


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

- 关注
近年来,深度学习模型(DLM)在软件漏洞检测领域的应用探索引起了行业广泛关注,在某些情况下,利用DLM模型能够获得超越传统静态分析工具的检测效果。然而,虽然研究人员对DLM模型的价值预测让人惊叹,但很多人对这些模型本身的特性并不十分清楚。
为了从应用角度对DLM模型在漏洞检测场景下的能力与价值进行验证,Steenhoek等人发表了《An Empirical Study of Deep Learning Models for Vulnerability Detection》(《漏洞检测的深度学习模型实证研究》)论文。该论文全面回顾了近年来公开发表的DLM在源代码漏洞检测方面的相关研究,并实际复现了多个SOTA深度学习模型(见表1)。通过将这些模型在两个广泛使用的漏洞检测数据集上进行充分实验,论文作者从模型能力、训练数据和模型解释等方面进行了6个专项课题的研究分析。
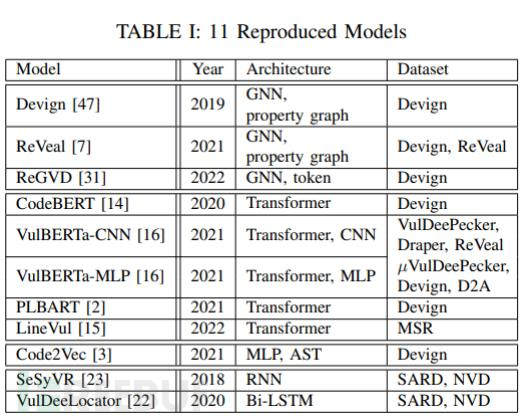
为了验证模型的准确性,作者使用了与原始资料中相同的数据集和参数设置,对这些模型的运行结果进行了再次测试验证(见表 II)。其中A、P、R、F分别代表深度学习中常见的准确率(accuracy)、精确度(precision)、召回率(recall)和F1分数。总体而言,复现的结果差异在合理范围内(上下2%)。
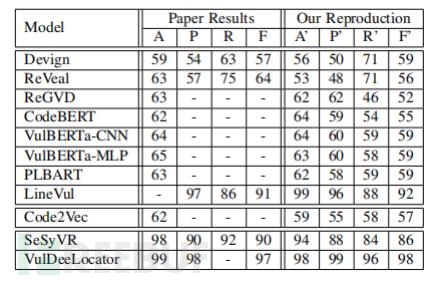
表 II
需要说明的是,为了更精确地比较模型,作者优化了模型的实现,使它们可以同时支持Devign和MSR数据集。然而,在本论文所列举的研究问题分析中,作者仅使用了上述模型中的9个而排除了VulDeeLocator和SeSyVR两种模型,原因是它们不容易针对Devign和MSR数据集进行优化。通过对深度学习漏洞检测模型进行实证研究,作者详细分析了六个研究问题,并在以下方面取得收获:
对深度学习漏洞检测模型进行了全面研究。
提供了一个包含11个SOTA深度学习模型和数据集的复现包,以便其他研究人员可以使用这些工具来进行漏洞检测研究。
设计了6个RQs,以评估深度学习模型在漏洞检测方面的性能、鲁棒性和可解释性,并通过实验回答了这些问题。
提供了有关如何解释深度学习漏洞检测模型决策的示例和数据,以帮助其他研究人员理解。
RQ1:不同模型之间的漏洞检测结果是否具有一致性?单个模型的多次运行和多个模型间的差异点是什么?
