


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
 本文由
FreeBuf_292258 创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
本文由
FreeBuf_292258 创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
前言
众所周知,cobalt strike作为一个大杀器,已被各种渗透测试团队和真实攻击团队大范围使用,因其功能完善、配置灵活性高等特点,在满足攻击需要和躲避检测方面都有着不俗的表现。
其应用的广泛性给各大防御团队带来巨大的防御和检测成本。虽然终端行为的严格监控,可以有效的发现各种高危行为,进而回溯到cobalt strike木马,但因终端行为检测存在滞后性(进入终端后不做动作,或仅作低危操作,终端监控系统很难发现),让各大公司安全团队无法接受,所以大家纷纷盯上了网络通信检测,想从网络通信角度迅速精准发现cobalt strike入侵。
分析cobalt strike的常用网络通信协议,我们关注如下三种http、https、dns。其中http、dns因其通信特征均为明文,各种检测逻辑已经满天飞,应用到各种开源IDS设备就可以有效检测,但https却成为难于攻克的难题。
cobalt strike利用https加密机制,将通信特征隐藏,让流量检测设备无能为力,据笔者所知,当前针对https的检测仅能针对已公开的ioc,例如证书信息、已出现过被安全人员分析后的https包等已知特征来检测,但均无法对未出现过的https进行进行检测。而在实际攻击场景,cobalt strike配置https通信非常方便,攻击者每次攻击均重新配置(更改证书、域名、通信特征等),让这种基于现有ioc检测https通信的方式有效性微乎其微。
那如何才能检测cobalt strike的https通信呢?下面咱们一起来探索下,在机器学习大热的趋势下,尝试用机器学习的方法对cobalt strike的https通信进行检测。
注:该方法仅是笔者的初步探索,还未达到生产环境要求,后续还在逐步研究,欢迎探讨。
分析问题:
想利用机器学习,我们要先分析我们面临的问题,我们是想通过机器学习分析cobalt strike的通信包,找出通信规律,然后用这个规律对新的通信包进行检测。 那从哪找我们需要的规律呢?
上面说过,cobalt strike可以通过配置文件,实现通信特征的灵活变动,但我们发现这个变动仅仅是针对http包层次的,http底层的tcp层呢?
理论上是没有变化的,因为无论攻击者如何配置http通信特征,tcp层的特征都是独立于攻击者的配置的,是软件和操作系统本身决定的。这样,我们就有了找规律的方向了。
我们怎么利用机器学习找通信规律和利用规律检测呢?
通常,实现机器学习检测需要如下几步:
原始数据采集(网络通信包)
转换为机器学习能理解的数据-
通过机器学习得出通信规律(检测规则)
使用规则部署检测系统
传入通信包特征,检测是否为cobalt strike木马通信
转换为机器学习的术语,对应的是:
原始数据采集
特征工程
机器学习建模
模型发布
在线预测(或实时预测、在线推理)
下面我们从这5步骤逐个探讨:
原始数据采集
这是第一步,也是最终容易理解的,机器学习和人学习一样,你要告诉机器什么是好,什么是坏,她才能形成一个模式规律,才能用于后续判定好坏。
这里我们需要两部分数据,一是哪些人是坏人(cobalt strike),他们有什么特征?二是哪些人是好人,他们有什么特征?
