


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

- 关注
 本文由
创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
本文由
创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
注意力机制
注意力机制是人类利用有限的注意力资源从大量信息中快速筛选出高价值信息的手段,是人类在长期进化中形成的一种生存机制,人类视觉注意力机制极大地提高了视觉信息处理的效率与准确性,那换到模型上也是这样:
其核心就是让模型能动态关注输入的重要部分,以一张图解释
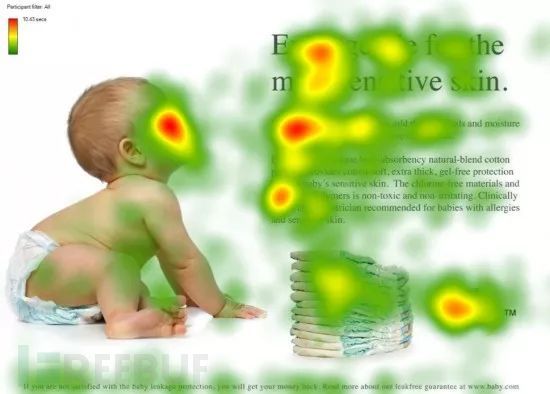
在上图中,热力图颜色越深的地方代表该区域受到更高的关注,这张图是我从一位师傅那里取来的,在做类似快速阅读之内的吧,可以看到,在处理这个页面时,在图片上模型更加关注的是小孩的面部区域,在文本上模型更加关注的是标题,按照我们自己的认知来说,确实是观察这些地方
Query (Q),Key (K )和Value (V )
注意力机制的实现就是靠**Query (**Q **),Key (**K **)和Value (**V ),分别是查询矩阵,键矩阵,值矩阵
引用一个师傅的举例就明白了:
可以这样理解, V 是我们手头已经有的所有资料,可以作为一个知识库; Q 是我们待查询的东西,我们希望把 V 中和 Q 有关的信息都找出来;而 K 是 V 这个知识库的钥匙 ,V中每个位置的信息对应于一个 K 。对于 V 中的每个位置的信息而言,如果 Q 和对应钥匙 的匹配程度越高,那么就可以从该条信息中找到和 Q 更多的内容
Self-Attention自注意力机制
先给出数学公式,不复杂

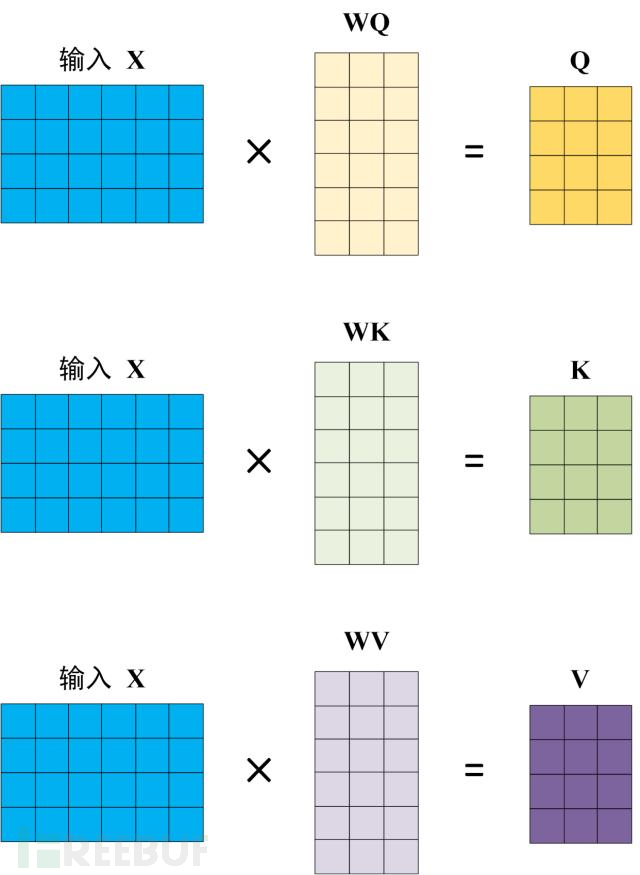
这里的Q,K,V是怎么得来的呢?输入矩阵X分别乘以线性变换矩阵W_Q,W_K,W_v得到Q,K,V,如下图:
得到Q,K,V后就可以计算出Self-Attention的输出