研究动机:揭示深度学习模型漏洞检测结果的不确定性,帮助研究人员更好地理解这些模型的表现。
实验设计:实验人员在Devign数据集上使用三个不同的随机种子对11种DLM模型进行训练,然后测量它们在漏洞检测方面的性能,并比较它们之间的一致性。作者测量了在所有三个随机种子下具有相同二进制标签的输入所占的百分比,并将其称为“稳定输入”。然后,作者比较了这些稳定输入在不同模型之间的一致性。
研究发现:研究发现,不同模型在漏洞检测方面的表现存在一定的差异性 ,平均有34.9%的测试数据(30.6%总数据)因为随机种子的不同而产生不同的预测结果。其中,基于属性图(Property Graph)的GNN模型的差异性排名在前两位,而ReVeal模型在50%的测试数据中输出会在不同运行之间发生变化。相比之下,Code2Vec模型表现出最小的变异性。此外,作者还发现,不稳定输入与更多错误预测成正相关。
总的来看,虽然每次运行结果之间存在预测差异,但F1测试分数并没有显著变化,并且平均标准差仅为2.9(见 表 III)。因此,虽然当使用不同的随机种子来训练和测试模型时,模型的性能可能会有所变化,但这种变化应该是可以接受的,并且不会对整体性能产生太大影响。
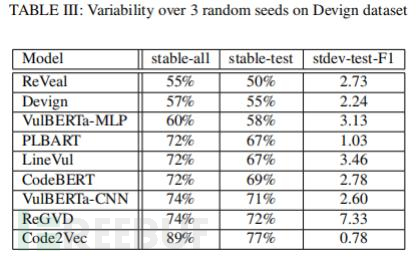
表 III
另外,不同架构的DLM模型在测试结果上表现出了较低的一致性:因为只有7%的测试数据(和7%的总数据)被所有模型所认可。三个GNN模型仅在20%的测试示例(和25%的总数据)上达成了一致,而三个表现最佳的transformer模型(LineVul、PLBART和VulBERTa-CNN)在34%的测试数据(和44%的总数据)上达成了一 致。但是,当比较所有5个transformer模型时,只有22%的测试示例(和29%的总数据)是一致的(见表 IV)。不同模型之间的低一致性意味着:当没有基准标签时,跨模型比较性能的差异测试方法可能意 义非常有限。
表 IV
RQ2:是否存在某些类型的漏洞更容易被检测?是否应该为每种类型的漏洞建立单独模型,还是训练一个可以检测所有漏洞的模型?哪种方式训练出的模型性能更好呢?
研究动机:研究人员将漏洞分为不同的类型,探索这些类型对模型性能和准确性的影响。这有助于更好地理解 DLM处理不同类型漏洞的表现,并为改进模型提供指导。
实验设计:作者借助CWE漏洞分类系统,把漏洞数据分成5类(见表 V)。然后,使用多个DLM来检测这 些漏洞,从而对比它们在不同漏洞类型上的表现。为了减少偏差,研究人员进行了交叉验证。具体的分类包括:缓冲区溢出(Buffer overflow)、值错误(Value error)、资源错误(Resource error)、输入验证错 误(Input validation error)、特权升级(Privilege escalation)。
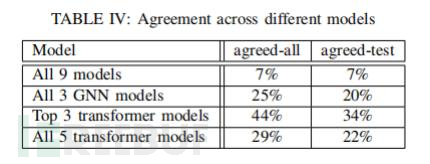
表 V
研究发现:不同类型的漏洞对于DLM的性能和准确性有着不同的影响 (见图1)。具体而言, 一些漏洞类型比其他类型更容易被检测到,例如值错误和缓冲区溢出,而一些漏洞类型则更难以被检测到,例如输入验证错误和特权升级。此外,研究人员还发现,混合模型(棕色柱状图)的性能通常弱于单模型-单漏洞类型 的方式 ,也就是说,在处理不同类型漏洞时,建立单个模型可能不如建立专门针对每种漏洞类型的模型来得 有效。同时,跨漏洞类型的性能往往低于相同漏洞类型的性能(圆形)。
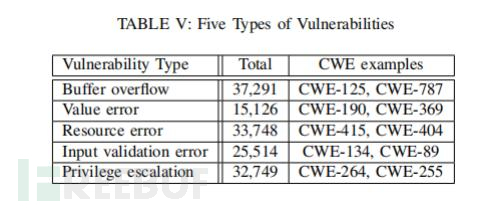
图1
"cross-bugtype" 和 "same-bugtype" 是用于评估混合模型性能的两种方法。在 "cross-bugtype" 中,测试数据和训练数据属于不同的漏洞类型,而在 "same-bugtype" 中,测试数据和训练数据属于相同的漏洞类型。这两种方法可以帮助我们了解混合模型在不同漏洞类型上的性能表现。如果混合模型在 "cross-bugtype" 和 "same-bugtype" 上都表现良好,则说明该模型具有更广泛的适用性和鲁棒性。
RQ3:目前的DLM是否能够精准预测某些具有特定代码特征的程序,如果不能,这些代码特征是什么?