1.cobalt strike恶意通信的数据(为了第一时间发现恶意通讯,我们抓心跳包,无需抓指令包)
2.其他正常通信的数据包,这个无需解释,这是“好人”
这里有个比较麻烦的地方,我们打开cobalt strike病毒,用wireshark抓包,很难区分出哪个tcp session是木马的通信,我尝试过用https的server name找到https的通信域名,然后再逐条追踪tcp流程的方法。
可这个方法太low了,尤其是https通信多的时候,重复操作到崩溃。
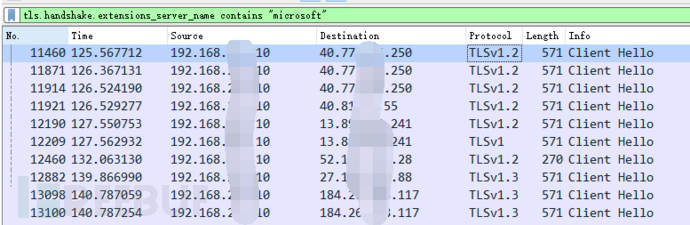
所以我们需要神器:Microsoft Network Monitor 3.4 https://www.microsoft.com/en-us/download/details.aspx?id=4865
直接抓对应的cobalt strick木马病毒进行的包,选中全部的包,然后另存为,保存已选择的包为cap,最后用wireshark转换格式为pcap。
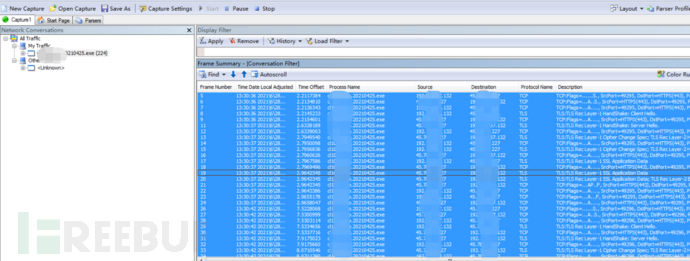
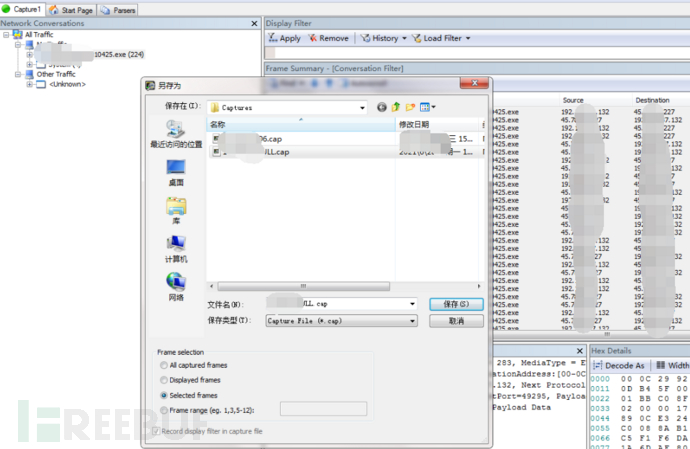
正常通信包就不细说了,直接用wireshark抓一段时间的包就行了,这样我们就有了两个通信包,木马通信包:black.pcap和正常通信包:white.pcap
注意:这里所有通信包,都要用wireshark保存为标准的pcap格式,为下一步做准备,切记。
特征工程
这是第二步骤,所谓的特征工程,前面已经解释过了,就是把原始数据转换为机器学习能理解的数据。但这个转换并不是简单的直接提取。
根据抓包结果,我们可以得到如下6个字段的信息

但这些信息对机器学习来说是没有什么意义的,因为这些不是特征,那什么是特征呢?根据业内通用定义,我举例几个,给大家感性的认识下tcp的通信特征:
持续时间、流字节率,即每秒传输的数据包字节数、流包率,即每秒传输的数据包数、每秒前向包的数量、正向数据包的总大小、数据包在正向的平均大小、数据包正向标准偏差大小、流的最大长度、最小包到达间隔时间等等
好,我们知道我们需要什么了,那接下来怎么把我们的TCP通信包转成对应的特征,这里我们需要cicflowmeter,一款流量特征提取工具,该工具输入pcap文件,输出pcap文件中包含的数据包的特征信息,共80多维(其中有用的76维,其他为源、目的、端口、时间等信息),以csv表格的形式输出。这个工具,网上的各种介绍都是基于java版本的,需要用JetBrains打开,然后经过繁琐的配置才可以运行,对用python搞机器学习的同学非常不友好,所以今天我们就来看看python版的,但也有无数的坑要踩一踩:
1、安装,一切顺利,开开心心。

2、运行使用,报错!
