


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

- 关注
AFL二三事——源码分析
前言
AFL,全称“American Fuzzy Lop”,是由安全研究员Michal Zalewski开发的一款基于覆盖引导(Coverage-guided)的模糊测试工具,它通过记录输入样本的代码覆盖率(代码执行路径的覆盖情况),以此进行反馈,对输入样本进行调整以提高覆盖率,从而提升发现漏洞的可能性。AFL可以针对有源码和无源码的程序进行模糊测试,其设计思想和实现方案在模糊测试领域具有十分重要的意义。
深入分析AFL源码,对理解AFL的设计理念和其中用到的技巧有着巨大的帮助,对于后期进行定制化Fuzzer开发也具有深刻的指导意义。所以,阅读AFL源码是学习AFL必不可少的一个关键步骤。
(注:需要强调的是,本文的主要目的是协助fuzz爱好者阅读AFL的源码,所以需要在了解AFL基本工作流程和原理的前提下进行阅读,本文并不会在原理侧做过多说明。)
当别人都要快的时候,你要慢下来。
宏观
首先在宏观上看一下AFL的源码结构:
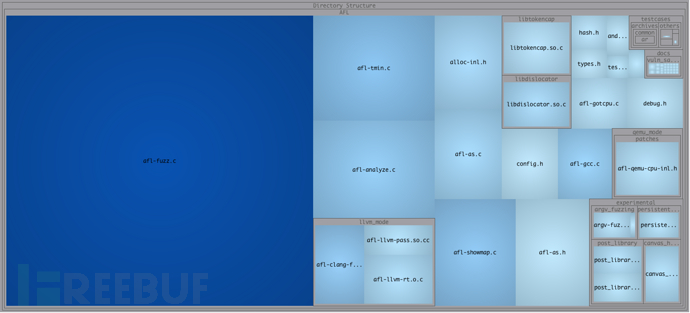
主要的代码在afl-fuzz.c文件中,然后是几个独立模块的实现代码,llvm_mode和qemu_mode的代码量大致相当,所以分析的重点应该还是在AFL的根目录下的几个核心功能的实现上,尤其是afl-fuzz.c,属于核心中的重点。
各个模块的主要功能和作用的简要说明:
插桩模块
afl-as.h, afl-as.c, afl-gcc.c:普通插桩模式,针对源码插桩,编译器可以使用gcc, clang;llvm_mode:llvm 插桩模式,针对源码插桩,编译器使用clang;qemu_mode:qemu 插桩模式,针对二进制文件插桩。
fuzzer 模块
afl-fuzz.c:fuzzer 实现的核心代码,AFL 的主体。其他辅助模块
afl-analyze:对测试用例进行分析,通过分析给定的用例,确定是否可以发现用例中有意义的字段;afl-plot:生成测试任务的状态图;afl-tmin:对测试用例进行最小化;afl-cmin:对语料库进行精简操作;afl-showmap:对单个测试用例进行执行路径跟踪;afl-whatsup:各并行例程fuzzing结果统计;afl-gotcpu:查看当前CPU状态。
部分头文件说明
alloc-inl.h:定义带检测功能的内存分配和释放操作;config.h:定义配置信息;debug.h:与提示信息相关的宏定义;hash.h:哈希函数的实现定义;types.h:部分类型及宏的定义。
一、AFL的插桩——普通插桩
(一) 、AFL 的 gcc —— afl-gcc.c
1. 概述
afl-gcc是GCC 或 clang 的一个wrapper(封装),常规的使用方法是在调用./configure时通过CC将路径传递给afl-gcc或afl-clang。(对于 C++ 代码,则使用CXX并将其指向afl-g++/afl-clang++。)afl-clang,afl-clang++,afl-g++均为指向afl-gcc的一个符号链接。
afl-gcc的主要作用是实现对于关键节点的代码插桩,属于汇编级,从而记录程序执行路径之类的关键信息,对程序的运行情况进行反馈。
2. 源码
1. 关键变量
在开始函数代码分析前,首先要明确几个关键变量:
static u8* as_path; /* Path to the AFL 'as' wrapper,AFL的as的路径 */
static u8** cc_params; /* Parameters passed to the real CC,CC实际使用的编译器参数 */
static u32 cc_par_cnt = 1; /* Param count, including argv0 ,参数计数 */
static u8 be_quiet, /* Quiet mode,静默模式 */
clang_mode; /* Invoked as afl-clang*? ,是否使用afl-clang*模式 */
# 数据类型说明
# typedef uint8_t u8;
# typedef uint16_t u16;
# typedef uint32_t u32;
2. main函数
main 函数全部逻辑如下:
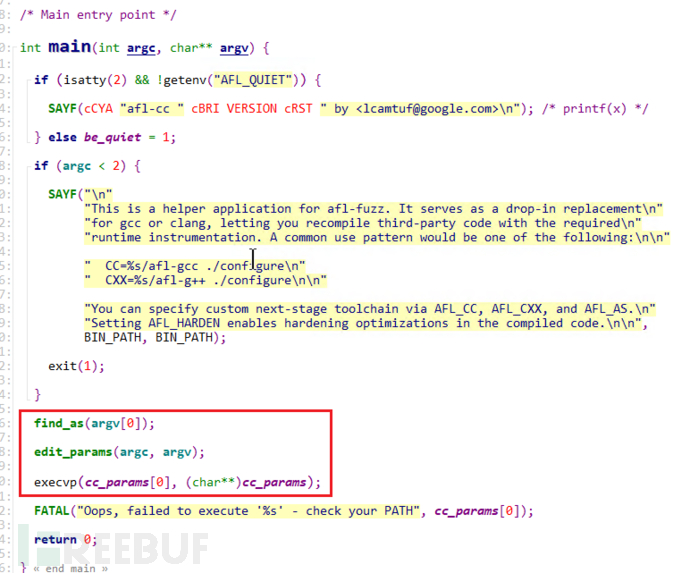
其中主要有如下三个函数的调用:
find_as(argv[0]):查找使用的汇编器edit_params(argc, argv):处理传入的编译参数,将确定好的参数放入cc_params[]数组调用
execvp(cc_params[0], (cahr**)cc_params)执行afl-gcc
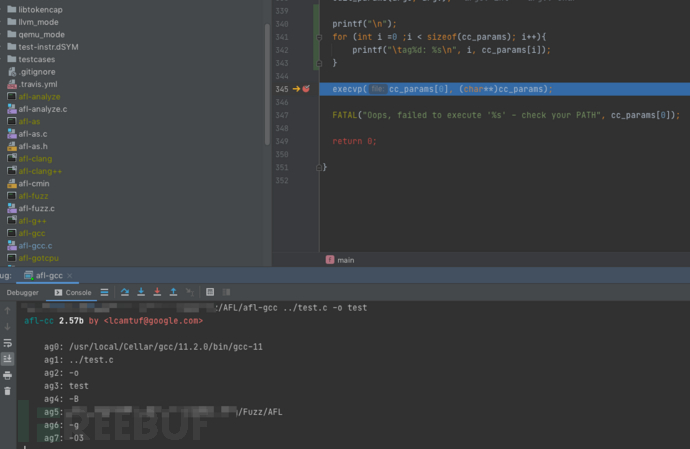
这里添加了部分代码打印出传入的参数arg[0] - arg[7],其中一部分是我们指定的参数,另外一部分是自动添加的编译选项。
3. find_as 函数
函数的核心作用:寻找afl-as
函数内部大概的流程如下(软件自动生成,控制流程图存在误差,但关键逻辑没有问题):
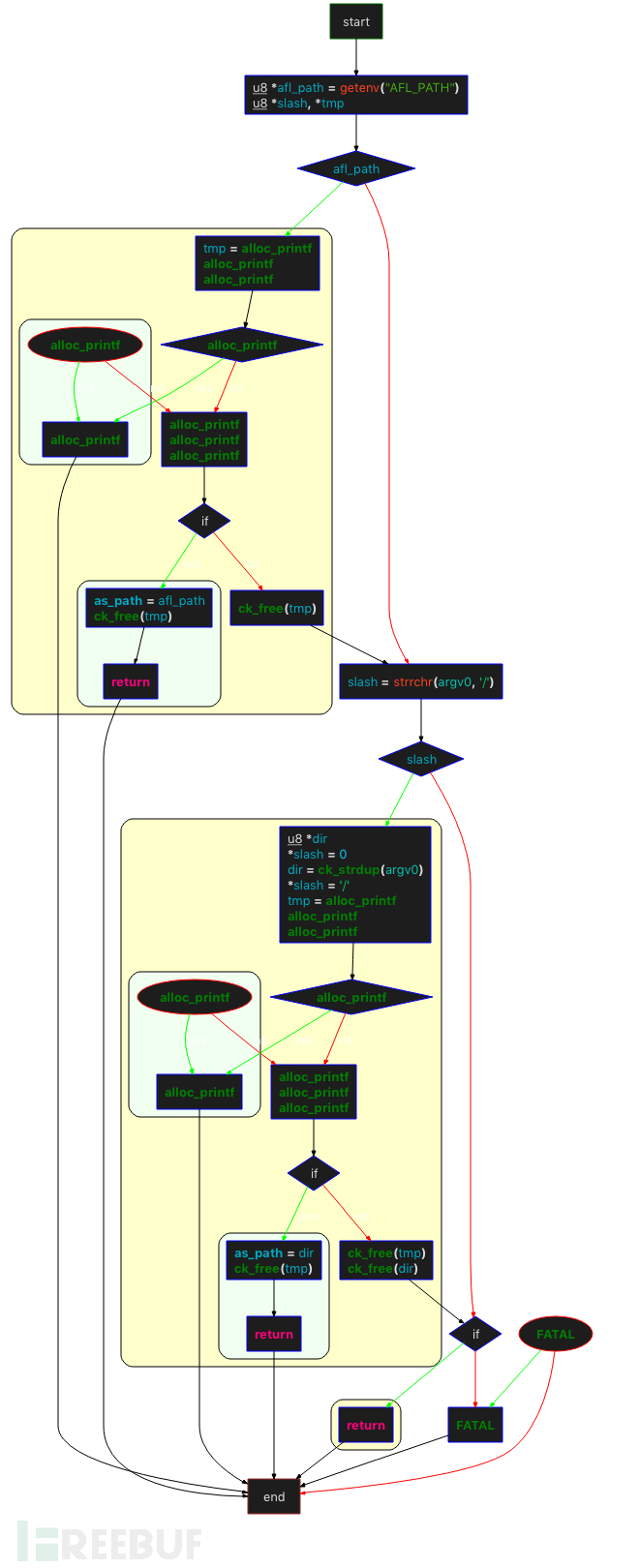
首先检查环境变量
AFL_PATH,如果存在直接赋值给afl_path,然后检查afl_path/as文件是否可以访问,如果可以,as_path = afl_path。如果不存在环境变量
AFL_PATH,检查argv[0](如“/Users/v4ler1an/AFL/afl-gcc”)中是否存在 "/" ,如果存在则取最后“/” 前面的字符串作为dir,然后检查dir/afl-as是否可以访问,如果可以,将as_path = dir。以上两种方式都失败,抛出异常。
4. edit_params 函数
核心作用:将argv拷贝到u8 **cc_params ,然后进行相应的处理。
函数内部的大概流程如下:
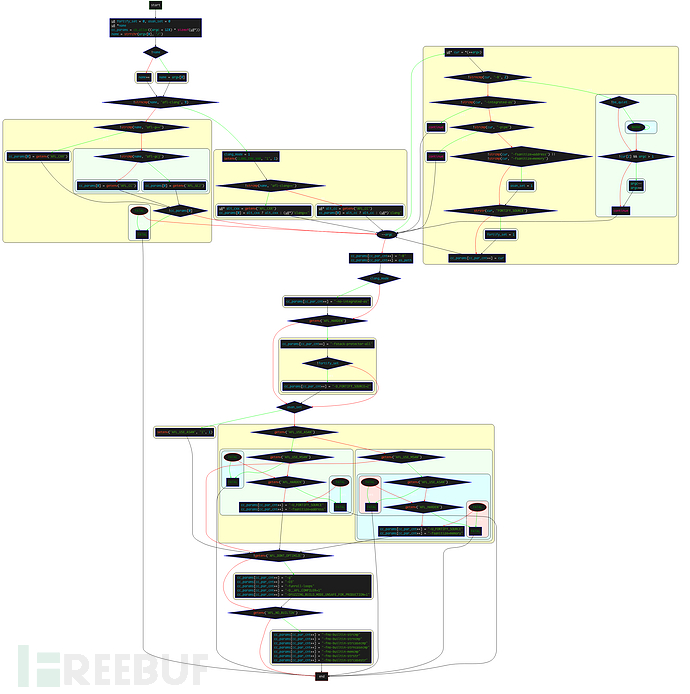
调用
ch_alloc()为cc_params分配大小为(argc + 128) * 8的内存(u8的类型为1byte无符号整数)检查
argv[0]中是否存在/,如果不存在则name = argv[0],如果存在则一直找到最后一个/,并将其后面的字符串赋值给name对比
name和固定字符串afl-clang:若相同,设置
clang_mode = 1,设置环境变量CLANG_ENV_VAR为1对比
name和固定字符串afl-clang++::若相同,则获取环境变量
AFL_CXX的值,如果存在,则将该值赋值给cc_params[0],否则将afl-clang++赋值给cc_params[0]。这里的cc_params为保存编译参数的数组;若不相同,则获取环境变量
AFL_CC的值,如果存在,则将该值赋值给cc_params[0],否则将afl-clang赋值给cc_params[0]。
如果不相同,并且是Apple平台,会进入
#ifdef __APPLE__。在Apple平台下,开始对name进行对比,并通过cc_params[0] = getenv("")对cc_params[0]进行赋值;如果是非Apple平台,对比name和 固定字符串afl-g++(此处忽略对Java环境的处理过程):若相同,则获取环境变量
AFL_CXX的值,如果存在,则将该值赋值给cc_params[0],否则将g++赋值给cc_params[0];若不相同,则获取环境变量
AFL_CC的值,如果存在,则将该值赋值给cc_params[0],否则将gcc赋值给cc_params[0]。
进入 while 循环,遍历从
argv[1]开始的argv参数:如果扫描到
-B,-B选项用于设置编译器的搜索路径,直接跳过。(因为在这之前已经处理过as_path了);如果扫描到
-integrated-as,跳过;如果扫描到
-pipe,跳过;如果扫描到
-fsanitize=address和-fsanitize=memory告诉 gcc 检查内存访问的错误,比如数组越界之类,设置asan_set = 1;如果扫描到
FORTIFY_SOURCE,设置fortify_set = 1。FORTIFY_SOURCE主要进行缓冲区溢出问题的检查,检查的常见函数有memcpy, mempc/py, memmove, memset, strcpy, stpc/py, strncpy, strcat, strncat, sprintf, vsprintf, snprintf, gets等;对
cc_params进行赋值:cc_params[cc_par_cnt++] = cur;
跳出
while循环,设置其他参数:取出前面计算出的
as_path,设置-B as_path;
如果为
clang_mode,则设置-no-integrated-as;
3. 如果存在环境变量AFL_HARDEN,则设置-fstack-protector-all。且如果没有设置fortify_set,追加-D_FORTIFY_SOURCE=2;sanitizer相关,通过多个if进行判断:
如果
asan_set在前面被设置为1,则设置环境变量AFL_USE_ASAN为1;如果
asan_set不为1且,存在AFL_USE_ASAN环境变量,则设置-U_FORTIFY_SOURCE -fsanitize=address;
如果不存在
AFL_USE_ASAN环境变量,但存在AFL_USE_MSAN环境变量,则设置-fsanitize=memory(不能同时指定AFL_USE_ASAN或者AFL_USE_MSAN,也不能同时指定AFL_USE_MSAN和AFL_HARDEN,因为这样运行时速度过慢;如果不存在
AFL_DONT_OPTIMIZE环境变量,则设置-g -O3 -funroll-loops -D__AFL_COMPILER=1 -DFUZZING_BUILD_MODE_UNSAFE_FOR_PRODUCTION=1;如果存在
AFL_NO_BUILTIN环境变量,则表示允许进行优化,设置-fno-builtin-strcmp -fno-builtin-strncmp -fno-builtin-strcasecmp -fno-builtin-strncasecmp -fno-builtin-memcmp -fno-builtin-strstr -fno-builtin-strcasestr。
最后补充
cc_params[cc_par_cnt] = NULL;,cc_params参数数组编辑完成。
###(二)、AFL的插桩 —— afl-as.c
1. 概述
afl-gcc是 GNU as 的一个wrapper(封装),唯一目的是预处理由 GCC/clang 生成的汇编文件,并注入包含在afl-as.h中的插桩代码。 使用afl-gcc / afl-clang编译程序时,工具链会自动调用它。该wapper的目标并不是为了实现向.s或asm 代码块中插入手写的代码。
experiment/clang_asm_normalize/中可以找到可能允许 clang 用户进行手动插入自定义代码的解决方案,GCC并不能实现该功能。
2. 源码
1. 关键变量
在开始函数代码分析前,首先要明确几个关键变量:
static u8** as_params; /* Parameters passed to the real 'as',传递给as的参数 */
static u8* input_file; /* Originally specified input file ,输入文件 */
static u8* modified_file; /* Instrumented file for the real 'as',as进行插桩处理的文件 */
static u8 be_quiet, /* Quiet mode (no stderr output) ,静默模式,没有标准输出 */
clang_mode, /* Running in clang mode? 是否运行在clang模式 */
pass_thru, /* Just pass data through? 只通过数据 */
just_version, /* Just show version? 只显示版本 */
sanitizer; /* Using ASAN / MSAN 是否使用ASAN/MSAN */
static u32 inst_ratio = 100, /* Instrumentation probability (%) 插桩覆盖率 */
as_par_cnt = 1; /* Number of params to 'as' 传递给as的参数数量初始值 */
注:如果在参数中没有指明--m32或--m64,则默认使用在编译时使用的选项。
2. main函数
main 函数全部逻辑如下:
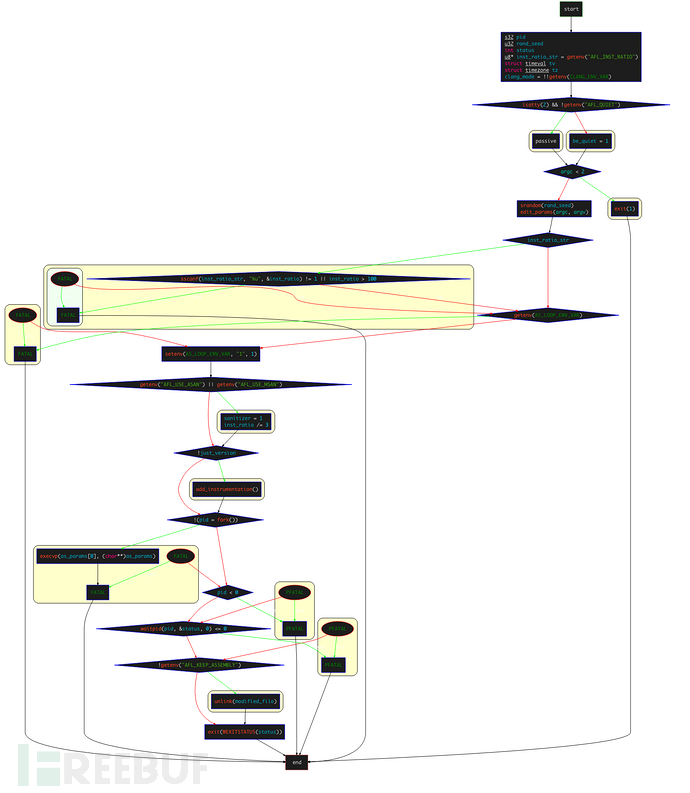
首先获取环境变量
AFL_INST_RATIO,赋值给inst_ratio_str,该环境变量主要控制检测每个分支的概率,取值为0到100%,设置为0时则只检测函数入口的跳转,而不会检测函数分支的跳转;通过
gettimeofday(&tv,&tz);获取时区和时间,然后设置srandom()的随机种子rand_seed = tv.tv_sec ^ tv.tv_usec ^ getpid();调用
edit_params(argc, argv)函数进行参数处理;检测
inst_ratio_str的值是否合法范围内,并设置环境变量AFL_LOOP_ENV_VAR;读取环境变量``AFL_USE_ASAN
和AFL_USE_MSAN的值,如果其中有一个为1,则设置sanitizer为1,且将inst_ratio`除3。这是因为在进行ASAN的编译时,AFL无法识别出ASAN特定的分支,导致插入很多无意义的桩代码,所以直接暴力地将插桩概率/3;调用
add_instrumentation()函数,这是实际的插桩函数;fork 一个子进程来执行
execvp(as_params[0], (char**)as_params);。这里采用的是 fork 一个子进程的方式来执行插桩。这其实是因为我们的execvp执行的时候,会用as_params[0]来完全替换掉当前进程空间中的程序,如果不通过子进程来执行实际的as,那么后续就无法在执行完实际的as之后,还能unlink掉modified_file;调用
waitpid(pid, &status, 0)等待子进程执行结束;读取环境变量
AFL_KEEP_ASSEMBLY的值,如果没有设置这个环境变量,就unlink掉modified_file(已插完桩的文件)。设置该环境变量主要是为了防止afl-as删掉插桩后的汇编文件,设置为1则会保留插桩后的汇编文件。
可以通过在main函数中添加如下代码来打印实际执行的参数:
print("\n");
for (int i = 0; i < sizeof(as_params); i++){
peinrf("as_params[%d]:%s\n", i, as_params[i]);
}
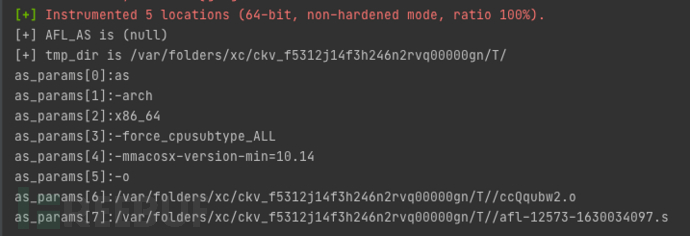
在插桩完成后,会生成.s文件,内容如下(具体的文件位置与设置的环境变量相关):
3. add_instrumentation函数
add_instrumentation函数负责处理输入文件,生成modified_file,将instrumentation插入所有适当的位置。其整体控制流程如下:

整体逻辑看上去有点复杂,但是关键内容并不算很多。在main函数中调用完edit_params()函数完成as_params参数数组的处理后,进入到该函数。
判断
input_file是否为空,如果不为空则尝试打开文件获取fd赋值给inf,失败则抛出异常;input_file为空则inf设置为标准输入;打开
modified_file,获取fd赋值给outfd,失败返回异常;进一步验证该文件是否可写,不可写返回异常;while循环读取inf指向文件的每一行到line数组,每行最多MAX_LINE = 8192个字节(含末尾的‘\0’),从line数组里将读取到的内容写入到outf指向的文件,然后进入到真正的插桩逻辑。这里需要注意的是,插桩只向.text段插入,:首先跳过标签、宏、注释;
这里结合部分关键代码进行解释。需要注意的是,变量
instr_ok本质上是一个flag,用于表示是否位于.text段。变量设置为1,表示位于.text中,如果不为1,则表示不再。于是,如果instr_ok为1,就会在分支处执行插桩逻辑,否则就不插桩。首先判断读入的行是否以‘\t’ 开头,本质上是在匹配
