


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

- 关注
 本文由
创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
本文由
创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
萌新见解,文笔微末,大佬见谅!
前置知识
在CTF(Capture The Flag)比赛中,Reverse Engineering(逆向工程)是一种常见的挑战类型。它主要考察选手分析和理解程序运行机制的能力,要求选手通过对提供的二进制文件或脚本代码的逆向分析,找到特定的答案(通常是一个字符串、flag或漏洞利用方式)。
1. 任务类型
密码破解: 分析程序如何验证密码,找到正确的密码输入。
加密算法还原: 还原文件中的自定义加密逻辑,破解加密内容。
程序逻辑分析: 理解程序执行流程,发现隐藏的信息。
代码修补(Patch): 修补或修改程序以跳过验证、解锁某些功能。
虚拟机和字节码分析: 逆向基于自定义虚拟机(VM)的代码,理解指令集和逻辑。
恶意代码分析: 逆向分析恶意程序,提取其中的隐藏内容或行为。
2. 工具
IDA Pro:用于反编译和分析二进制文件
AndroidKiller:反编译 Android APK。
3. 典型例题
简单密码验证: 程序要求输入特定密码,使用静态分析找到硬编码密码。
自定义加密解密: 文件中存在自定义加密逻辑,逆向程序找到加密算法并解密。
动态库 Hook: 通过拦截动态库函数的调用提取关键数据。
自定义虚拟机分析: 逆向分析虚拟机指令集和执行逻辑。
恶意代码逆向: 解析恶意文件的行为,提取其隐藏功能或敏感信息。
4. 学习路径
学习汇编语言(x86/x64)和 C/C++ 基础。(这里我是用python写的)
熟悉常见文件格式(ELF、PE、Mach-O 等)。
学会使用静态和动态分析工具。
参与 CTF 比赛,逐步积累经验。
解题
easyre
看到exe文件,首先查壳: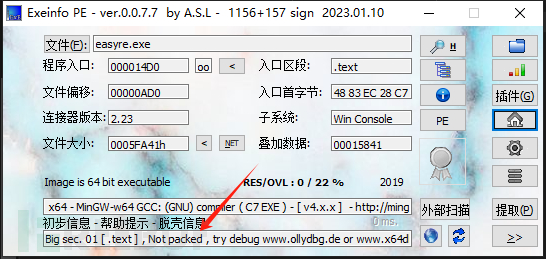
未加壳,丢入IDA查看main: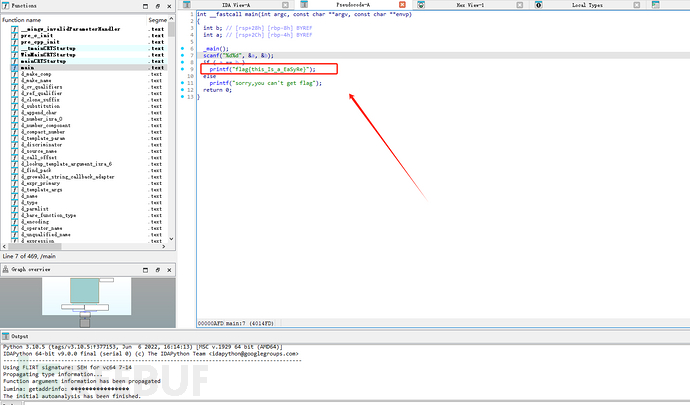
获得flag。
reverse1
同上,先查壳: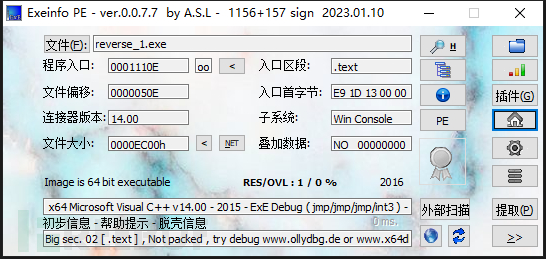
未加壳,丢入IDA查看main: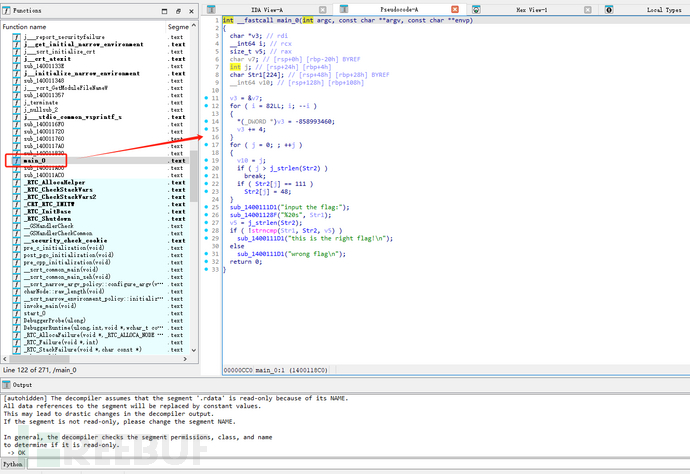
分析:
这段伪代码的功能可以拆解如下:
**初始化内存:**将从地址 &v7 开始的区域初始化为特定值(-858993460,等价于 0xCCCCCCCC,通常是未初始化内存的默认值)。
v3 = &v7;
for (i = 82LL; i; --i) {
*(_DWORD *)v3 = -858993460;
