


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

- 关注
写在前面的话
跨站点脚本 (XSS) 是一种众所周知的漏洞类型,威胁行为者可以将 JavaScript 代码注入易受攻击的页面。当不知情的目标用户访问该页面时,注入的代码将在目标用户的会话中执行。此攻击的影响可能因应用程序而异,例如帐户接管(ATO)、数据泄露,甚至远程代码执行(RCE),但不会造成业务影响。

XSS有多种类型,例如反射型、存储型和通用型。但近年来,XSS的变异类型因绕过 DOMPurify、Mozilla bleach、Google Caja 等数据清洗程序而令人生畏……影响了包括 Google 搜索在内的众多应用程序。到目前为止,我们发现许多应用程序都容易受到此类攻击。
背景
如果您是 Web 开发人员,您可能已经集成甚至实施了某种数据清洗措施来保护您的应用程序免受 XSS攻击。但人们对制作合适的HTML数据清洗程序其难度并不清楚。HTML数据清洗程序的目标是确保用户生成的内容(例如文本输入或从外部来源获取的数据)不会带来任何安全风险或破坏网站或应用程序的预期功能。
实施HTML数据清洗程序的主要挑战之一在于HTML本身的复杂性。HTML是一种多功能语言,具有各种元素、属性和潜在组合,这些元素、属性和组合可能会影响网页的结构和行为。准确解析和分析HTML代码并保留其预期功能可能是一项艰巨的任务。
HTML
在讨论mXSS之前,我们先来了解一下HTML,它是网页的基础标记语言。了解HTML的结构及其工作原理至关重要,因为mXSS(变异型跨站点脚本)攻击利用了HTML的特殊性和复杂性。
HTML被认为是一种“宽容”的语言,因为它在遇到错误或意外代码时具有宽容的特性。与一些更严格的编程语言不同,即使代码编写得不完美,HTML也会优先显示内容。这种宽容的表现如下:
当呈现错误的标记时,浏览器不会崩溃或显示错误信息,而是会尝试尽可能地解释和修复HTML,即使其中包含轻微的语法错误或缺少元素。例如,在浏览器中打开标记“<p>test”时将按预期执行,尽管缺少结束的p标记。查看最终页面的HTML代码时,我们可以看到解析器修复了损坏的标记并p自行关闭了元素:<p>test</p>。
它为何具有宽容度?原因如下:
1、可访问性:网络应该对所有人都开放,HTML中的小错误不应妨碍用户查看内容,宽容度允许更广泛的用户和开发人员与网络互动;
2、灵活性:HTML经常被具有不同编码经验水平的人们使用,宽容度允许一些粗心或错误的出现,而不会完全破坏页面的功能;
3、向后兼容性:网络在不断发展,但许多现有网站都是使用较旧的HTML标准构建的。即使这些较旧的网站不符合最新规范,宽容度也能确保它们仍可在现代浏览器中显示;
但是我们的HTML解析器如何知道以何种方式“修复”出问题的标记?应该把<a><b>变成<a></a><b></b>还是<a><b></b></a>?
为了回答这个问题,社区有一个文档齐全的HTML规范,但不幸的是,仍然存在一些歧义,导致即使在当今的主流浏览器之间也存在不同的HTML解析行为。
变异
好的,就算HTML可以允许有问题的标记,可这有什么关系呢?
mXSS中的 M 代表“变异”,HTML中的变异指的是出于某种原因对标记所做的任何类型的修改行为。例如:
1、当解析器修复损坏的标记(<p>test→ <p>test</p>)时,这就是一种变异;
2、规范化属性引号(<a alt=test>→ <a alt=”test”>),这是一种变异;
3、重新排列元素(<table><a>→ <a></a><table></table>),这是一种变异;
4、等等…
而mXSS,则可以利用这种行为来绕过数据清洗。
HTML解析背景
不同的内容解析类型
HTML并不是一个通用的解析环境。元素以不同的方式处理其内容,目前有七种不同的解析模式。我们需要弄清楚这些模式,以了解它们如何影响mXSS漏洞:
1、void元素:area, base, br, col, embed, hr, img, input, link, meta, source, track, wbr;
2、模版元素:template;
3、原始文本元素:script, style, noscript, xmp, iframe, noembed, noframes;
4、可转义的原始文本元素:textarea, title;
5、外部内容元素:svg, math;
6、明文状态:plaintext;
7、普通元素:所有其他允许的HTML元素都是普通元素;
我们可以使用以下示例展示解析类型之间的差异:
1、我们的第一个输入是一个div元素,它是一个“普通元素”:
<div><a alt="</div><img src=x onerror=alert(1)>">
2、第二个输入是使用style元素的类似标记(即“原始文本”):
<style><a alt="</style><img src=x onerror=alert(1)>">
查看解析后的标记,我们可以清楚地看到解析的差异:


