


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

- 关注
本文作者:Pamela@涂鸦智能安全实验室
基本概念
iptables
iptables 是一个包过滤防火墙,可以对包进行封装、过滤、重定向或者网络地址转换(DNAT、SNAT)、地址伪装、透明代理、访问控制、连接跟踪等功能,它是一个免费开源的软件,工作在用户空间,底层是 netfilter,它工作在内核空间,是内核的一部分,由一些信息包过滤表组成,这些表包含内核用来控制信息包过滤处理的规则集,iptables 在用户空间的插入、修改、删除等操作最终都会反映到内核的规则集中。
Netfilter
Natfilter 是集成到linux内核协议栈中的一套防火墙系统,用户可通过运行在用户空间的工具来把相关配置下发给Netfilter 。
Netfilter 提供了整个防火墙的框架,各个协议基于Netfilter 框架来自己实现自己的防火墙功能。每个协议都有自己独立的表来存储自己的配置信息,他们之间完全独立的进行配置和运行。
内核中包括的防火墙子模块
1、链路层的防火墙模块,对应协议栈是在软桥(bridge)中对报文进行处理。对应用户空间的配置工具是ebtables。
2、网络层中ipv4的防火墙模块,对应协议栈是在Ipv4协议栈中对报文进行处理,对应用户空间的配置工具是iptables
3、网络层中ipv6的防火墙模块,对应协议栈是在Ipv6协议栈中对报文进行处理,对应用户空间的配置工具是ip6tables
4、对ARP处理的防火墙模块,该处理是在协议栈的IPv4部分,但是自己有独立的表来存放自己的配置,对应用户空间的配置工具是arptables。
本篇文主要讲解Netfilter 整体实现和ipv4 协议的防火墙系统。结合其配置工具iptables 的使用来讲解防火墙内部的具体实现,结合在内核源码级上进行详细分析。
原理
Netfilter是Linux2.4引入的一个子系统,它作为一个通用的、抽象的框架,提供一整套的hook函数的管理机制,使得诸如数据包过滤,网络地址转换(NAT)和基于协议类型的链接跟踪成为了可能。
Netfilter在内核中的位置如下:
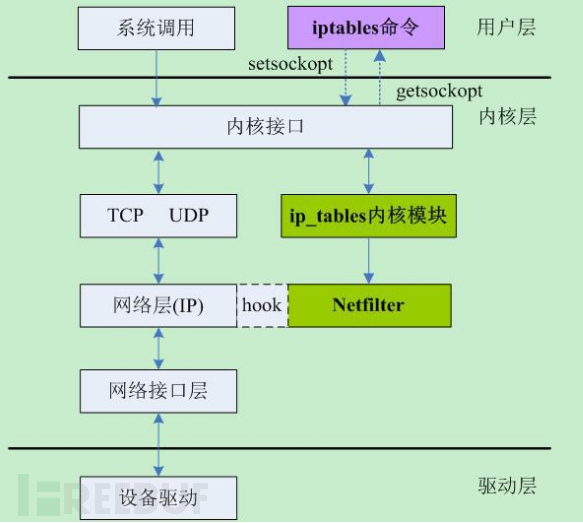
这幅图很直观地反应了用户空间的iptables和内核空间的基于Netfilter的ip_tables模块之间的关系和其通讯方式,以及Netfilter在这其中扮演的角色。Netfilter会在协议栈中的每个数据包的不同地方设置HOOK点。如下所示:
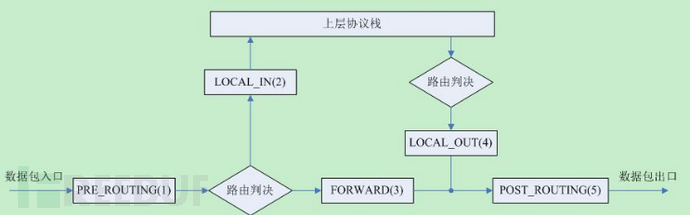
在每个关键点上,有很多已经按照优先级预先注册了的回调函数,这些回调函数形成了一条链。对于每个到来的数据包会依次被那些回调函数处理在根据情况是放行,修改还是丢弃。这也对应了Ipv4防火墙的四大功能:
1、对报文的过滤(对应filter表)
2、对报文的修改(对应mangle表)
3、对会话的连接跟踪(connection track)
4、网络地址转换(NAT)
Ipv4 Netfilter在五个点来拦截报文,每个拦截点对应与iptable的一个chain。对应图中的回调函数及作用依次是:
1、PREROUTING: 在报文路由前进行对报文的拦截
2、INPUT:对到本机的报文进行拦截
3、FORWARD:对需要本机进行三层转发的报文进行拦截
4、OUTPUT:对本机生成的报文进行拦截
5、POSTROUTIN:路由后对报文进行拦截
在Ipv4 Netfilter中,报文有三条处理流程:
发往本机的报文:
![]() 经过本机三层转发的报文
经过本机三层转发的报文
![]() 本机产生往外发送的报文
本机产生往外发送的报文
![]()
每个回调函数必须要向Netfilter框架返回下列几个值:
- NF_ACCEPT , 这个返回值告诉Netfilter该数据包被接受了并且该数据包应当被递交到网络协议栈的下一阶段.
