


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

- 关注
 本文由
创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
本文由
创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
为什么会提出GAN
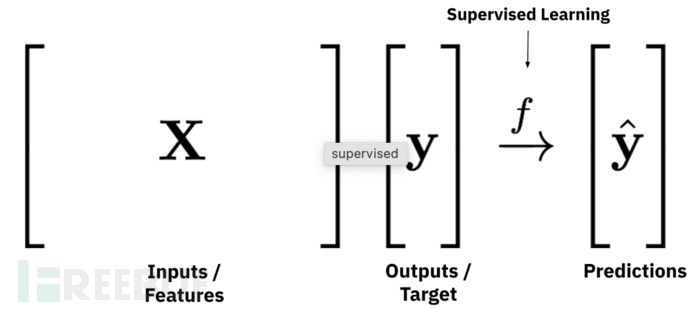
在监督式学习中,我们通常是给模型数据和对应的标签,让他分析输入,不断训练出能从数据推断出标签的能力,前面的文章中的模型都是如此,从恶意代码和垃圾邮件中推断出其对应的标签,当然强化学习RL是根据奖励机制来学习的,不是监督式的
那问题来了,如果我们想让模型凭空画出一副画或者创造一首曲子出来,用监督式来训练出的模型是不具备这样的能力的,监督式训练是训练模型找到数据对应的值或标签,是不具备想象力的,这里有没有像教小孩学习一样,只给一个标准答案,任何稍有偏差的答案直接否定掉
GAN的应用领域最开始在图像生成领域,每次的图像生成都不是一成不变的,极大体现出模型的想象力,但每次生成的图像虽然不同但都是合理或区域一个整体方向的,不会胡乱生成,这又是怎么做到的呢?
GAN主要由生成器和判别器组成,接下来以一个简单的例子来讲讲两者
让模型学着画出一条一元二次曲线,这个相较于其他而言,训练压力小点
怎么训练
先以一个通俗易懂的例子带入吧
需要知道的是什么在引导模型学习,他的老师是谁?在监督学习中预测值Y和标签值Y之间的差值就是老师,引导模型不断去减少这个差值
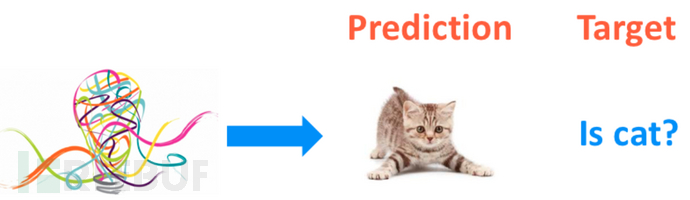
在GAN中,模型凭借着"想象力"生成了小猫的照片,那如何确定生成的就是小猫的照片呢?生成的效果好不好呢?像不像小猫呢?

以监督式学习的思想来看的话那还不简单,就拿真实小猫的图片Target,让模型去不断学习,减少自己生成图片Prediction和真实小猫Target的差距不就行了吗?

