


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

- 关注
一、无服务介绍(Serverless)
计算服务的演进
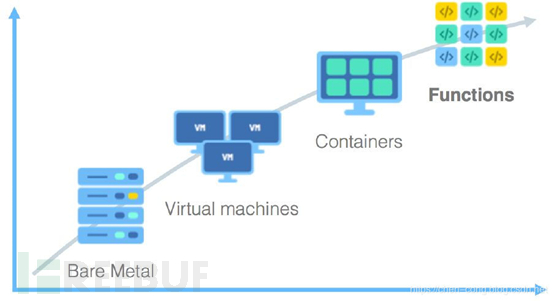
随着业务的不断迭代,计算服务从最初的物理服务器向虚拟化发展,接着又出现容器技术,无论是哪种技术,降低成本、提高效率才是云服务永恒不变的主题。至此出现了无服务Serverless技术。
PS:以下介绍中无服务与Serverless是等同概念。
什么是无服务计算
云原生计算基金会(Cloud NativeComputing Foundation, CNCF)对无服务器计算作了如下定义:
Serverless computing refers to theconcept of building and running applications that do not require servermanagement. It describes a finer-grained deployment model where applications,bundled as one or more functions, are uploaded to a platform and then executed,scaled, and billed in response to the exact demand needed at the moment.
无服务器计算是指开发者在构建和运行应用时无需管理服务器等基础设施。它描述了一种更细粒度的部署模型,其中将应用程序打包为一个或多个功能,上传到平台上,然后执行、扩展和计费,以响应当时真实的需求。
Serverless其实就一个函数或代码程序,当有访问时开始运行其函数代码,运行完成后就会自动删除,真正做到按次计费。Serverless由第三方托管,就是一个PassS服务,由事件触发。整个无服务的生命周期可以做到毫秒级别。
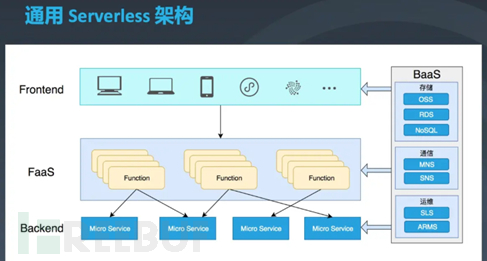
最底层实现复杂业务的后端微服务(Backend),然后FaaS层通过一系列函数实现业务逻辑,并为前端直接提供服务。对于前端开发者来说,前端可以通过编写函数的方式来实现服务端的逻辑。FaaS是计算层的Serverless架构实现方式之一,天然无状态的设计,实现自动的水平扩展。FaaS就像是一个强力脱水一样,连接了云上的各种服务,可用于轻松构建业务系统,实现高可用,可扩展,同时又很经济实惠的架构。越丰富的云上服务,例如大数据分析系统,AI系统,越能增加FaaS的能力。
云厂商的常见Serverless架构
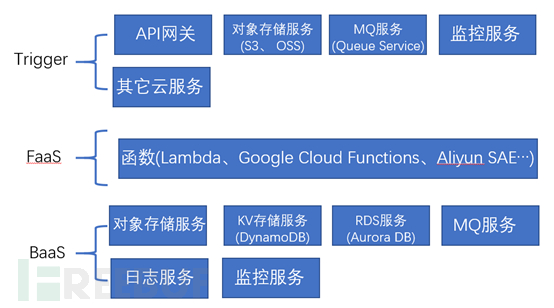
Trigger,由它来进行事件驱动,通过API网关、对象存储等服务进行事件驱动。
FaaS,函数即服务,每一个函数都是一个服务,函数可以由任何语言编写,除此之外不需要关心任何运维细节,比如:计算资源、弹性扩容,而且可以按量计费,且支持事件驱动。业界大云厂商都支持 FaaS,各自都有一套工作台、或者可视化工作流来管理这些函数。
BaaS,后端及服务,就是集成了许多中间件技术,可以无视环境调用服务,比如数据即服务(数据库服务),缓存服务等。组成 Serverless的 FaaS + BaaS。
Serverless常见服务商提供的解决方案

如果不使用公有云服务,而是自己搭建Serverless平台的话也是可以的,如OpenStack也提供了相应的解决方案。Openstack中有个项目叫Qinling,此项目就是在OpenStack平台上提供Function as a Service的功能。从OpenStack Rocky版本才开始支持Qinling项目。
Qinling利用OpenStack中已有的组件来支撑用户自定的Function运行。OpenStack提供丰富的IaaS层资源以及用户验证( Keystone ),事件监控( Adoh ),负载均衡等功能。用户自定义Function可以灵活地利用这些资源和服务达到效果。
AWS眼中的Serverless
“现代化的架构是使用AWS的服务,Lambda的功能,把它们连接在一起。没有中间层、没有应用层、也没有数据层,它是一系列WEB服务连接在一起,由功能连接在一起,无需服务器,而安全、可能、规模、性能、成本管理这些事项由AWS来完成。--“Everyone wants just to focus onbusiness logic.”
