


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

- 关注
正文
“PDF是Portable Document Format的简称,意为“可携带文档格式”,是由Adobe Systems用于与应用程序、操作系统、硬件无关的方式进行文件交换所发展出的文件格式。PDF文件以PostScript语言图象模型为基础,无论在哪种打印机上都可保证精确的颜色和准确的打印效果,即PDF会忠实地再现原稿的每一个字符、颜色以及图象。” — — WIKI
近期作者发现有很多黑客组织在攻击时,喜欢额外放一个PDF作为诱饵文档,用来迷惑用户降低用户的警惕性,殊不知,PDF中也存在着多个字段可以协助我们进行溯源。
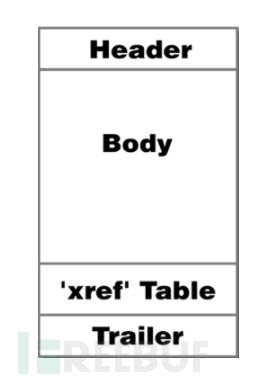
首先,我们先来认识一下PDF文件,PDF结构分为四个部分,分别是:
1. _header_,提供PDF版本号
2. _body_ ,包含页面,图形内容和大部分辅助信息的主体,全部编码为一系列对象。
3. _xref Table_,交叉引用表,列出文件中每个对象的位置便于随机访问。
4. _Trailer_,trailer包括trailer字典,它有助于找到文件的每个部分, 并列出可以在不处理整个文件的情况下读取的各种元数据。