v3 += 4;
}
**替换字符串 Str2 中的字符:**Str2 中所有的 'o' 都会被替换为 '0'
for ( j = 0; ; ++j )
{
v10 = j;
if ( j > j_strlen(Str2) )
break;
if ( Str2[j] == 111 )
Str2[j] = 48;
}
ASCII 值 111(对应字母 'o'), ASCII 值 48(对应数字 '0')
寻找str2值:直接双击Str2,定位对应位置。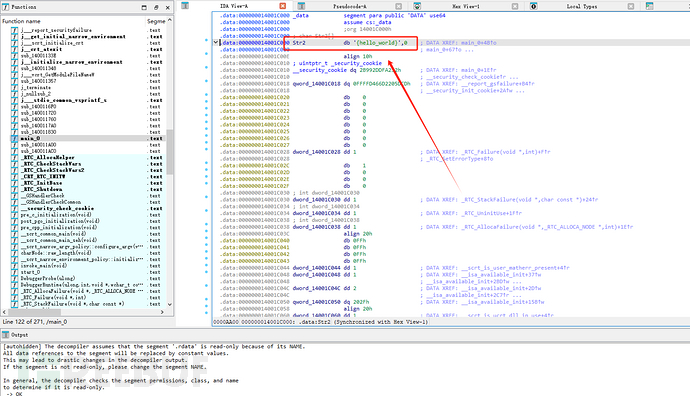
结论:根据上边,所有o换为0,得到flag:flag{hell0_w0rld}
reverse2
没有后缀,直接丢IDA,查看main: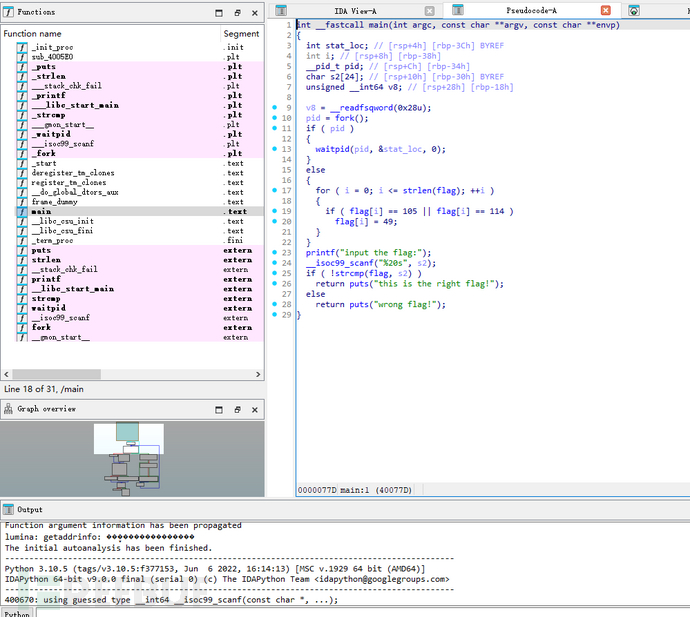
分析
pid = fork();
if ( pid )
{
waitpid(pid, &stat_loc, 0);
}
else
{
......
}
fork() 用于创建一个新进程,当前进程(父进程)和新创建的进程(子进程)分别执行不同的代码路径。父进程:调用 waitpid() 等待子进程结束。子进程:修改 flag 字符串。
{
for ( i = 0; i <= strlen(flag); ++i )
{
if ( flag[i] == 105 || flag[i] == 114 )
flag[i] = 49;
}
}
遍历 flag 字符串的每个字符:如果字符是 'i'(ASCII 105)或 'r'(ASCII 114),将其替换为 '1'(ASCII 49)。然后将修改后的flag保存在子进程中。
根据代码,关键点在与flag的原始值,寻找flag原始值: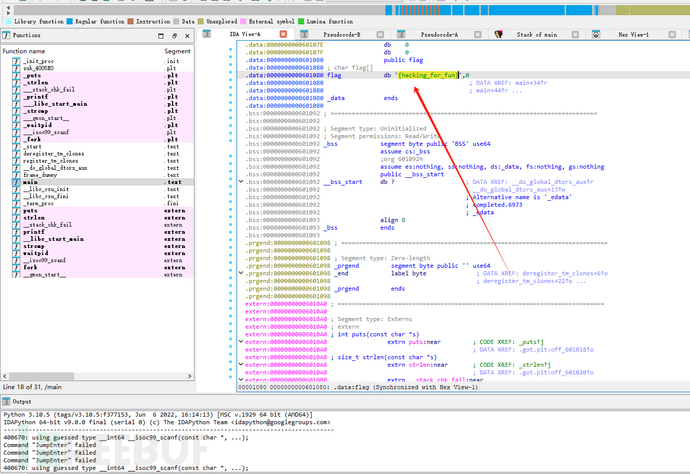
然后替换得到flag:flag{hack1ng_fo1_fun}
内涵的软件
exe先查壳:
无壳,丢入IDA查看main: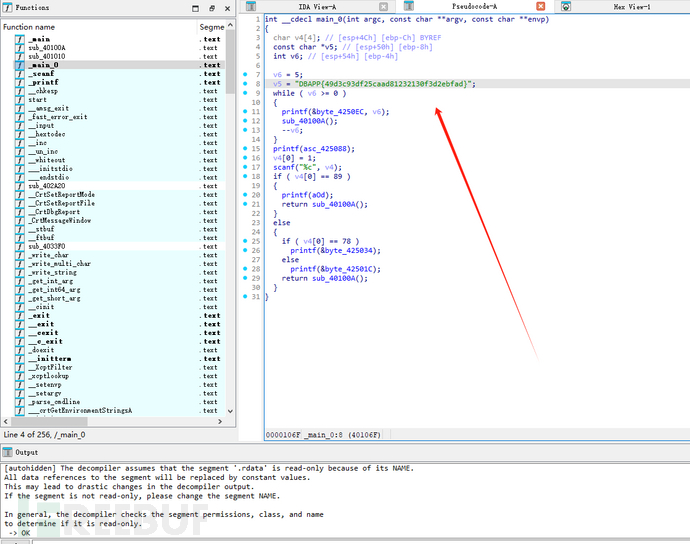
这没啥好说的,直接提交:flag{49d3c93df25caad81232130f3d2ebfad}
新年快乐
exe,先查壳: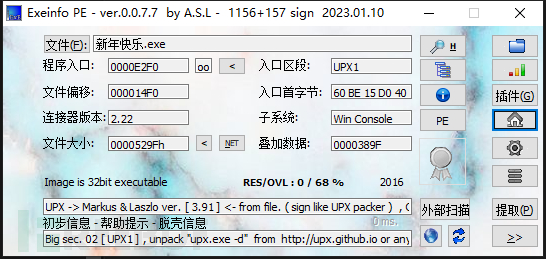
有uxp壳,upx.exe -d解壳: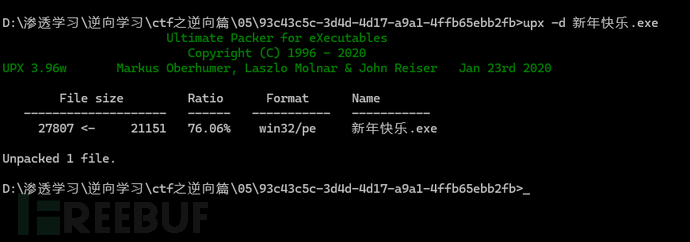
丢入IDA: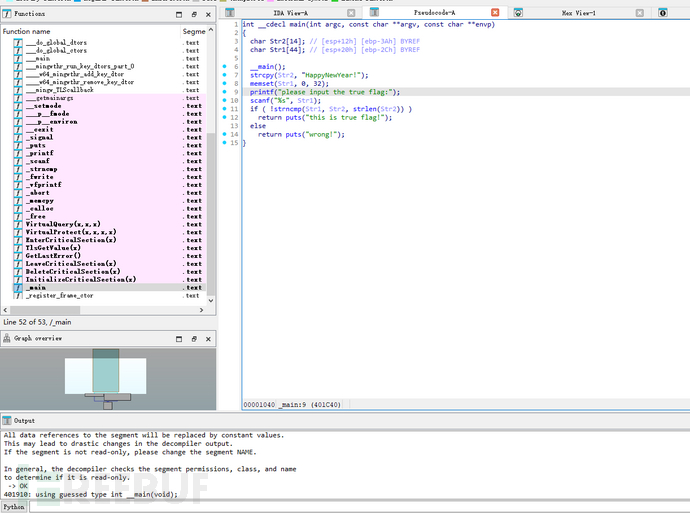
分析
char Str2[14]; // 用于存储正确的 flag
char Str1[44]; // 用于存储用户输入的 flag
逻辑初始化:
__main();
strcpy(Str2, "HappyNewYear!");
memset(Str1, 0, 32);