注意Q,K做点积后除以了根号下d_k,这个做法有点类似于正则化,目的是为了避免做完点积后的值过大,会导致在进行softmax后,输出值直接会为0或1,后续根本无法学习
例如,假设 QKT, QK^T ,QKT 的值是 [100, 101, 102],那么:
e100≈2.7×1043 e^{100} \approx 2.7 \times 10^{43} e100≈2.7×1043
e101≈7.4×1043 e^{101} \approx 7.4 \times 10^{43} e101≈7.4×1043
e102≈2.0×1044 e^{102} \approx 2.0 \times 10^{44} e102≈2.0×1044
Softmax 输出接近 [0, 0, 1],梯度几乎为 0,模型难以学习
softmax在模型中的作用是将点积化后的值进行归一化,是这些值是一个离散的概率分别,相加之和=1
Multi-Head Attention多头注意力机制
这里有两种处理方法,第一种是将输入X切割成多个部分,仍进行上述操作,最后将这些部分进行拼接即可
第二种是直接复制多个输入X,进行上述操作,不同的是不同X对应的W_Q,W_K,W_V这三个矩阵的值不同,最后拼接起来,再经过线性变换得到最终的值
第一种(分割)
这里我问了Grok,解释得相当不错

这样做可以从多个视角进行注意力观察
第二种
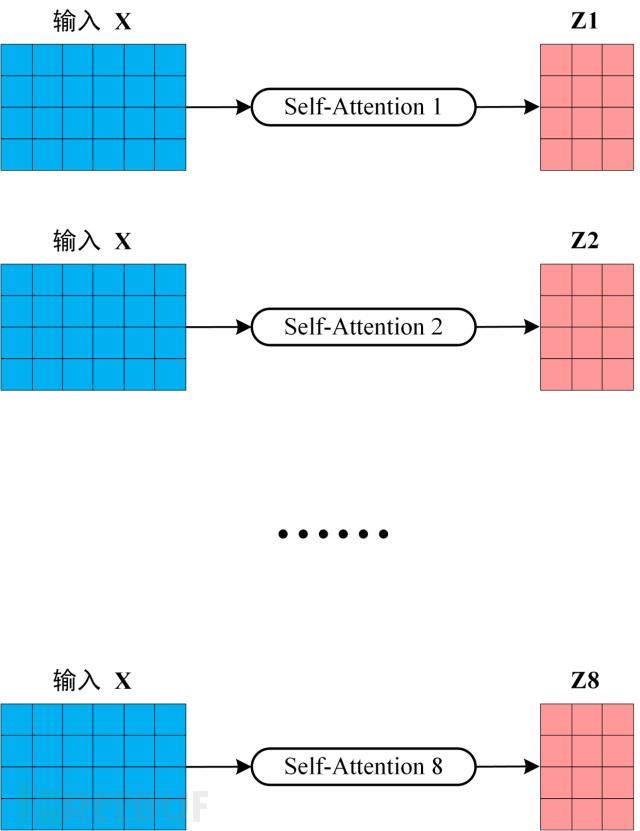
首先将输入X分别传递到 h 个不同的 Self-Attention 中,计算得到 h 个输出矩阵Z。下图是 h=8 时候的情况,此时会得到 8 个输出矩阵Z
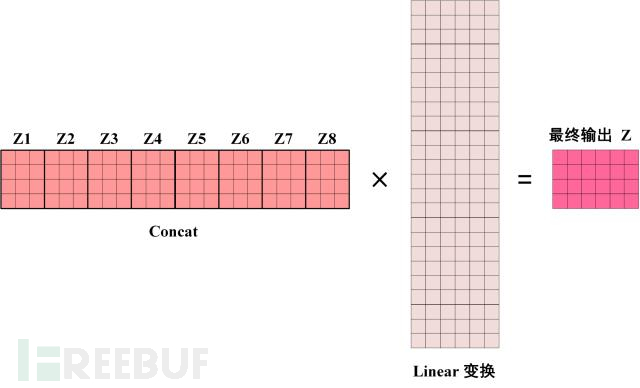
得到 8 个输出矩阵 Z1 到 Z8 之后,Multi-Head Attention 将它们拼接在一起 (Concat),然后传入一个Linear层,得到 Multi-Head Attention 最终的输出Z
优点:这种方法相较于第一种而言,效果更好,每个注意力头都是基于完整的输入进行计算的,可以保留更多全局信息