确实不无道理,但我们这里要的是想象力,生成的图片,不同想象力可能生成不同的照片,如果只拿一个最终生冷的答案就否决了他的想象力了,那岂不是扼杀了这种想象力, 显然用监督学习的方法在这里的确是有问题的
那换个思路,我们把用Target来考核模型换成判断生成的图片是否像一只猫,这不就既让图片生成的是猫,并且充分发挥了其想象力
物以类聚,以此类推,这样的思想在安全领域,就可以用到生成恶意代码或者恶意攻击流量,使其以不同的形式进行攻击
那我们就可以设计一个模型,它的任务就是来判断这只想象出来的猫是不是长得像真猫,要让模型具备这样的能力,我们在训练的时候,不但有自己生成的小猫图片,还有真实的小猫图片,让模型学会如何去区分这两者,哈哈,我们的目的就此达到
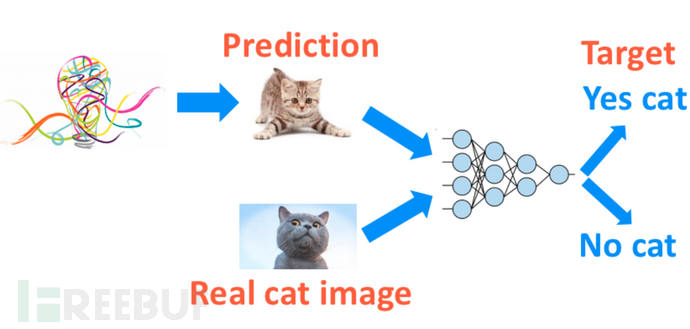
上面所述的模型其实就是最开始所说的判别器
到这里了,有人可能要问了,这样下来,你最多得到一个非常厉害的辨别模型,我们这里是想要一个生成猫猫的模型,那怎么将这种厉害的辨别能力转接到生成模型那里呢,那就是让辨别模型反过来指导生成模型学习
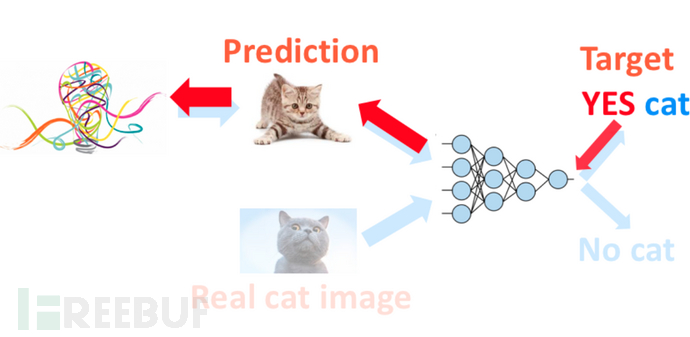
上图如果转化成白话,意思就是,判决模型拿着对真猫的理解,和生成模型说:你看,你要照着我对真猫的想法来,修改一下这里这里,你就能画出更像真猫的想象猫了。 也就是告诉生成模型,怎么画可以画出我觉得想真猫的猫
上面生动的解释是不是一下就明白GAN的核心思想了,在网上摸索了几天,介绍的都很官方,几乎就是照搬Ian Goodfellow大神论文中的原话,没有用自己的想法来解释,这篇生动的解释是借鉴了莫烦师傅的文章https://mofanpy.com/tutorials/machine-learning/gan/gan
这里还有个更有趣的解释:
生成器:学习真实样本以假乱真
判别器:小孩通过学习成验钞机的水平
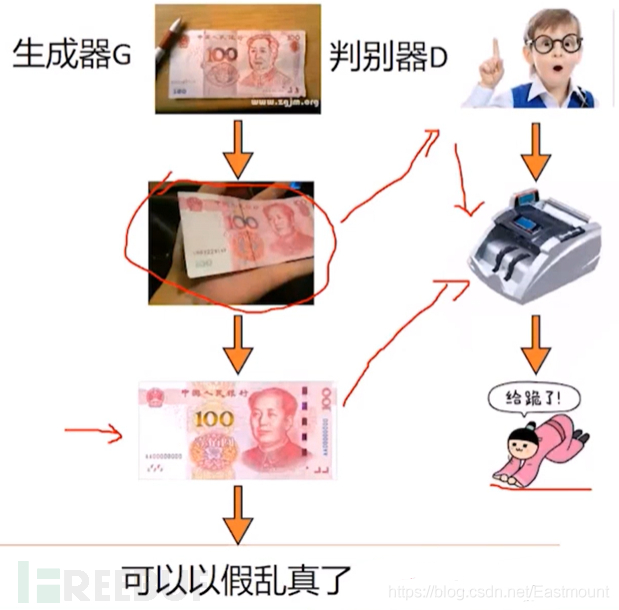
我们还是以更专业的角度来解释一下,生成器和判别器之间的较量可以可视化出下图
图中的黑色虚线表示真实的样本的分布情况,蓝色虚线表示判别器判别概率的分布情况,绿色实线表示生成样本的分布。 Z 表示噪声, Z 到 x 表示通过生成器之后的分布的映射情况
我们的目标是使用生成样本分布(绿色实线)去拟合真实的样本分布(黑色虚线),来达到生成以假乱真样本的目的
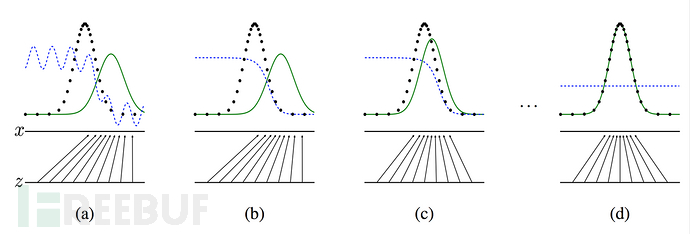
(a) 初始阶段
黑色色曲线(真实数据分布)和绿色色点线(生成数据分布)差异很大,说明生成器生成的假数据和真实数据分布差距较大
蓝色虚线(判别器的判别概率)在真实数据分布高的区域接近1,在生成数据分布高的区域接近0,说明判别器很容易区分真假数据
底部的箭头表示梯度方向,生成器会根据判别器的反馈调整生成分布,试图“欺骗”判别器
(b) 训练中期
绿色点线(生成分布)开始向黑色曲线(真实分布)靠近,说明生成器在学习真实数据的分布
蓝色虚线(判别概率)变得更平缓,说明判别器开始难以区分真假数据,判别概率在真假数据重叠区域接近0.5
(c) 接近收敛
黑色点线和绿色曲线进一步靠近,生成分布和真实分布的重叠更多
蓝色虚线更加平坦,接近0.5,说明判别器几乎无法区分真假数据(理想情况下,判别器在收敛时对所有数据输出0.5,因为真假数据分布一致)
(d) 收敛状态
黑色点线和绿色曲线几乎完全重合,生成分布接近真实分布
蓝色虚线几乎是一条水平线,接近0.5,说明判别器完全无法区分真假数据,GAN训练达到平衡
目标函数
判别器的目标函数
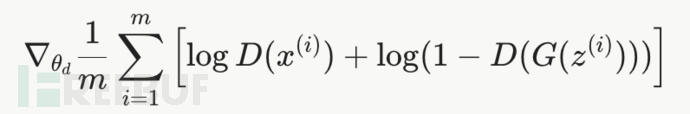
这是判别器 D的梯度,用于更新判别器的参数
其中x表示真实图片,z表示输入G网络的噪声,G是生成器,D是判别器
logD(x^i): 判别器希望对真实样本x^i输出接近1的概率,最大化这一项
Log(1-D(G(z^i))): 在这个式子中G(z^i)代表生成器生成的样本,判别器希望对这个生成样本的输出接近0的概率,这样整个Log(1-D(G(z^i)))就更大