AWS Lambda就是一项Serverless服务,可使您无需预配置或管理服务器即可运行代码。AWSLambda 只在需要时执行您的代码并自动缩放,从每天几个请求到每秒数千个请求。您只需按消耗的计算时间付费 –代码未运行时不产生费用。借助 AWS Lambda,您几乎可以为任何类型的应用程序或后端服务运行代码,并且不必进行任何管理。AWS Lambda 在可用性高的计算基础设施上运行您的代码,执行计算资源的所有管理工作,其中包括服务器和操作系统维护、容量预置和自动扩展、代码监控和记录。您只需要以 AWS Lambda 支持的一种语言提供您的代码。您可以使用 AWS Lambda 运行代码以响应事件,例如更改 Amazon S3 存储桶或 Amazon DynamoDB 表中的数据;以及使用 Amazon API Gateway 运行代码以响应 HTTP 请求;或者使用通过 AWS SDK 完成的 API 调用来调用您的代码。借助这些功能,您可以使用 Lambda 轻松地为 Amazon S3 和 Amazon DynamoDB 等 AWS 服务构建数据处理触发程序,处理 Kinesis 中存储的流数据,或创建您自己的按 AWS 规模、性能和安全性运行的后端。
Serverless常见使用场景
AI应用
智能客服
视频和图片识别,分析
实时数据处理
文件处理
流数据处理
ETL
应用后端
移动APP的后端
物联网IoT的后端
如下汇总了一些实际的场景案例
1)低频请求
在物联网行业中,由于物联网设备传输数据量小,且往往是固定时间间隔进行数据传输,因此经常涉及低频请求场景。
例如:物联网应用程序每分钟仅运行一次,每次运行50ms,这意味着CPU的使用率为0.1%/小时,这也意味着可以有1000个相同的应用共享计算资源。而Serverless架构下,用户可以购买每分钟100ms的资源来满足计算需求,通过这种方式就能够有效解决效率问题,降低使用成本。
2)定制事件
例如用户注册时发邮件验证邮箱地址,通过定制的事件来触发后续的注册流程,而无需再配置额外的应用来处理后续的请求。
3)固定时间触发
在固定时间触发服务,例如在夜间或者服务空闲时间来处理繁忙时候的交易数据,或者运行批量数据,来生成数据报表,通过Serverless方式,不用再额外购买利用率并不高的处理资源。
4)流量突发型事件