strcpy(Str2, "HappyNewYear!"):将字符串 "HappyNewYear!" 拷贝到 Str2 中,作为正确的 flag。
memset(Str1, 0, 32):将 Str1 的前 32 个字节初始化为 0,以确保没有残留数据。
根据if判断,比较 Str1 和 Str2 的前 strlen(Str2) 个字符,匹配即可得到flag。
所以正确flag为:flag{HappyNewYear!}
xor
丢入IDA: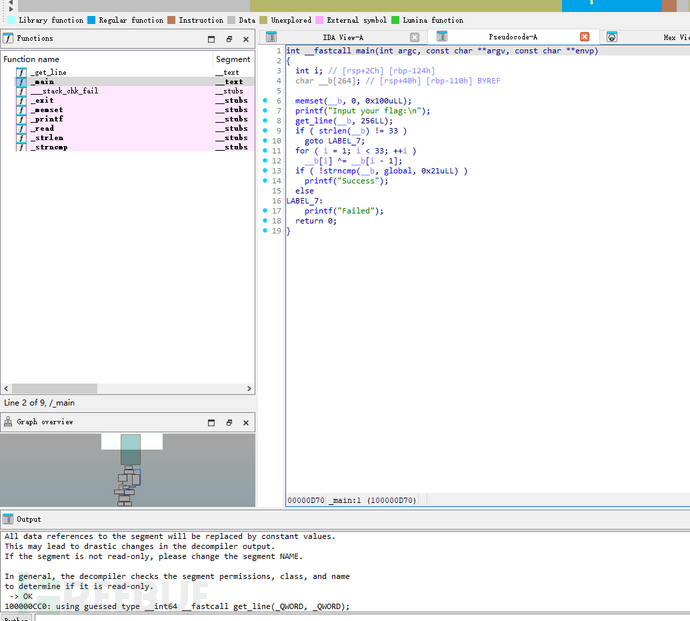
for (i = 1; i < 33; ++i)
__b[i] ^= __b[i - 1];
__b[i] ^= __b[i - 1];:将 __b[i] 与 __b[i-1] 进行按位异或(XOR)操作。这样会改变 __b 数组的值,使得它的内容被“混淆”了。每个字符都会和前一个字符进行异或操作,生成一个新的字符。
关键点分析
用户输入长度:用户输入的字符串必须是 33 个字符长。若不是,会直接失败。
按位异或处理:输入的字符串会依次与前一个字符进行按位异或操作。这种操作通常用于加密或“扰乱”原始数据。结果是,__b 中的字符被逐渐混淆,这意味着如果我们知道 __b 最初的内容,我们就可以通过这个过程推断出原始字符串。
与 global 比较:最终,处理后的 __b 字符串将与 global 字符串进行比较。如果匹配,输出 "Success",否则输出 "Failed"。
查找global值: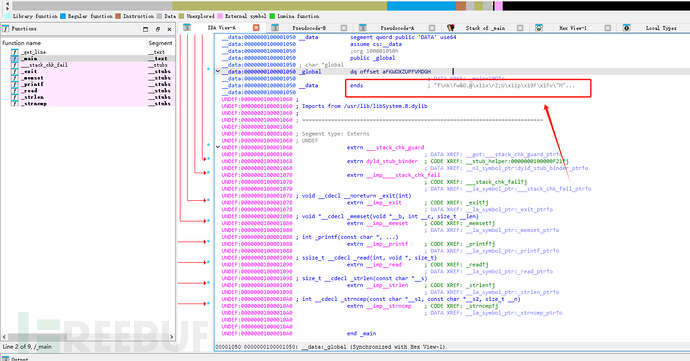
显示不全,点击aFKWOXZUPFVMDGH继续寻找: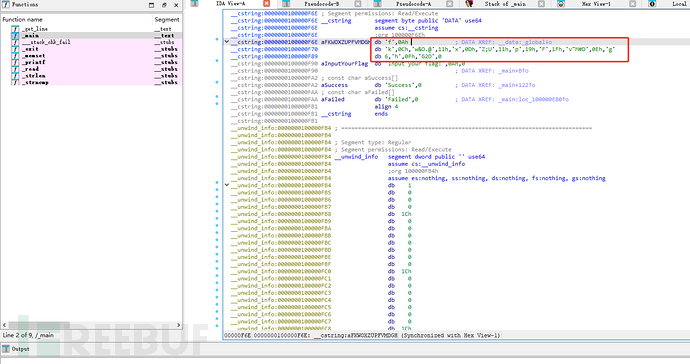
得到global值:['f',0Ah,'k',0Ch,'w&O.@',11h,'x',0Dh,'Z;U',11h,'p',19h,'F',1Fh,'v"M#D',0Eh,'g',6,'h',0Fh,'G2O',0]
脚本计算
tmp = ['f', 0x0A, 'k', 0x0C, 'w', '&', 'O', '.', '@', 0x11, 'x', 0x0D, 'Z', ';', 'U', 0x11, 'p', 0x19, 'F', 0x1F, 'v',
'"', 'M', '#', 'D', 0x0E, 'g', 6, 'h', 0x0F, 'G', '2', 'O']
# 初始化 flag,首先存储第一个字符
flag = [tmp[0]]
# 解密逻辑
for i in range(1, len(tmp)):
if isinstance(tmp[i], str):
if isinstance(tmp[i - 1], str):
# tmp[i] 和 tmp[i-1] 都是字符串
flag.append(chr(ord(tmp[i]) ^ ord(tmp[i - 1])))