- NF_DROP, 丢弃该数据包,不再传输.
- NF_STOLEN, 模块接管该数据,告诉Netfilter”忘掉”该数据报.该回调函数将会出来该数据包,并且Netfilter应该放弃对该数据包做任何处理.但是,这并不意味着该数据包的资源已经被释放.这个数据包以及它独自的sk_buff数据结构依然有效,只是回调函数从Netfilter获取了该数据包的所有权.
- NF_QUEUE, 对该数据包进程排队(通常用于将该数据报给用户空间的进程进行处理)
- NF_REPEAT, 再次调用该回调函数,应当谨慎使用这个值,以免造成死循环.
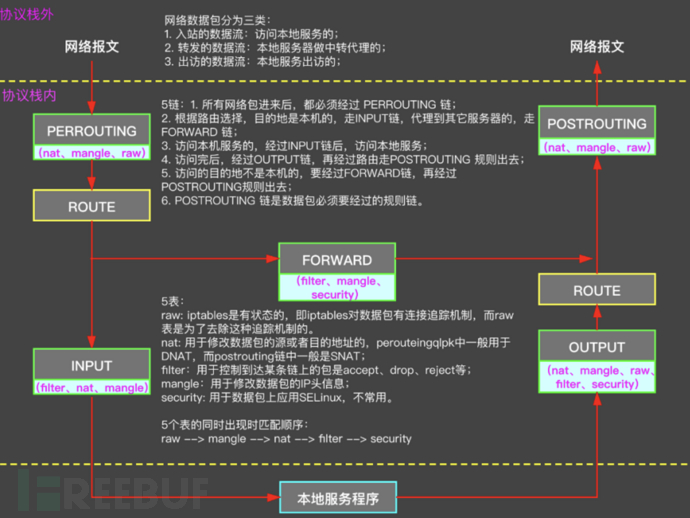
要想Netfilter针对具体的包执行具体的动作,就需要设置规则.根据功能划分,Netfilter分为Filter,NAT,Mangle和RAW四个功能.由这四个功能派生成为了iptables的4张表.