梯度 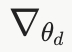 用于通过梯度上升更新D的参数
用于通过梯度上升更新D的参数
要强调的是,因为判别器是希望整个式子的值随着训练越来越大,所以这里使用的是梯度上升(注意不是梯度下降)
生成器的目标函数
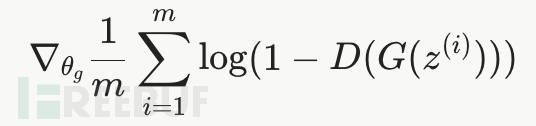
这是生成器 G 的梯度,用于更新生成器的参数
生成器的目的是最小化这个值,也就是让D(G(z^i))更接近于1,即生成的样本被判别器认为是真实的,那么整个值就会更小
因为生成器的目的是最小化这个值,所以训练时使用的是梯度下降
还要说明的就是,这里的概率0~1,是指给判别器一张图片,它判断这张图片为真的概率越接近1,代表越真实
生成过程
这个过程给出一张图就十分明了了
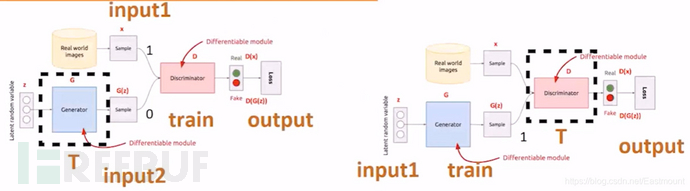
第一步(左图):希望判决器尽可能地分开真实数据和我生成的数据。那么,怎么实现呢?我的真实数据就是input1(Real World images),我生成的数据是input2(Generator)。input1的正常输出是1,input2的正常输出是0,对于一个判决器(Discriminator)而言,我希望它判决好,首先把生成器固定住(虚线T),然后生成一批样本和真实数据混合给判决器去判断
第二步(右图):固定住判决器(虚线T),我想办法去混淆它,刚才经过训练的判决器很厉害,此时我们想办法调整生成器,从而混淆判别器,即通过固定判决器并调整生成器,使得最后的输出output让生成的数据也输出1(第一步为0)
实战之生成手写数字集
先给个简单的demo吧
老规矩先上代码
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
import matplotlib.pyplot as plt
import numpy as np
import glob
import os
# 设置TensorFlow日志级别,减少不必要的警告信息
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
(train_images, train_labels), (_, _) = tf.keras.datasets.mnist.load_data()
# 重塑并归一化数据到[-1, 1],以匹配生成器的tanh输出
train_images = train_images.reshape(train_images.shape[0], 28, 28, 1).astype('float32')
train_images = (train_images - 127.5) / 127.5
# 批大小和缓冲区大小
BATCH_SIZE = 256
BUFFER_SIZE = 60000
datasets = tf.data.Dataset.from_tensor_slices(train_images)
datasets = datasets.shuffle(BUFFER_SIZE).batch(BATCH_SIZE)
# 生成器模型
def generator_model():
model = tf.keras.Sequential()
model.add(layers.Dense(256, input_shape=(100,), use_bias=False))
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
model.add(layers.Dense(512, use_bias=False))
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
model.add(layers.Dense(28 * 28 * 1, use_bias=False, activation='tanh'))
model.add(layers.Reshape((28, 28, 1)))
return model
# 判别器
def discriminator_model():