else:
# tmp[i] 是字符串,tmp[i-1] 是整数
flag.append(chr(ord(tmp[i]) ^ tmp[i - 1]))
else:
# tmp[i] 是整数
if isinstance(tmp[i - 1], str):
# tmp[i-1] 是字符串
flag.append(chr(tmp[i] ^ ord(tmp[i - 1])))
else:
# tmp[i-1] 也是整数
flag.append(chr(tmp[i] ^ tmp[i - 1]))
# 合并结果并确保使用 UTF-8 编码
flag_result = ''.join(flag)
# 输出结果,尝试使用 UTF-8 编码显示
try:
print("Decrypted Flag:", flag_result.encode('utf-8').decode('utf-8'))
except UnicodeDecodeError:
print("Decrypted Flag (raw):", flag_result)
这里有坑,输出如果是乱码则加个编码。。。
reverse3
exe,查壳:
丢入IDA: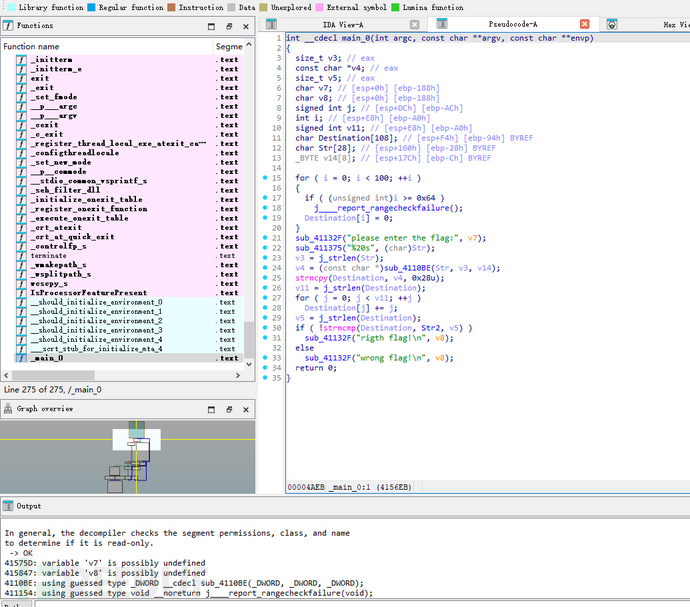
char Destination[108]; // 用于存储目标字符串
char Str[28]; // 用于存储用户输入的字符串
_BYTE v14[8]; // 用作辅助数组
初始化 Destination 数组
for ( i = 0; i < 100; ++i )
{
if ( (unsigned int)i >= 0x64 )
j____report_rangecheckfailure();
Destination[i] = 0;
}
调用sub_4110BE函数,传递 Str 和它的长度作为参数,并将结果存储到 v4。
v3 = j_strlen(Str);
v4 = (const char *)sub_4110BE(Str, v3, v14);
strncpy(Destination, v4, 0x28u);
遍历 Destination 字符串,将每个字符的 ASCII 值加上它的索引 j,即 Destination[j] += j。这样,字符串中的每个字符都会通过其索引发生变化,增加了一种偏移量。
v11 = j_strlen(Destination);
for ( j = 0; j < v11; ++j )
Destination[j] += j;
字符串匹配
v5 = j_strlen(Destination);
if ( !strncmp(Destination, Str2, v5) )
sub_41132F("rigth flag!\n", v8);
else
sub_41132F("wrong flag!\n", v8);