移动互联网应用经常会面对突发流量场景。例如:移动应用的通常流量情况是QPS 20,但每隔5分钟会有一个持续10s的QPS 200流量(10倍于通常流量)。在Serverless架构下,开发人员可以利用弹性扩展特性,快速构建新的计算能力来满足当前需求,无需单独部署一台满足QPS 200流量的服务器,当业务高峰后,资源能够自动释放,有效节省成本。
使用无服务的优点,因为使用的是PaaS平台,所以如下内容就不需要关心了,技术人员只需要关心业务逻辑上的技术即可。
1)不需要考虑资源预配置和使用率
2)不需要考虑可靠性和容错
3)不需要考虑扩展性
4)不需要考虑运维和管理
二、AWS Lambda实践之HelloWorld
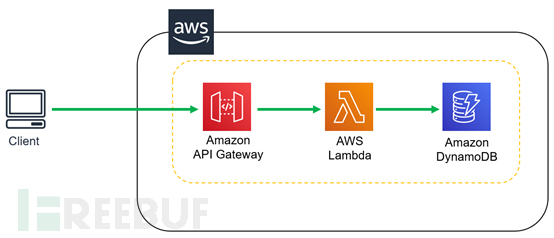
本次实验使用的是AWS上的Lambda服务,BaaS为DynamoDB服务,Trigger为API Gateway服务,整体架构为API Gateway + Lambda + DynamoDB。在做实验时请使用AWS国际版,因为在使用AWS中国版时会牵涉到一个API Gateway备案问题,如果没有备案的话无法直接在公网上使用API接口,因此推荐使用AWS国际版来进行相关实验。
应用交互示意图如下图:
在DynamoDB里创建数据表与相应的内容
创建DynamoDB数据库表项
选择DynamoDB服务,创建表
PS:请记住此数据表名,在后续Lambda函数里会用到此表名进行数据库的读取。
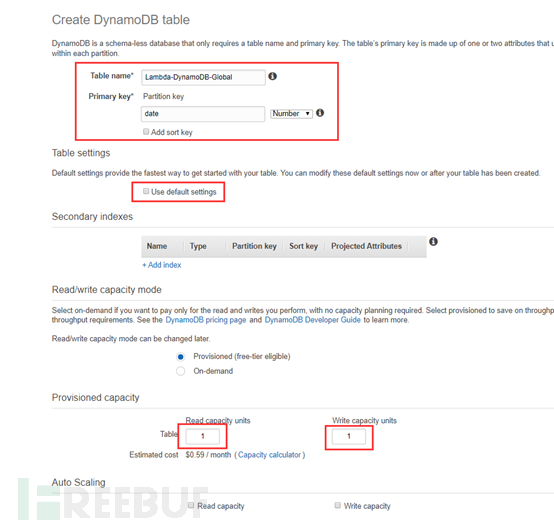
如果仅仅实验使用,取消默认设置,把Readcapacity units与Write capacity units改成1。
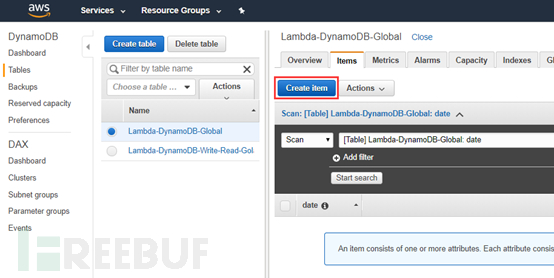
创建DynamoDB数据库表项内容
创建item
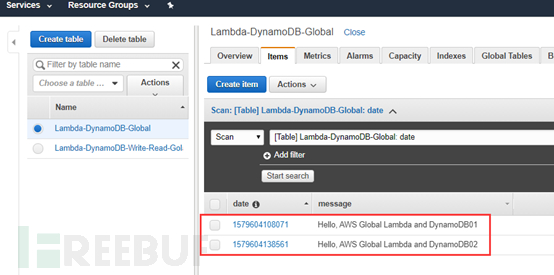
 创建完后可以看到相应数据库表里的内容,此时就已经有两项数据内容了
创建完后可以看到相应数据库表里的内容,此时就已经有两项数据内容了
创建Lambda函数
选择Lambda服务
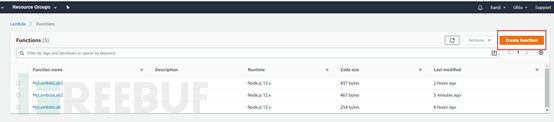
创建Lambda函数
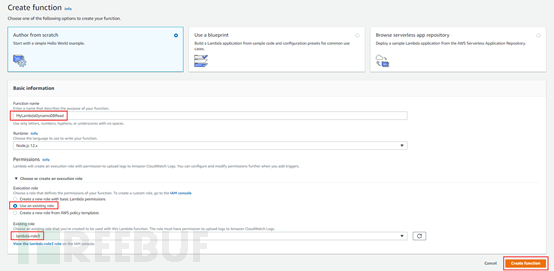 PS:在使用Lambda时需要在IAM里的role有相应的权限,否则无法使用Lambda服务,如果涉及到DynamoDB时还需要Lambda对DynamoDB的访问权限,本实现环境的IAM权限如下:
PS:在使用Lambda时需要在IAM里的role有相应的权限,否则无法使用Lambda服务,如果涉及到DynamoDB时还需要Lambda对DynamoDB的访问权限,本实现环境的IAM权限如下:
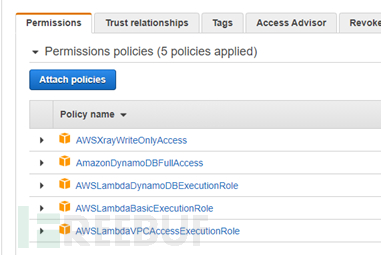 PS:可以忽略AWSLambdaVPCAccessExecuteRole权限,此权限为弹性网络接口以将您的函数连接到 VPC 的权限编写Lambda函数。
PS:可以忽略AWSLambdaVPCAccessExecuteRole权限,此权限为弹性网络接口以将您的函数连接到 VPC 的权限编写Lambda函数。
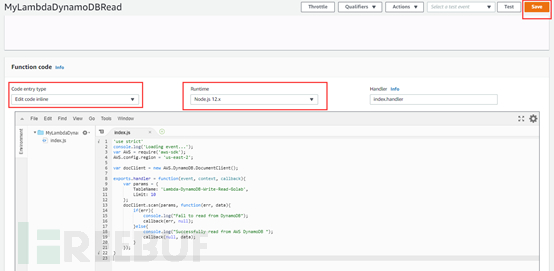
本实验直接使用在线编辑方式(还包括上传.zip文件或是从S3获取代码),使用的是Node.js 12.x语言
代码如下:
'use strict'
console.log('Loading event...');
var AWS = require('aws-sdk');
AWS.config.region = 'us-east-2'; //一个根据实际情况填写相应的region
var docClient = new AWS.DynamoDB.DocumentClient();
exports.handler = function(event, context, callback){
var params = {
TableName: 'Lambda-DynamoDB-Write-Read-Golab', //使用之前创建的Dynamo的表名
Limit: 10
};
docClient.scan(params, function(err, data){
if(err){
console.log("Fail to read from DynamoDB");
callback(err, null);
}else{
console.log("Successfully read from AWS DynamoDB ");
callback(null, data);
}
});
}编辑完后选择Save,并且可以直接在线进行测试,点击右上名的Test即可以测试此函数代码是否可以正常使用。点击Test后会出现如下窗口页面,随便使用一个Event template即可,然后选择Create。
 测试结果可以读取数据表里的内容,并且此Serverless的运行时间为323.46ms,使用时占用了90MB内存
