


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

 百度安全实验室
百度安全实验室- 关注
一、引言
在日常企业安全能力建设中,收敛企业外网高危资产,以保障公司外部安全是企业安全的重要工作。WEB 高危服务(如:管理后台、内部系统等)外开是企业所面临的一个重要风险。针对该风险,传统的方式是基于规则进行识别,该方式需要投入大量人力成本进行规则维护。由于规则难以覆盖全面,经常出现误报、漏报,效果不佳的问题。
通过“文心大模型”,仅投入少量资源,解决了高危 WEB 应用服务识别的问题,并且准确率达到了 70% 以上,下面将详细为大家介绍。
二、传统高危 WEB 服务识别技术
传统高危 WEB 服务识别技术通过收集开源指纹库和内部产品指纹维护构建成了一套企业指纹识别库,其主要原理是通过获取 WEB 应用的 Header、Body、Title、Banner 等信息,对比指纹库规则进行判别,该模式下需要源源不断地扩充企业指纹库来达到较好的检出效果。传统的高危 WEB 服务识别技术架构如下图所示:
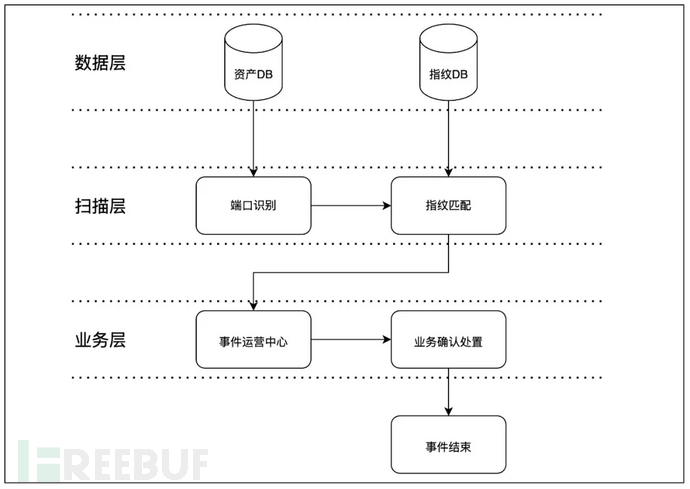
该架构主要包含三部分,分别为数据层、扫描层和业务层。其中数据层作为整个架构的基石,承载着公司网络资产和指纹资产,其数据丰富程度很大程度上决定了 WEB 服务识别能力的成熟度和覆盖广度。
扫描层通常对数据层数据进行处理,解析成固定格式的数据作为扫描输入源。一般情况下,利用端口扫描模块对资产发起端口发现,服务识别,CPE 信息获取等操作。在获取了一批有效的资产数据之后,对资产发起请求获取服务信息,并对比已有指纹库进行判别。其主要实现逻辑如下图所示:

通过 WEB 服务解析模块对所有 WEB 资产服务信息进行提取
获取到 WEB 服务信息后通过与指纹 DB 对比获取结果
返回传递最终结果
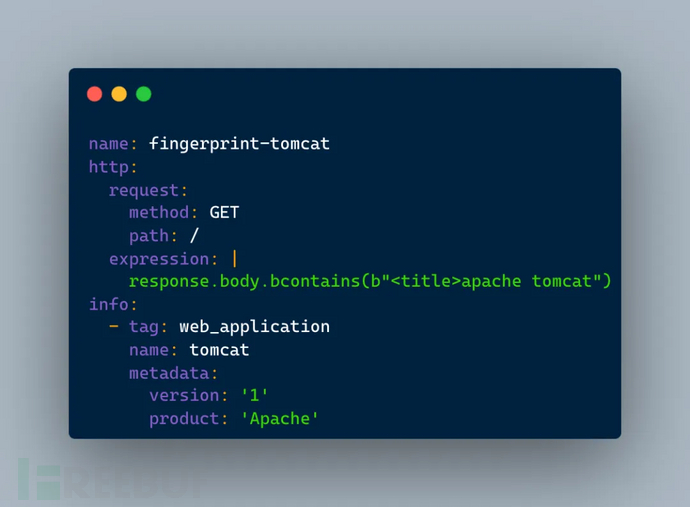 图:指纹规则示例
图:指纹规则示例
业务层作为事件运营处置层,通常接受其他数据源的输入,安全运营人员判别事件后,将其推送给业务方进行修复,从而完成事件闭环。
三、高危 WEB 服务识别面临困难点
在第二章里了解了传统高危 WEB 服务识别的技术原理以及方案,那么从方案中可以发现会存在以下几点问题:
检测规则依赖人工编写维护,在人力资源有限的情况下,如何保障外网高危服务资产的风险得以收敛?