1、filter 表:该表用来存储对报文过滤的配置信息,并且该表是iptables 默认的表,如果命令没有指定表的话,就默认使用该表来存储配置信息。
该表里包含了三个chain,,分别为IPUT,OUTPUT,FORWARD
2、mangle 表,该表用来存储那些对报文修改的配置信息,该表包含了上面所说的五个chain。
3、raw表,直译为原始的意思,该表主要是来在协议栈入口处对原始报文进行跟踪和处理的,该表包含了2个chain,分别为OUTPUT(本机生成的报文进入Ipv4协议栈的入口),PREROUTING(目的ip是到本机的报文进入Ipv4协议栈的入口)。
4、nat表,该表用来存储网络地址转换的相关配置信息。NAT功能分SNAT(源地址转换)和DNAT(目的地址转换),SNAT是在协议栈出口进行转换,DNAT是在协议栈入口进行转换。该表包含了三个chain,分别为 DNAT的PREROUNGIN和OUTPUT,SNAT的POSTROUTIN。
iptables规则库管理
iptables的规则被存储在不同的链中,相当与一个规则库,当我们修改玩规则,用iptables-save命令进行存储。iptables 规则就是当数据包“流经”系统时,数据包符合什么样的条件,就做出什么样的策略进行处理。这些规则中包括源地址、目的地址、源端口、目的端口、传输协议、服务类型等,当数据包与规则匹配时,iptables根据定义好的规则进行 accept、drop、reject、jump、queue等处理。
iptables 规则作用在 IP 层,IP 层有5个hook点的位置,其实就对应iptables的 5 条链:INPUT、OUTPUT、PREROUTING、POSTROUTING、FORWARD。
RAW表
RAW表之使用PREOUTING和OUTPUT链,具有最高优先级,可以对收到的数据包在连接跟踪之前处理.RAW表主要作用就是运行我们对某些也定的数据包打上 NOTRACK 标记,被打上了NOTRACK标记的数据包将跳过NAT表和 ip_conntrack处理,即不再做地址转换和数据包的链接跟踪处理了.如大量访问的web服务器,可以让80端口不再让iptables做数据包的链接跟踪处理,以提高用户的访问速度.
iptables -t raw -A PREOUTING -p tcp --dport 80 -j NOTRACK
iptables -t raw -A PREOUTING -p tcp --sport 80 -j NOTRACK
iptables -A FORWARD -m state --state UNTRACKED -j ACCEPT
Mangle表
Mangle表主要用于修改数据包的TOS(Type of Service,服务类型),TTL(Time To Live,生存周期),以及为数据包设置Mark标记,以实现QoS(Quality Of Service,服务质量)调整以及策略路由等应用,mange表对应的内核模块为iptables_mangle.由于需要相应的路由设备支持,应用并不广泛.注意Mark并没有真正地改动数据包,只是在内核空间为包设了一个标记.
nat表
此表仅用于NAT,也就是转换包的源或目标地址.注意,就像我们前面说过的,只有流的第一个包会被这个链匹配,其后的包会自动被做相同的处理.实际的操作分为三类: DNAT,SNAT, MASQUERADE
- DNAT 操作主要用在一种这样的情况,你有一个合法的IP地址,要把对防火墙的访问重定向到其他的机子上(比如DMZ).也就是说,我们改变的是目的地址,以使包能从路由到某台机器.
- SNAT 改变包的源地址,这在极大程度上可以隐藏你的本地网络或者DMZ等.一个很好的来自是我们知道防火墙的外部地址,但必须用这个地址替换本地网络地址.有了这个操作,防火墙就能自动地对包做SNAT和De-SNAT(就是反向的SNAT),以使LAN能连接到Internet.
- MASQUEREAD,地址伪装, 算是snat中的一种特例,可以实现自动化的snat.在iptables中有着和SNAT相近的效果,但也有一些区别,但使用SNAT的时候,出口ip的地址范围可以是一个,也可以是多个.但是对于SNAT,不管是几个地址,必须明确的指明要SNAT的ip,假如当前系统用的是ADSL动态拨号方式,那么每次拨号,出口ip就会改变,而且改变幅度很大,不一定是某个范围内的地址.这个时候如果按照现在的方式来配置iptables就会出现问题了,因为每次拨号后,服务器的地址都会变化 ,而iptables规则内的ip是不会随着自动变化的,每次地址变化后都必须手工修改一次iptables,把规则里面的固定ip修改成新的ip,这样是非常不好用的. MASQUEREAD 就是针对场景设计的,他的作用是,从服务器的网卡上,自动话去当前IP地址来做NAT. 如
iptables -t nat -A POSTROUTING -s 10.8.0.0/255.255.255.0 -o eth0 -j MASQUEREAD. 按照上面的配置, 不用制定SNAT的目标IP, 不管现在eth0的出口获得了怎样的动态IP, MASQUEREAD会自动读取eth0现在的IP地址然后做SNAT出去,这样就实现了很多的动态SNAT地址转换.