div元素的内容渲染为HTML,a元素就创建了。看似是div和img标签结束符的东西实际上是a元素的属性值,因此它们会被被渲染为元素a的alt文本值,而不是HTML标记。在第二种情况中,style元素的内容被渲染为原始文本,因此没有创建任何a元素,所谓的属性现在是正常的HTML标记。
外部内容元素
HTML5 引入了在网页中集成专门内容的新方法。两个关键示例是<svg>和<math>元素。这些元素利用不同的命名空间,这意味着它们遵循与标准HTML不同的解析规则。了解这些不同的解析规则对于缓解与mXSS攻击相关的潜在安全风险至关重要。
让我们看一下与之前相同的例子,但这次封装在一个svg元素内:
<svg><style><a alt="</style><img src=x onerror=alert(1)>">

在这种情况下,我们确实看到创建了一个a元素。该style元素不遵循“原始文本”解析规则,因为它位于不同的命名空间内。当位于 SVG 或 MathML 命名空间内时,解析规则会发生变化,不再遵循HTML语言。
需要注意的是,使用命名空间混淆技术(例如DOMPurify 2.0.0 绕过),威胁行为者可以操纵数据清洗器,以不同于浏览器最终呈现内容的方式解析内容,从而逃避对恶意元素的检测。
从变异到成为漏洞
解析器差异
无论哪种方式,威胁行为者都可以利用数据清洗器算法与渲染器(例如浏览器)算法之间的解析器不匹配。由于HTML解析的复杂性,存在解析差异并不一定意味着一个解析器是错误的而另一个是正确的。
让我们以noscript元素为例,它的解析规则是:“如果启用了noscript标志,则将标记器切换到RAWTEXT 状态。否则,将标记器保持在data状态。”(链接)这意味着,根据 JavaScript 是禁用还是启用,noscript元素主体的呈现方式会有不同。逻辑上,JavaScript 不会在数据清洗阶段启用,但会在渲染器中启用。从定义上讲,这种行为并没有错,但可能会导致绕过,例如:
<noscript><style></noscript><img src=x onerror=”alert(1)”>
禁用JavaScript:

启用JavaScript:

解析往返
解析往返是一种众所周知且有据可查的现象,即:“如果使用HTML解析器解析此算法的输出,则可能不会返回原始DOM树结构。不经过序列化和重新解析步骤的往返DOM树结构也可以由HTML解析器本身生成,尽管这种情况通常不符合要求。”
这意味着根据我们解析HTML标记的次数,生成的 DOM 树可能会发生变化。
先看看下面这个例子,但我们要先知道,form元素不能嵌套form元素:

但form标记可以通过下列方式嵌套:
<form id="outer"><div></form><form id="inner"><input> html ├── head └── body └── form id="outer" └── div └── form id="inner" └── input
</form>由于未关闭,因此将被忽略,并且未关闭的div元素和input元素将与内部form元素关联。现在,如果此DOM树结构被序列化并重新解析,则<form id="inner">开始标记将被忽略,因此input元素将与外部form元素关联。
<html><head></head><body><form id="outer"><div><form id="inner"><input></form></div></form></body></html> html ├── head └── body └── form id="outer" └── div └── input
威胁行为者可以利用此行为在数据清洗器和渲染器之间造成命名空间混淆,从而导致绕过,例如:
<form><math><mtext></form><form><mglyph><style></math><img src onerror=alert(1)>
数据清洗
下面给出的是一个数据清洗示例,应用程序获取清洗器输出并将svg元素重命名为custom-svg,这会改变元素的命名空间,并可能在重新渲染时导致 XSS:

上下文相关
HTML解析很复杂,并且可能因上下文而异。例如,解析整个文档与 Firefox 中的片段解析不同。在处理浏览器中从清洗到渲染的变化时,开发人员可能会错误地更改渲染数据的上下文,从而导致解析差异并最终绕过清洗器。由于第三方清洗器不知道结果将放在哪个上下文中,因此它们无法解决这个问题。当浏览器实现内置清洗器(Sanitizer API工作)时,这个问题有望得到解决。
例如,应用程序清洗输入,但在将其嵌入页面时,它将其封装在 SVG 中,将上下文更改为 SVG 命名空间:

mXSS案例研究
下面这个例子是一款名为Joplin的软件,这是一款用Electron开发的笔记桌面应用程序。由于电子配置不安全,Joplin中的 JS 代码可以使用 Node 内部功能,从而使威胁行为者能够在目标设备上执行任意命令。
该漏洞的根源在于清洗器的解析器中,它通过htmlparser2 npm 包解析不受信任的HTML输入。该包本身声称它们不遵循规范,并且更看重速度而不是准确性。
我们很快就注意到这个解析器并不符合规范。通过以下输入,我们可以看到该解析器忽略了不同的命名空间:

虽然清洗器的解析器不会渲染img元素,但渲染器会渲染元素。这是解析器差异的一个示例,威胁行为者只需添加onerror事件处理程序,当目标用户打开恶意笔记时,该处理程序就会执行任意代码:
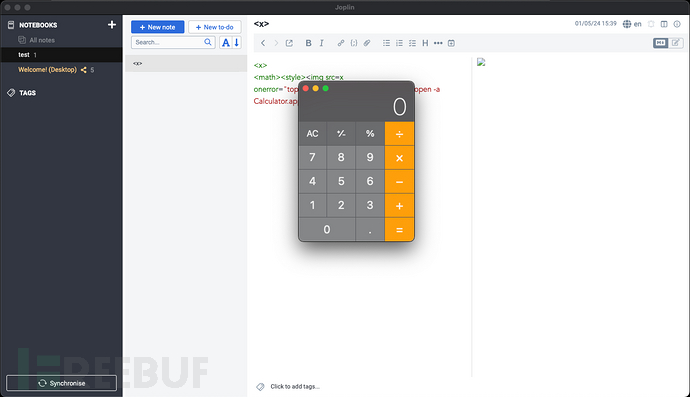
问题缓解
我们鼓励开发人员深入了解此类错误,以便他们能够根据自己的应用程序更好地决定如何缓解此问题。在我们的研究过程中,我们发现了开发人员为了解决mXSS问题而采取的许多缓解方法和安全措施:
1、检查和清洗客户端:这可能是要遵循的最重要的规则。使用在客户端运行的清洗程序(例如DOMPurify)可避免解析器差异风险。
2、不要重新解析:为了避免“往返mXSS”,应用程序可以将已清洗的 DOM 树直接插入文档中,而无需序列化并重新呈现内容。
3、始终对原始内容进行编码或删除:由于mXSS的理念是想办法让恶意字符串在清洗器中呈现为原始文本,但稍后解析为HTML,因此在清洗器阶段不允许/编码任何原始文本将使其无法重新呈现为HTML。请注意,这可能会破坏某些内容,例如 CSS 代码。
4、不支持外部内容元素:不支持外部内容元素(删除 svg/math 元素及其内容而不重命名)可显著降低复杂性。请注意,这不会缓解mXSS,但提供了预防措施。
5、支持通过父命名空间检查来清洗外部元素:解决命名空间混淆的更复杂的方法是实施父命名空间检查,并删除任何位于错误命名空间中的元素。
总结
mXSS(变异型跨站点脚本)是一种由HTML处理方式引起的安全漏洞。即使 Web 应用程序具有强大的过滤器来阻止传统的 XSS攻击,mXSS仍可能潜入其中。这是因为mXSS利用HTML行为中的特殊性,使数据清洗工具无法发现恶意元素。
参考资料
https://www.youtube.com/watch?v=g3yzTQnIgtE
https://sonarsource.github.io/mxss-cheatsheet/
https://research.securitum.com/dompurify-bypass-using-mxss/
https://html.spec.whatwg.org/multipage/scripting.html#the-noscript-element
https://html.spec.whatwg.org/multipage/parsing.html
https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2023-33726
参考链接
https://www.sonarsource.com/blog/mxss-the-vulnerability-hiding-in-your-code/
- 0 文章数
- 0 关注者