.s文件中声明的段,然后判断line[1]是否为.:if (line[0] == '\t' && line[1] == '.') { /* OpenBSD puts jump tables directly inline with the code, which is a bit annoying. They use a specific format of p2align directives around them, so we use that as a signal. */ if (!clang_mode && instr_ok && !strncmp(line + 2, "p2align ", 8) && isdigit(line[10]) && line[11] == '\n') skip_next_label = 1; if (!strncmp(line + 2, "text\n", 5) || !strncmp(line + 2, "section\t.text", 13) || !strncmp(line + 2, "section\t__TEXT,__text", 21) || !strncmp(line + 2, "section __TEXT,__text", 21)) { instr_ok = 1; continue; } if (!strncmp(line + 2, "section\t", 8) || !strncmp(line + 2, "section ", 8) || !strncmp(line + 2, "bss\n", 4) || !strncmp(line + 2, "data\n", 5)) { instr_ok = 0; continue; } }'\t'开头,且
line[1]=='.',检查是否为p2align指令,如果是,则设置skip_next_label = 1;尝试匹配
"text\n""section\t.text""section\t__TEXT,__text""section __TEXT,__text"其中任意一个,匹配成功, 设置instr_ok = 1, 表示位于.text段中,continue跳出,进行下一次遍历;尝试匹配
"section\t""section ""bss\n""data\n"其中任意一个,匹配成功,设置instr_ok = 0,表位于其他段中,continue跳出,进行下一次遍历;
接下来通过几个
if判断,来设置一些标志信息,包括off-flavor assembly,Intel/AT&T的块处理方式、ad-hoc __asm__块的处理方式等;/* Detect off-flavor assembly (rare, happens in gdb). When this is encountered, we set skip_csect until the opposite directive is seen, and we do not instrument. */ if (strstr(line, ".code")) { if (strstr(line, ".code32")) skip_csect = use_64bit; if (strstr(line, ".code64")) skip_csect = !use_64bit; } /* Detect syntax changes, as could happen with hand-written assembly. Skip Intel blocks, resume instrumentation when back to AT&T. */ if (strstr(line, ".intel_syntax")) skip_intel = 1; if (strstr(line, ".att_syntax")) skip_intel = 0; /* Detect and skip ad-hoc __asm__ blocks, likewise skipping them. */ if (line[0] == '#' || line[1] == '#') { if (strstr(line, "#APP")) skip_app = 1; if (strstr(line, "#NO_APP")) skip_app = 0; }AFL在插桩时重点关注的内容包括:
^main, ^.L0, ^.LBB0_0, ^\tjnz foo(_main函数, gcc和clang下的分支标记,条件跳转分支标记),这些内容通常标志了程序的流程变化,因此AFL会重点在这些位置进行插桩:对于形如
\tj[^m].格式的指令,即条件跳转指令,且R(100)产生的随机数小于插桩密度inst_ratio,直接使用fprintf将trampoline_fmt_64(插桩部分的指令)写入outf指向的文件,写入大小为小于MAP_SIZE的随机数——R(MAP_SIZE),然后插桩计数
ins_lines加一,continue跳出,进行下一次遍历;/* If we're in the right mood for instrumenting, check for function names or conditional labels. This is a bit messy, but in essence, we want to catch: ^main: - function entry point (always instrumented) ^.L0: - GCC branch label ^.LBB0_0: - clang branch label (but only in clang mode) ^\tjnz foo - conditional branches ...but not: ^# BB#0: - clang comments ^ # BB#0: - ditto ^.Ltmp0: - clang non-branch labels ^.LC0 - GCC non-branch labels ^.LBB0_0: - ditto (when in GCC mode) ^\tjmp foo - non-conditional jumps Additionally, clang and GCC on MacOS X follow a different convention with no leading dots on labels, hence the weird maze of #ifdefs later on. */ if (skip_intel || skip_app || skip_csect || !instr_ok || line[0] == '#' || line[0] == ' ') continue; /* Conditional branch instruction (jnz, etc). We append the instrumentation right after the branch (to instrument the not-taken path) and at the branch destination label (handled later on). */ if (line[0] == '\t') { if (line[1] == 'j' && line[2] != 'm' && R(100) < inst_ratio) { fprintf(outf, use_64bit ? trampoline_fmt_64 : trampoline_fmt_32, R(MAP_SIZE)); ins_lines++; } continue; }对于label的相关评估,有一些label可能是一些分支的目的地,需要自己评判
首先检查该行中是否存在
:,然后检查是否以.开始如果以
.开始,则代表想要插桩^.L0:或者^.LBB0_0:这样的branch label,即 style jump destination检查
line[2]是否为数字 或者 如果是在clang_mode下,比较从line[1]开始的三个字节是否为LBB.,前述所得结果和R(100) < inst_ratio)相与。如果结果为真,则设置instrument_next = 1;
否则代表这是一个function,插桩
^func:,function entry point,直接设置instrument_next = 1(defer mode)。
/* Label of some sort. This may be a branch destination, but we need to tread carefully and account for several different formatting conventions. */ #ifdef __APPLE__ /* Apple: L<whatever><digit>: */ if ((colon_pos = strstr(line, ":"))) { if (line[0] == 'L' && isdigit(*(colon_pos - 1))) { #else /* Everybody else: .L<whatever>: */ if (strstr(line, ":")) { if (line[0] == '.') { #endif /* __APPLE__ */ /* .L0: or LBB0_0: style jump destination */ #ifdef __APPLE__ /* Apple: L<num> / LBB<num> */ if ((isdigit(line[1]) || (clang_mode && !strncmp(line, "LBB", 3))) && R(100) < inst_ratio) { #else /* Apple: .L<num> / .LBB<num> */ if ((isdigit(line[2]) || (clang_mode && !strncmp(line + 1, "LBB", 3))) && R(100) < inst_ratio) { #endif /* __APPLE__ */ /* An optimization is possible here by adding the code only if the label is mentioned in the code in contexts other than call / jmp. That said, this complicates the code by requiring two-pass processing (messy with stdin), and results in a speed gain typically under 10%, because compilers are generally pretty good about not generating spurious intra-function jumps. We use deferred output chiefly to avoid disrupting .Lfunc_begin0-style exception handling calculations (a problem on MacOS X). */ if (!skip_next_label) instrument_next = 1; else skip_next_label = 0; } } else { /* Function label (always instrumented, deferred mode). */ instrument_next = 1; } } }上述过程完成后,来到
while循环的下一个循环,在while的开头,可以看到对以 defered mode 进行插桩的位置进行了真正的插桩处理:
if (!pass_thru && !skip_intel && !skip_app && !skip_csect && instr_ok && instrument_next && line[0] == '\t' && isalpha(line[1])) { fprintf(outf, use_64bit ? trampoline_fmt_64 : trampoline_fmt_32, R(MAP_SIZE)); instrument_next = 0; ins_lines++; }这里对
instr_ok, instrument_next变量进行了检验是否为1,而且进一步校验是否位于.text段中,且设置了 defered mode 进行插桩,则就进行插桩操作,写入trampoline_fmt_64/32。
至此,插桩函数add_instrumentation的主要逻辑已梳理完成。
4. edit_params函数
edit_params,该函数主要是设置变量as_params的值,以及use_64bit/modified_file的值, 其整体控制流程如下:
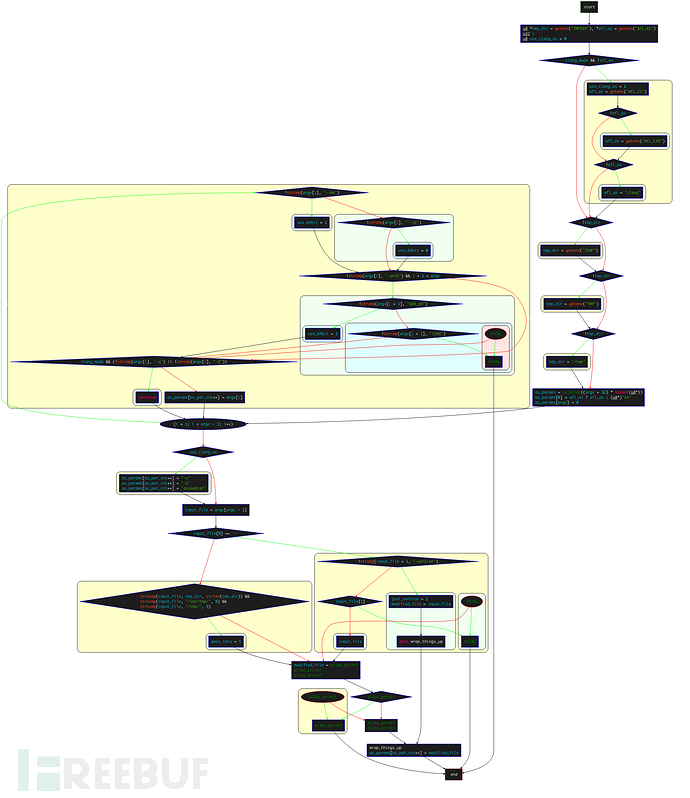
获取环境变量
TMPDIR和AFL_AS;对于
__APPLE_宏, 如果当前在clang_mode且没有设置AFL_AS环境变量,会设置use_clang_mode = 1,并设置afl-as为AFL_CC/AFL_CXX/clang中的一种;设置
tmp_dir,尝试获取的环境变量依次为TEMP, TMP,如果都失败,则直接设置为/tmp;调用
ck_alloc()函数为as_params参数数组分配内存,大小为(argc + 32) * 8;设置
afl-as路径:as_params[0] = afl_as ? afl_as : (u8*)"as";设置
as_params[argc] = 0;,as_par_cnt 初始值为1;遍历从
argv[1]到argv[argc-1]之前的每个 argv:如果存在字符串
--64, 则设置use_64bit = 1;如果存在字符串--32,则设置use_64bit = 0。对于__APPLE__,如果存在-arch x86_64,设置use_64bit=1,并跳过-q和-Q选项;as_params[as_par_cnt++] = argv[i],设置as_params的值为argv对应的参数值
开始设置其他参数:
对于
__APPLE__,如果设置了use_clang_as,则追加-c -x assembler;设置
input_file变量:input_file = argv[argc - 1];,把最后一个参数的值作为input_file;如果
input_file的首字符为-:如果后续为
-version,则just_version = 1,modified_file = input_file,然后跳转到wrap_things_up。这里就只是做version的查询;如果后续不为
-version,抛出异常;
如果
input_file首字符不为-,比较input_file和tmp_dir、/var/tmp、/tmp/的前strlen(tmp_dir)/9/5个字节是否相同,如果不相同,就设置pass_thru为1;
设置
modified_file:modified_file = alloc_printf("%s/.afl-%u-%u.s", tmp_dir, getpid(), (u32)time(NULL));,即为tmp_dir/afl-pid-tim.s格式的字符串设置
as_params[as_par_cnt++] = modified_file,as_params[as_par_cnt] = NULL;。
3. instrumentation trampoline 和 main_payload
trampoline的含义是“蹦床”,直译过来就是“插桩蹦床”。个人感觉直接使用英文更能表达出其代表的真实含义和作用,可以简单理解为桩代码。
1. trampoline_fmt_64/32
根据前面内容知道,在64位环境下,AFL会插入trampoline_fmt_64到文件中,在32位环境下,AFL会插入trampoline_fmt_32到文件中。trampoline_fmt_64/32定义在afl-as.h头文件中:
static const u8* trampoline_fmt_32 = "\n" "/* --- AFL TRAMPOLINE (32-BIT) --- */\n" "\n" ".align 4\n" "\n" "leal -16(%%esp), %%esp\n" "movl %%edi, 0(%%esp)\n" "movl %%edx, 4(%%esp)\n" "movl %%ecx, 8(%%esp)\n" "movl %%eax, 12(%%esp)\n" "movl $0x%08x, %%ecx\n" // 向ecx中存入识别代码块的随机桩代码id "call __afl_maybe_log\n" // 调用 __afl_maybe_log 函数 "movl 12(%%esp), %%eax\n" "movl 8(%%esp), %%ecx\n" "movl 4(%%esp), %%edx\n" "movl 0(%%esp), %%edi\n" "leal 16(%%esp), %%esp\n" "\n" "/* --- END --- */\n" "\n";static const u8* trampoline_fmt_64 = "\n" "/* --- AFL TRAMPOLINE (64-BIT) --- */\n" "\n" ".align 4\n" "\n" "leaq -(128+24)(%%rsp), %%rsp\n" "movq %%rdx, 0(%%rsp)\n" "movq %%rcx, 8(%%rsp)\n" "movq %%rax, 16(%%rsp)\n" "movq $0x%08x, %%rcx\n" // 64位下使用的寄存器为rcx "call __afl_maybe_log\n" // 调用 __afl_maybe_log 函数 "movq 16(%%rsp), %%rax\n" "movq 8(%%rsp), %%rcx\n" "movq 0(%%rsp), %%rdx\n" "leaq (128+24)(%%rsp), %%rsp\n" "\n" "/* --- END --- */\n" "\n";