filter表
filter表用来过滤数据包,我们可以在任何时候匹配包并过滤他们.我们就是在这里根据包的内容对包做DROP或ACCEPT的.当然,我们也可以在其他地方做些过滤,但是这个表才是设计用来过滤的.每个表分别作用在netfilter框架中的不同的Hook点上.在iptables,这些Hook点被称为链.他们的对应关系如下:
- filter表:INPUT,FORWARD,OUTPUT
- nat表:PREROUTING,POSTROUTING
- mangle表:PREROUTING,INPUT,FORWARD,OUTPUT,POSTROUTING
- raw表:PREROUTING,OUTPUT
以上4个表,按照处理优先级从高到底,依次是: RAW>Mangle>NAT>Filter
Netfilter与iptables的关系
netfilter组件也称为 内核空间(kernelspace),是内核的一部分,由一些信息包过滤表组成,这些表(filter,nat,mangle,raw)包含内核用来控制信息包过滤处理的规则集iptables组建是一种工具,也称为用户空间(userspace),它使插入,修改和除去信息包过滤表中的规则变得容易.通过使用用户空间,可以构建自己的定制规则,这些规则存储在内核空间的信息包过滤表中.这些规则具有目标,它们告诉内核对来自某些源,前往某些目的地或具有某些系诶类型的信息包做些什么.如果某个信息包与规则匹配,那么使用目标ACCEPT运行该信息包通过,还可以使用目标DROP或REJECT来阻塞并杀死信息包.对于可对信息包执行的其他操作,还有许多其他的目标。
iptables规则库管理
iptables的规则被存储在各种不同的链中,相当与一个规则库,当我们修改玩规则可用iptables-save命令存储.
iptables命令格式
iptables的命令结构是: iptables [-t table] command [chain] [rules] [-j target]
- t Table,Table对应的四张表是filter,nat,mangle以及raw
- command
- A 在指定链的末尾添加(append)一条新的规则
- D 删除(delete)指定链中的某一条规则,可以按照规则序号和内容删除
- I 在指定链中插入(insert)一条新规则,默认在第一行添加
- R 修改,替换(replace)指定链中的某一条规则,可以按照规则序号和内容替换
- L 列出(list)指定链中所有的规则进行查看
- E 重命名用户定义的链,不改变链本身
- F 清空(flush)
- N 新建(new-chain) 一条用户自己定义的规则链
- X 删除制定表中用户自定义的规则链(delete-chain)
- P 设置指定链的默认策略(policy)
- Z 将所有表的所有链的字节和数据包计数清零
- n 使用数字形式(numberic)显示输出结果
- v 查看规则表详细信息(verbose)的信息
- V 查看版本(version)
- h 获取帮助(help)
- chain,链名称,指 INPUT链,OUTPUT链,FORWARD链,PRETOUTING链,POSTROUTING链
- rules,规则/限定条件
- target,动作,常见的包括 ACCEPT(通过),DROP(丢弃),REJECT(丢弃并返回发送端一个Destination Unreachable的ICMP封包)
示例命令
- 将进入到本机的ICMP报文全部丢弃,禁止ping
iptables -t filter -A INPUT -p icmp -j DROP - 在INPUT链中第二条规则位置插入一条规则(运行TCP协议通过)
iptables -t filter -I INPUT 2 tcp -j ACCEPT - 删除INPUT链中的第二条规则
iptables -t filter -D INPUT 2 - 将192.168.0.200进入本机的icmp协议包都丢弃
iptables -A INPUT -p icmp -s 192.168.0.200 -j DROP - 不允许192.168.0.200主机通过本机的DNS服务来执行域名解析
iptables -A INPUT -p udp -s 192.168.0.200 --dport 53 -j REJECT - 允许192.168.1.0/24 网段的主机向本机192.168.0.1提出任何服务请求
iptables -A INPUT -p all -s 192.168.1.0/24 -d 192.168.0.1 -j ACCEPT - 允许客户端主机从eth1这个接口访问本机的SSH服务
iptables -A INPUT -p tcp -i eth1 --dport 22 -j ACCEPT - 不允许本机的应用程序从eth0接口发送出去数据包去访问edu.uuu.com.tw以外的网站
iptables -A OUTPUT -o th0 -p tcp -d ! edu.uuu.com.tw --dport 80 -j REJECT - 不允许本企业内部的主机访问企业以外的任何网站
iptable -A FORWARD -i eth1 -o eth0 -p tcp --dport 80 -j DROP - 将FORWARD链的默认策略设置为DROP
iptables -t filter -p FORWAED DROP
规则匹配过程
实际应用中每个链中包含的规则数量不尽相同,无论那一个FIlter表其规则匹配过程都是 First Match, 即优先执行. 当我们在防火墙上添加的规则被逐条加入到INPUT链中,被顺序编号,例如rule1,rule2等.当封包进入INPUT链之后,Filter机制会以这个数据包的特征从INPUT链内的第一条规则逐一向下匹配.如果数据包遇到第一条规则允许通过,那么这个数据包就会进入到本地进程httpd,而不管下面的rule2,rule3.相反如果第一条规则说要丢弃,即使是rule2规则运行通过也不起作用,这就是 First Match原则.在使用规则时要注意First Match原则,尽量减少不必要的规则.因为当数据包进入防火墙之后会在特定的链中逐一对比,规则条数越多,数据包在防火墙中滞留的时间就越长,防火墙性能就会降低.