缺点:这种方法参数量大计算复杂度度高
掩码机制
介绍Transformer中的掩码机制,主要包括三部分:
encoder的self attention的长度mask
decoder的self attention的causal mask
encoder和decoder的cross-attention的mask
encoder的self attention的长度mask
编码器的自注意力掩码,当处理数据时,输入的长度可能是不一样的,我们当时的处理是将同一个batch中的所有样本都padding到最长长度,这样可以解决输入变长的问题,怎么实现呢?这里就要用到掩码了

这里存在数据的位置为白色(填充0),不存在的为灰色(填充1)
这里讲一下,我们在进行实现的时候,是采用b图这样的方法,而不是采用a图,为什么呢?
在实际模型训练过程中使用(b)而不使用(a),使用 (b) 不会出错是因为 Q 为padding的部分最终计算loss时会被过滤掉(torch.nn.functional.cross_entropy的ignore_idx参数设成<ignore>将这部分的loss去掉,不纳入计算),所以 Q 是否mask无影响。而使用(a)时,由于有些行的所有位置都被mask掉了,这部分计算attention时容易出现NaN
为什么会出现 NaN?
当某一行全被屏蔽(全为 −10^9),Softmax 的分母接近 0,导致数值不稳定。
在浮点运算中,这种情况可能触发 NaN,导致后续计算也变成 NaN。
NaN 会传播到损失计算,即使有 ignore_idx,梯度已经受损,训练可能崩溃
得到mask之后,我们应该怎么用才能将padding部分的attention权重置为0呢?做法是直接将 Q 和 K 的内积计算结果中被mask掉的部分的值置为-inf,这样的话,过一层softmax之后,padding部分的attention权重就是0了
decoder的self attention的causal mask
解码器的自注意力因果掩码,在解码器种,自注意力需要确保当前时间步只关注之前的输出
为什么需要?