测试结果可以读取数据表里的内容,并且此Serverless的运行时间为323.46ms,使用时占用了90MB内存
部署API网关
选择API Gateway服务,并创建一个API网关
 选择REST API并且Build一个
选择REST API并且Build一个
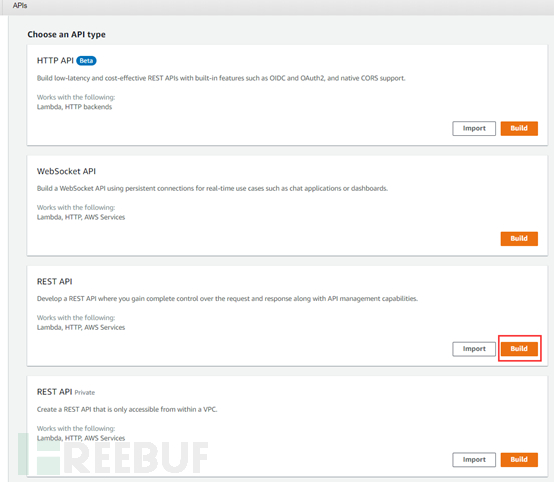
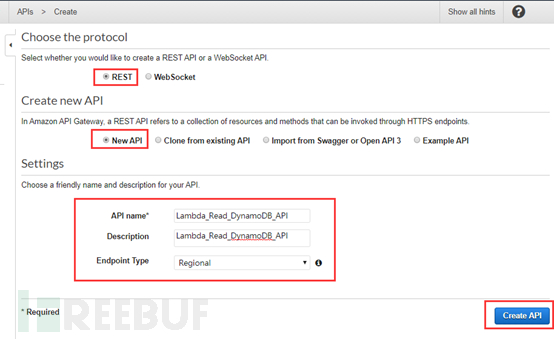
选择REST API模式,并使用New API,填写API名字,最后点击创建API
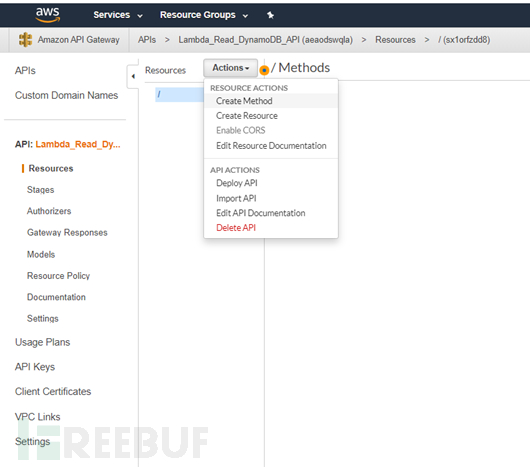
 创建一个新的方法
创建一个新的方法
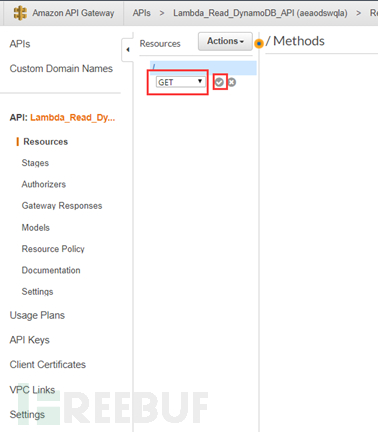
创建一个get方式,并且选择确认
在类型里选择Lambda Function,并且在Lambda Function里填写之前创建的Lambda Function名字,最后支持Save。
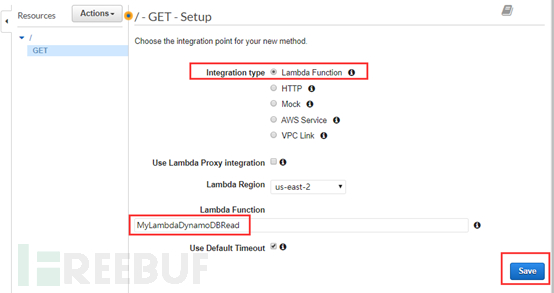
点击Save后会弹出一个窗口,直接选择OK就行了。
最后进行API的部署
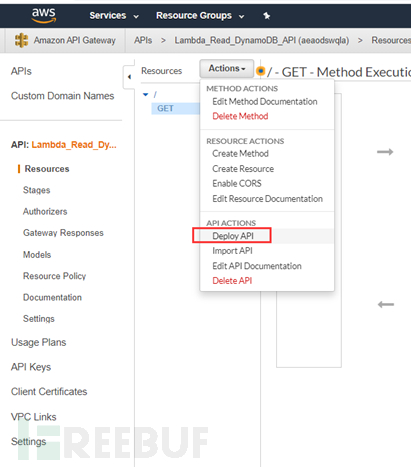
完成上述配置后,会生成一个GET方法,然后直接选择Actions再选择Deploy API进行API网关的部署
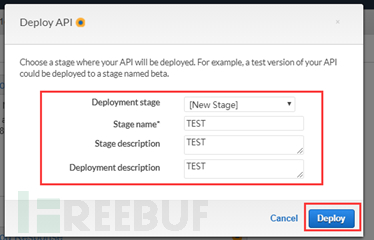
 填写一个API的版本信息后进行部署,选择Deploy。
填写一个API的版本信息后进行部署,选择Deploy。
 选择Stages的TEST下的GET方法,在右边会生成一个API的访问方式
选择Stages的TEST下的GET方法,在右边会生成一个API的访问方式
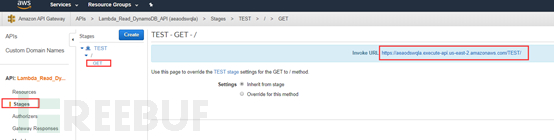 拷贝后直接就可以通过公网进行访问了
拷贝后直接就可以通过公网进行访问了
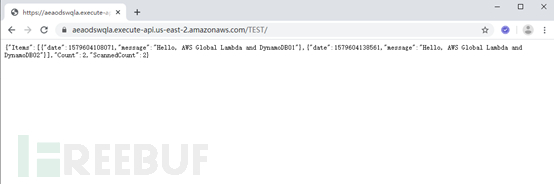
到此,此实验完成。
三、Serverless安全问题
任何一种新型应用都会存在相应的安全问题,特别是类似Serverless服务,直接就是以函数计算服务形式存在的,因此安全问题更加明显。在此简单来介绍下Serverless相关的安全问题与解决方案。
PS:此安全介绍中暂不涉及Serverless平台安全问题。