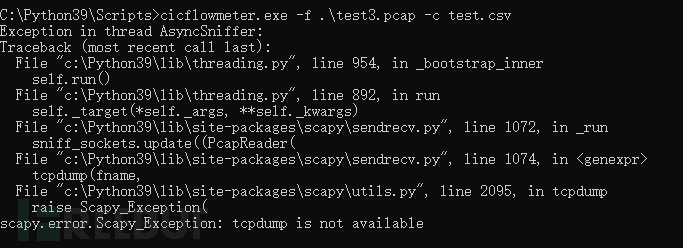
这里研究了好久,发现是scapy版本不对!(参考地址:https://gitlab.com/hieulw/cicflowmeter)

拆卸新版本,安装旧版本pip3.9.exe install scapy=2.4.3
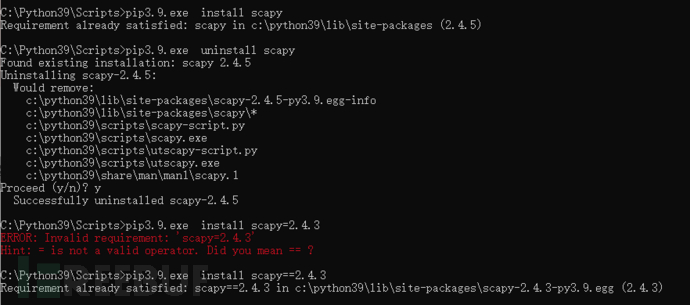
继续运行,又报错!这个很清晰了,需要windump程序。
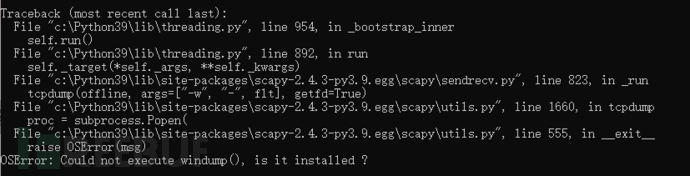
下载windump到python script目录,运行,但依然报错,最后调整windump已兼容模式运行(运行系统是win10 2020H2, 改软件兼容模式为xp sp3),完美解决!
运行成功,提取数据ok
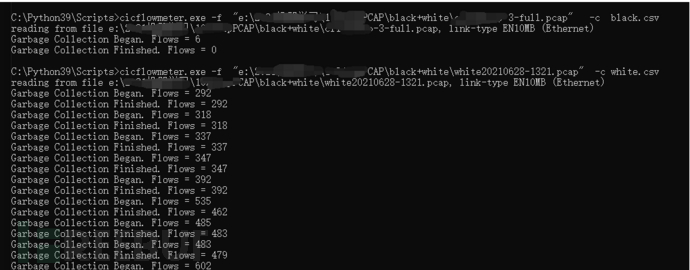
提取到的csv数据如下:

特征字段对应关系如下:
id | 字段名 | 说明 |
1 | flow_duration | 流持续时间 |
2 | flow_byts_s | 流字节率,即每秒传输的数据包字节数 |
3 | flow_pkts_s | 流包率,即每秒传输的数据包数 |
4 | fwd_pkts_s | 每秒前向包的数量 |
5 | bwd_pkts_s | 每秒后向包的数量 |
6 | tot_fwd_pkts | 在正向上包的数量 |
7 | tot_bwd_pkts | 在反向上包的数量 |
8 | totlen_fwd_pkts | 正向数据包的总大小 |
9 | totlen_bwd_pkts | 反向数据包的总大小 |
10 | fwd_pkt_len_max | 包在正向上的最大大小 |
11 | fwd_pkt_len_min | 包在正向上的最小大小 |
12 | fwd_pkt_len_mean | 数据包在正向的平均大小 |
13 | fwd_pkt_len_std | 数据包正向标准偏差大小 |
14 | bwd_pkt_len_max | 包在反向上的最大大小 |
15 | bwd_pkt_len_min | 包在反向上的最小大小 |
16 | bwd_pkt_len_mean | 数据包在反向的平均大小 |