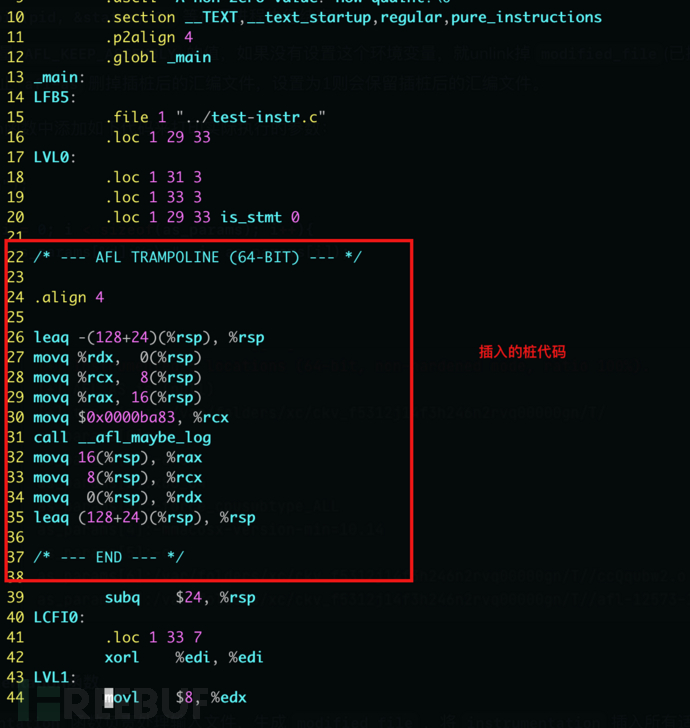
上面列出的插桩代码与我们在.s文件和IDA逆向中看到的插桩代码是一样的:
.s文件中的桩代码:
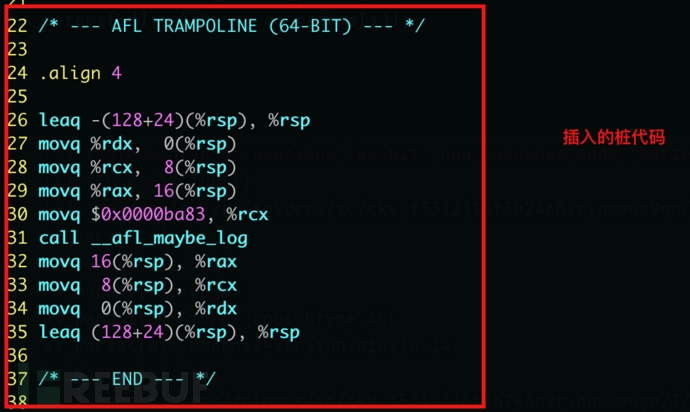
IDA逆向中显示的桩代码:

上述代码执行的主要功能包括:
保存
rdx、rcx、rax寄存器将
rcx的值设置为fprintf()函数将要打印的变量内容调用
__afl_maybe_log函数恢复寄存器
在以上的功能中,__afl_maybe_log才是核心内容。
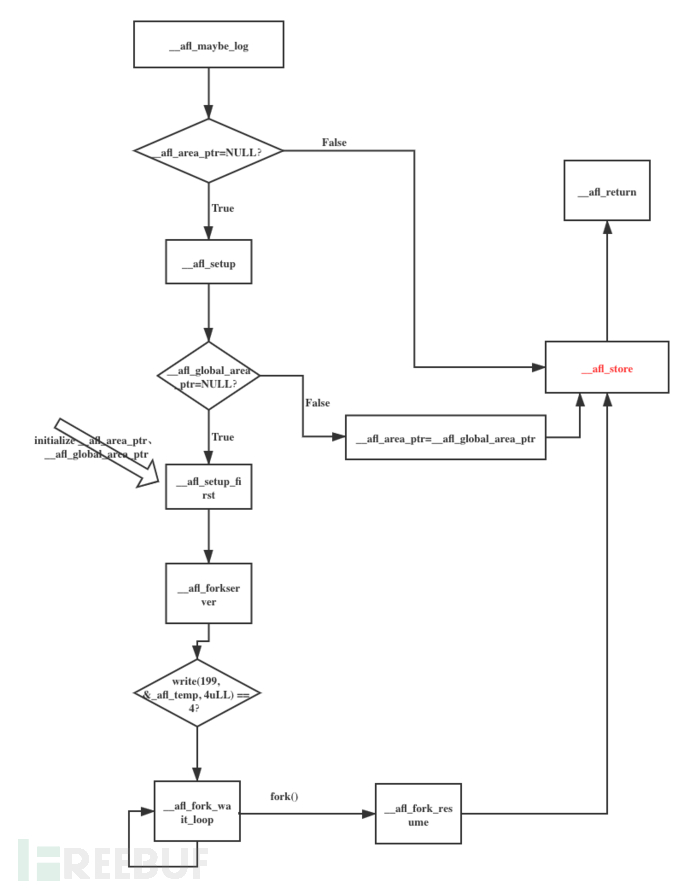
从__afl_maybe_log函数开始,后续的处理流程大致如下(图片来自ScUpax0s师傅):
首先对上面流程中涉及到的几个bss段的变量进行简单说明(以64位为例,从main_payload_64中提取):
.AFL_VARS:
.comm __afl_area_ptr, 8
.comm __afl_prev_loc, 8
.comm __afl_fork_pid, 4
.comm __afl_temp, 4
.comm __afl_setup_failure, 1
.comm __afl_global_area_ptr, 8, 8
__afl_area_ptr:共享内存地址;__afl_prev_loc:上一个插桩位置(id为R(100)随机数的值);__afl_fork_pid:由fork产生的子进程的pid;__afl_temp:缓冲区;__afl_setup_failure:标志位,如果置位则直接退出;__afl_global_area_ptr:全局指针。
说明
以下介绍的指令段均来自于main_payload_64。
2. __afl_maybe_log
__afl_maybe_log: /* 源码删除无关内容后 */
lahf
seto %al
/* Check if SHM region is already mapped. */
movq __afl_area_ptr(%rip), %rdx
testq %rdx, %rdx
je __afl_setup
首先,使用lahf指令(加载状态标志位到AH)将EFLAGS寄存器的低八位复制到AH,被复制的标志位包括:符号标志位(SF)、零标志位(ZF)、辅助进位标志位(AF)、奇偶标志位(PF)和进位标志位(CF),使用该指令可以方便地将标志位副本保存在变量中;
然后,使用seto指令溢出置位;
接下来检查共享内存是否进行了设置,判断__afl_area_ptr是否为NULL:
如果为NULL,跳转到
__afl_setup函数进行设置;如果不为NULL,继续进行。
3. __afl_setup
__afl_setup:
/* Do not retry setup is we had previous failues. */
cmpb $0, __afl_setup_failure(%rip)
jne __afl_return
/* Check out if we have a global pointer on file. */
movq __afl_global_area_ptr(%rip), %rdx
testq %rdx, %rdx
je __afl_setup_first
movq %rdx, __afl_area_ptr(%rip)
jmp __afl_store
该部分的主要作用为初始化__afl_area_ptr,且只在运行到第一个桩时进行本次初始化。
首先,如果__afl_setup_failure不为0,直接跳转到__afl_return返回;
然后,检查__afl_global_area_ptr文件指针是否为NULL:
如果为NULL,跳转到
__afl_setup_first进行接下来的工作;如果不为NULL,将
__afl_global_area_ptr的值赋给__afl_area_ptr,然后跳转到__afl_store。
4. __afl_setup_first
__afl_setup_first:
/* Save everything that is not yet saved and that may be touched by
getenv() and several other libcalls we'll be relying on. */
leaq -352(%rsp), %rsp
movq %rax, 0(%rsp)
movq %rcx, 8(%rsp)
movq %rdi, 16(%rsp)
movq %rsi, 32(%rsp)
movq %r8, 40(%rsp)
movq %r9, 48(%rsp)
movq %r10, 56(%rsp)
movq %r11, 64(%rsp)
movq %xmm0, 96(%rsp)
movq %xmm1, 112(%rsp)
movq %xmm2, 128(%rsp)
movq %xmm3, 144(%rsp)
movq %xmm4, 160(%rsp)
movq %xmm5, 176(%rsp)
movq %xmm6, 192(%rsp)
movq %xmm7, 208(%rsp)
movq %xmm8, 224(%rsp)
movq %xmm/9, 240(%rsp)
movq %xmm10, 256(%rsp)
movq %xmm11, 272(%rsp)
movq %xmm12, 288(%rsp)
movq %xmm13, 304(%rsp)
movq %xmm14, 320(%rsp)
movq %xmm15, 336(%rsp)
/* Map SHM, jumping to __afl_setup_abort if something goes wrong. */
/* The 64-bit ABI requires 16-byte stack alignment. We'll keep the
original stack ptr in the callee-saved r12. */
pushq %r12
movq %rsp, %r12
subq $16, %rsp
andq $0xfffffffffffffff0, %rsp
leaq .AFL_SHM_ENV(%rip), %rdi
call _getenv
testq %rax, %rax
je __afl_setup_abort
movq %rax, %rdi
call _atoi
xorq %rdx, %rdx /* shmat flags */
xorq %rsi, %rsi /* requested addr */
movq %rax, %rdi /* SHM ID */
call _shmat
cmpq $-1, %rax
je __afl_setup_abort
/* Store the address of the SHM region. */
movq %rax, %rdx
movq %rax, __afl_area_ptr(%rip)
movq %rax, __afl_global_area_ptr(%rip)
movq %rax, %rdx
首先,保存所有寄存器的值,包括xmm寄存器组;
然后,进行rsp的对齐;
然后,获取环境变量__AFL_SHM_ID,该环境变量保存的是共享内存的ID:
如果获取失败,跳转到
__afl_setup_abort;如果获取成功,调用
_shmat,启用对共享内存的访问,启用失败跳转到__afl_setup_abort。
接下来,将_shmat返回的共享内存地址存储在__afl_area_ptr和__afl_global_area_ptr变量中。
后面即开始运行__afl_forkserver。
5. __afl_forkserver
__afl_forkserver:
/* Enter the fork server mode to avoid the overhead of execve() calls. We
push rdx (area ptr) twice to keep stack alignment neat. */
pushq %rdx
pushq %rdx
/* Phone home and tell the parent that we're OK. (Note that signals with
no SA_RESTART will mess it up). If this fails, assume that the fd is
closed because we were execve()d from an instrumented binary, or because
the parent doesn't want to use the fork server. */
movq $4, %rdx /* length */
leaq __afl_temp(%rip), %rsi /* data */
movq $" STRINGIFY((FORKSRV_FD + 1)) ", %rdi /* file desc */
CALL_L64("write")
cmpq $4, %rax
jne __afl_fork_resume
这一段实现的主要功能是向FORKSRV_FD+1(也就是198+1)号描述符(即状态管道)中写__afl_temp中的4个字节,告诉 fork server (将在后续的文章中进行详细解释)已经成功启动。
6. __afl_fork_wait_loop
__afl_fork_wait_loop:
/* Wait for parent by reading from the pipe. Abort if read fails. */
movq $4, %rdx /* length */
leaq __afl_temp(%rip), %rsi /* data */
movq $" STRINGIFY(FORKSRV_FD) ", %rdi /* file desc */
CALL_L64("read")
cmpq $4, %rax
jne __afl_die
/* Once woken up, create a clone of our process. This is an excellent use
case for syscall(__NR_clone, 0, CLONE_PARENT), but glibc boneheadedly
caches getpid() results and offers no way to update the value, breaking
abort(), raise(), and a bunch of other things :-( */
CALL_L64("fork")
cmpq $0, %rax
jl __afl_die
je __afl_fork_resume
/* In parent process: write PID to pipe, then wait for child. */
movl %eax, __afl_fork_pid(%rip)
movq $4, %rdx /* length */
leaq __afl_fork_pid(%rip), %rsi /* data */
movq $" STRINGIFY((FORKSRV_FD + 1)) ", %rdi /* file desc */
CALL_L64("write")
movq $0, %rdx /* no flags */
leaq __afl_temp(%rip), %rsi /* status */
movq __afl_fork_pid(%rip), %rdi /* PID */
CALL_L64("waitpid")
cmpq $0, %rax
jle __afl_die
/* Relay wait status to pipe, then loop back. */
movq $4, %rdx /* length */
leaq __afl_temp(%rip), %rsi /* data */
movq $" STRINGIFY((FORKSRV_FD + 1)) ", %rdi /* file desc */
CALL_L64("write")
jmp __afl_fork_wait_loop
等待fuzzer通过控制管道发送过来的命令,读入到
__afl_temp中:读取失败,跳转到
__afl_die,结束循环;读取成功,继续;
fork 一个子进程,子进程执行
__afl_fork_resume;将子进程的pid赋给
__afl_fork_pid,并写到状态管道中通知父进程;等待子进程执行完成,写入状态管道告知 fuzzer;
重新执行下一轮
__afl_fork_wait_loop。
7. __afl_fork_resume
__afl_fork_resume:
/* In child process: close fds, resume execution. */
movq $" STRINGIFY(FORKSRV_FD) ", %rdi
CALL_L64("close")
movq $(" STRINGIFY(FORKSRV_FD) " + 1), %rdi
CALL_L64("close")
popq %rdx
popq %rdx
movq %r12, %rsp
popq %r12
movq 0(%rsp), %rax
movq 8(%rsp), %rcx
movq 16(%rsp), %rdi
movq 32(%rsp), %rsi
movq 40(%rsp), %r8
movq 48(%rsp), %r9
movq 56(%rsp), %r10
movq 64(%rsp), %r11
movq 96(%rsp), %xmm0
movq 112(%rsp), %xmm1
movq 128(%rsp), %xmm2
movq 144(%rsp), %xmm3
movq 160(%rsp), %xmm4
movq 176(%rsp), %xmm5
movq 192(%rsp), %xmm6
movq 208(%rsp), %xmm7
movq 224(%rsp), %xmm8
movq 240(%rsp), %xmm/9
movq 256(%rsp), %xmm10
movq 272(%rsp), %xmm11
movq 288(%rsp), %xmm12
movq 304(%rsp), %xmm13
movq 320(%rsp), %xmm14
movq 336(%rsp), %xmm15
leaq 352(%rsp), %rsp
jmp __afl_store
关闭子进程中的fd;
恢复子进程的寄存器状态;
跳转到
__afl_store执行。
8. __afl_store
__afl_store: /* Calculate and store hit for the code location specified in rcx. */ xorq __afl_prev_loc(%rip), %rcx xorq %rcx, __afl_prev_loc(%rip) shrq $1, __afl_prev_loc(%rip) incb (%rdx, %rcx, 1)
我们直接看反编译的代码:
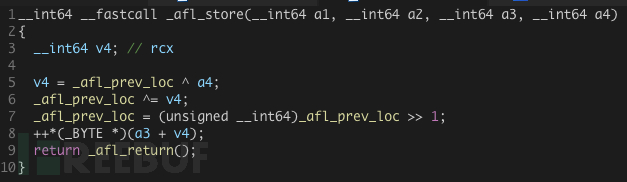
这里第一步的异或中的a4,其实是调用__afl_maybe_log时传入 的参数:

再往上追溯到插桩代码:
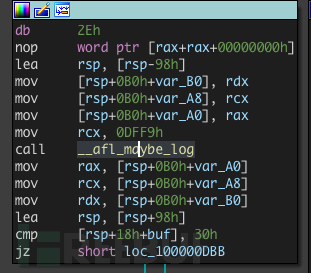
可以看到传入rcx的,实际上就是用于标记当前桩的随机id, 而_afl_prev_loc其实是上一个桩的随机id。
经过两次异或之后,再将_afl_prev_loc右移一位作为新的_afl_prev_loc,最后再共享内存中存储当前插桩位置的地方计数加一。
二、AFL 的插桩 —— llvm_mode
(一)、LLVM 前置知识
LLVM 主要为了解决编译时多种多样的前端和后端导致编译环境复杂、苛刻的问题,其核心为设计了一个称为LLVM IR的中间表示,并以库的形式提供一些列接口,以提供诸如操作 IR 、生成目标平台代码等等后端的功能。其整体架构如下所示:
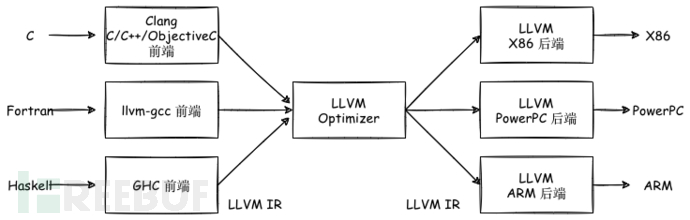
不同的前端和后端使用统一的中间代码LLVM InterMediate Representation(LLVM IR),其结果就是如果需要支持一门新的编程语言,只需要实现一个新的前端;如果需要支持一款新的硬件设备,只需要实现一个新的后端;优化阶段为通用阶段,针对统一的 LLVM IR ,与新的编程语言和硬件设备无关。
GCC 的前后端耦合在一起,没有进行分离,所以GCC为了支持一门新的编程语言或一个新的硬件设备,需要重新开发前端到后端的完整过程。
Clang 是 LLVM 项目的一个子项目,它是 LLVM 架构下的 C/C++/Objective-C 的编译器,是 LLVM 前端的一部分。相较于GCC,具备编译速度快、占用内存少、模块化设计、诊断信息可读性强、设计清晰简单等优点。