我们可以识别和发现已知框架和服务并将其转为检测规则,那么面对未知服务/框架我们如何能够发现潜在风险?
那么接下来,我将会围绕以上两点问题进行展开,讨论如何通过大模型能力帮助公司解决传统方案的痛点。
四、大模型高危 WEB 应用服务识别设计思路
在前面我们讲到了,传统检测方案依赖与人工维护指纹规则来保障检测能力的成熟度。那么在当下文生文大模型飞速发展的情况下,是否可以通过训练大模型等方式来识别高危 WEB 应用服务呢?答案是显然的。
4.1. 大模型输入
在开始正式训练模型识别高危 WEB 应用服务前,我们需要考虑好模型的输入数据格式。从安全工程师的视角来看,判断一个 WEB 应用服务是否为高危应用主要从以下几个方面:Title,Body、Header 等三类信息,其中较为重要的是 Title,Body 两块。由于原始的 HTML Body 中会包含较多无用标签和数据,因此我们需要在原始数据基础上继续清洗,以保证最终模型输入的数据是相对较为干净的。如果原始数据中包含较多的脏数据,可能模型会产生噪点,最终影响到真实场景下的输出不稳定。除此之外,由于输入的 Token 限制,需要对较大的原始 HTML Body 进行缩减以满足 Token 要求。
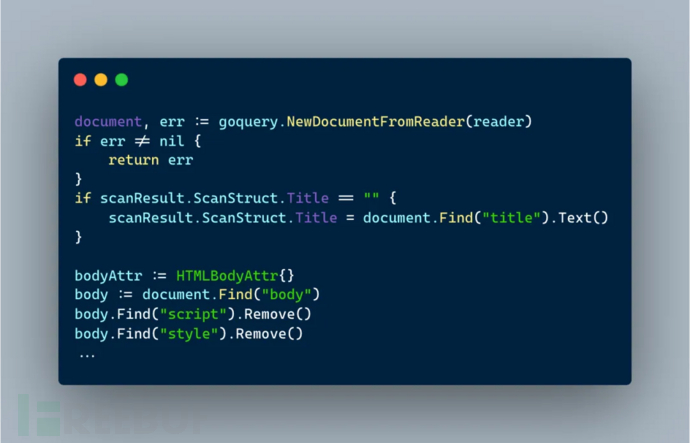 图:输入数据清洗示例
图:输入数据清洗示例
4.2. 大模型判别规则
为了训练模型,告诉模型哪类服务是高危服务,需要在前期制定好模型判别规则约束好高危服务的范围有哪些,可以通过提前界定好的规则判断 WEB 应用是否为高危服务,下面是几个判定案例:
系统涉及到管理功能的平台视为高危服务。
已知的开源系统/框架不应该开放到外网访问的视为高危服务,比如:Kibana、ElasticSearch、Grafana、Nacos 等。
无效页面、错误页面视为非高危服务,比如:状态 404,500,502 等以及 nginx/centos 等 default page 页面。
对外提供服务的常规页面,产品介绍页面视为非高危,比如:百度智能云产品、百度网盘等 ToB、ToC 场景。
4.3. Prompt 构造
在上面我们定义好了部分判别规则后,需要构造模型理解的 Prompt 指导大模型如何进行服务判别,Prompt 的好坏影响着大模型的性能。一个好的 Prompt 上下文能够充分利用大模型的背景语料知识,并在 Prompt 提示下的特定工作内容中获得更好的表现。经过后期的观察表现,我们提炼出来了以下一部分 Prompt 作为模型指导,其内容如下所示:
"现在有一份从网站首页提取的数据,请你根据这份数据判断该网站是否属于高危服务,并给出响应的判断理由。\n\n"+
.....