Netfilter原理
Netfilter hook点的定义
对于每种类型的协议,数据包丢会一次按照hook点的方向进行传输,每个hook点上Netfilter又按照优先级挂了很多hook函数.这些hook函数就是用来处理数据包的.Netfilter使用NF_HOOK(include/linux/netfilter.h)宏在协议栈内部切入到Netfilter框架中.在2.6内核中定义如下:
#define NF_HOOK(pf, hook, skb, indev, outdev, okfn) \\
NF_HOOK_THRESH(pf, hook, skb, indev, outdev, okfn, INT_MIN)
#define NF_HOOK_THRESH(pf, hook, skb, indev, outdev, okfn, thresh) \\
({int __ret; \\
if ((__ret=nf_hook_thresh(pf, hook, &(skb), indev, outdev, okfn, thresh, 1)) == 1)\\
__ret = (okfn)(skb); \\
__ret;})
关于宏NF_HOOK各个参数的解释说明:
- pf: 协议族名称,Netfilter架构统一可以用于IP层之外,因此这个变量还可以有诸如PF_INET6,PF_DECent等名字. 在TCP建立 中已经说明了目前所有的协议簇.
- hook: HOOK点的名字,对于IP层,就是PREROUTING,INPUT,FORWARD,OUTPUT,POSTROUTING 五个值
- skb: struct sk_buff是存储网络包的重要的数据结构
- indev: 数据包进来的设备 以struct net_device结构表示
- outdev: 数据包出去的设备, 以struct net_device 结构表示
- okfn: 函数指针, 当所有的该HOOK点的所有等级函数调用完后,转而走此流程
NF_HOOK_THRESH宏想对于NF_HOOK仅仅只是增加了一个thresh参数,这个参数就是用来制定该宏通过该宏去遍历钩子函数时的优先级.同时, 该宏内部又调用了nf_hook_thresh函数.
static inline int nf_hook_thresh(int pf, unsigned int hook,
struct sk_buff **pskb,
struct net_device *indev,
struct net_device *outdev,
int (*okfn)(struct sk_buff *), int thresh,
int cond)
{
if (!cond)
return 1;
#ifndef CONFIG_NETFILTER_DEBUG
if (list_empty(&nf_hooks[pf][hook]))
return 1;
#endif
return nf_hook_slow(pf, hook, pskb, indev, outdev, okfn, thresh);
}
该函数只是增加了一个cond参数,该参数为0则放弃遍历,直接返回1. 为1 则执行nf_hook_slow按照okfn定义的优先级去遍历钩子函数.在net/netfiltr.core.h文件中定义了一个二维的结构体数组, 用来存储不同协议钩子点的回调处理函数.struct list_head nf_hooks[NPROTO][NF_MAX_HOOKS];我们以AF_INET/PF_INET为例,它的序号是2,对应的钩子函数就是:
- PRE_ROUTING nf_hooks[2][0]
- LOCAL_IN nf_hooks[2][1]
- FORWARD nf_hooks[2][2]
- LOCAL_OUT nf_hooks[2][3]
- POST_ROUTING nf_hooks[2][4]
Netfilter的执行过程
NF_IP_PRE_ROUTING
net/ipv4/ip_input.c里的ip_rcv函数.该函数主要用来处理网络层报文的入口函数.它到Netfilter框架的切入点为:
NF_HOOK(PF_INET,NF_IP_PRE_ROUTING,skb,dev,NULL,ip_rcv_finish)
如果当前收到了一个IP报文(PF_INET),吧么就把这个报文传到Netfilter的NF_IP_PRE_ROUTING过滤点,调用nf_hook_slow()函数在过滤点(nf_hooks[2][0])是否已经有人注册了相关的用于处理数据包的钩子函数.如果有,则遍历nf_hooks[2][0]去寻找匹配的match和相应的target.根据返回到Netfilter框架中的值来进一步决定该如何处理该数据包(由钩子模块处理还是由ip_rcv_finish函数继续处理还是交由ip_rcv_finish函数继续处理).