model = tf.keras.Sequential()
# 输入形状为(28, 28, 1),展平
model.add(layers.Flatten(input_shape=(28, 28, 1)))
model.add(layers.Dense(512, use_bias=False))
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
model.add(layers.Dense(256, use_bias=False))
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
# 输出层:使用sigmoid激活,输出概率值
model.add(layers.Dense(1, activation='sigmoid'))
return model
# 定义损失函数
cross_entropy = tf.keras.losses.BinaryCrossentropy(from_logits=False)
# 判别器损失函数
def discriminator_loss(real_out, fake_out):
real_loss = cross_entropy(tf.ones_like(real_out), real_out) # 真实图像标签为1
fake_loss = cross_entropy(tf.zeros_like(fake_out), fake_out) # 生成图像标签为0
return real_loss + fake_loss
# 生成器损失函数
def generator_loss(fake_out):
return cross_entropy(tf.ones_like(fake_out), fake_out) # 希望生成图像被判为1
# 定义优化器
generator_opt = tf.keras.optimizers.legacy.Adam(1e-4)
discriminator_opt = tf.keras.optimizers.legacy.Adam(1e-4)
# 训练参数
EPOCHS = 200
noise_dim = 100
num_exp_to_generate = 16
seed = tf.random.normal([num_exp_to_generate, noise_dim])
# 实例化模型
generator = generator_model()
discriminator = discriminator_model()
# 反向传播函数
@tf.function # @tf.function是TensorFlow中的一个装饰器(Decorator它可以把普通的Python函数转换成高性能的TensorFlow计算图(Graph)
def train_step(images):
noise = tf.random.normal([BATCH_SIZE, noise_dim])
with tf.GradientTape() as gen_tape, tf.GradientTape() as disc_tape:
# 判别器判断真实图像
real_out = discriminator(images, training=True)
# 生成器生成图像
gen_image = generator(noise, training=True)
# 判别器判断生成图像
fake_out = discriminator(gen_image, training=True)
gen_loss = generator_loss(fake_out)# 生成器损失
disc_loss = discriminator_loss(real_out, fake_out)# 判别器损失
# 计算梯度
gradient_gen = gen_tape.gradient(gen_loss, generator.trainable_variables)
gradien如需授权、对文章有疑问或需删除稿件,请联系 FreeBuf 客服小蜜蜂(微信:freebee1024)
- 0 文章数
- 0 关注者