从整个形态中Serverless安全可以分为两个维度,一个是上线前的安全,另一个则是上线后的Run Time安全。
1. Serverless上线前安全
1)威胁建模
Serverless有多种应用场景,如在注册服务、定单派送等服务时都存在相应的安全问题场景,如机器人注册、刷单等恶意操作。或是存在一些合规安全问题,如数据安全、或是数据隐私方面的问题。因此需要根据不同的应用场景生成相应风险点,形成一个较为完整的威胁建模,最终输出一个Check List,作为开发编码的规范来解决这些安全问题。
2)组件与依赖的安全问题
据统计,在编写一个应用程序时开源组件会占到其代码的60-80%的比率,因此开源组件的安全问题是我们需要特别关注的问题。另一方面就是组件的依赖关系,如果一个依赖存在漏洞,则会影响整个应用的安全问题。因此需要实时关注开源组件与依赖库的安全更新,或是通过自动化扫描工具对这些代码进行扫描。
3)软件成分分析
此部分内容类似上述所描述的问题,分析应用中使用了多少组件与依赖库,如,fastjson,struts2,spring,jenkins等,这些组件与依赖库是否存在安全问题,如库名、版本号、风险等级、漏洞数量等内容。同时还需要对开源组件的License进行分析,规避法律风险,如开源许可证的完整信息、是否开源、是否商用等问题。通过相应的软件成分分析工具对上述这些信息进行自动化的分析。
4)最小权限
权限分配也是Serverless非常重要的一个环节,通过分配不同的服务具有不同的角色为每个功能授予最小权限,如使用AWS的身份验证服务(IAM),可以最大限度的减少潜在的安全风险。
2. Run Time安全
1)寄生模式
在Serverless Function code启动前先启动一个安全防护代码,与Serverless集成变成一个新的Function Code,作为原始Serverless Function code的防护程序,确认只允许执行正常的Functioncode,有点类似RASP这种概念。
2)日志
一旦使用了Serverless,快速迭代的功能和业务,可能会让我们忽略了一些安全问题的迹象。比如发送到Serverless的大量请求,可能意味着功能存在漏洞,但由于没有持续关注这些日志或信息而导致安全问题。因此需要通过日志分析,识别执行日志中的异常情况。
*本文作者:ZhiXian,转载请注明来自FreeBuf.COM
如需授权、对文章有疑问或需删除稿件,请联系 FreeBuf 客服小蜜蜂(微信:freebee1024)
- 0 文章数
- 0 关注者