最终从源码到机器码的流程如下(以 Clang 做编译器为例):

(LLVM Pass 是一些中间过程处理 IR 的可以用户自定义的内容,可以用来遍历、修改 IR 以达到插桩、优化、静态分析等目的。)
代码首先由编译器前端clang处理后得到中间代码IR,然后经过各 LLVM Pass 进行优化和转换,最终交给编译器后端生成机器码。
(二)、 AFL的afl-clang-fast
1. 概述
AFL的llvm_mode可以实现编译器级别的插桩,可以替代afl-gcc或afl-clang使用的比较“粗暴”的汇编级别的重写的方法,且具备如下几个优势:
编译器可以进行很多优化以提升效率;
可以实现CPU无关,可以在非 x86 架构上进行fuzz;
可以更好地处理多线程目标。
在AFL的llvm_mode文件夹下包含3个文件:afl-clang-fast.c,afl-llvm-pass.so.cc, afl-llvm-rt.o.c。
afl-llvm-rt.o.c文件主要是重写了afl-as.h文件中的main_payload部分,方便调用;
afl-llvm-pass.so.cc文件主要是当通过afl-clang-fast调用 clang 时,这个pass被插入到 LLVM 中,告诉编译器添加与 ``afl-as.h` 中大致等效的代码;
afl-clang-fast.c文件本质上是 clang 的 wrapper,最终调用的还是 clang 。但是与afl-gcc一样,会进行一些参数处理。
llvm_mode的插桩思路就是通过编写pass来实现信息记录,对每个基本块都插入探针,具体代码在afl-llvm-pass.so.cc文件中,初始化和forkserver操作通过链接完成。
2. 源码
1. afl-clang-fast.c
1. main 函数
main函数的全部逻辑如下:
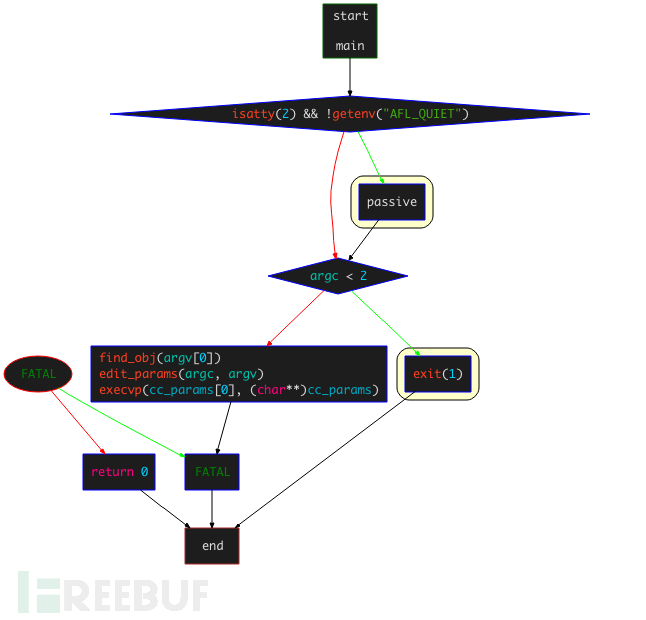
主要是对find_obj(), edit_params(), execvp()函数的调用,
其中主要有以下三个函数的调用:
find_obj(argv[0]):查找运行时libraryedit_params(argc, argv):处理传入的编译参数,将确定好的参数放入cc_params[]数组execvp(cc_params[0], (cahr**)cc_params):替换进程空间,传递参数,执行要调用的clang
这里后两个函数的作用与afl-gcc.c中的作用基本相同,只是对参数的处理过程存在不同,不同的主要是find_obj()函数。
2. find_obj 函数
find_obj()函数的控制流逻辑如下:
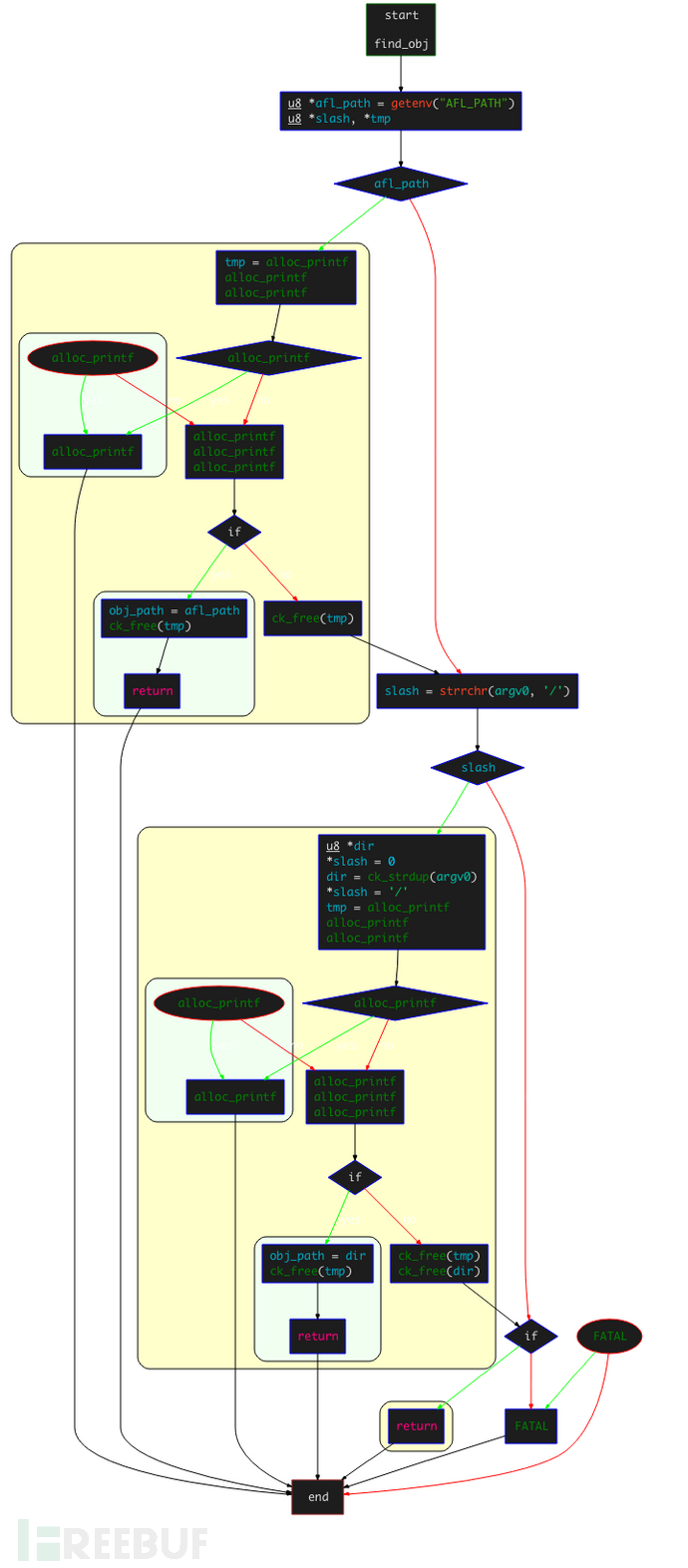
首先,读取环境变量
AFL_PATH的值:如果读取成功,确认
AFL_PATH/afl-llvm-rt.o是否可以访问;如果可以访问,设置该目录为obj_path,然后直接返回;如果读取失败,检查
arg0中是否存在/字符,如果存在,则判断最后一个/前面的路径为 AFL 的根目录;然后读取afl-llvm-rt.o文件,成功读取,设置该目录为obj_path,然后直接返回。
如果上面两种方式都失败,到
/usr/local/lib/afl目录下查找是否存在afl-llvm-rt.o,如果存在,则设置为obj_path并直接返回(之所以向该路径下寻找,是因为默认的AFL的MakeFile在编译时,会定义一个名为AFL_PATH的宏,该宏会指向该路径);如果以上全部失败,抛出异常提示找不到
afl-llvm-rt.o文件或afl-llvm-pass.so文件,并要求设置AFL_PATH环境变量 。
函数的主要功能是在寻找AFL的路径以找到afl-llvm-rt.o文件,该文件即为要用到的运行时库。
3. edit_params 函数
该函数的主要作用仍然为编辑参数数组,其控制流程如下:
首先,判断执行的是否为
afl-clang-fast++:如果是,设置
cc_params[0]为环境变量AFL_CXX;如果环境变量为空,则设置为clang++;如果不是,设置
cc_params[0]为环境变量AFL_CC;如果环境变量为空,则设置为clang;
判断是否定义了
USE_TRACE_PC宏,如果有,添加-fsanitize-coverage=trace-pc-guard -mllvm(only Android) -sanitizer-coverage-block-threshold=0(only Android)选项到参数数组;如果没有,依次将-Xclang -load -Xclang obj_path/afl-llvm-pass.so -Qunused-arguments选项添加到参数数组;(这里涉及到llvm_mode使用的2种插桩方式:默认使用的是传统模式,使用afl-llvm-pass.so注入来进行插桩,这种方式较为稳定;另外一种是处于实验阶段的方式——trace-pc-guard模式,对于该模式的详细介绍可以参考llvm相关文档——tracing-pcs-with-guards)遍历传递给
afl-clang-fast的参数,进行一定的检查和设置,并添加到cc_params数组:如果存在
-m32或armv7a-linux-androideabi,设置bit_mode为32;如果存在
-m64,设置bit_mode为64;如果存在
-x,设置x_set为1;如果存在
-fsanitize=address或-fsanitize=memory,设置asan_set为1;如果存在
-Wl,-z,defs或-Wl,--no-undefined,则直接pass掉。
检查环境变量是否设置了
AFL_HARDEN:如果有,添加
-fstack-protector-all选项;如果有且没有设置
FORTIFY_SOURCE,添加-D_FORTIFY_SOURCE=2选项;
检查参数中是否存在
-fsanitize=memory,即asan_set为0:如果没有,尝试读取环境变量
AFL_USE_ASAN,如果存在,添加-U_FORTIFY_SOURCE -fsanitize=address;接下来对环境变量
AFL_USE_MSAN的处理方式与AFL_USE_ASAN类似,添加的选项为-U_FORTIFY_SOURCE -fsanitize=memory;
检查是否定义了
USE_TRACE_PC宏,如果存在定义,检查是否存在环境变量AFL_INST_RATIO,如果存在,抛出异常AFL_INST_RATIO无法在trace-pc时使用;检查环境变量
AFL_NO_BUILTIN,如果没有设置,添加-g -O3 -funroll-loops;检查环境变量
AFL_NO_BUILTIN,如果进行了设置,添加-fno-builtin-strcmp -fno-builtin-strncmp -fno-builtin-strcasecmp -fno-builtin-strcasecmp -fno-builtin-memcmp;添加参数
-D__AFL_HAVE_MANUAL_CONTROL=1 -D__AFL_COMPILER=1 -DFUZZING_BUILD_MODE_UNSAFE_FOR_PRODUCTION=1;定义了两个宏
__AFL_LOOP(), __AFL_INIT();检查是否设置了
x_set, 如果有添加-x none;检查是否设置了宏
__ANDORID__,如果没有,判断bit_mode的值:如果为0,即没有
-m32和-m64,添加obj_path/afl-llvm-rt.o;如果为32,添加
obj_path/afl-llvm-rt-32.o;如果为64,添加
obj_path/afl-llvm-rt-64.o。
2. afl-llvm-pass.so.cc
afl-llvm-pass.so.cc文件实现了 LLVM-mode 下的一个插桩 LLVM Pass。
本文不过多关心如何实现一个LLVM Pass,重点分析该pass的实现逻辑。
该文件只有一个Transform pass:AFLCoverage,继承自ModulePass,实现了一个runOnModule函数,这也是我们需要重点分析的函数。
namespace {
class AFLCoverage : public ModulePass {
public:
static char ID;
AFLCoverage() : ModulePass(ID) { }
bool runOnModule(Module &M) override;
// StringRef getPassName() const override {
// return "American Fuzzy Lop Instrumentation";
// }
};
}
1. pass注册
对pass进行注册的部分源码如下:
static void registerAFLPass(const PassManagerBuilder &,
legacy::PassManagerBase &PM) {
PM.add(new AFLCoverage());
}
static RegisterStandardPasses RegisterAFLPass(
PassManagerBuilder::EP_ModuleOptimizerEarly, registerAFLPass);
static RegisterStandardPasses RegisterAFLPass0(
PassManagerBuilder::EP_EnabledOnOptLevel0, registerAFLPass);
其核心功能为向PassManager注册新的pass,每个pass相互独立。
对于pass注册的细节部分请读者自行研究llvm的相关内容。
2. runOnModule 函数
该函数为该文件中的关键函数,其控制流程图如下:
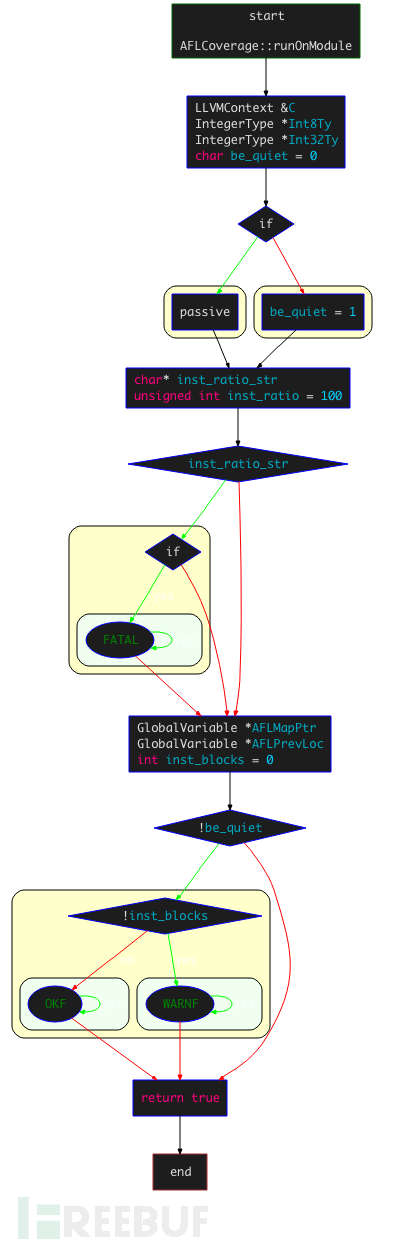
首先,通过
getContext()来获取LLVMContext,获取进程上下文:LLVMContext &C = M.getContext(); IntegerType *Int8Ty = IntegerType::getInt8Ty(C); IntegerType *Int32Ty = IntegerType::getInt32Ty(C);设置插桩密度:读取环境变量
AFL_INST_RATIO,并赋值给inst_ratio,其值默认为100,范围为 1~100,该值表示插桩概率;获取只想共享内存shm的指针以及上一个基本块的随机ID:
GlobalVariable *AFLMapPtr = new GlobalVariable(M, PointerType::get(Int8Ty, 0), false, GlobalValue::ExternalLinkage, 0, "__afl_area_ptr"); GlobalVariable *AFLPrevLoc = new GlobalVariable( M, Int32Ty, false, GlobalValue::ExternalLinkage, 0, "__afl_prev_loc", 0, GlobalVariable::GeneralDynamicTLSModel, 0, false);进入插桩过程:
通过
for循环遍历每个BB(基本块),寻找BB中适合插入桩代码的位置,然后通过初始化IRBuilder实例执行插入;BasicBlock::iterator IP = BB.getFirstInsertionPt(); IRBuilder<> IRB(&(*IP));随机创建当前BB的ID,然后插入load指令,获取前一个BB的ID;
if (AFL_R(100) >= inst_ratio) continue; // 如果大于插桩密度,进行随机插桩 /* Make up cur_loc */ unsigned int cur_loc = AFL_R(MAP_SIZE); ConstantInt *CurLoc = ConstantInt::get(Int32Ty, cur_loc); // 随机创建当前基本块ID /* Load prev_loc */ LoadInst *PrevLoc = IRB.CreateLoad(AFLPrevLoc); PrevLoc->setMetadata(M.getMDKindID("nosanitize"), MDNode::get(C, None)); Value *PrevLocCasted = IRB.CreateZExt(PrevLoc, IRB.getInt32Ty()); // 获取上一个基本块的随机ID插入load指令,获取共享内存的地址,并调用
CreateGEP函数获取共享内存中指定index的地址;/* Load SHM pointer */ LoadInst *MapPtr = IRB.CreateLoad(AFLMapPtr); MapPtr->setMetadata(M.getMDKindID("nosanitize"), MDNode::get(C, None)); Value *MapPtrIdx = IRB.CreateGEP(MapPtr, IRB.CreateXor(PrevLocCasted, CurLoc));插入load指令,获取对应index地址的值;插入add指令加一,然后创建store指令写入新值,并更新共享内存;
/* Update bitmap */ LoadInst *Counter = IRB.CreateLoad(MapPtrIdx); Counter->setMetadata(M.getMDKindID("nosanitize"), MDNode::get(C, None)); Value *Incr = IRB.CreateAdd(Counter, ConstantInt::get(Int8Ty, 1)); IRB.CreateStore(Incr, MapPtrIdx) ->setMetadata(M.getMDKindID("nosanitize"), MDNode::get(C, None));右移
cur_loc,插入store指令,更新__afl_prev_loc;/* Set prev_loc to cur_loc >> 1 */ StoreInst *Store = IRB.CreateStore(ConstantInt::get(Int32Ty, cur_loc >> 1), AFLPrevLoc); Store->setMetadata(M.getMDKindID("nosanitize"), MDNode::get(C, None));最后对插桩计数加1;
扫描下一个BB,根据设置是否为quiet模式等,并判断
inst_blocks是否为0,如果为0则说明没有进行插桩;if (!be_quiet) { if (!inst_blocks) WARNF("No instrumentation targets found."); else OKF("Instrumented %u locations (%s mode, ratio %u%%).", inst_blocks, getenv("AFL_HARDEN") ? "hardened" : ((getenv("AFL_USE_ASAN") || getenv("AFL_USE_MSAN")) ? "ASAN/MSAN" : "non-hardened"), inst_ratio); }
整个插桩过程较为清晰,没有冗余动作和代码。
3. afl-llvm-rt.o.c
该文件主要实现了llvm_mode的3个特殊功能:deferred instrumentation, persistent mode,trace-pc-guard mode 。
1. deferred instrumentation
AFL会尝试通过只执行一次目标二进制文件来提升性能,在main()之前暂停程序,然后克隆“主”进程获得一个稳定的可进行持续fuzz的目标。简言之,避免目标二进制文件的多次、重复的完整运行,而是采取了一种类似快照的机制。
虽然这种机制可以减少程序运行在操作系统、链接器和libc级别的消耗,但是在面对大型配置文件的解析时,优势并不明显。
在这种情况下,可以将forkserver的初始化放在大部分初始化工作完成之后、二进制文件解析之前来进行,这在某些情况下可以提升10倍以上的性能。我们把这种方式称为LLVM模式下的deferred instrumentation。
首先,在代码中寻找可以进行延迟克隆的合适的、不会破坏原二进制文件的位置,然后添加如下代码:
#ifdef __AFL_HAVE_MANUAL_CONTROL __AFL_INIT();#endif
以上代码插入,在afl-clang-fast.c文件中有说明:
cc_params[cc_par_cnt++] = "-D__AFL_INIT()=" "do { static volatile char *_A __attribute__((used)); " " _A = (char*)\"" DEFER_SIG "\"; "#ifdef __APPLE__ "__attribute__((visibility(\"default\"))) " "void _I(void) __asm__(\"___afl_manual_init\"); "#else "__attribute__((visibility(\"default\"))) " "void _I(void) __asm__(\"__afl_manual_init\"); "#endif /* ^__APPLE__ */