解码器在训练时是并行处理的,输入是整个目标序列(例如翻译的目标句子)
如果不屏蔽未来信息,模型会“作弊”,提前看到后续的词,导致训练和推理行为不一致
实现方式也是很简单,掩码就是个倒三角形状
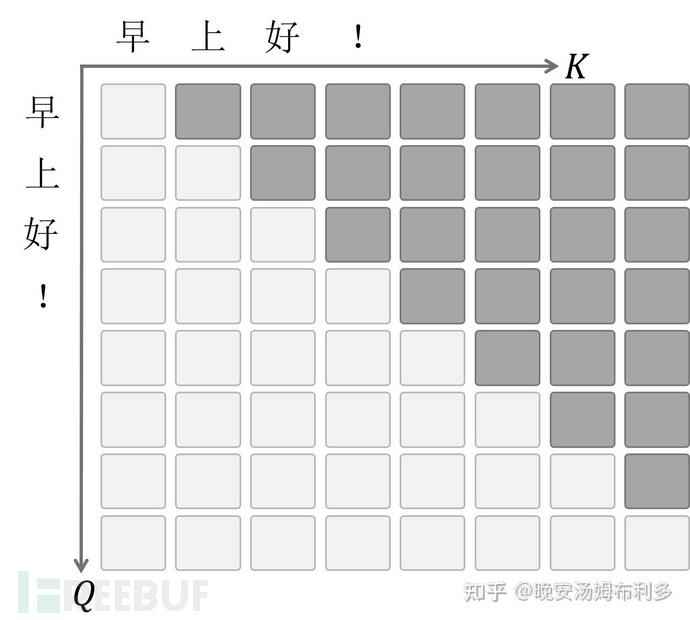
encoder和decoder的cross-attention的mask
编码器和解码器的交叉注意力的掩码,这个很容易与编码器的自注意力掩码混淆,其他都是一样的,区别在于对象不同
编码器掩码用于自注意力,屏蔽的是输入序列内部的无效部分
交叉注意力掩码用于解码器,屏蔽的是编码器输出对解码器生成的影响
交叉注意力掩码出现在 Transformer 的解码器中,具体用于编码器-解码器之间的交叉注意力(Cross-Attention)层。这里的“交叉”指的是解码器的查询(Query)与编码器的键(Key)和值(Value)进行注意力计算。掩码的作用是屏蔽编码器输出序列中的填充位置(padding),确保解码器只关注编码器的有效信息
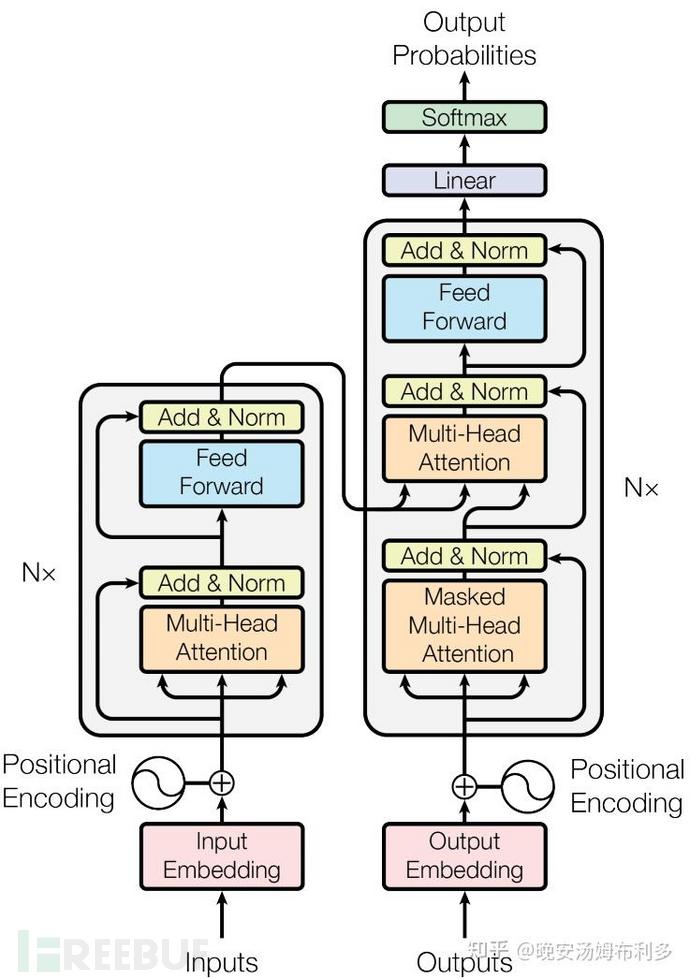
这里要解释一下,什么事交叉注意力,先提前看看encoder和decoder的原理图吧
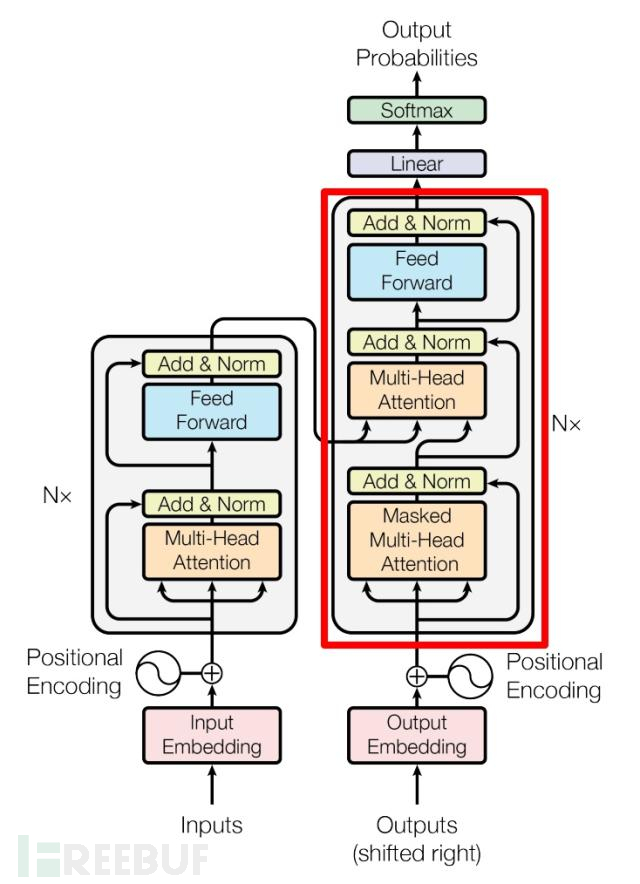
这里红框中从上到下第二个即为交叉注意力,第二个 Multi-Head Attention 层的K, V矩阵使用 Encoder 的编码信息进行计算,而Q使用上一个 Decoder模块的输出计算
输入编码
Transformer的输入是由词编码和位置编码相加而来的
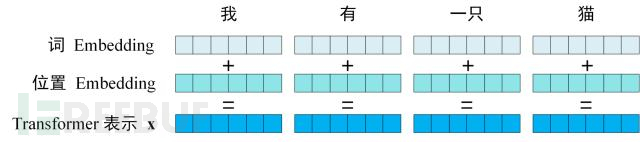
还记得学LSTM时用到了Word2Vec模型来训练词的Embedding,有意思的是Transformer不仅要有词Embedding,还要有位置Embedding,为什么呢?
LSTM的输入是有顺序的,所以默认就有位置信息,而Transformer是利用全局信息,不能知晓单词在句子中的顺序,所以 Transformer 中使用位置 Embedding 保存单词在序列中的相对或绝对位置