17 | bwd_pkt_len_std | 数据包反向标准偏差大小 |
18 | pkt_len_max | 流的最大长度 |
19 | pkt_len_min | 流的最小长度 |
20 | pkt_len_mean | 流的平均长度 |
21 | pkt_len_std | 流长度的方差 |
22 | pkt_len_var | 最小包到达间隔时间 |
23 | fwd_header_len | 用于前向方向上的包头的总字节数 |
24 | bwd_header_len | 用于后向方向上的包头的总字节数 |
25 | fwd_seg_size_min | 在正方向观察到的最小segment尺寸 |
26 | fwd_act_data_pkts | 在正向方向上具有至少1字节TCP数据有效负载的包 |
27 | flow_iat_mean | 两个流之间的平均时间 |
28 | flow_iat_max | 两个流之间的最大时间 |
29 | flow_iat_min | 两个流之间的最小时间 |
30 | flow_iat_std | 两个流之间标准差 |
31 | fwd_iat_tot | 在正向发送的两个包之间的总时间 |
32 | fwd_iat_max | 在正向发送的两个包之间的最大时间 |
33 | fwd_iat_min | 在正向发送的两个包之间的最小时间 |
34 | fwd_iat_mean | 在正向发送的两个包之间的平均时间 |
35 | fwd_iat_std | 在正向发送的两个数据包之间的标准偏差时间 |
36 | bwd_iat_tot | 反向发送的两个包之间的总时间 |
37 | bwd_iat_max | 在反向发送的两个包之间的最大时间 |
38 | bwd_iat_min | 反向发送的两个包之间的最小时间 |
39 | bwd_iat_mean | 反向发送的两个数据包之间的平均时间 |
40 | bwd_iat_std | 在正向发送的两个数据包之间的标准偏差时间 |
41 | fwd_psh_flags | 在正向传输的数据包中设置PSH标志的次数(UDP为0) |
42 | bwd_psh_flags | 在反向传输的数据包中设置PSH标志的次数(UDP为0) |
