的,这是 DeepSBD 模型的优势之一。

0x04 结论
本文介绍了一种基于深度神经网络的模型 DeepSBD,用于检测 Twitter 上的社交机器人。它是一种注意力感知深度神经网络模型。DeepSBD 是第一个使用全面的个人资料和行为信息集对用户表示进行建模的深度学习方法,因为社交机器人被注入具有不同目标的 OSN,从而显示出不同的行为模式。DeepSBD 使用 CNN 和 BiLSTM 架构联合建模用户行为。它将个人资料、时间和活动信息建模为序列,这些信息被馈送到两层堆叠的 BiLSTM,而内容信息则被提供给深度 CNN。
参考链接:https://ieeexplore.ieee.org/document/9505695/
如需授权、对文章有疑问或需删除稿件,请联系 FreeBuf 客服小蜜蜂(微信:freebee1024)
 在线社交网络安全
在线社交网络安全





- 44 文章数
- 51 关注者