位置Embedding用PE表示,Positional Encoding(位置编码),训练公式如下
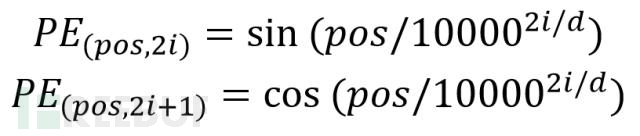
第一个对应偶数维度 ,第二个对应奇数维度
这样光秃秃的给个公式可能不够直观,就拿上面的"今天天气"来举例

随着i的增大,1/10000^(i/4)的分母越来越大,值越来越小,波长越短,pos变化同样的大小,得到的值变化的幅度(差异)更大,就更精细
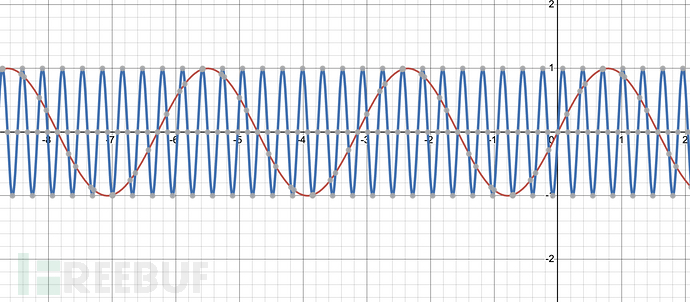
上图蓝色的sin曲线的波长更短,红色的sin曲线的波长更长
在学这里的时候一直没明白为什么波长越短就越精细,我最开始想的,波长越短,那我x同样增加1,值大小变化是很大的,怎么就精细了
带着这个问题,问了一下Grok,他是这样解答的
“变化更精细”的真正含义
误解:你可能认为“变化更精细”是指 pos 变化同样距离时,sin 或 cos的值变化更大。但实际上,“精细”指的是分辨能力更高,即高维度的 PE 能在更小的 pos 范围内产生更多的变化模式,从而区分更细微的位置差异。
Feed-Forward前馈神经网络
为了增强模型的表示能力,引入了前馈神经网络,其实就是两层全连接层
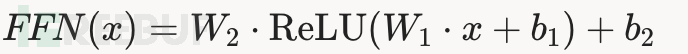
Add & Norm
贴一张图,便于理解后面的解释
在上面整个模型的图中我们看到Add & Norm,这两个又是啥
分别是残差链接,层归一化
是 Transformer 架构中每个子层(如多头自注意力层和前馈神经网络层)的重要组成部分,确保模型训练稳定并加速收敛
Add残差链接: y = x + F(x)
x 是子层的输入
F(x) 是子层的输出(如多头自注意力或前馈网络的结果)
y 是最终输出,进入下一步
有人要问了,加个输出加上输入有什么好处
缓解梯度消失:通过直接传递输入 x,即使F(x)的梯度很小,反向传播时仍能通过 x传播梯度。
保留原始信息:在翻译“今天天气很好”时,残差连接确保词嵌入和位置编码的信息不会因深层变换而丢失,直接传递给后续层。