"## 要求:\n" +
"1.充分考虑数据中每一个字段,发现可能象征着风险的关键字。\n" +
.....
"## 判断依据:\n" +
"高危服务主要指代暴露后可能对公司信息系统造成危害对服务。\n" +
"1. 对于管理后台登录、控制面板、数据库面板等页面,应当判定为高危服务。\n" +
......
"非高危服务指正常对外开放,提供各种功能的服务。\n" +
"1. 对于常规的网站服务、普通用户登录等页面,判定为非高危服务。\n" +
.....
"## 输出格式\n" +
"{\"reason\": \"<判断为高危或非高危的具体理由>\", \"isDangerous\": <true或false>}\n\n\n\n\n"
4.4. 输入数据源
在准备好以上的工作之后,我们需要挑选一批数据作为初始数据投喂给基础模型识别与训练。前期数据源需要保证数据的质量具有代表性,确保模型能够直观从数据源中构建出我们想要的结果。因此我们在训练前期,通过内部的资产库,挑选了 100 多条具有代表性的数据作为初始输入,这里包含常见的 WEB 应用框架(Grafana、ElasticSearch)、内部高危系统、常规百度对外服务和通用管理后台页面等。
在前期人工完成数据标记之后,我们已经基本完成了一个初版的数据源。为了提升模型的准确率,需要增加数据源来满足模型了解足够的知识。因此后期采用了 self instruction 的方法,直接调用大模型打标,并进行人工复核。
self instructe 用的是所谓语境学习 (In-contextLearning) 的方法,通过在 Prompt 中提供数个样例,依赖大模型预言基座,执行小样本学习。具体方式就是将上述的 Prompt 进行改造,构造几个预先设定好的对话上下文,让大模型在已经进行了几轮对话的前提下对新的内容进行生成。此处对话直接使用普适性较高且性能优越的旗舰模型:百度千帆 ERNIE 4.0 Turbo。
4.5. 模型微调
微调的数据量被建议在 1k 条左右。由于本模型使用的是百度千帆平台进行训练,按照格式导出数据在千帆平台上训练即可。得到的模型发布后,相较于原始模型能够更加准确地回答,并且确保了输出格式的准确,严格按照样式。
微调完成后,对于后续模型数据的录入,就无需再通过之前的 Prompt Learning 等方式,直接使用当前模型进行标注,人工筛选后重复训练进行模型强化学习。
通过以上流程,我们基本上可以训练出来一个较为精准的模型帮助我们识别外部高危 WEB 应用服务。接下来讲解一下训练后的模型在真实场景下的实践。