referer:net/netfilter/core.c#L110
/* Returns 1 if okfn() needs to be executed by the caller,
* -EPERM for NF_DROP, 0 otherwise. */
int nf_hook_slow(int pf, unsigned int hook, struct sk_buff **pskb,
struct net_device *indev,
struct net_device *outdev,
int (*okfn)(struct sk_buff *),
int hook_thresh)
{
struct list_head *elem;
unsigned int verdict;
int ret = 0;
/* We may already have this, but read-locks nest anyway */
rcu_read_lock();
elem = &nf_hooks[pf][hook];
next_hook:
verdict = nf_iterate(&nf_hooks[pf][hook], pskb, hook, indev,
outdev, &elem, okfn, hook_thresh);
if (verdict == NF_ACCEPT || verdict == NF_STOP) {
ret = 1;
goto unlock;
} else if (verdict == NF_DROP) {
kfree_skb(*pskb);
ret = -EPERM;
} else if ((verdict & NF_VERDICT_MASK) == NF_QUEUE) {
NFDEBUG("nf_hook: Verdict = QUEUE.\\n");
if (!nf_queue(pskb, elem, pf, hook, indev, outdev, okfn,
verdict >> NF_VERDICT_BITS))
goto next_hook;
}
unlock:
rcu_read_unlock();
return ret;
}
# 调用nf_iterate()遍历去选找所有满足要求的hook函数.
# referer:net/netfilter/core.c#L66
unsigned int nf_iterate(struct list_head *head,
struct sk_buff **skb,
int hook,
const struct net_device *indev,
const struct net_device *outdev,
struct list_head **i,
int (*okfn)(struct sk_buff *),
int hook_thresh)
{
unsigned int verdict;
/*
* The caller must not block between calls to this
* function because of risk of continuing from deleted element.
*/
list_for_each_continue_rcu(*i, head) {
// 根据优先级查找双向链表nf_hooks[][],找到对应的回调函数来处理数据包
struct nf_hook_ops *elem = (struct nf_hook_ops *)*i;
if (hook_thresh > elem->priority)
continue;
/* Optimization: we don't need to hold module
reference here, since function can't sleep. --RR */
verdict = elem->hook(hook, skb, indev, outdev, okfn);
if (verdict != NF_ACCEPT) {
#ifdef CONFIG_NETFILTER_DEBUG
if (unlikely((verdict & NF_VERDICT_MASK)
> NF_MAX_VERDICT)) {
NFDEBUG("Evil return from %p(%u).\\n",
elem->hook, hook);
continue;
}
#endif
if (verdict != NF_REPEAT)
return verdict;
*i = (*i)->prev;
}
}
return NF_ACCEPT;
}
NF_IP_FORWARD
net/ipv4/ip_forward.c中的ip_forward函数,它的切入点是:
NF_HOOK(PF_INET,NF_IP_FORWARD,skb,skb->dev,rt->u.dst.dev,ip_forward_finish)
在经过路由抉择后,所有需要本机转发的报文都会交由ip_forward函数处理.这里,该函数由NF_IP_FORWARD过滤点切入到Netfilter框架,在nf_hooks[2][2]过滤点进行匹配查找,最后根据返回值来确定ip_forward_finish函数的执行情况.