Norm层归一化:就是在残差处理过后进行标准化
目的就是使训练的时候更稳定
编码器和解码器
前面讲了那么多,都是在介绍构成编码器和解码器的模块(输入层 , Mutl-Head Attention , Add&Norm , Feed-Forward , Mask掩码 )
编码器(Encoder)
即上图的左半边,编码器的组成:
多头自注意力机制(Multi-Head Self-Attention)
允许模型关注输入序列中不同位置的词,捕捉词与词之间的关系
“多头”意味着并行计算多个注意力机制,增强模型的表达能力
前馈神经网络(Feed-Forward Neural Network, FFN)
对每个位置的表示进行独立的全连接变换,增加非线性
此外,每一层还有残差连接(Residual Connection)和层归一化(Layer Normalization),以稳定训练并提高性能
解码器(Decoder)
即上图的右半边,解码器含三个主要子模块:
掩码多头自注意力机制(Masked Multi-Head Self-Attention)
与编码器的自注意力不同,这里加入了“掩码”,确保模型在生成当前词时只能看到之前的词,防止“偷看”未来的信息
多头交叉注意力机制(Multi-Head Cross-Attention)
将解码器的中间表示与编码器的输出进行注意力计算,捕捉源序列与目标序列之间的关系
前馈神经网络(Feed-Forward Neural Network, FFN)
与编码器类似,对每个位置进行独立变换。
和编码器一样,解码器每层也有残差连接和层归一化。最终,解码器通过一个线性层和 softmax 函数,将输出转换为目标词汇表的概率分布,逐步生成目标序列
编码器和解码器相辅相成
Transformer模型又编码器和解码器构成,我们想想Transformer是干啥的,最多的应用就是翻译,怎么使Transformer具有翻译能力呢?首先就是要先训练它具备翻译能力,之后才可以进行推理预测(这里也就是翻译)
那我们就从训练和预测来看看编码器和解码器怎么工作,各自的作用是什么吧!