__afl_manual_init()函数实现如下:
/* This one can be called from user code when deferred forkserver mode
is enabled. */
void __afl_manual_init(void) {
static u8 init_done;
if (!init_done) {
__afl_map_shm();
__afl_start_forkserver();
init_done = 1;
}
}
首先,判断是否进行了初始化,没有则调用__afl_map_shm()函数进行共享内存初始化。__afl_map_shm()函数如下:
/* SHM setup. */
static void __afl_map_shm(void) {
u8 *id_str = getenv(SHM_ENV_VAR); // 读取环境变量 SHM_ENV_VAR 获取id
if (id_str) { // 成功读取id
u32 shm_id = atoi(id_str);
__afl_area_ptr = shmat(shm_id, NULL, 0); // 获取shm地址,赋给 __afl_area_ptr
/* Whooooops. */
if (__afl_area_ptr == (void *)-1) _exit(1); // 异常则退出
/* Write something into the bitmap so that even with low AFL_INST_RATIO,
our parent doesn't give up on us. */
__afl_area_ptr[0] = 1; // 进行设置
}
}
然后,调用__afl_start_forkserver()函数开始执行forkserver:
/* Fork server logic. */
static void __afl_start_forkserver(void) {
static u8 tmp[4];
s32 child_pid;
u8 child_stopped = 0;
/* Phone home and tell the parent that we're OK. If parent isn't there,
assume we're not running in forkserver mode and just execute program. */
if (write(FORKSRV_FD + 1, tmp, 4) != 4) return; // 写入4字节到状态管道,通知 fuzzer已准备完成
while (1) {
u32 was_killed;
int status;
/* Wait for parent by reading from the pipe. Abort if read fails. */
if (read(FORKSRV_FD, &was_killed, 4) != 4) _exit(1);
/* If we stopped the child in persistent mode, but there was a race
condition and afl-fuzz already issued SIGKILL, write off the old
process. */
// 处于persistent mode且子进程已被killed
if (child_stopped && was_killed) {
child_stopped = 0;
if (waitpid(child_pid, &status, 0) < 0) _exit(1);
}
if (!child_stopped) {
/* Once woken up, create a clone of our process. */
child_pid = fork(); // 重新fork
if (child_pid < 0) _exit(1);
/* In child process: close fds, resume execution. */
if (!child_pid) {
close(FORKSRV_FD); // 关闭fd,
close(FORKSRV_FD + 1);
return;
}
} else {
/* Special handling for persistent mode: if the child is alive but
currently stopped, simply restart it with SIGCONT. */
// 子进程只是暂停,则进行重启
kill(child_pid, SIGCONT);
child_stopped = 0;
}
/* In parent process: write PID to pipe, then wait for child. */
if (write(FORKSRV_FD + 1, &child_pid, 4) != 4) _exit(1);
if (waitpid(child_pid, &status, is_persistent ? WUNTRACED : 0) < 0)
_exit(1);
/* In persistent mode, the child stops itself with SIGSTOP to indicate
a successful run. In this case, we want to wake it up without forking
again. */
if (WIFSTOPPED(status)) child_stopped = 1;
/* Relay wait status to pipe, then loop back. */
if (write(FORKSRV_FD + 1, &status, 4) != 4) _exit(1);
}
}
上述逻辑可以概括如下:
首先,设置
child_stopped = 0,写入4字节到状态管道,通知fuzzer已准备完成;进入
while,开启fuzz循环:调用
read从控制管道读取4字节,判断子进程是否超时。如果管道内读取失败,发生阻塞,读取成功则表示AFL指示forkserver执行fuzz;如果
child_stopped为0,则fork出一个子进程执行fuzz,关闭和控制管道和状态管道相关的fd,跳出fuzz循环;如果
child_stopped为1,在persistent mode下进行的特殊处理,此时子进程还活着,只是被暂停了,可以通过kill(child_pid, SIGCONT)来简单的重启,然后设置child_stopped为0;forkserver向状态管道
FORKSRV_FD + 1写入子进程的pid,然后等待子进程结束;WIFSTOPPED(status)宏确定返回值是否对应于一个暂停子进程,因为在persistent mode里子进程会通过SIGSTOP信号来暂停自己,并以此指示运行成功,我们需要通过SIGCONT信号来唤醒子进程继续执行,不需要再进行一次fuzz,设置child_stopped为1;子进程结束后,向状态管道
FORKSRV_FD + 1写入4个字节,通知AFL本次执行结束。
######2. persistent mode
persistent mode并没有通过fork子进程的方式来执行fuzz。一些库中提供的API是无状态的,或者可以在处理不同输入文件之间进行重置,恢复到之前的状态。执行此类重置时,可以使用一个长期存活的进程来测试多个用例,以这种方式来减少重复的fork()调用和操作系统的开销。不得不说,这种思路真的很优秀。
一个基础的框架大概如下:
while (__AFL_LOOP(1000)) {
/* Read input data. */
/* Call library code to be fuzzed. */
/* Reset state. */
}
/* Exit normally */
设置一个while循环,并指定循环次数。在每次循环内,首先读取数据,然后调用想fuzz的库代码,然后重置状态,继续循环。(本质上也是一种快照。)
对于循环次数的设置,循环次数控制了AFL从头重新启动过程之前的最大迭代次数,较小的循环次数可以降低内存泄漏类故障的影响,官方建议的数值为1000。(循环次数设置过高可能出现较多意料之外的问题,并不建议设置过高。)
一个persistent mode的样例程序如下:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <signal.h>
#include <string.h>
/* Main entry point. */
int main(int argc, char** argv) {
char buf[100]; /* Example-only buffer, you'd rep/lace it with other global or
local variables appropriate for your use case. */
while (__AFL_LOOP(1000)) {
/*** P/LACEHOLDER CODE ***/
/* STEP 1: 初始化所有变量 */
memset(buf, 0, 100);
/* STEP 2: 读取输入数据,从文件读入时需要先关闭旧的fd然后重新打开文件*/
read(0, buf, 100);
/* STEP 3: 调用待fuzz的code*/
if (buf[0] == 'f') {
printf("one\n");
if (buf[1] == 'o') {
printf("two\n");
if (buf[2] == 'o') {
printf("three\n");
if (buf[3] == '!') {
printf("four\n");
abort();
}
}
}
}
/*** END P/LACEHOLDER CODE ***/
}
/* 循环结束,正常结束。AFL会重启进程,并清理内存、剩余fd等 */
return 0;
}
宏定义__AFL_LOOP内部调用__afl_persistent_loop函数:
cc_params[cc_par_cnt++] = "-D__AFL_LOOP(_A)="
"({ static volatile char *_B __attribute__((used)); "
" _B = (char*)\"" PERSIST_SIG "\"; "
#ifdef __APPLE__
"__attribute__((visibility(\"default\"))) "
"int _L(unsigned int) __asm__(\"___afl_persistent_loop\"); "
#else
"__attribute__((visibility(\"default\"))) "
"int _L(unsigned int) __asm__(\"__afl_persistent_loop\"); "
#endif /* ^__APPLE__ */
"_L(_A); })";
__afl_persistent_loop(unsigned int max_cnt)的逻辑如下:
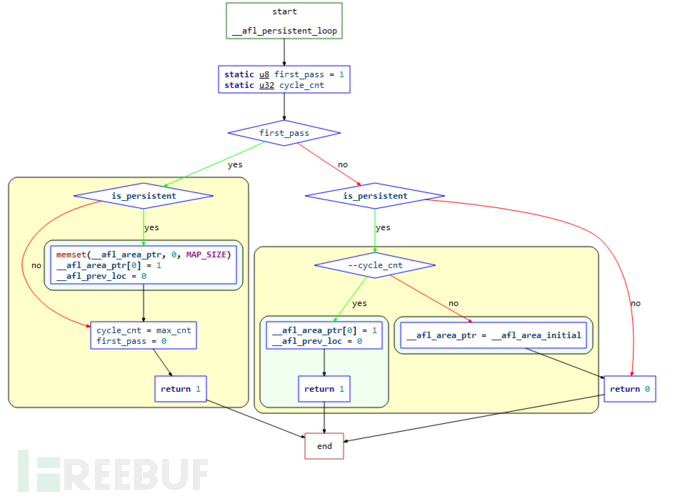
结合源码梳理一下其逻辑:
/* A simplified persistent mode handler, used as exp/lained in README.llvm. */
int __afl_persistent_loop(unsigned int max_cnt) {
static u8 first_pass = 1;
static u32 cycle_cnt;
if (first_pass) {
if (is_persistent) {
memset(__afl_area_ptr, 0, MAP_SIZE);
__afl_area_ptr[0] = 1;
__afl_prev_loc = 0;
}
cycle_cnt = max_cnt;
first_pass = 0;
return 1;
}
if (is_persistent) {
if (--cycle_cnt) {
raise(SIGSTOP);
__afl_area_ptr[0] = 1;
__afl_prev_loc = 0;
return 1;
} else {
__afl_area_ptr = __afl_area_initial;
}
}
return 0;
}
首先判读是否为第一次执行循环,如果是第一次:
如果
is_persistent为1,清空__afl_area_ptr,设置__afl_area_ptr[0]为1,__afl_prev_loc为0;设置
cycle_cnt的值为传入的max_cnt参数,然后设置first_pass=0表示初次循环结束,返回1;
如果不是第一次执行循环,在 persistent mode 下,且
--cycle_cnt大于1:发出信号
SIGSTOP让当前进程暂停设置
__afl_area_ptr[0]为1,__afl_prev_loc为0,然后直接返回1如果
cycle_cnt为0,设置__afl_area_ptr指向数组__afl_area_initial。
最后返回0
重新总结一下上面的逻辑:
第一次执行loop循环,进行初始化,然后返回1,此时满足
while(__AFL_LOOP(1000), 于是执行一次fuzz,计数器cnt减1,抛出SIGSTOP信号暂停子进程;第二次执行loop循环,恢复之前暂停的子进程继续执行,并设置
child_stopped为0。此时相当于重新执行了一次程序,重新对__afl_prev_loc进行设置,随后返回1,再次进入while(_AFL_LOOP(1000)),执行一次fuzz,计数器cnt减1,抛出SIGSTOP信号暂停子进程;第1000次执行,计数器cnt此时为0,不再暂停子进程,令
__afl_area_ptr指向无关数组__afl_area_initial,随后子进程结束。
3. trace-pc-guard mode
该功能的使用需要设置宏AFL_TRACE_PC=1,然后再执行afl-clang-fast时传入参数-fsanitize-coverage=trace-pc-guard。
该功能的主要特点是会在每个edge插入桩代码,函数__sanitizer_cov_trace_pc_guard会在每个edge进行调用,该函数利用函数参数guard指针所指向的uint32值来确定共享内存上所对应的地址:
void __sanitizer_cov_trace_pc_guard(uint32_t* guard) { __afl_area_ptr[*guard]++;}
guard的初始化位于函数__sanitizer_cov_trace_pc_guard_init中:
void __sanitizer_cov_trace_pc_guard_init(uint32_t* start, uint32_t* stop) { u32 inst_ratio = 100; u8* x; if (start == stop || *start) return; x = getenv("AFL_INST_RATIO"); if (x) inst_ratio = atoi(x); if (!inst_ratio || inst_ratio > 100) { fprintf(stderr, "[-] ERROR: Invalid AFL_INST_RATIO (must be 1-100).\n"); abort(); } *(start++) = R(MAP_SIZE - 1) + 1; while (start < stop) { // 这里如果计算stop-start,就是程序里总计的edge数 if (R(100) < inst_ratio) *start = R(MAP_SIZE - 1) + 1; else *start = 0; start++; }}
三、AFL的fuzzer —— afl-fuzz.c
1. 、概述
AFL中最重要的部分便是fuzzer的实现部分——afl_fuzz.c,其主要作用是通过不断变异测试用例来影响程序的执行路径。该文件代码量在8000行左右,处于篇幅原因,我们不会对每一个函数进行源码级分析,而是按照功能划分,介绍其中的核心函数。该文件属于AFL整个项目的核心中的核心,强烈建议通读该文件。
在介绍源码的同时,会穿插AFL的整体运行过程和设计思路,辅助理解源码的设计思路。
在功能上,可以总体上分为3部分:
初始配置:进行fuzz环境配置相关工作
fuzz执行:fuzz的主循环过程
变异策略:测试用例的变异过程和方式
我们将按照以上3个功能对其中的关键函数和流程进行分析。
2、核心源码分析
1. 初始配置
1.1 第一个while循环
while ((opt = getopt(argc, argv, "+i:o:f:m:b:t:T:dnCB:S:M:x:QV")) > 0)
... ...