43 | fwd_urg_flags | 在正向传输的数据包中设置URG标志的次数(UDP为0) |
44 | bwd_urg_flags | 反方向数据包中设置URG标志的次数(UDP为0) |
45 | fin_flag_cnt | 带有FIN的包数量 |
46 | syn_flag_cnt | 带有SYN的包数量 |
47 | rst_flag_cnt | 带有RST的包数量 |
48 | psh_flag_cnt | 带有PUSH的包数量 |
49 | ack_flag_cnt | 带有 ACK的包数量 |
50 | urg_flag_cnt | 带有URG的包数量 |
51 | ece_flag_cnt | 带有ECE的包数量 |
52 | down_up_ratio | 下载和上传的比例 |
53 | pkt_size_avg | 数据包的平均大小 |
54 | init_fwd_win_byts | 在正向的初始窗口中发送的字节数 |
55 | init_bwd_win_byts | 在反向的初始窗口中发送的字节数 |
56 | active_max | 流在空闲之前处于活动状态的最大时间 |
57 | active_min | 流空闲前激活的最小时间 |
58 | active_mean | 流在空闲之前处于活动状态的平均时间 |
59 | active_std | 流在空闲之前处于活动状态的标准偏差时间 |
60 | idle_max | 流在激活之前空闲的最大时间 |
61 | idle_min | 流在激活之前空闲的最小时间 |
62 | idle_mean | 流在激活之前空闲的平均时间 |
63 | idle_std | 流量在激活前处于空闲状态的标准偏差时间 |
64 | fwd_byts_b_avg | 在正向上的平均字节数块速率 |
65 | fwd_pkts_b_avg | 在正向方向上数据包的平均数量 |
66 | bwd_byts_b_avg | 在反向上的平均字节数块速率 |
67 | bwd_pkts_b_avg | 在反向方向上数据包的平均数量 |
68 | fwd_blk_rate_avg | 在正向方向上平均bulk速率 |
69 | bwd_blk_rate_avg | 在反向方向上平均bulk速率 |