计算Destination的长度 v5。使用strncmp函数比较Destination和Str2字符串的前v5个字符。如果相等,说明用户输入的标志正确,否则显示 "wrong flag!"。
分析编码函数
分析sub_4110BE函数:
关键部分: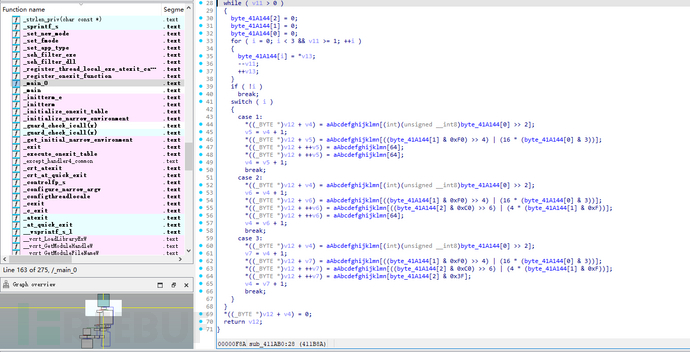
该函数实现了一个Base64 编码器的功能,将输入的值编码后输出。
关键输入Str2,双击查看: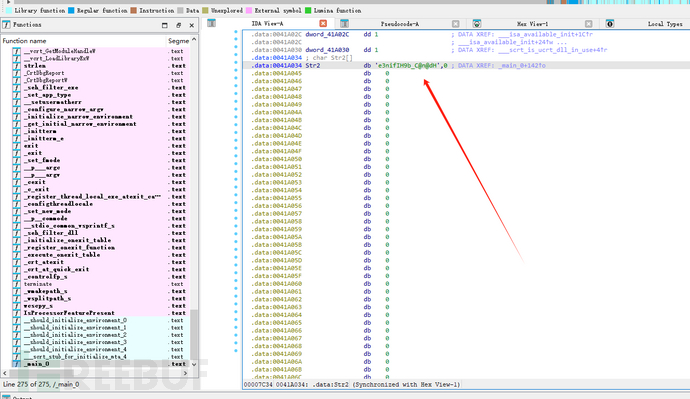
根据上述,编写脚本:
import base64
def calculate_flag(str2: str) -> str:
# 初始化变量
destination = [0] * len(str2)
decoded = []
# 倒推偏移操作,计算 Destination 原始值
for i in range(len(str2)):
destination[i] = ord(str2[i]) - i
# 将 Destination 反向 Base64 解码
base64_chars = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/"
base64_decoded = []
buffer = []
for char in destination:
if chr(char) in base64_chars:
buffer.append(base64_chars.index(chr(char)))
if len(buffer) == 4:
# 处理 Base64 编码的 4 个字符转回 3 字节
value = (buffer[0] << 18) | (buffer[1] << 12) | (buffer[2] << 6) | buffer[3]
base64_decoded.extend([(value >> 16) & 0xFF, (value >> 8) & 0xFF, value & 0xFF])
buffer = []
elif chr(char) == '=':
# '=' 填充的情况
if len(buffer) == 2:
value = (buffer[0] << 18) | (buffer[1] << 12)
base64_decoded.extend([(value >> 16) & 0xFF])
elif len(buffer) == 3:
value = (buffer[0] << 18) | (buffer[1] << 12) | (buffer[2] << 6)
base64_decoded.extend([(value >> 16) & 0xFF, (value >> 8) & 0xFF])
buffer = []
# 将字节数组转为字符串
for b in base64_decoded:
decoded.append(chr(b))
return ''.join(decoded)