研究动机:在传统的程序分析中,我们知道一些漏洞特征很难被捕捉,例如循环和指针。类似地,研究人员想要了解哪些特征能够被DLM准确捕捉,哪些属于难以捕捉的特征。
实验设计:首先,研究人员将Devign数据集分为易于处理和难以处理的两个子集。然后使用一个基于逻辑回归(Logistic Regression)的模型公式来计算每个函数的难度得分,并将其用作选择简单和困难训练和测试样本的依据。接下来,研究人员对数据进行了特征提取,并使用了一些常见的代码特征(如控制流结构、字符串操作等)。最后,他们使用了5折交叉验证(5 fold cross validation)来评估不同深度学习模型在Devign数据集上的性能,并比较了它们在易/难子集上的性能差异。
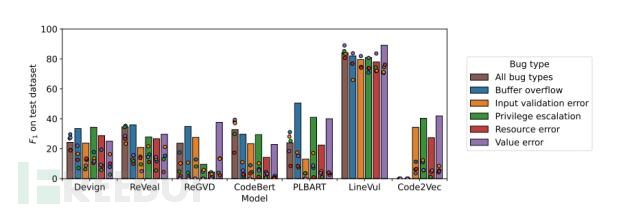
图2
研究发现:DLM在简单子集上的性能强于原始数据集和困难数据集,这说明逻辑回归和难度系数计算出的难 度得分可以有效判定DLM对简单、困难的识别性能。
研究人员发现,所有DLM针对call、length和pointers的重要性评估是一致性的(认为它们并没有太大的影响)。此外,控制流相关结构(如for、goto、if、jump、switch和while)在不同模型之间的重要性评估有所不同,但大体被分类为困难类型。同时,所有DLM都认为arrays和switch属于简单类型(图 3)。
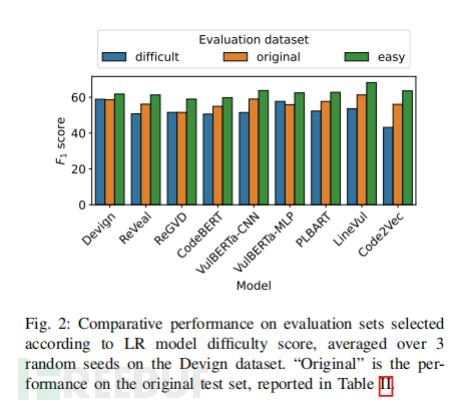
图3
RQ4:增加数据集的大小是否可以提高模型漏洞检测表现?
研究动机:高质量的漏洞检测数据通常难以获取。一般来说,程序自动标记容易导致错误标签。而手动标记耗费大量人力和时间。因此,如果知道这个问题的答案,研究人员可以较准确地评估当前的数据量是否足以训练成功的模型,从而节约成本。
实验设计:通过组合两个数据集(Devign和MSR)生成了一个不平衡数据集(Imbalanced-dataset)和一个平衡数据集(balanced-dataset)。
研究发现:总体来说,所有模型都在增加数据量时提高了性能(图 4)。然而,某些情况下的提升并不明显。10%的平衡数据和100%的平衡数据对比,平均来说并没有性能提升。对于不平衡数据来说,平均提升仅为0.16的F1分数。只有LineVul,每增加10%数据集性能同步稳定增加。而其他模型则是性能波动,代表在一定区间内增加数据不一定带来性能提升。
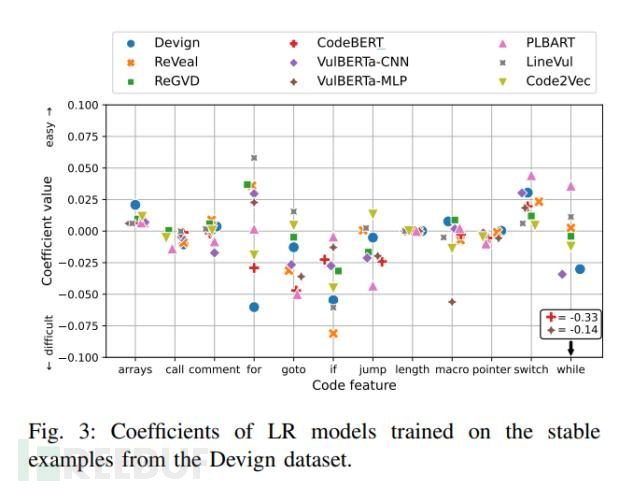
图4
RQ5:训练数据集中的项目构成是否影响模型的性能?如果是,以何种方式影响?