训练阶段
在训练时,数据是由对应的标签的(比如“今天天气很好” → “Today the weather is nice”),通过监督学习优化模型参数,解码器和编码器是在训练过程中学会数据和标签之间的映射,比如在翻译过程中中文句子中的字和英文句子的单词之间的关系
先来看看这时编码器在干什么吧
输入:
源语言序列,比如“今天天气很好”,进行词嵌入和位置编码,形成输入向量
处理:
- 多头注意力机制----对整个序列进行注意力计算,捕捉词之间的关系
- Add & Norm----使用残差和归一化,使输出更加稳定
- 前馈神经网络----再对输出应用两层全连接,加强表示
输出:
输出的向量中能很好的表示整个句子的全局信息
我理解的就是:编码器将中文句子转化为机器可用的表示,捕捉词序、语法和语义,为解码器提供翻译基础
接下来看看解码器
输入:
"
<start>Today the weather is nice<end>",进行词嵌入和位置编码,形成输入向量
处理:
掩码多头注意力(Masked Multi-Head Attention),通过掩码实现只关注当前词之前的词,比如预测is时,只能看到Today the weather
Add & Norm:残差连接和层归一化
多头交叉注意力(Multi-Head Cross-Attention):将当前英文表示与编码器的输出对齐,比如生成"wether"时,只关注"天气"
前馈网络(FFN):增强表示。
输出层:通过线性层和 softmax,预测下一个词的概率分布
这里我理解的就是利用编码器对中文的理解输出和已知目标序列,学习中英词语之间的映射关系
训练和预测时是一致的,只是说在预测时,解码器的输入只有<start>
看到一个师傅自己画的一幅图,十分生动形象,他的描述是:编码器和解码器像一个你画我猜,而我们使用大量带标签数据去训练时便是在培养它们俩之间的"默契"
Transformer和LLM大模型的关系
比如说,我最早知晓的大模型GPT 系列模型,他的一个显著特点是它确实只使用了 Transformer 的解码器部分(Decoder-only )
为什么只用解码器,不用编码器呢?
ChatGPT 的目标是生成文本(如对话、回答问题),而不是翻译或序列转换。它不需要单独的输入序列(源语言)和输出序列(目标语言),因此不需要编码器
解码器足以处理自回归生成任务,预测下一个词
其他的模型呢?
通过一张表来看看吧
| 模型 | 架构 | 参数规模 | 特点 | 开源 |
|---|---|---|---|---|
| BERT(Google) | Encoder-only | 3.4 亿 | 双向理解 | 是 |
| GPT-3/4 | Decoder-only | 1750 亿+ | 生成能力强 | 否 |
| LLaMA(Meta) | Decoder-only | 70-650 亿 | 高效研究模型 | 是 |
| Grok(X) | Decoder-only | 未公开 | 真实性+对话 | 否 |
| Mistral | Decoder-only | 70 亿+ | 轻量高效 | 是 |
| T5(Google) | Encoder-Decoder | 110 亿 | 任务统一 | 是 |
| Gemini(Google) | 未全公开 | 未公开 | 多模态 | 否 |
| Claude(Anthropic) | Decoder-only | 未公开 | 安全透明 | 否 |
| Ernie(百度) | 早期Encoder-Decoder,后期Decoder-only | 10 万亿? | 中文优化 | 否 |
| DeepSeek | Decoder-only | 6710 亿 | 高性价比 | 是 |
总结:对Transformer有了大致的了解(肯定有理解错的地方),这次没有贴上代码实现过程还有Transformer的实际应用,还在想Transformer除了语言翻译,可不可以应用到web安全当中来,总之,溯洄从之————
已在FreeBuf发表 0 篇文章
如需授权、对文章有疑问或需删除稿件,请联系 FreeBuf 客服小蜜蜂(微信:freebee1024)
- 0 文章数
- 0 关注者