# 输入目标字符串
str2 = "e3nifIH9b_C@n@dH"
flag = calculate_flag(str2)
print("flag:", flag)
获得flag: flag{i_l0ve_you}
helloword
apk文件,AndroidKiller分析即可看见flag: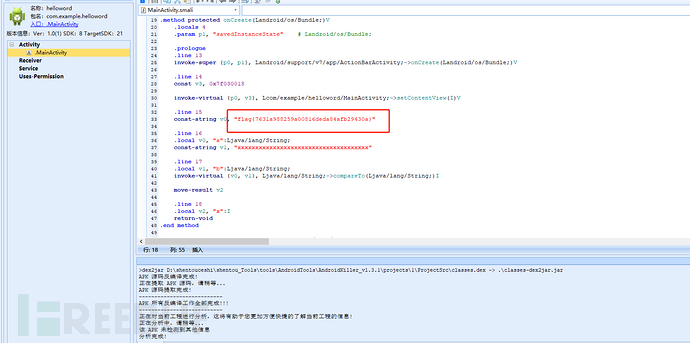
不一样的flag
exe文件,查壳: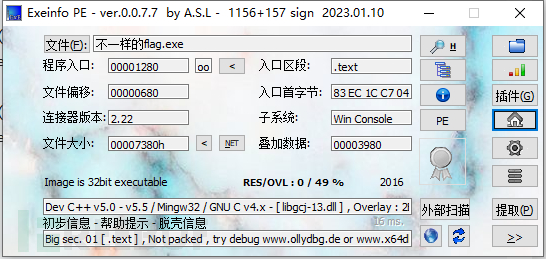
丢入IDA: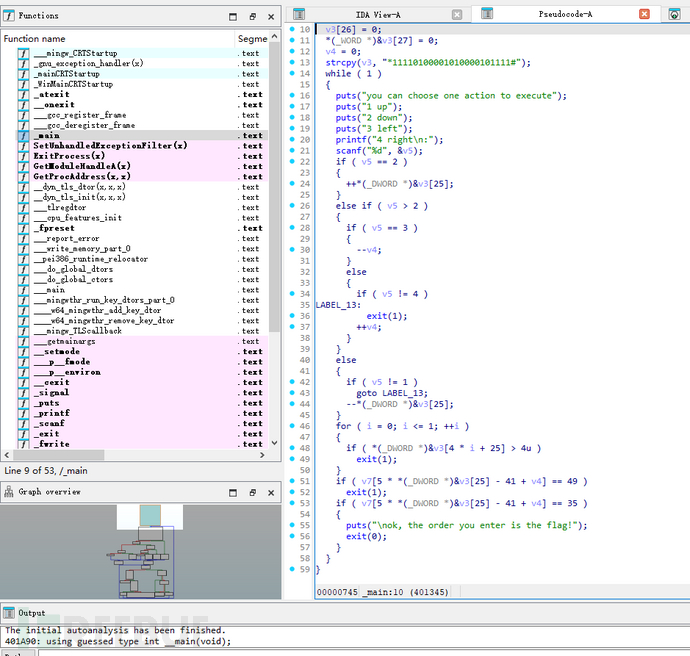
根据v3的值*11110100001010000101111#,改代码表示了迷宫的布局,其中*是起点,#是目标位置,1是不可通过的位置,0是可以通过的位置。1是上,2是下,3是左,4是右。正确出去的方向即是flag值。
变量 v3[25] 和 v4 分别代表玩家在二维迷宫中的行和列位置。
根据v3的值,迷宫可以表示为:
*1111
01000
01010
00010
1111#
根据迷宫,flag应该是:222441144222
SimpleRev
无后缀,直接丢入IDA查看main: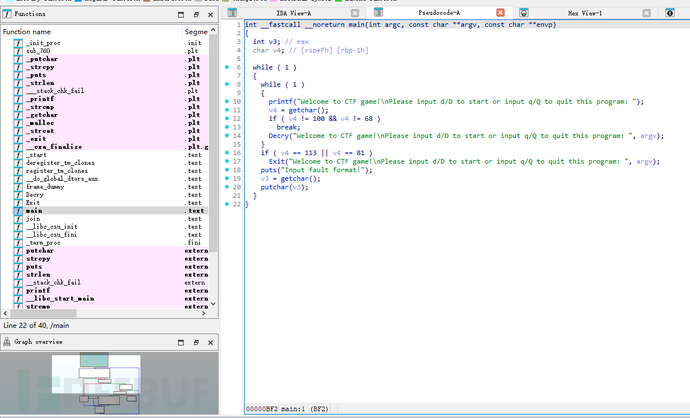
输入d或D会调用模拟的Decry()。
输入q或Q退出程序。
输入其他内容会提示错误并继续循环。
双击查看Decry():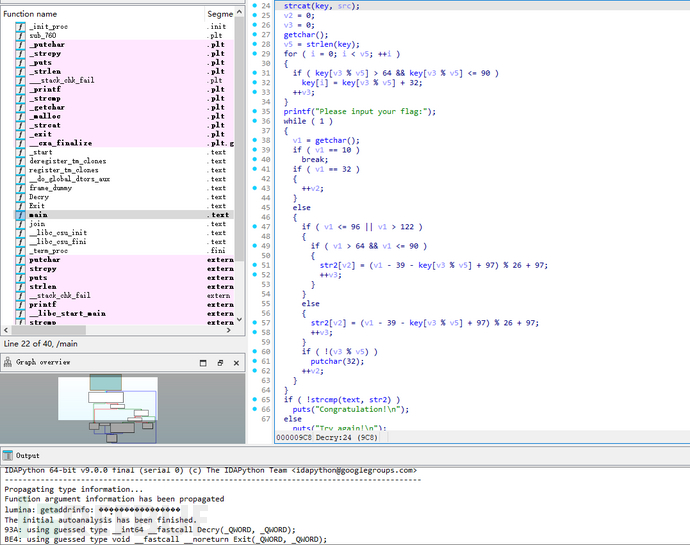
*(_QWORD *)src = 0x534C43444ELL; // src = "DLCLS"
v9[0] = 0x776F646168LL; // v9 = "ahdow"
text = (char *)join(key3, v9);
这部分得到text=key3+v9。
strcpy(key, key1); // 将 key1 复制到 key
strcat(key, src); // 将 src 拼接到 key
这部分得到keykey = key1 + src。
if (key[v3 % v5] > 64 && key[v3 % v5] <= 90)
key[i] = key[v3 % v5] + 32;
将 key 中的大写字母转为小写。
printf("Please input your flag:");
while (1) {
v1 = getchar();
if (v1 == 10) // 输入结束
break;
if (v1 == 32) { // 空格处理
++v2;
} else {
if (v1 > 64 && v1 <= 90) { // 大写字母
str2[v2] = (v1 - 39 - key[v3 % v5] + 97) % 26 + 97;
++v3;
} else if (v1 > 96 && v1 <= 122) { // 小写字母