五、大模型高危 WEB 应用服务识别实践
目前该方案在公司场景中的架构如下图所示: 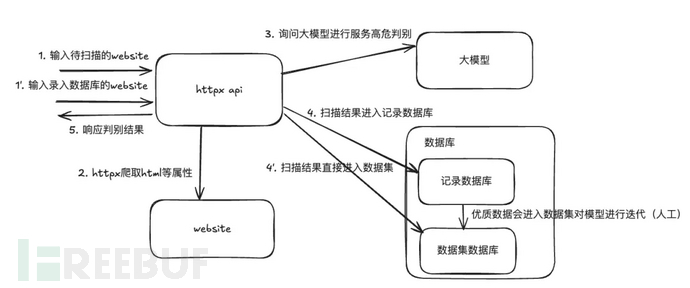
该架构主要分为两部分:WEB 资产信息获取和大模型判别。
目前应用在服务识别的下一模块进行调用,默认情况下进行外网资产端口发现和服务识别后,调用资产信息采集 Agent 解析 WEB 资产中包含的报文、标题等关键信息,经过数据清洗之后由 API 接口直接请求对接后端大模型能力进行判定;根据判定结果推送至事件运营中心运营。
那么在模型前期,会基于人工运营的数据对大模型进行 Prompt 调整,用来确保获得更加精准的 Prompt 帮助模型提升准确率。前期经过几轮迭代之后,模型可以在无人监督的情况下得出较好的精度。以下为训练后真实发现的高危 WEB 应用服务案例:
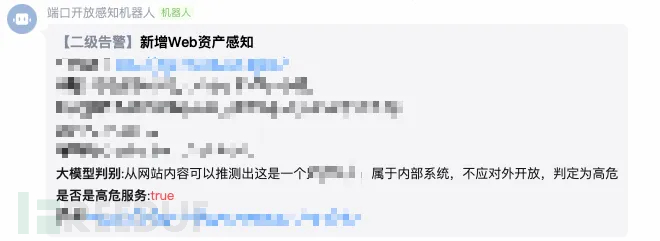
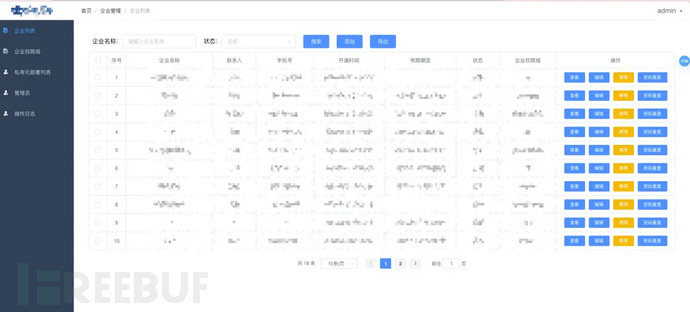 图:高危服务识别案例1
图:高危服务识别案例1

 图:高危服务识别案例2
图:高危服务识别案例2
5.1. 后续迭代优化
在前期我们花费时间得到一个精度较高的模型后,在后期持续运营迭代过程中,只需投入少量人力复核识别结果,对偏差数据进行微调,可以不断完善提升模型准确率。流程如下图所示:
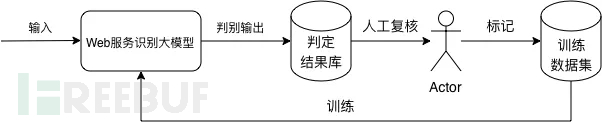
在后期人工标记过程中,可以定期对模型的训练数据进行纠正标记;积攒一批量的数据对模型进行微调,可以在一定程度上避免由于标记数据不足而导致的模型微调结果不理想的情况。
六、后记
在实际的安全使用场景中,该方式通过较少的数据集训练出较好的模型效果。目前能够以较为精准的知识判别 WEB 服务是否为高危应用,目前准确率达到:70%。同时在实际应用过程中,内部也发现了很多业务方的管理后台服务和测试环境等高危应用场景外开的情况,能够有效地解决如上提到的两点问题,在人力资源有限的情况下,只需要定期投入部分人力对模型进行标记调整,同时无需关注维护指纹规则库就可以达到较为显著的效果。
除此之外该方案面临最大的一个问题在于大模型并不具备先见知识,对于部分场景下的 WEB 应用缺乏真实的理解,比如 ToB 交付业务服务应该需要开放在公网提供给客户等场景下,大模型识别目前精准度还待提升。未来还需要持续投入人力完善模型训练,解决该场景下的问题。
如需授权、对文章有疑问或需删除稿件,请联系 FreeBuf 客服小蜜蜂(微信:freebee1024)






- 121 文章数
- 49 关注者