70 | fwd_seg_size_avg | 观察到的前向方向上数据包的平均大小 |
71 | bwd_seg_size_avg | 观察到的后向方向上数据包的平均大小 |
72 | cwe_flag_count | 带有CWE的包数量 |
73 | subflow_fwd_pkts | 在正向子流中包的平均数量 |
74 | subflow_bwd_pkts | 反向子流中数据包的平均数量 |
75 | subflow_fwd_byts | 子流在正向中的平均字节数 |
76 | subflow_bwd_byts | 子流在反向中的平均字节数 |
最后,将黑数据和白数据合并,并打上标签(文件名:文件名:white+black.csv,标签类为hacked,黑为1,白为0)

这里还有一个细节,我们怎么从这些特征中选择我们需要的特征?这个在机器学习领域也是有选择方法的,如根据各个特征之间的关联度、根据特征对最终结果的影响度等,不过我们这里不讨论这么复杂,我们全要!
机器学习建模
第三步,这个步骤我们可用python的Numpy、Pandas、sklearn、seaborn等模块,通过代码实现,但这里我们不写代码(其实是笔者还没调试通代码和后续模型部署等流程,哈哈),用腾讯云的机器学习平台:智能钛机器学习平台(https://console.cloud.tencent.com/tione/project/list)实现,模型整体如下:
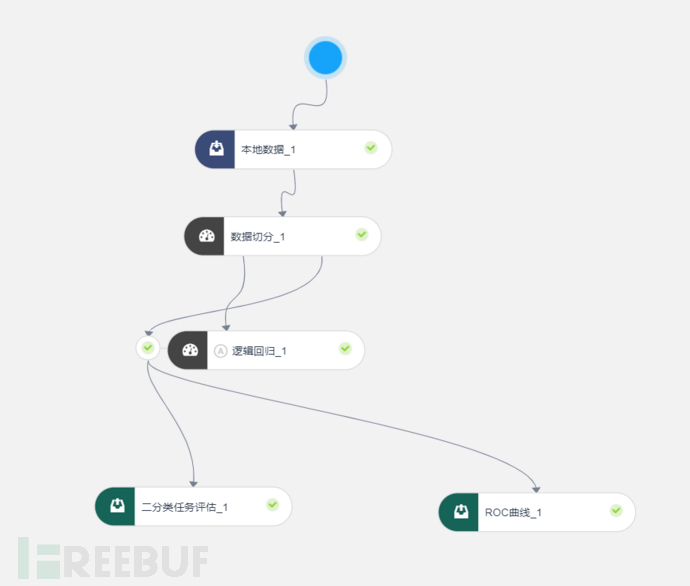
本地数据节点配置,将我们的特征文件white+black.csv导入:
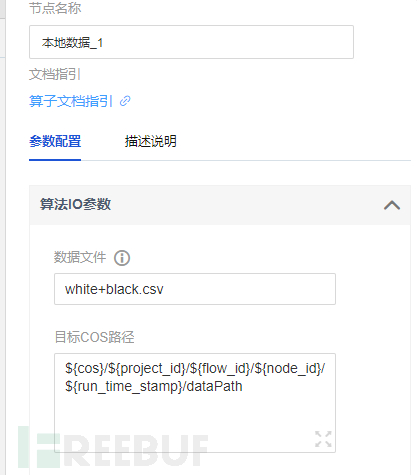
数据切分节点配置,配置分割比例,一般模式训练80%,验证20%
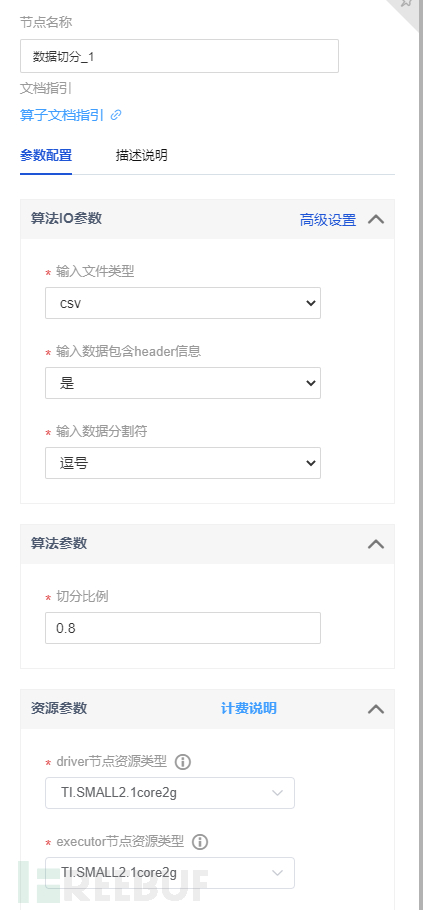
逻辑回归节点配置,其中表前列0为hacked列,就是黑白标签,其他均为特征列
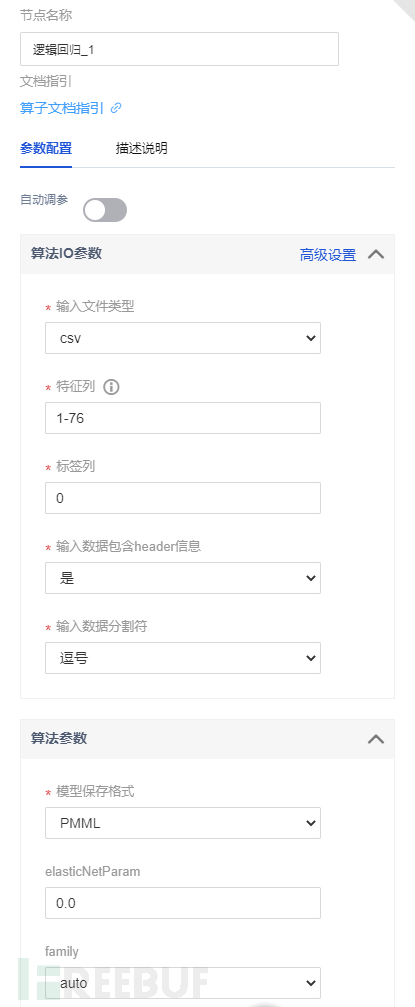
评估模块配置,从预测结果数据,可以看到预测列在78列
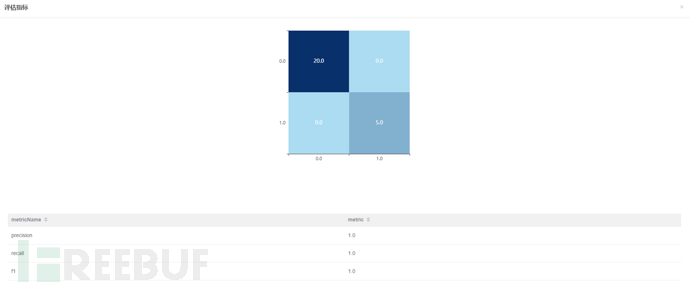
运行后的评估效果,效果喜人!