NF_IP_POST_ROUTING
net/ipv4/ip_output.c中的ip_output函数,它切入Netfilter框架的切入点是:
NF_HOOK_COND(PF_INET,NF_IP_POST_ROUTING,skb,NULL,dev,ip_finsish_output,!(IPCB(skb)->flasg & IPSKB_REROUTED));
如果需要陷入Netfilter框架则数据包会在nf_hooks[2][4]过滤点去进行匹配查找.
NF_IP_LOCAL_IN
在net/ipv4/ip_input.c中的ip_local_deliver函数处理所有目的地是本机的数据包.其切入函数是:
NF_HOOK(PF_INET,NF_IP_LOCAL_IN,skb,skb-<dev,NULL,ip_local_deliver_finish);
发给本机的数据包,首先全部回去nf_hooks[2][1]过滤点上检测是否有相关数据包的回调处理函数,如果有则执行匹配和动作,最后根据返回值执行ip_local_dliver_finish函数.
NF_IP_LOCAL_OUT
net/ipv4/ip_output.c中的ip_push_pending_frames函数. 该函数是将IP分片重组成完整的IP报文,然后发送出去.进入Netfilter框架的切入点为:
NF_HOOK(PF_INET, NF_IP_LOCAL_OUT, skb, NULL, skb->dst->dev, dst_output);
对于所有从本机出发的报文都会首先去Netfilter的nf_hooks[2][3]过滤点去过滤.一般情况下来说,不管是路由器还是PC端,很少有人限制自己机器发出去的报文.因为这样做的潜在风险也是显而易见的,往往会因为一些不恰当的设置导致某些服务失效,所以在这个过滤点上拦截的数据包的情况非常少.当然也不排除特殊情况.
连接跟踪
连接跟踪系统使得iptables基于连接上细纹而不是单个包来作出规则判断,给iptables提供了有状态操作的功能.跟踪系统包将和已有的链接继续你比较,如果包所属的连接已经存在就更新连接状态,否则就创建一个新连接.如果 raw table的某个chain 对包比较为目标是 NOTRACK,那这个包会跳过链接跟踪系统.
连接的状态
连接跟踪系统中的连接状态有:
- NEW: 如果到达的包关联不到任何已有的链接,但包是合法的,就为这个包创建一个新连接.对 面向连接(connection-aware)的协议例如TCP以及非面向连接的(connectionless)的协议例如UDP都适用.
- ESTABLISHED: 当一个连接收到应答方向的合法包时,状态从NEW变成ESTABLISHED. 对TCP这个合法包其实就是SYN/ACK包;对UDP和ICMP是源和目的IP与原包相反的包
- REALTED: 包不属于已有的连接,但是和已有的连接有一定的关系,这可能是辅助连接(helper connection),例如FTP数据传输连接,或者是其他协议试图建立链接时的ICMP应答包.
- INVALID: 包不属于已有连接,并且因为某些元应不用来创建一个新连接,例如无法识别,无法路由等等.
- UNTRACKED: 如果在raw table中标记为目标是UNTRACKED,这个包将不会进入到连接跟踪系统.
- SNAT: 包的元地址被NAT修改之后会进入的虚拟状态.连接跟踪系统据此在收到反向包时对地址做方向转换.
- DNAT: 包的目的地址被NAT修改之后会进入的虚拟状态.连接跟踪系统据此在收到反向包是对地址做反向转换.
这些状态可以定位到连接生命周期内部,管理员可以编写出更加细粒度,适用范围更大,更安全的规则.下篇文章会对这些状态进行详细地讲解。
漏洞悬赏计划:涂鸦智能安全响应中心(https://src.tuya.com)欢迎白帽子来探索。
招聘内推计划:涵盖安全开发、安全测试、代码审计、安全合规等所有方面的岗位,简历投递sec@tuya.com,请注明来源。
参考
netfilter/iptables 简介(一)洞悉linux下的Netfilter&iptables:什么是Netfilter?Netfilter/Iptables入门Netfilter/iptables简介Linux数据包路由原理、Iptables/netfilter入门学习
- 0 文章数
- 0 关注者