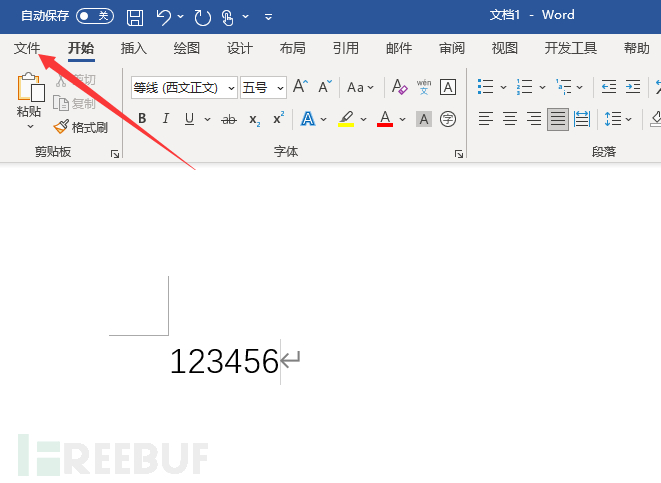
我们可以测试一下,就使用Word来生成一个PDF吧,首先打开Word,点击文件。
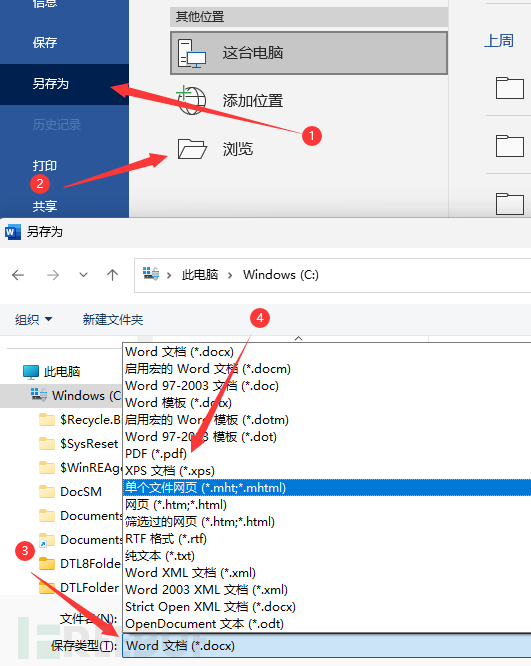
选择另存为,点击浏览,选择保存类型为PDF。
这样我们就生成了一个PDF文件,如下图
接着,我们使用010Editor 打开PDF(首次打开会提示安装一个PDF模板),我们选择点击“安装”模板。
点击同意。
此时我们便使用010Editor解析了PDF文件。
我们先简单看一下文件结构,我们展开“struct PDFHeader sPDFHeader”可以看到这个PDF文件遵守的是PDF1.7的规范。
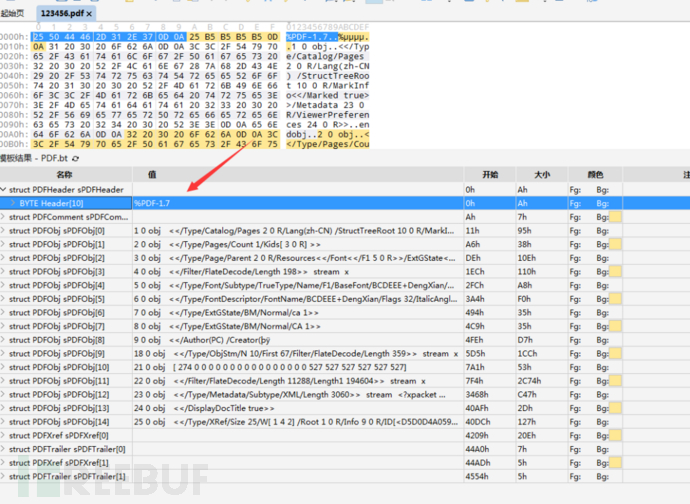
我们接着向下看,找到”PDFObj”中的”Author”对象,可以看到有一部分乱码了,我们定位到到编辑界面去查看。
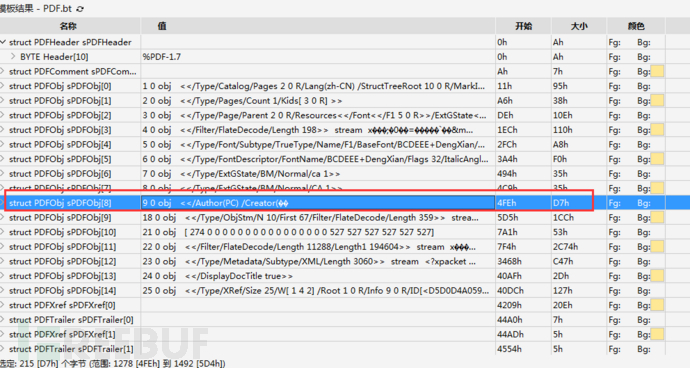
依次点击“Author”对象所在的”PDFObj\[8\]”->”Data\[200\]”,可以看到上面部分的编辑框已经定位到字段位置。
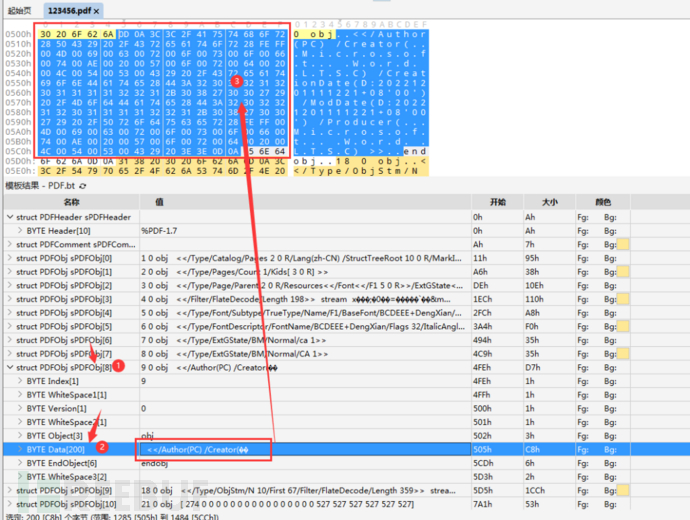