str2[v2] = (v1 - 39 - key[v3 % v5] + 97) % 26 + 97;
++v3;
}
if (!(v3 % v5)) // 每 v5 次循环插入一个空格
putchar(32);
++v2;
}
}
根据上述描述,还需要知道key1、key3为便可逆推。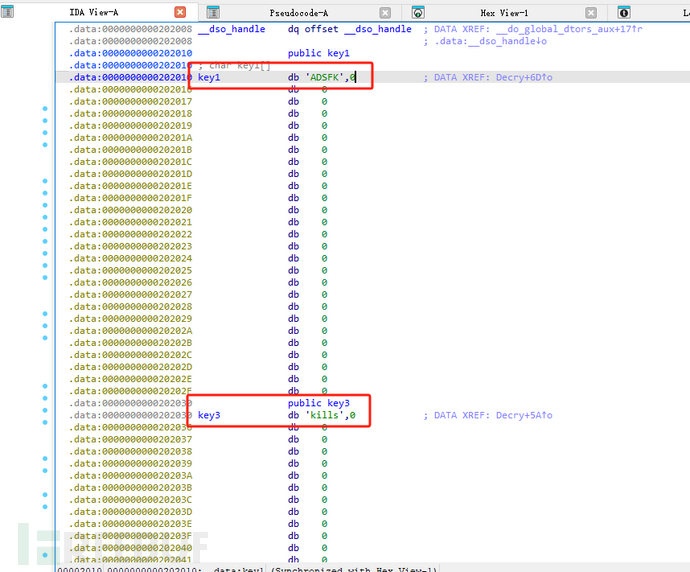
key1和key3的值已知。
printf("Please input your flag:");
while ( 1 )
{
v1 = getchar();
if ( v1 == 10 )
break;
if ( v1 == 32 )
{
++v2;
}
else
{
if ( v1 <= 96 || v1 > 122 )
{
if ( v1 > 64 && v1 <= 90 )
{
str2[v2] = (v1 - 39 - key[v3 % v5] + 97) % 26 + 97;
++v3;
}
}
else
{
str2[v2] = (v1 - 39 - key[v3 % v5] + 97) % 26 + 97;
++v3;
}
if ( !(v3 % v5) )
putchar(32);
++v2;
}
}
根据上边代码,对输入内容进行操作后储存在 str2 里,最后将 str2 与 text 作比较,相同则为 flag。
脚本
根据这写逆推脚本:
text = "killshadow" # 解密目标文本
key = "adsfkndcls" # 密钥文本
flag = [""] * 10 # 用于存储加密后的 flag
str_result = [""] * 10 # 用于存储解密结果
# 遍历目标文本的每个字符
for i in range(10):
# 遍历所有可能的字符('A'-'Z', 'a'-'z')
for j in range(128):
if j < ord('A') or j > ord('z') or (ord('Z') < j < ord('a')):
continue # 跳过无效字符
# 加密字符的逆向逻辑
if (j - 39 - ord(key[i]) + 97) % 26 + 97 == ord(text[i]):
str_result[i] = chr((j - 39 - ord(key[i]) + 97) % 26 + 97) # 解密字符
flag[i] = chr(j) # 对应的加密字符
print(f"Flag so far: {''.join(flag)} Decoded text: {''.join(str_result)}")
break # 找到匹配字符后退出当前循环
# 输出最终结果
print(f"flag{{{''.join(flag)}}}")
flag为: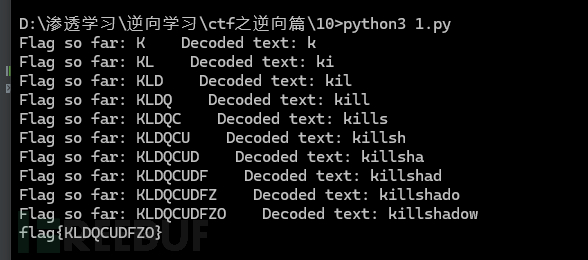