该循环主要通过getopt获取各种环境配置、选项参数等。
1.2 setup_signal_handlers 函数
调用sigaction,注册信号处理函数,设置信号句柄。具体的信号内容如下:
| 信号 | 作用 |
|---|---|
| SIGHUP/SIGINT/SIGTERM | 处理各种“stop”情况 |
| SIGALRM | 处理超时的情况 |
| SIGWINCH | 处理窗口大小 |
| SIGUSER1 | 用户自定义信号,这里定义为skip request |
| SIGSTP/SIGPIPE | 不是很重要的一些信号,可以不用关心 |
1.3 check_asan_opts 函数
读取环境变量ASAN_OPTIONS和MSAN_OPTIONS,做一些必要性检查。
1.4 fix_up_sync 函数
如果通过-M或者-S指定了sync_id,则更新out_dir和sync_dir的值:设置sync_dir的值为out_dir,设置out_dir的值为out_dir/sync_id。
1.5 save_cmdline 函数
copy当前命令行参数,保存。
1.6 check_if_tty 函数
检查是否在tty终端上面运行:读取环境变量AFL_NO_UI,如果存在,设置not_on_tty为1,并返回;通过ioctl读取window size,如果报错为ENOTTY,表示当前不在一个tty终端运行,设置not_on_tty。
1.7 几个CPU检查相关的函数
static void get_core_count(void)get_core_count():获取核心数量check_crash_handling():确保核心转储不会进入程序check_cpu_governor():检查CPU管理者
1.8 setup_shm函数
该函数用于设置共享内存和virgin_bits,属于比较重要的函数,这里我们结合源码来解析一下:
/* Configure shared memory and virgin_bits. This is called at startup. */
EXP_ST void setup_shm(void) {
u8* shm_str;
if (!in_bitmap) memset(virgin_bits, 255, MAP_SIZE);
// 如果 in_bitmap 为空,调用 memset 初始化数组 virgin_bits[MAP_SIZE] 的每个元素的值为 ‘255’。
memset(virgin_tmout, 255, MAP_SIZE); // 调用 memset 初始化数组 virgin_tmout[MAP_SIZE] 的每个元素的值为 ‘255’。
memset(virgin_crash, 255, MAP_SIZE); // 调用 memset 初始化数组 virgin_crash[MAP_SIZE] 的每个元素的值为 ‘255’。
shm_id = shmget(IPC_PRIVATE, MAP_SIZE, IPC_CREAT | IPC_EXCL | 0600);
// 调用 shmget 函数分配一块共享内存,并将返回的共享内存标识符保存到 shm_id
if (shm_id < 0) PFATAL("shmget() failed");
atexit(remove_shm); // 注册 atexit handler 为 remove_shm
shm_str = alloc_printf("%d", shm_id); // 创建字符串 shm_str
/* If somebody is asking us to fuzz instrumented binaries in dumb mode,
we don't want them to detect instrumentation, since we won't be sending
fork server commands. This should be rep/laced with better auto-detection
later on, perhaps? */
if (!dumb_mode) setenv(SHM_ENV_VAR, shm_str, 1);
// 如果不是dumb_mode,设置环境变量 SHM_ENV_VAR 的值为 shm_str
ck_free(shm_str);
trace_bits = shmat(shm_id, NULL, 0);
// 设置 trace_bits 并初始化为0
if (trace_bits == (void *)-1) PFATAL("shmat() failed");
}
这里通过trace_bits和virgin_bits两个 bitmap 来分别记录当前的 tuple 信息及整体 tuple 信息,其中trace_bits位于共享内存上,便于进行进程间通信。通过virgin_tmout和virgin_crash两个 bitmap 来记录 fuzz 过程中出现的所有目标程序超时以及崩溃的 tuple 信息。
1.9 setup_dirs_fds 函数
该函数用于准备输出文件夹和文件描述符,结合源码进行解析:
EXP_ST void setup_dirs_fds(void) {
u8* tmp;
s32 fd;
ACTF("Setting up output directories...");
if (sync_id && mkdir(sync_dir, 0700) && errno != EEXIST)
PFATAL("Unable to create '%s'", sync_dir);
/* 如果sync_id,且创建sync_dir文件夹并设置权限为0700,如果报错单errno不是 EEXIST ,抛出异常 */
if (mkdir(out_dir, 0700)) { // 创建out_dir, 权限为0700
if (errno != EEXIST) PFATAL("Unable to create '%s'", out_dir);
maybe_delete_out_dir();
} else {
if (in_p/lace_resume) // 创建成功
FATAL("Resume attempted but old output directory not found");
out_dir_fd = open(out_dir, O_RDONLY); // 以只读模式打开,返回fd:out_dir_fd
#ifndef __sun
if (out_dir_fd < 0 || flock(out_dir_fd, LOCK_EX | LOCK_NB))
PFATAL("Unable to flock() output directory.");
#endif /* !__sun */
}
/* Queue directory for any starting & discovered paths. */
tmp = alloc_printf("%s/queue", out_dir);
if (mkdir(tmp, 0700)) PFATAL("Unable to create '%s'", tmp);
// 创建 out_dir/queue 文件夹,权限为0700
ck_free(tmp);
/* Top-level directory for queue metadata used for session
resume and related tasks. */
tmp = alloc_printf("%s/queue/.state/", out_dir);
// 创建 out_dir/queue/.state 文件夹,用于保存session resume 和相关tasks的队列元数据。
if (mkdir(tmp, 0700)) PFATAL("Unable to create '%s'", tmp);
ck_free(tmp);
/* Directory for flagging queue entries that went through
deterministic fuzzing in the past. */
tmp = alloc_printf("%s/queue/.state/deterministic_done/", out_dir);
if (mkdir(tmp, 0700)) PFATAL("Unable to create '%s'", tmp);
ck_free(tmp);
/* Directory with the auto-selected dictionary entries. */
tmp = alloc_printf("%s/queue/.state/auto_extras/", out_dir);
if (mkdir(tmp, 0700)) PFATAL("Unable to create '%s'", tmp);
ck_free(tmp);
/* The set of paths currently deemed redundant. */
tmp = alloc_printf("%s/queue/.state/redundant_edges/", out_dir);
if (mkdir(tmp, 0700)) PFATAL("Unable to create '%s'", tmp);
ck_free(tmp);
/* The set of paths showing variable behavior. */
tmp = alloc_printf("%s/queue/.state/variable_behavior/", out_dir);
if (mkdir(tmp, 0700)) PFATAL("Unable to create '%s'", tmp);
ck_free(tmp);
/* Sync directory for keeping track of cooperating fuzzers. */
if (sync_id) {
tmp = alloc_printf("%s/.synced/", out_dir);
if (mkdir(tmp, 0700) && (!in_p/lace_resume || errno != EEXIST))
PFATAL("Unable to create '%s'", tmp);
ck_free(tmp);
}
/* All recorded crashes. */
tmp = alloc_printf("%s/crashes", out_dir);
if (mkdir(tmp, 0700)) PFATAL("Unable to create '%s'", tmp);
ck_free(tmp);
/* All recorded hangs. */
tmp = alloc_printf("%s/hangs", out_dir);
if (mkdir(tmp, 0700)) PFATAL("Unable to create '%s'", tmp);
ck_free(tmp);
/* Generally useful file descriptors. */
dev_null_fd = open("/dev/null", O_RDWR);
if (dev_null_fd < 0) PFATAL("Unable to open /dev/null");
dev_urandom_fd = open("/dev/urandom", O_RDONLY);
if (dev_urandom_fd < 0) PFATAL("Unable to open /dev/urandom");
/* Gnuplot output file. */
tmp = alloc_printf("%s/plot_data", out_dir);
fd = open(tmp, O_WRONLY | O_CREAT | O_EXCL, 0600);
if (fd < 0) PFATAL("Unable to create '%s'", tmp);
ck_free(tmp);
plot_file = fdopen(fd, "w");
if (!plot_file) PFATAL("fdopen() failed");
fprintf(plot_file, "# unix_time, cycles_done, cur_path, paths_total, "
"pending_total, pending_favs, map_size, unique_crashes, "
"unique_hangs, max_depth, execs_per_sec\n");
/* ignore errors */
该函数的源码中,开发者对关键位置均做了清楚的注释,很容易理解,不做过多解释。
1.10 read_testcases 函数
该函数会将in_dir目录下的测试用例扫描到queue中,并且区分该文件是否为经过确定性变异的input,如果是的话跳过,以节省时间。
调用函数add_to_queue()将测试用例排成queue队列。该函数会在启动时进行调用。
1.11 add_to_queue 函数
该函数主要用于将新的test case添加到队列,初始化fname文件名称,增加cur_depth深度,增加queued_paths测试用例数量等。
首先,queue_entry结构体定义如下:
struct queue_entry {
u8* fname; /* File name for the test case */
u32 len; /* Input length */
u8 cal_failed, /* Calibration failed? */
trim_done, /* Trimmed? */
was_fuzzed, /* Had any fuzzing done yet? */
passed_det, /* Deterministic stages passed? */
has_new_cov, /* Triggers new coverage? */
var_behavior, /* Variable behavior? */
favored, /* Currently favored? */
fs_redundant; /* Marked as redundant in the fs? */
u32 bitmap_size, /* Number of bits set in bitmap */
exec_cksum; /* Checksum of the execution trace */
u64 exec_us, /* Execution time (us) */
handicap, /* Number of queue cycles behind */
depth; /* Path depth */
u8* trace_mini; /* Trace bytes, if kept */
u32 tc_ref; /* Trace bytes ref count */
struct queue_entry *next, /* Next element, if any */
*next_100; /* 100 elements ahead */
};
然后在函数内部进行的相关操作如下:
/* Append new test case to the queue. */static void add_to_queue(u8* fname, u32 len, u8 passed_det) { struct queue_entry* q = ck_alloc(sizeof(struct queue_entry)); // 通过ck_alloc分配一个 queue_entry 结构体,并进行初始化 q->fname = fname; q->len = len; q->depth = cur_depth + 1; q->passed_det = passed_det; if (q->depth > max_depth) max_depth = q->depth; if (queue_top) { queue_top->next = q; queue_top = q; } else q_prev100 = queue = queue_top = q; queued_paths++; // queue计数器加1 pending_not_fuzzed++; // 待fuzz的样例计数器加1 cycles_wo_finds = 0; /* Set next_100 pointer for every 100th element (index 0, 100, etc) to allow faster iteration. */ if ((queued_paths - 1) % 100 == 0 && queued_paths > 1) { q_prev100->next_100 = q; q_prev100 = q; } last_path_time = get_cur_time();}
1.12 pivot_inputs 函数
在输出目录中为输入测试用例创建硬链接。
1. 13 find_timeout 函数
变量timeout_given没有被设置时,会调用到该函数。该函数主要是在没有指定-t选项进行 resuming session 时,避免一次次地自动调整超时时间。
1.14 detect_file_args
识别参数中是否有“@@”,如果有,则替换为out_dir/.cur_input,没有则返回:
/* Detect @@ in args. */
EXP_ST void detect_file_args(char** argv) {
u32 i = 0;
u8* cwd = getcwd(NULL, 0);
if (!cwd) PFATAL("getcwd() failed");
while (argv[i]) {
u8* aa_loc = strstr(argv[i], "@@"); // 查找@@
if (aa_loc) {
u8 *aa_subst, *n_arg;
/* If we don't have a file name chosen yet, use a safe default. */
if (!out_file)
out_file = alloc_printf("%s/.cur_input", out_dir);
/* Be sure that we're always using fully-qualified paths. */
if (out_file[0] == '/') aa_subst = out_file;
else aa_subst = alloc_printf("%s/%s", cwd, out_file);
/* Construct a replacement argv value. */
*aa_loc = 0;
n_arg = alloc_printf("%s%s%s", argv[i], aa_subst, aa_loc + 2);
argv[i] = n_arg;
*aa_loc = '@';
if (out_file[0] != '/') ck_free(aa_subst);
}
i++;
}
free(cwd); /* not tracked */
}
1.15 check_binary 函数
检查指定路径要执行的程序是否存在,是否为shell脚本,同时检查elf文件头是否合法及程序是否被插桩。
2. 第一遍fuzz
2.1 检查
调用get_cur_time()函数获取开始时间,检查是否处于qemu_mode。
2.2 perform_dry_run 函数
该函数是AFL中的一个关键函数,它会执行input文件夹下的预先准备的所有测试用例,生成初始化的 queue 和 bitmap,只对初始输入执行一次。函数控制流程图如下:
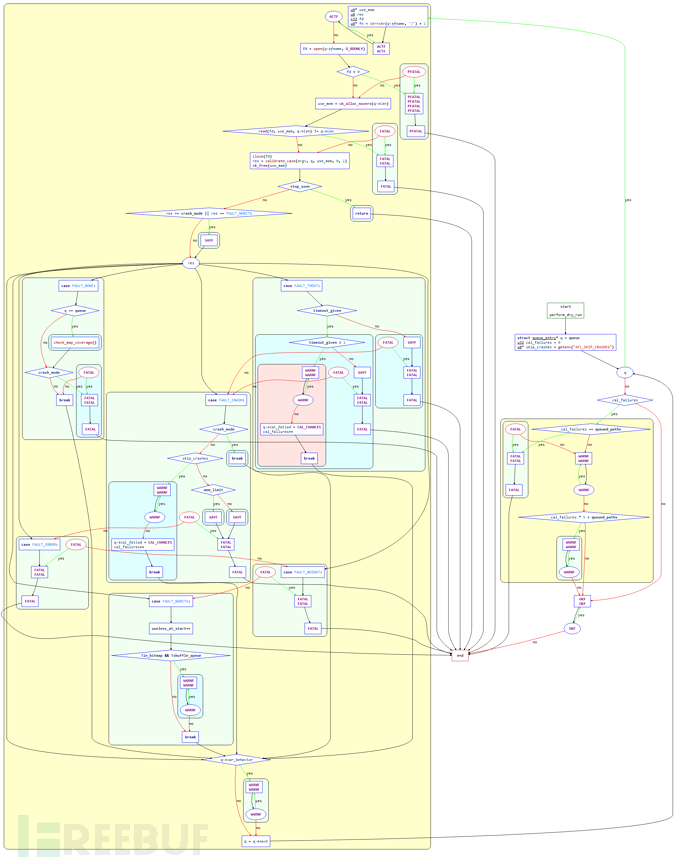
下面将结合函数源码进行解析(删除部分非关键代码):
/* Perform dry run of all test cases to confirm that the app is working as
expected. This is done only for the initial inputs, and only once. */
static void perform_dry_run(char** argv) {
struct queue_entry* q = queue; // 创建queue_entry结构体
u32 cal_failures = 0;
u8* skip_crashes = getenv("AFL_SKIP_CRASHES"); // 读取环境变量 AFL_SKIP_CRASHES
while (q) { // 遍历队列
u8* use_mem;
u8 res;
s32 fd;
u8* fn = strrchr(q->fname, '/') + 1;
ACTF("Attempting dry run with '%s'...", fn);
fd = open(q->fname, O_RDONLY);
if (fd < 0) PFATAL("Unable to open '%s'", q->fname);
use_mem = ck_alloc_nozero(q->len);
if (read(fd, use_mem, q->len) != q->len)
FATAL("Short read from '%s'", q->fname); // 打开q->fname,读取到分配的内存中
close(fd);
res = calibrate_case(argv, q, use_mem, 0, 1); // 调用函数calibrate_case校准测试用例
ck_free(use_mem);
if (stop_soon) return;
if (res == crash_mode || res == FAULT_NOBITS)
SAYF(cGRA " len = %u, map size = %u, exec speed = %llu us\n" cRST,
q->len, q->bitmap_size, q->exec_us);
switch (res) { // 判断res的值
case FAULT_NONE:
if (q == queue) check_map_coverage(); // 如果为头结点,调用check_map_coverage评估覆盖率
if (crash_mode) FATAL("Test case '%s' does *NOT* crash", fn); // 抛出异常
break;
case FAULT_TMOUT:
if (timeout_given) { // 指定了 -t 选项
/* The -t nn+ syntax in the command line sets timeout_given to '2' and
instructs afl-fuzz to tolerate but skip queue entries that time
out. */
if (timeout_given > 1) {
WARNF("Test case results in a timeout (skipping)");
q->cal_failed = CAL_CHANCES;
cal_failures++;
break;
}
SAYF(... ...);
FATAL("Test case '%s' results in a timeout", fn);
} else {
SAYF(... ...);
FATAL("Test case '%s' results in a timeout", fn);
}
case FAULT_CRASH:
if (crash_mode) break;
if (skip_crashes) {
WARNF("Test case results in a crash (skipping)");
q->cal_failed = CAL_CHANCES;
cal_failures++;
break;
}
if (mem_limit) { // 建议增加内存
SAYF(... ...);
} else {
SAYF(... ...);
}
FATAL("Test case '%s' results in a crash", fn);
case FAULT_ERROR:
FATAL("Unable to execute target application ('%s')", argv[0]);
case FAULT_NOINST: // 测试用例运行没有路径信息
FATAL("No instrumentation detected");
case FAULT_NOBITS: // 没有出现新路径,判定为无效路径
useless_at_start++;
if (!in_bitmap && !shuffle_queue)
WARNF("No new instrumentation output, test case may be useless.");
break;
}
if (q->var_behavior) WARNF("Instrumentation output varies across runs.");
q = q->next; // 读取下一个queue
}
if (cal_failures) {
if (cal_failures == queued_paths)
FATAL("All test cases time out%s, giving up!",
skip_crashes ? " or crash" : "");
WARNF("Skipped %u test cases (%0.02f%%) due to timeouts%s.", cal_failures,
((double)cal_failures) * 100 / queued_paths,
skip_crashes ? " or crashes" : "");
if (cal_failures * 5 > queued_paths)
WARNF(cLRD "High percentage of rejected test cases, check settings!");
}
OKF("All test cases processed.");
}
总结以上流程:
进入
while循环,遍历input队列,从队列中取出q->fname,读取文件内容到分配的内存中,然后关闭文件;调用
calibrate_case函数校准该测试用例;根据校准的返回值
res,判断错误类型;打印错误信息,退出。
2.3 calibrate_case 函数
该函数同样为AFL的一个关键函数,用于新测试用例的校准,在处理输入目录时执行,以便在早期就发现有问题的测试用例,并且在发现新路径时,评估新发现的测试用例的是否可变。该函数在perform_dry_run,save_if_interesting,fuzz_one,pilot_fuzzing,core_fuzzing函数中均有调用。该函数主要用途是初始化并启动fork server,多次运行测试用例,并用update_bitmap_score进行初始的byte排序。
函数控制流程图如下:
结合源码进行解读如下:
/* Calibrate a new test case. This is done when processing the input directory
to warn about flaky or otherwise problematic test cases early on; and when
new paths are discovered to detect variable behavior and so on. */
static u8 calibrate_case(char** argv, struct queue_entry* q, u8* use_mem,
u32 handicap, u8 from_queue) {
static u8 first_trace[MAP_SIZE]; // 创建 firts_trace[MAP_SIZE]
u8 fault = 0, new_bits = 0, var_detected = 0, hnb = 0,
first_run = (q->exec_cksum == 0); // 获取执行追踪结果,判断case是否为第一次运行,若为0则表示第一次运行,来自input文件夹
u64 start_us, stop_us;
s32 old_sc = stage_cur, old_sm = stage_max;
u32 use_tmout = exec_tmout;
u8* old_sn = stage_name; // 保存原有 stage_cur, stage_max, stage_name
/* Be a bit more generous about timeouts when resuming sessions, or when
trying to calibrate already-added finds. This helps avoid trouble due
to intermittent latency. */
if (!from_queue || resuming_fuzz)
// 如果from_queue为0(表示case不是来自queue)或者resuming_fuzz为1(表示处于resuming sessions)
use_tmout = MAX(exec_tmout + CAL_TMOUT_ADD,
exec_tmout * CAL_TMOUT_PERC / 100); // 提升 use_tmout 的值
q->cal_failed++;
stage_name = "calibration"; // 设置 stage_name
stage_max = fast_cal ? 3 : CAL_CYCLES; // 设置 stage_max,新测试用例的校准周期数
/* Make sure the fork server is up before we do anything, and let's not
count its spin-up time toward binary calibration. */
if (dumb_mode != 1 && !no_fork server && !forksrv_pid)
init_fork server(argv); // 没有运行在dumb_mode,没有禁用fork server,切forksrv_pid为0时,启动fork server
if (q->exec_cksum) { // 判断是否为新case(如果这个queue不是来自input文件夹)
memcpy(first_trace, trace_bits, MAP_SIZE);
hnb = has_new_bits(virgin_bits);
if (hnb > new_bits) new_bits = hnb;
}
start_us = get_cur_time_us();
for (stage_cur = 0; stage_cur < stage_max; stage_cur++) { // 开始执行 calibration stage,总计执行 stage_max 轮
u32 cksum;
if (!first_run && !(stage_cur % stats_update_freq)) show_stats(); // queue不是来自input,第一轮calibration stage执行结束,刷新一次展示界面
write_to_testcase(use_mem, q->len);
fault = run_target(argv, use_tmout);
/* stop_soon is set by the handler for Ctrl+C. When it's pressed,
we want to bail out quickly. */
if (stop_soon || fault != crash_mode) goto abort_calibration;
if (!dumb_mode && !stage_cur && !count_bytes(trace_bits)) {
// 如果 calibration stage第一次运行,且不在dumb_mode,共享内存中没有任何路径
fault = FAULT_NOINST;
goto abort_calibration;
}
cksum = hash32(trace_bits, MAP_SIZE, HASH_CONST);
if (q->exec_cksum != cksum) {
hnb = has_new_bits(virgin_bits);
if (hnb > new_bits) new_bits = hnb;
if (q->exec_cksum) { // 不等于exec_cksum,表示第一次运行,或在相同参数下,每次执行,cksum不同,表示是一个路径可变的queue
u32 i;
for (i = 0; i < MAP_SIZE; i++) {
if (!var_bytes[i] && first_trace[i] != trace_bits[i]) {
// 从0到MAP_SIZE进行遍历, first_trace[i] != trace_bits[i],表示发现了可变queue
var_bytes[i] = 1;
stage_max = CAL_CYCLES_LONG;
}
}
var_detected = 1;
} else {
q->exec_cksum = cksum; // q->exec_cksum=0,表示第一次执行queue,则设置计算出来的本次执行的cksum
memcpy(first_trace, trace_bits, MAP_SIZE);
}
}
}
stop_us = get_cur_time_us();
total_cal_us += stop_us - start_us; // 保存所有轮次的总执行时间
total_cal_cycles += stage_max; // 保存总轮次
/* OK, let's collect some stats about the performance of this test case.