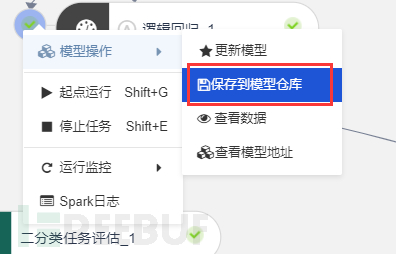
保存到仓库,准备后续用
模型发布
第四步,我们已经获得了模型,也就是知道怎么检测木马通信了,我们怎么把这个规则(模型)部署上线,应用起来呢,我们还是用腾讯云的平台:智能钛弹性模型服务,用在线预测进行发布。
从模型仓库启动模型服务
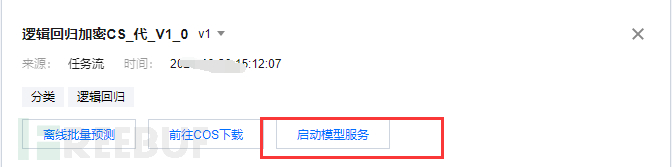
配置模型服务(这里要选择生成token,截图为标注选择)
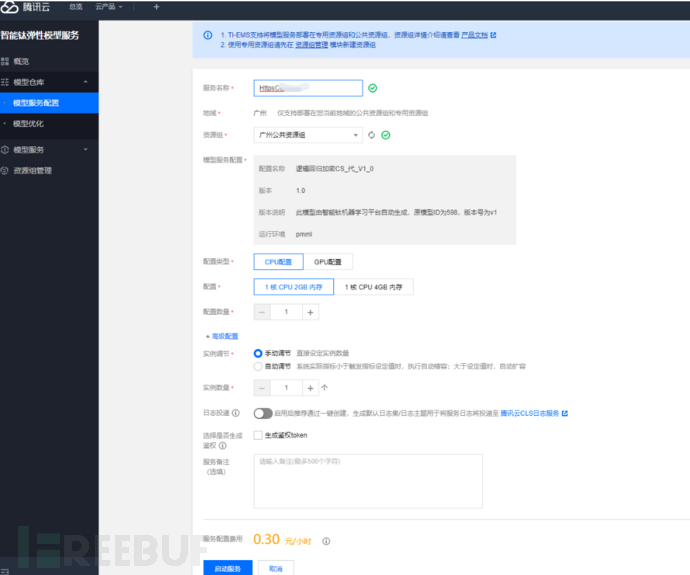
启动模型服务
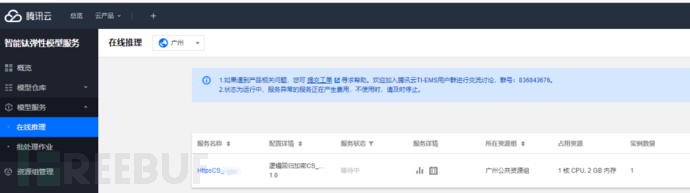
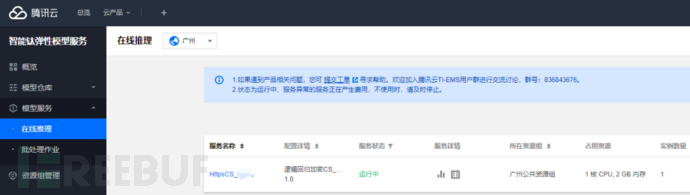
点击更多--调用,启动公网调用。这样检测服务就可以用了。
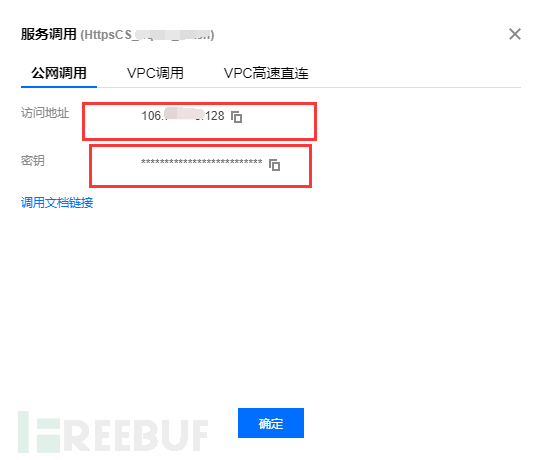
在线预测
最后一步,我们用起来。
首先,抓一个病毒通信的包,转换成在线推理接口可以用的数据(将cvs抓成json,可用如下工具https://www.bejson.com/json/col2json/)
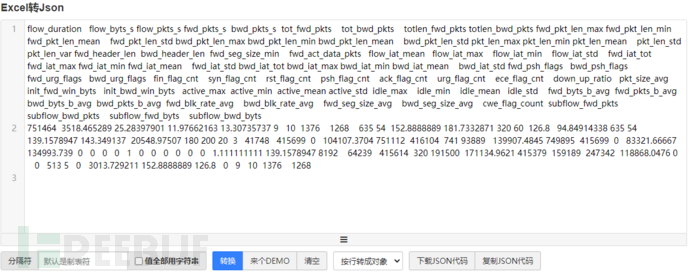
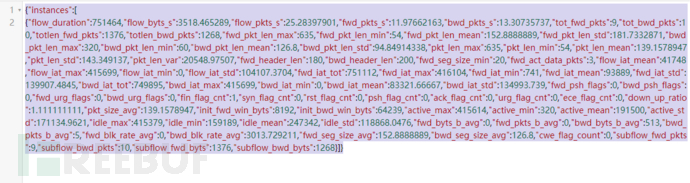