luck_guy
丢入IDA: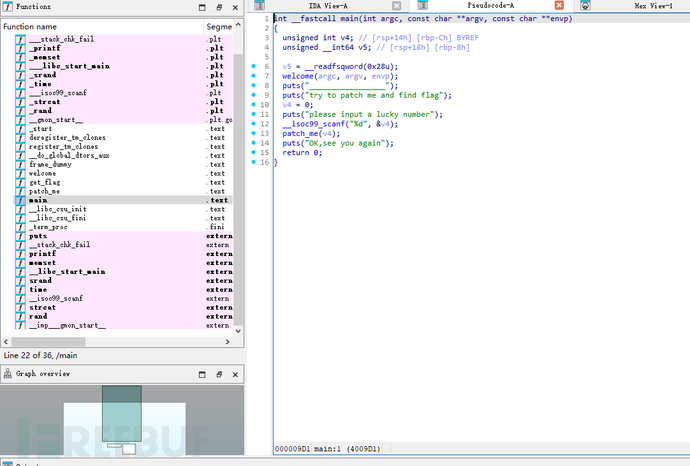
输入的数字被传递给patch_me()函数,这是获取 flag 的关键。需要对 patch_me 的逻辑进行分析,可能包含验证输入是否满足某种条件或执行某种操作。
分析patch_me():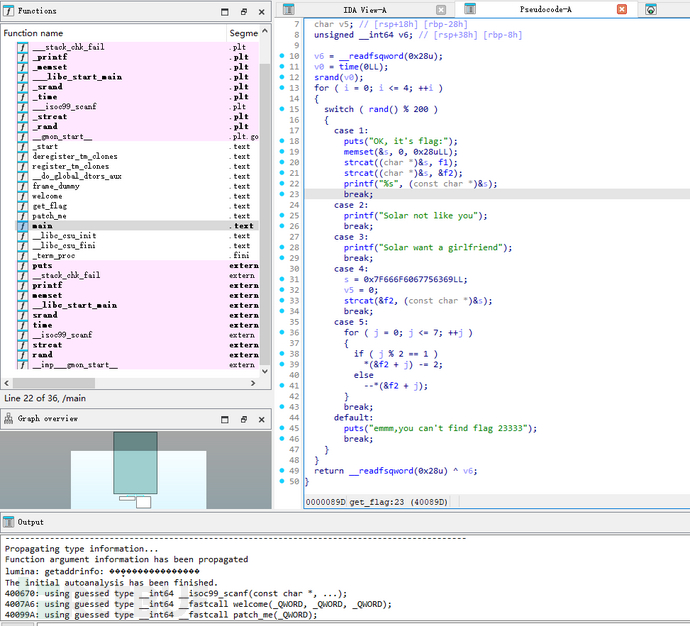
根据case1:
case 1:
puts("OK, it's flag:");
memset(&s, 0, 0x28uLL);
strcat((char *)&s, f1);
strcat((char *)&s, &f2);
printf("%s", (const char *)&s);
break
需要知道f1和f2的值。
f1的值为: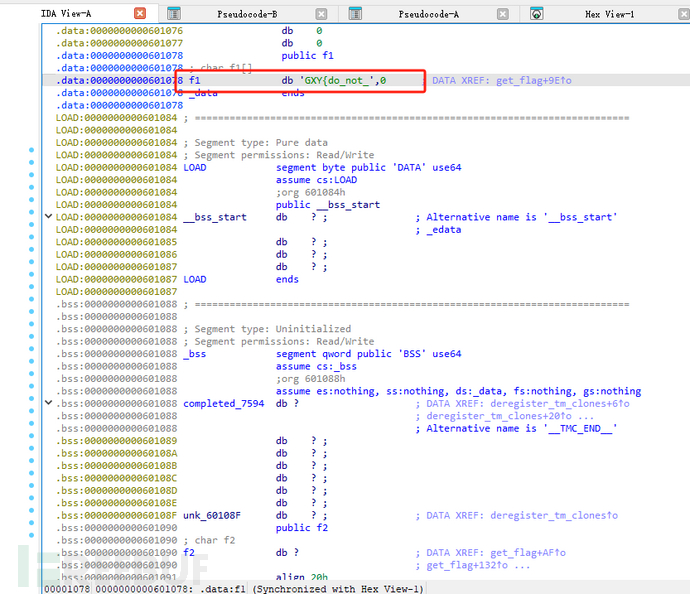
明显是半截,f2的值未知,则需要考虑其他。
case2和case3忽略。
case 4:
s = 0x7F666F6067756369LL;
v5 = 0;
strcat(&f2, (const char *)&s);
break;
case 5:
for ( j = 0; j <= 7; ++j )
{
if ( j % 2 == 1 )
*(&f2 + j) -= 2;
else
--*(&f2 + j);
}
根据代码,f2为0x7F666F6067756369flag=f1+f2
则写脚本:
def calculate_flag():
# 已知值
f1 = "GXY{do_not_"
f2 = 0x7F666F6067756369 # 小端序存储
# 将 f2 转换为小端序字符串
f2_bytes = f2.to_bytes(8, byteorder='little')
f2_chars = [chr(b) for b in f2_bytes] # 转换为字符列表
# case 5 的逻辑
for i in range(len(f2_chars)):
if i % 2 == 0: # 偶数索引
f2_chars[i] = chr(ord(f2_chars[i]) - 1)
else: # 奇数索引
f2_chars[i] = chr(ord(f2_chars[i]) - 2)
# 将修改后的 f2_chars 转换回字符串
f2_modified = ''.join(f2_chars)
# 拼接得到最终 flag
flag = f1 + f2_modified
return flag
# 计算并打印结果
flag = calculate_flag()
print("Flag:", flag)
此处注意,小端序的使用是现代计算机体系结构的默认行为,结合上述代码逻辑以及标准库函数调用,小端序存储和读取是符合预期的。
未完待续~
已在FreeBuf发表 0 篇文章
- 0 文章数
- 0 关注者