This is used for fuzzing air time calculations in calculate_score(). */
q->exec_us = (stop_us - start_us) / stage_max; // 单次执行时间的平均值
q->bitmap_size = count_bytes(trace_bits); // 最后一次执行所覆盖的路径数
q->handicap = handicap;
q->cal_failed = 0;
total_bitmap_size += q->bitmap_size; // 加上queue所覆盖的路径数
total_bitmap_entries++;
update_bitmap_score(q);
/* If this case didn't result in new output from the instrumentation, tell
parent. This is a non-critical problem, but something to warn the user
about. */
if (!dumb_mode && first_run && !fault && !new_bits) fault = FAULT_NOBITS;
abort_calibration:
if (new_bits == 2 && !q->has_new_cov) {
q->has_new_cov = 1;
queued_with_cov++;
}
/* Mark variable paths. */
if (var_detected) { // queue是可变路径
var_byte_count = count_bytes(var_bytes);
if (!q->var_behavior) {
mark_as_variable(q);
queued_variable++;
}
}
// 恢复之前的stage值
stage_name = old_sn;
stage_cur = old_sc;
stage_max = old_sm;
if (!first_run) show_stats();
return fault;
}
总结以上过程如下:
进行参数设置,包括当前阶段
stage_cur,阶段名称stage_name,新比特 `new_bit 等初始化;参数
from_queue,判断case是否在队列中,且是否处于resuming session, 以此设置时间延迟。testcase参数q->cal_failed加1, 是否校准失败参数加1;判断是否已经启动fork server ,调用函数
init_fork server();拷贝
trace_bits到first_trace,调用get_cur_time_us()获取开始时间start_us;进入loop循环,该loop循环多次执行testcase,循环次数为8次或者3次;
调用
write_to_testcase将修改后的数据写入文件进行测试。如果use_stdin被清除,取消旧文件链接并创建一个新文件。否则,缩短prog_in_fd;调用
run_target通知fork server可以开始fork并fuzz;调用
hash32校验此次运行的trace_bits,检查是否出现新的情况;将本次运行的出现
trace_bits哈希和本次 testcase的q->exec_cksum对比。如果发现不同,则调用has_new_bits函数和总表virgin_bits对比;判断
q->exec_cksum是否为0,不为0说明不是第一次执行。后面运行如果和前面第一次trace_bits结果不同,则需要多运行几次;loop循环结束;
收集一些关于测试用例性能的统计数据。比如执行时间延迟,校准错误,bitmap大小等等;
调用
update_bitmap_score()函数对测试用例的每个byte进行排序,用一个top_rate[]维护最佳入口;如果没有从检测中得到
new_bit,则告诉父进程,这是一个无关紧要的问题,但是需要提醒用户。
总结:calibratecase函数到此为止,该函数主要用途是init_fork server;将testcase运行多次;用update_bitmap_score进行初始的byte排序。
2.4 init_forkserve 函数
AFL的fork server机制避免了多次执行execve()函数的多次调用,只需要调用一次然后通过管道发送命令即可。该函数主要用于启动APP和它的fork server。函数整体控制流程图如下:
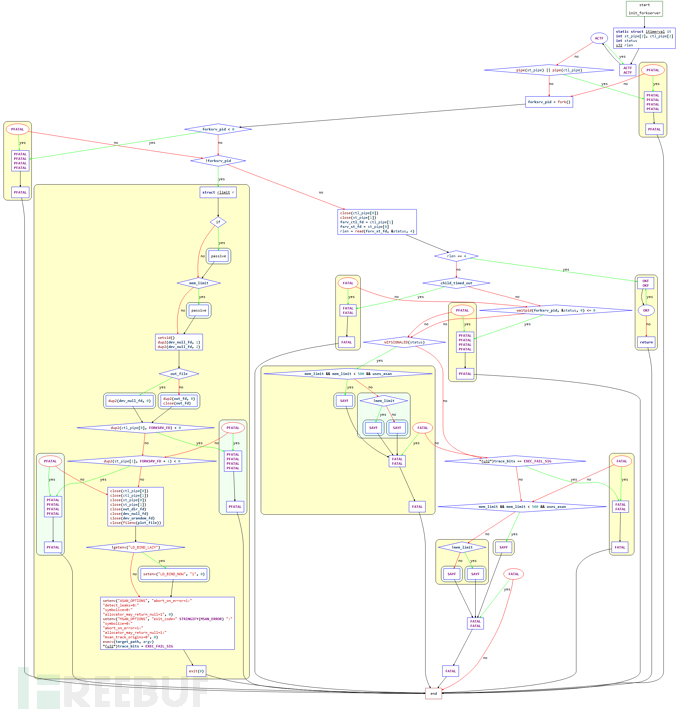
结合源码梳理一下函数流程:
EXP_ST void init_fork server(char** argv) {
static struct itimerval it;
int st_pipe[2], ctl_pipe[2];
int status;
s32 rlen;
ACTF("Spinning up the fork server...");
if (pipe(st_pipe) || pipe(ctl_pipe)) PFATAL("pipe() failed");
// 检查 st_pipe 和ctl_pipe,在父子进程间进行管道通信,一个用于传递状态,一个用于传递命令
forksrv_pid = fork();
// fork进程出一个子进程
// 如果fork成功,则现在有父子两个进程
// 此时的父进程为fuzzer,子进程则为目标程序进程,也是将来的fork server
if (forksrv_pid < 0) PFATAL("fork() failed"); // fork失败
// 子进程和父进程都会向下执行,通过pid来使父子进程执行不同的代码
if (!forksrv_pid) { // 子进程执行
struct rlimit r;
/* 中间省略针对OpenBSD的特殊处理 */
... ...
/* Isolate the process and configure standard descriptors. If out_file is
specified, stdin is /dev/null; otherwise, out_fd is cloned instead. */
// 创建守护进程
setsid();
// 重定向文件描述符1和2到dev_null_fd
dup2(dev_null_fd, 1);
dup2(dev_null_fd, 2);
// 如果指定了out_file,则文件描述符0重定向到dev_null_fd,否则重定向到out_fd
if (out_file) {
dup2(dev_null_fd, 0);
} else {
dup2(out_fd, 0);
close(out_fd);
}
/* Set up control and status pipes, close the unneeded original fds. */
// 设置控制和状态管道,关闭不需要的一些文件描述符
if (dup2(ctl_pipe[0], FORKSRV_FD) < 0) PFATAL("dup2() failed");
if (dup2(st_pipe[1], FORKSRV_FD + 1) < 0) PFATAL("dup2() failed");
close(ctl_pipe[0]);
close(ctl_pipe[1]);
close(st_pipe[0]);
close(st_pipe[1]);
close(out_dir_fd);
close(dev_null_fd);
close(dev_urandom_fd);
close(fileno(plot_file));
/* This should improve performance a bit, since it stops the linker from
doing extra work post-fork(). */
// 如果没有设置延迟绑定,则进行设置,不使用缺省模式
if (!getenv("LD_BIND_LAZY")) setenv("LD_BIND_NOW", "1", 0);
/* Set sane defaults for ASAN if nothing else specified. */
// 设置环境变量ASAN_OPTIONS,配置ASAN相关
setenv("ASAN_OPTIONS", "abort_on_error=1:"
"detect_leaks=0:"
"symbolize=0:"
"allocator_may_return_null=1", 0);
/* MSAN is tricky, because it doesn't support abort_on_error=1 at this
point. So, we do this in a very hacky way. */
// MSAN相关
setenv("MSAN_OPTIONS", "exit_code=" STRINGIFY(MSAN_ERROR) ":"
"symbolize=0:"
"abort_on_error=1:"
"allocator_may_return_null=1:"
"msan_track_origins=0", 0);
/* 带参数执行目标程序,报错才返回
execv()会替换原有进程空间为目标程序,所以后续执行的都是目标程序。
第一个目标程序会进入__afl_maybe_log里的__afl_fork_wait_loop,并充当fork server。
在整个过程中,每次要fuzz一次目标程序,都会从这个fork server再fork出来一个子进程去fuzz。
因此可以看作是三段式:fuzzer -> fork server -> target子进程
*/
execv(target_path, argv);
/* Use a distinctive bitmap signature to tell the parent about execv()
falling through. */
// 告诉父进程执行失败,结束子进程
*(u32*)trace_bits = EXEC_FAIL_SIG;
exit(0);
}
/* Close the unneeded endpoints. */
close(ctl_pipe[0]);
close(st_pipe[1]);
fsrv_ctl_fd = ctl_pipe[1]; // 父进程只能发送命令
fsrv_st_fd = st_pipe[0]; // 父进程只能读取状态
/* Wait for the fork server to come up, but don't wait too long. */
// 在一定时间内等待fork server启动
it.it_value.tv_sec = ((exec_tmout * FORK_WAIT_MULT) / 1000);
it.it_value.tv_usec = ((exec_tmout * FORK_WAIT_MULT) % 1000) * 1000;
setitimer(ITIMER_REAL, &it, NULL);
rlen = read(fsrv_st_fd, &status, 4); // 从管道里读取4字节数据到status
it.it_value.tv_sec = 0;
it.it_value.tv_usec = 0;
setitimer(ITIMER_REAL, &it, NULL);
/* If we have a four-byte "hello" message from the server, we're all set.
Otherwise, try to figure out what went wrong. */
if (rlen == 4) { // 以读取的结果判断fork server是否成功启动
OKF("All right - fork server is up.");
return;
}
// 子进程启动失败的异常处理相关
if (child_timed_out)
FATAL("Timeout while initializing fork server (adjusting -t may help)");
if (waitpid(forksrv_pid, &status, 0) <= 0)
PFATAL("waitpid() failed");
... ...
}
我们结合fuzzer对该函数的调用来梳理完整的流程如下:
启动目标程序进程后,目标程序会运行一个fork server,fuzzer自身并不负责fork子进程,而是通过管道与fork server通信,由fork server来完成fork以及继续执行目标程序的操作。

对于fuzzer和目标程序之间的通信状态我们可以通过下图来梳理:
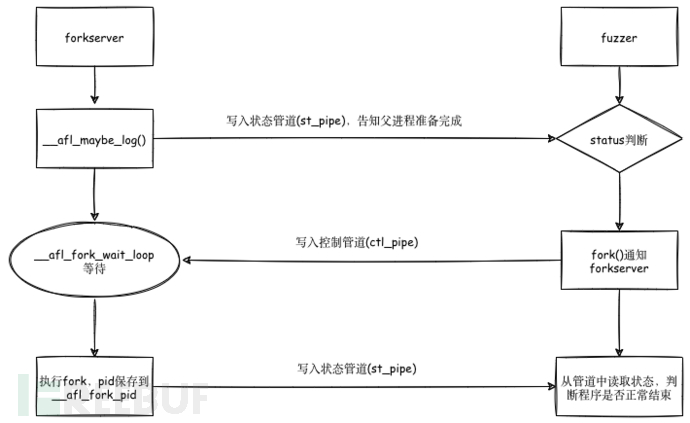
结合前面的插桩部分一起来看:
首先,afl-fuzz会创建两个管道:状态管道和控制管道,然后执行目标程序。此时的目标程序的main()函数已经被插桩,程序控制流进入__afl_maybe_log中。如果fuzz是第一次执行,则此时的程序就成了fork server们之后的目标程序都由该fork server通过fork生成子进程来运行。fuzz进行过程中,fork server会一直执行fork操作,并将子进程的结束状态通过状态管道传递给afl-fuzz。
(对于fork server的具体操作,在前面插桩部分时已经根据源码进行了说明,可以回顾一下。)
2.5 run_target 函数
该函数主要执行目标应用程序,并进行超时监控,返回状态信息,被调用的程序会更新trace_bits[]。
结合源码进行解释:
static u8 run_target(char** argv, u32 timeout) {
static struct itimerval it;
static u32 prev_timed_out = 0;
static u64 exec_ms = 0;
int status = 0;
u32 tb4;
child_timed_out = 0;
/* After this memset, trace_bits[] are effectively volatile, so we
must prevent any earlier operations from venturing into that
territory. */
memset(trace_bits, 0, MAP_SIZE); // 将trace_bits全部置0,清空共享内存
MEM_BARRIER();
/* If we're running in "dumb" mode, we can't rely on the fork server
logic compiled into the target program, so we will just keep calling
execve(). There is a bit of code duplication between here and
init_fork server(), but c'est la vie. */
if (dumb_mode == 1 || no_fork server) { // 如果是dumb_mode模式且没有fork server
child_pid = fork(); // 直接fork出一个子进程
if (child_pid < 0) PFATAL("fork() failed");
if (!child_pid) {
... ...