研究动机:不同的项目可能具有不同的代码风格和结构,这可能会影响模型在新项目上的泛化能力。因此,他们希望通过研究不同项目组成对模型性能的影响来了解这个问题。
实验设计:进行两组实验,第一组实验将数据集分为多样数据集(Diverse)和非多样(Non-diverse);第二组实验将数据集分为混合数据集(Mixed)和跨项目(Cross-project)数据集。
实验发现:实验1表明(图5a) ,几乎所有模型(6个模型中的5个)的Diverse数据集性能都弱于单一的Non-diverse数据集。
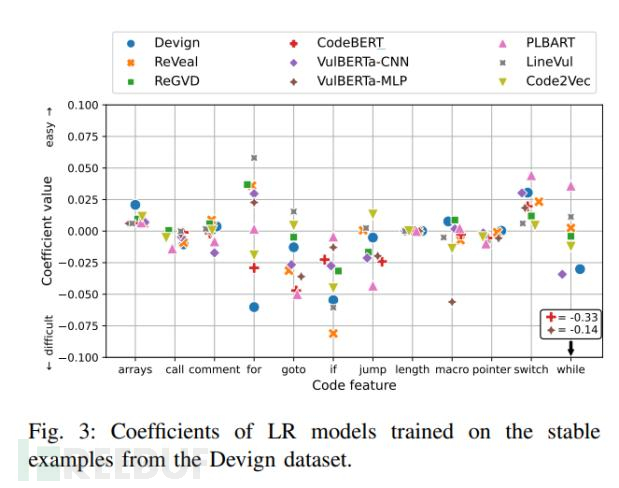
图5
实验2表明(图 5b) ,针对所有模型,混合数据集的性能超过跨项目数据集。这说明了使用同一项目不同数据源确实可以提高同项目的预测性能。
RQ6:模型基于什么源代码信息进行漏洞预测?不同模型之间是否在重要的代码特征上达成一致?
研究动机:LineVul模型达到惊人的91%F1分数,这恐怖数字后的原因是什么?例如,为了检测缓冲区溢出,基于语义的传统程序分析工具会识别相关语句,并对字符串长度和缓冲区大小进行推理。DLM利用的原理有哪些?是否使用了漏洞的语义方面来作出决策?不同的模型是否一致地认为某些特征更重要?
实验设计:使用SOTA深度学习解释工具:GNNExplainer和LIT。GNNExplainer和LIT都提供了一种评分机制来衡量代码特征的重要性。GNNExplainer会为每个节点中的每个标记(token)计算一个分数,而LIT则会为每行代码计算一个分数。对于测试数据集中的每个示例,这些工具会选择得分最高的前10行代码作为最重要的特征集合,并将其用于模型做出决策。
研究发现:尽管不同模型在个别预测上可能存在很大分歧,但它们所使用的代码信息却有很大重叠。所有模型对于重要特征都至少有3行相同代码(表 VI)。其中,Linevul和ReGVD在重要特征集合方面具有最高的相似性,平均共享6.88行代码。而Devign作为唯一基于属性图(property graph)的GNN模型,则与其他模型具有较低的重叠性,与PLBART之间的平均重叠率最低,仅为3.38行。
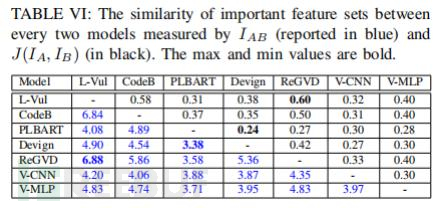
表VI
作者还检查了被所有模型都忽略的漏洞,并且学习了其对应的特征点。结果发现:这些漏洞特定于具体的应用,不具备通用性 ,因此,作者们认为这些漏洞漏报可能只是因为没有足够的训练数据。
有趣的是,Transformer架构模型有时不依赖漏洞的实际原因来进行预测。此结论的支撑是:因为Transformer模型采用固定大小的输入,有时会截断一些关键代码,包括可能是根本原因的代码。但模型仍 然可以获得高分F1分数来预测漏洞。作者展示了一个代码示例(Listing 1),虽然模型的预测结果是正确的,但使用的特征点并不是造成漏洞的实际原因。

这个例子揭示了模型试图捕捉一些特征模式( Pattern),而不是分析值传递、语义等造成错误的实际原因,为了证实这一点,作者让DLM预测和listing 1类似特征的代码。不出意外地,模型误报此代码包含漏洞(Listing 2)。这说明了DLM基于重要特征的规律模式做预测的方式,有时候会带来误报。

- 0 文章数
- 0 关注者