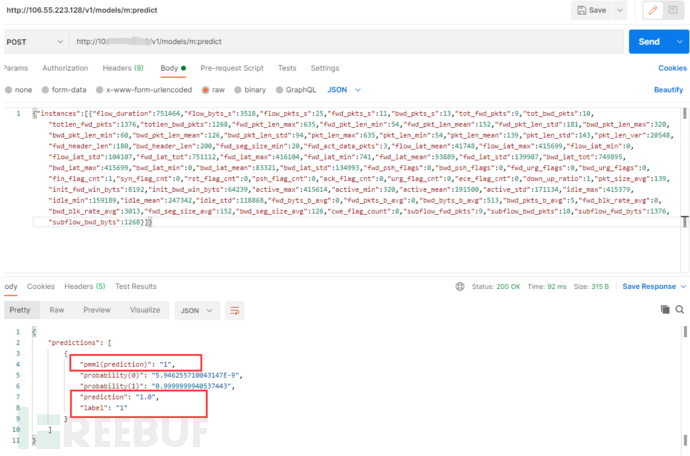
然后,进行最终调用,检测输入的通信特征是否是cobalt strike通信包。
curl(如下格式仅能用linux命令行,win下使用报错,疑似腾讯云兼容性问题)调用结果,返回为1,也就是木马通信,

postman调用结果(通过import功能,输入完整curl指令,导入。不要手工输入,会报错),返回结果同上
总结:
如上经过各种尝试,当前机器学习模型可以对测试的cobalt strike的通信数据进行准确检测,但这仅仅是demo而已。
cobalt strike 不同版本,不同配置方式,例如get、post、cookie等字段改变是否对通信特征有影响?这都需要进一步提取足够的数据传入模型,训练形成新的模型,也就是说这是一个滚动的过程,需要机器学习运营人员持续完善模型,而且要关注训练出的模型是否足够准确,防止随着样本输入越来越多,准确率反而下降的问题。
好了,就到了这里,开了个头,欢迎共同探讨!
 已在FreeBuf发表 7 篇文章
已在FreeBuf发表 7 篇文章
如需授权、对文章有疑问或需删除稿件,请联系 FreeBuf 客服小蜜蜂(微信:freebee1024)
 temp
temp
 我的收藏
我的收藏





- 7 文章数
- 10 关注者