/* Isolate the process and configure standard descriptors. If out_file is
specified, stdin is /dev/null; otherwise, out_fd is cloned instead. */
setsid();
dup2(dev_null_fd, 1);
dup2(dev_null_fd, 2);
if (out_file) {
dup2(dev_null_fd, 0);
} else {
dup2(out_fd, 0);
close(out_fd);
}
/* On Linux, would be faster to use O_CLOEXEC. Maybe TODO. */
close(dev_null_fd);
close(out_dir_fd);
close(dev_urandom_fd);
close(fileno(plot_file));
/* Set sane defaults for ASAN if nothing else specified. */
setenv("ASAN_OPTIONS", "abort_on_error=1:"
"detect_leaks=0:"
"symbolize=0:"
"allocator_may_return_null=1", 0);
setenv("MSAN_OPTIONS", "exit_code=" STRINGIFY(MSAN_ERROR) ":"
"symbolize=0:"
"msan_track_origins=0", 0);
execv(target_path, argv); // 让子进程execv执行目标程序
/* Use a distinctive bitmap value to tell the parent about execv()
falling through. */
*(u32*)trace_bits = EXEC_FAIL_SIG; // execv执行失败,写入 EXEC_FAIL_SIG
exit(0);
}
} else {
s32 res;
/* In non-dumb mode, we have the fork server up and running, so simply
tell it to have at it, and then read back PID. */
// 如果并不是处在dumb_mode模式,说明fork server已经启动了,我们只需要进行
// 控制管道的写和状态管道的读即可
if ((res = write(fsrv_ctl_fd, &prev_timed_out, 4)) != 4) {
if (stop_soon) return 0;
RPFATAL(res, "Unable to request new process from fork server (OOM?)");
}
if ((res = read(fsrv_st_fd, &child_pid, 4)) != 4) {
if (stop_soon) return 0;
RPFATAL(res, "Unable to request new process from fork server (OOM?)");
}
if (child_pid <= 0) FATAL("Fork server is misbehaving (OOM?)");
}
/* Configure timeout, as requested by user, then wait for child to terminate. */
// 配置超时,等待子进程结束
it.it_value.tv_sec = (timeout / 1000);
it.it_value.tv_usec = (timeout % 1000) * 1000;
setitimer(ITIMER_REAL, &it, NULL);
/* The SIGALRM handler simply kills the child_pid and sets child_timed_out. */
if (dumb_mode == 1 || no_fork server) {
if (waitpid(child_pid, &status, 0) <= 0) PFATAL("waitpid() failed");
} else {
s32 res;
if ((res = read(fsrv_st_fd, &status, 4)) != 4) {
if (stop_soon) return 0;
RPFATAL(res, "Unable to communicate with fork server (OOM?)");
}
}
if (!WIFSTOPPED(status)) child_pid = 0;
getitimer(ITIMER_REAL, &it);
exec_ms = (u64) timeout - (it.it_value.tv_sec * 1000 +
it.it_value.tv_usec / 1000); // 计算执行时间
it.it_value.tv_sec = 0;
it.it_value.tv_usec = 0;
setitimer(ITIMER_REAL, &it, NULL);
total_execs++;
/* Any subsequent operations on trace_bits must not be moved by the
compiler below this point. Past this location, trace_bits[] behave
very normally and do not have to be treated as volatile. */
MEM_BARRIER();
tb4 = *(u32*)trace_bits;
// 分别执行64和32位下的classify_counts,设置trace_bits所在的mem
#ifdef WORD_SIZE_64
classify_counts((u64*)trace_bits);
#else
classify_counts((u32*)trace_bits);
#endif /* ^WORD_SIZE_64 */
prev_timed_out = child_timed_out;
/* Report outcome to caller. */
if (WIFSIGNALED(status) && !stop_soon) {
kill_signal = WTERMSIG(status);
if (child_timed_out && kill_signal == SIGKILL) return FAULT_TMOUT;
return FAULT_CRASH;
}
/* A somewhat nasty hack for MSAN, which doesn't support abort_on_error and
must use a special exit code. */
if (uses_asan && WEXITSTATUS(status) == MSAN_ERROR) {
kill_signal = 0;
return FAULT_CRASH;
}
if ((dumb_mode == 1 || no_fork server) && tb4 == EXEC_FAIL_SIG)
return FAULT_ERROR;
/* It makes sense to account for the slowest units only if the testcase was run
under the user defined timeout. */
if (!(timeout > exec_tmout) && (slowest_exec_ms < exec_ms)) {
slowest_exec_ms = exec_ms;
}
return FAULT_NONE;
}
2.6 update_bitmap_score 函数
当我们发现一个新路径时,需要判断发现的新路径是否更“favorable”,也就是是否包含最小的路径集合能遍历到所有bitmap中的位,并在之后的fuzz过程中聚焦在这些路径上。
以上过程的第一步是为bitmap中的每个字节维护一个top_rated[]的列表,这里会计算究竟哪些位置是更“合适”的,该函数主要实现该过程。
函数的控制流程图如下:
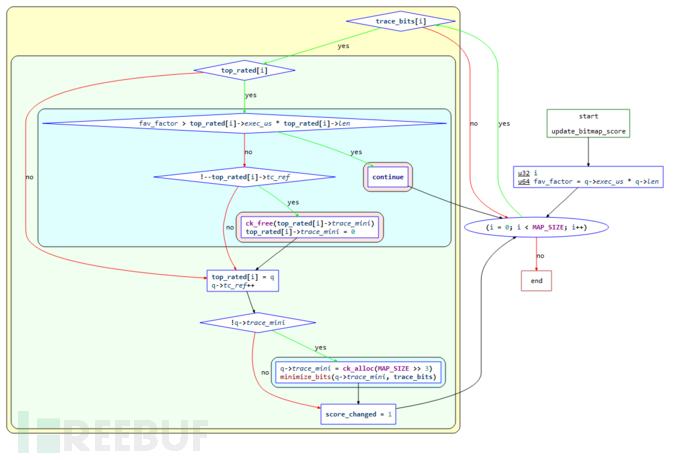
结合源码进行解释:
static void update_bitmap_score(struct queue_entry* q) { u32 i; u64 fav_factor = q->exec_us * q->len; // 首先计算case的fav_factor,计算方法是执行时间和样例大小的乘积 /* For every byte set in trace_bits[], see if there is a previous winner, and how it compares to us. */ for (i = 0; i < MAP_SIZE; i++) // 遍历trace_bits数组 if (trace_bits[i]) { // 不为0,表示已经被覆盖到的路径 if (top_rated[i]) { // 检查top_rated是否存在 /* Faster-executing or smaller test cases are favored. */ if (fav_factor > top_rated[i]->exec_us * top_rated[i]->len) continue; // 判断哪个计算结果更小 // 如果top_rated[i]的更小,则代表它的更优,不做处理,继续遍历下一个路径; // 如果q的更小,就执行以下代码: /* Looks like we're going to win. Decrease ref count for the previous winner, discard its trace_bits[] if necessary. */ if (!--top_rated[i]->tc_ref) { ck_free(top_rated[i]->trace_mini); top_rated[i]->trace_mini = 0; } } /* Insert ourselves as the new winner. */ top_rated[i] = q; // 设置为当前case q->tc_ref++; if (!q->trace_mini) { // 为空 q->trace_mini = ck_alloc(MAP_SIZE >> 3); minimize_bits(q->trace_mini, trace_bits); } score_changed = 1; }}
3. 主循环
3.1 主循环之前
3.1.1 cull_queue 函数
在前面讨论的关于case的top_rated的计算中,还有一个机制是检查所有的top_rated[]条目,然后顺序获取之前没有遇到过的byte的对比分数低的“获胜者”进行标记,标记至少会维持到下一次运行之前。在所有的fuzz步骤中,“favorable”的条目会获得更多的执行时间。
函数的控制流程图如下:
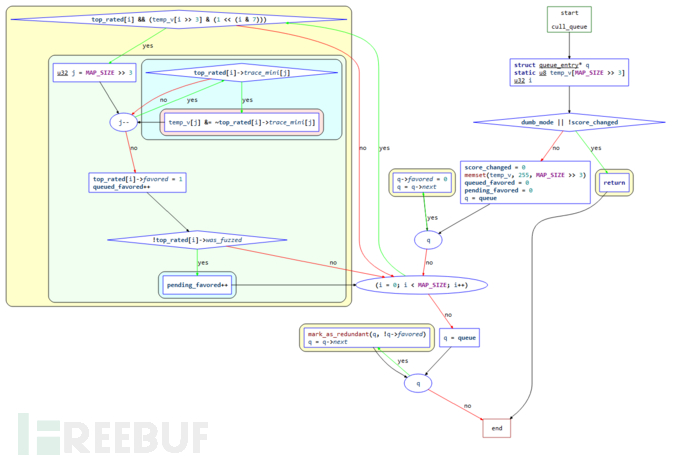
结合源码解析如下:
static void cull_queue(void) {
struct queue_entry* q;
static u8 temp_v[MAP_SIZE >> 3];
u32 i;
if (dumb_mode || !score_changed) return; // 如果处于dumb模式或者score没有发生变化(top_rated没有发生变化),直接返回
score_changed = 0;
memset(temp_v, 255, MAP_SIZE >> 3);
// 设置temp_v大小为MAP_SIZE>>3,初始化为0xff,全1,表示还没有被覆盖到,为0表示被覆盖到了。
queued_favored = 0;
pending_favored = 0;
q = queue;
while (q) { // 进行队列遍历
q->favored = 0; // 所有元素的favored均设置为0
q = q->next;
}
/* Let's see if anything in the bitmap isn't captured in temp_v.
If yes, and if it has a top_rated[] contender, let's use it. */
// i从0到MAP_SIZE进行迭代,筛选出一组队列条目,它们可以覆盖到所有现在已经覆盖的路径
for (i = 0; i < MAP_SIZE; i++)
if (top_rated[i] && (temp_v[i >> 3] & (1 << (i & 7)))) {
u32 j = MAP_SIZE >> 3;
/* Remove all bits belonging to the current entry from temp_v. */
// 从temp_v中,移除所有属于当前current-entry的byte,也就是这个testcase触发了多少path就给tempv标记上
while (j--)
if (top_rated[i]->trace_mini[j])
temp_v[j] &= ~top_rated[i]->trace_mini[j];
top_rated[i]->favored = 1;
queued_favored++;
if (!top_rated[i]->was_fuzzed) pending_favored++;
}
q = queue;
while (q) { // 遍历队列,不是favored的case(冗余的测试用例)被标记成redundant_edges
mark_as_redundant(q, !q->favored); // 位置在/queue/.state/redundent_edges中
q = q->next;
}
}
这里根据网上公开的一个例子来理解该过程:
现假设有如下tuple和seed信息:
tuple: t0, t1, t2, t3, t4
seed: s0, s1, s2
初始化
temp_v = [1,1,1,1,1]s1可覆盖t2, t3,s2覆盖t0, t1, t4,并且top_rated[0] = s2,top_rated[2]=s1
将按照如下过程进行筛选和判断:
首先判断 temp_v[0]=1,说明t0没有被覆盖;
top_rated[0] 存在 (s2) -> 判断s2可以覆盖的范围 ->
trace_mini = [1,1,0,0,1];更新
temp_v=[0,0,1,1,0], 标记s2为 "favored";继续判断 temp_v[1]=0,说明t1此时已经被覆盖,跳过;
继续判断 temp_v[2]=1,说明t2没有被覆盖;
top_rated[2] 存在 (s1) -> 判断s1可以覆盖的范围 ->
trace_mini=[0,0,1,1,0];更新
temp_v=[0,0,0,0,0],标记s1为 "favored";此时所有tuple都被覆盖,具备"favored'标记的为s1, s2,过程结束。
3.1.2 show_init_stats 函数
进入主循环前的准备工作使用的函数之一,主要作用为在处理输入目录的末尾显示统计信息,警告信息以及硬编码的常量;
3.1.3 find_start_position 函数
进入主循环前的准备工作使用的函数之一,主要作用为在resume时,尝试查找要开始的队列的位置。
3.1.4 write_stats_file 函数
也是准备工作函数之一,主要作用为更新统计信息文件以进行无人值守的监视。
3.1.5 save_auto 函数
该函数主要保存自动生成的extras。
3.2 主循环
这里是seed变异的主循环处理过程,我们将结合流程图和源码进行详细解读。
主循环的控制流程图如下(将while部分单独设置为了一个函数,只看循环部分即可):
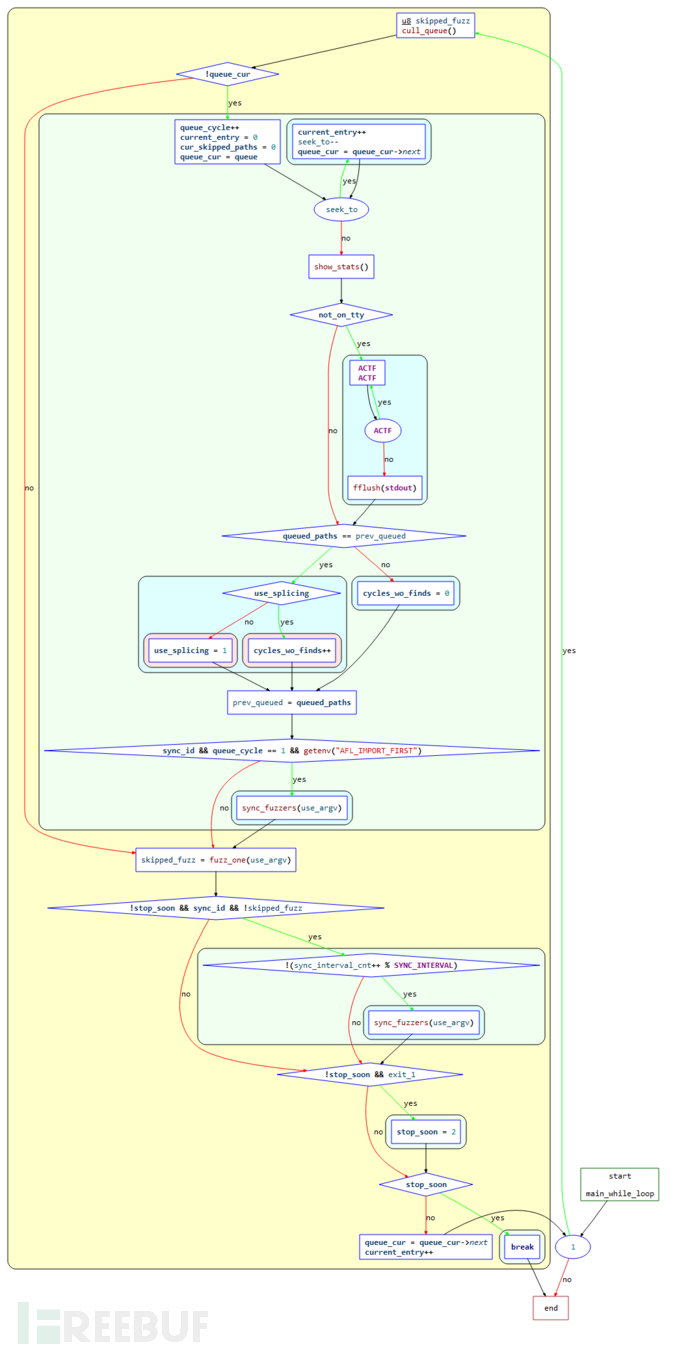
主循环源码:
while (1) { u8 skipped_fuzz; cull_queue(); // 调用cull_queue进行队列精简 if (!queue_cur) { // 如果queue_cure为空(所有queue都被执行完一轮) queue_cycle++; // 计数器,所有queue执行的轮数 current_entry = 0; cur_skipped_paths = 0; queue_cur = queue; // 准备开始新一轮fuzz while (seek_to) { // 如果seek_to不为空 current_entry++; seek_to--; queue_cur = queue_cur->next; // 从seek_to指定的queue项开始执行 } show_stats(); // 刷新展示界面 if (not_on_tty) { ACTF("Entering queue cycle %llu.", queue_cycle); fflush(stdout); } /* If we had a full queue cycle with no new finds, try recombination strategies next. */ if (queued_paths == prev_queued) { // 如果一轮执行后queue中的case数与执行前一样,表示没有发现新的case if (use_splicing) cycles_wo_finds++; else use_splicing = 1; // 是否使用splice进行case变异 } else cycles_wo_finds = 0; prev_queued = queued_paths; if (sync_id && queue_cycle == 1 && getenv("AFL_IMPORT_FIRST")) sync_fuzzers(use_argv); } skipped_fuzz = fuzz_one(use_argv); // 对queue_cur进行一次测试 if (!stop_soon && sync_id && !skipped_fuzz) { // 如果skipped_fuzz为0且存在sync_id,表示要进行一次sync if (!(sync_interval_cnt++ % SYNC_INTERVAL)) sync_fuzzers(use_argv); } if (!stop_soon && exit_1) stop_soon = 2; if (stop_soon) break; queue_cur = queue_cur->next; current_entry++;}
总结以上内容,该处该过程整体如下:
判断
queue_cur是否为空,如果是则表示已经完成队列遍历,初始化相关参数,重新开始一轮;找到queue入口的case,直接跳到该case;
如果一整个队列循环都没新发现,尝试重组策略;
调用关键函数
fuzz_one()对该case进行fuzz;上面的变异完成后,AFL会对文件队列的下一个进行变异处理。当队列中的全部文件都变异测试后,就完成了一个”cycle”,这个就是AFL状态栏右上角的”cycles done”。而正如cycle的意思所说,整个队列又会从第一个文件开始,再次进行变异,不过与第一次变异不同的是,这一次就不需要再进行“deterministic fuzzing”了。如果用户不停止AFL,seed文件将会一遍遍的变异下去。
3.3 主循环后
3.3.1 fuzz_one 函数
该函数源码在1000多行,出于篇幅原因,我们简要介绍函数的功能。但强烈建议通读该函数源码,
函数主要是从queue中取出entry进行fuzz,成功返回0,跳过或退出的话返回1。
整体过程:
根据是否有
pending_favored和queue_cur的情况,按照概率进行跳过;有pending_favored, 对于已经fuzz过的或者non-favored的有99%的概率跳过;无pending_favored,95%跳过fuzzed&non-favored,75%跳过not fuzzed&non-favored,不跳过favored;假如当前项有校准错误,并且校准错误次数小于3次,那么就用calibrate_case进行测试;
如果测试用例没有修剪过,那么调用函数trim_case对测试用例进行修剪;
修剪完毕之后,使用calculate_score对每个测试用例进行打分;
如果该queue已经完成deterministic阶段,则直接跳到havoc阶段;
deterministic阶段变异4个stage,变异过程中会多次调用函数common_fuzz_stuff函数,保存interesting 的种子:
bitflip,按位翻转,1变为0,0变为1
arithmetic,整数加/减算术运算
interest,把一些特殊内容替换到原文件中
dictionary,把自动生成或用户提供的token替换/插入到原文件中
havoc,中文意思是“大破坏”,此阶段会对原文件进行大量变异。
splice,中文意思是“绞接”,此阶段会将两个文件拼接起来得到一个新的文件。
该轮完成。
这里涉及到AFL中的变异策略,不在本次的讨论中,感兴趣的小伙伴可以结合源码自行进行研究。
3.3.2 sync_fuzzers 函数
该函数的主要作用是进行queue同步,先读取有哪些fuzzer文件夹,然后读取其他fuzzer文件夹下的queue文件夹中的测试用例,然后以此执行。如果在执行过程中,发现这些测试用例可以触发新路径,则将测试用例保存到自己的queue文件夹中,并将最后一个同步的测试用例的id写入到.synced/fuzzer文件夹名文件中,避免重复运行。
四、总结
分析完源码,可以感受到,AFL遵循的基本原则是简单有效,没有进行过多的复杂的优化,能够针对fuzz领域的痛点,对症下药,拒绝花里胡哨,给出切实可行的解决方案,在漏洞挖掘领域的意义的确非同凡响。后期的很多先进的fuzz工具基本沿用了AFL的思路,甚至目前为止已基本围绕AFL建立了“生态圈”,涉及到多个平台、多种漏洞挖掘对象,对于安全研究员来说实属利器,值得从事fuzz相关工作的研究员下足功夫去体会AFL的精髓所在。
考虑到篇幅限制,我们没有对AFL中的变异策略进行源码说明,实属遗憾。如果有机会,将新开文章详细介绍AFL的变异策略和源码分析。
五、参考文献
http://lcamtuf.coredump.cx/afl/
https://eternalsakura13.com/2020/08/23/afl/
https://bbs.pediy.com/thread-265936.htm
https://bbs.pediy.com/thread-249912.htm#msg_header_h3_3
如需授权、对文章有疑问或需删除稿件,请联系 FreeBuf 客服小蜜蜂(微信:freebee1024)






- 0 文章数
- 0 关注者