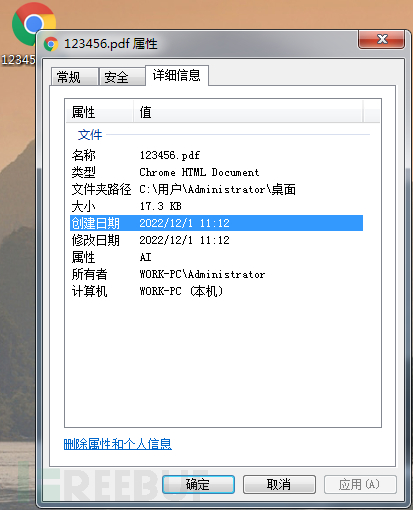
我们可以通过编辑窗看到作者名字是“PC”,使用了“Microsoft Word LTSC”创建了该PDF。
创建的时间是“2022年12月01日11点12分21秒”,时区是“+08:00”。
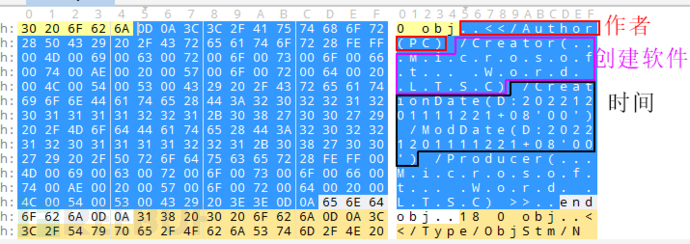
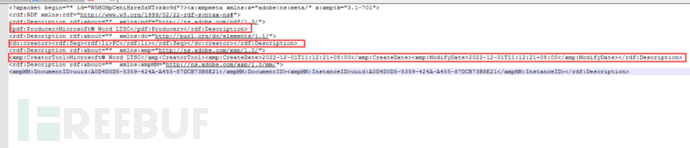
我们接着往下看,发现还有一个“XML”对象。
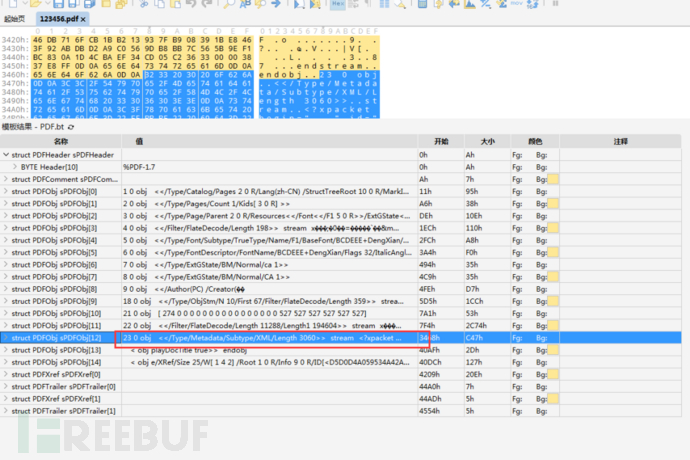
我们依旧在编辑器中定位过去,并将其复制出来。
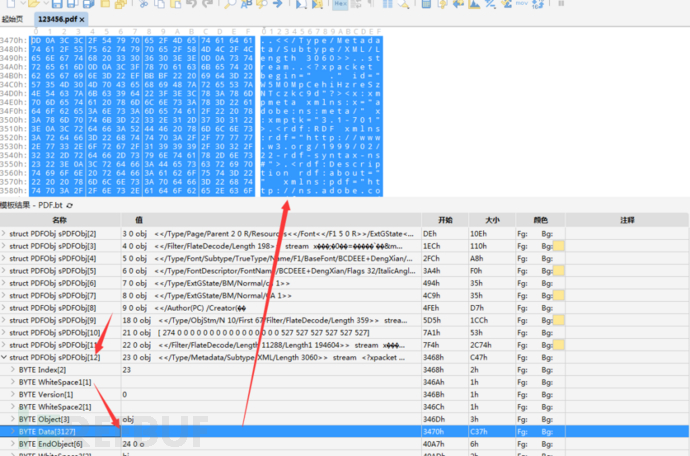
发现我们依旧可以在该字段看到用户、时间、时区、生成软件等信息。
在我们日常的工作中,便可以通过上述方法,对黑客使用的诱饵文档进行分析,并提取其中的关键信息,像是时区、用户名、使用软件等等进行攻击溯源。
PS:补充一点,使用不同软件生成的PDF是会有细微不同的,例如Chrome生成的PDF会附带“UA”信息,其他软件生成PDF也是类似原理。
PPS:作者曾在前些年使用了该方法,溯源到了某黑客团队的,最后,希望大家也能有所收获!
- 0 文章数
- 0 关注者