


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

- 关注
 本文由
创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
本文由
创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载

curl简介
今天给大家介绍一个命令行下的网络传输客户端工具、Web神器curl,它支持包Http、Ftp在内的常见网络协议,支持代理,支持Https、证书,支持各种Http方法,在各发行版的Linux和Windows都支持,而且linux默认自带。其底层的C库libcurl也被很多脚本语言包括PHP(cURL)、Perl(Net::Curl,WWW::Curl)、Python(PyCurl)等打包成模块调用,可直接用于Web客户端编程,编写网络爬虫或者其他Web自动工具。尤其对于php来说由于它缺乏这类工具可以直接做Web客户端,cURL就成了它唯一的选择了。
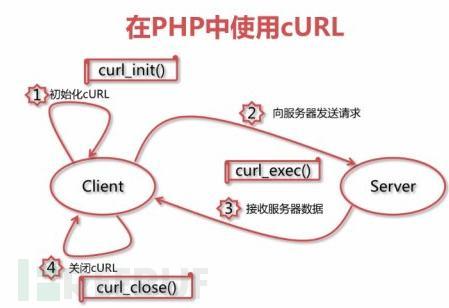
关于curl的详细介绍和各种参数很多很杂,在此不做赘述,请自己搜索或者查看官方文档。
简单访问
最简单的用法就是在命令行下输入curl 后面跟个网站Url就可以获取页面信息了。当然由于获取的是html文件的内容,不是我们浏览器常见的网站的展现形式(命令行浏览器有w3m可以更好解析html内容),有很多Html标签穿插在内容之间。
我们找个有趣的网站进行访问:
curl ff0000.com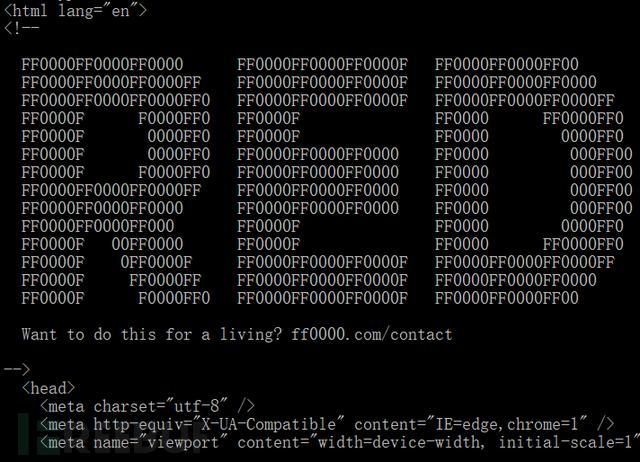
利用curl下载
curl作为一个支持多协议的工具,可不可代替wget做下载呢?当然,完全可以用来替代wget做文件下载,而且有不少的优势。下面就实例演示下:
下载载文档
我们以头条上一片文章的配图为例子,介绍如何下载图片。先通过浏览器访问,图片显示为:
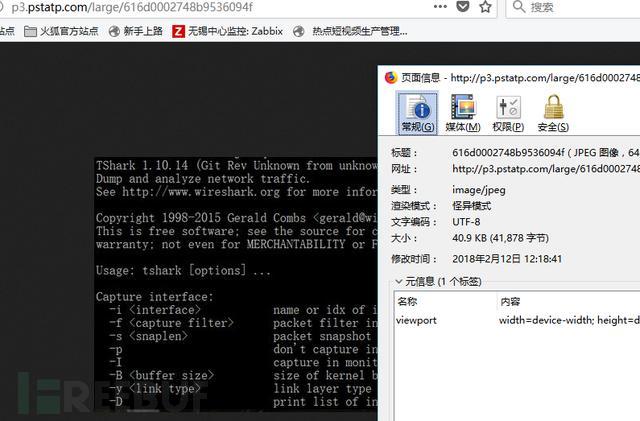
我们用curl下载,主要加-o/O参数,指定下载保存的文件名称:

其中,-o表示指定下载后文件的名称

其中,-O表示下载后的文件名和服务端的文件名一样。
目录下下载到的文件信息和浏览器显示效果的文件大小差不多,应该一样,表示下载成功,如下图。
![]()
如果不指定-o/O默认是直接输出信息到终端的,如果是图片文件的话,由于是二进制不支持显示,就会乱码。

批量下载
注意curl支持对url做模式匹配,这样一个url就可以表示多个文件,可以一次性下载多个文件:
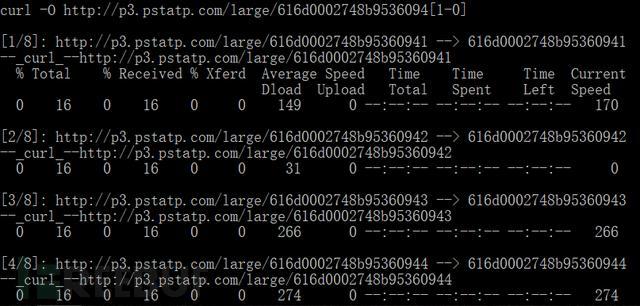
上图中的有个错误,大家发现问题没有?小编刚开始用的时候怎么也没下载到文件,后来找了半天才发现问题所在。Url最后的模式匹配部分写错了,[1-0]是个错误写法,应该是[下限-上限] 把上面的url改成[1-8]立马就可以了。结果如下:
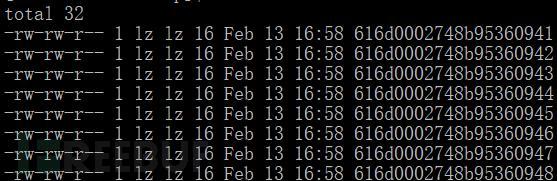
由于URL是演示需要,随意杜撰的所以都没下载到文件,文件大小很小为空。
对多个文件我们也能通过-o指定自己的需要名字,不过需要用一个变量#1来表示后面模式的中的参数,如下图所示:
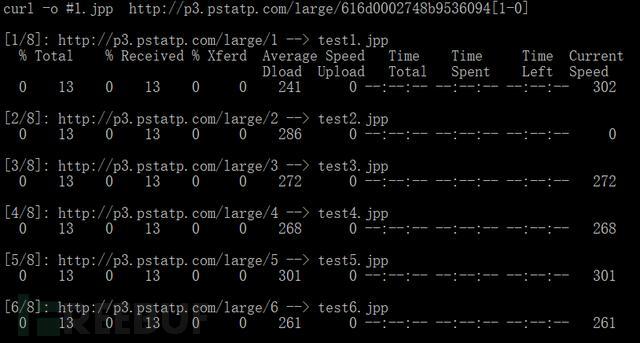
结果是,这样就可以个性化命名下载的文件了。
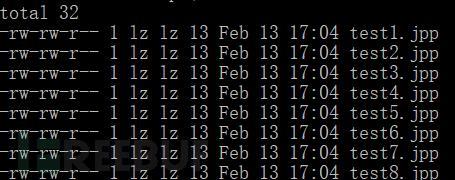
用这招可以一下子把所有序列化特征的文件都下载来了,是不是很方便。对了,这才是它比一般浏览器厉害的地方,可以用来取代人,自动做重复性的工作。
curl还支持很多的下载功能,比如断点续传、分段部分下载等等。更多技巧请看官方的文档或者去搜索,应该都找得到,在此就不多说了。
用curl做安全渗透
获取http头搜集服务器信息
通过curl快速取得服务器版本信息。我们可以用curl -I url取得Web服务的Http头信息,做为信息搜集用,为进一步渗透做准备。例如,我们看看今日头条旗下的产品悟空问答的首页:
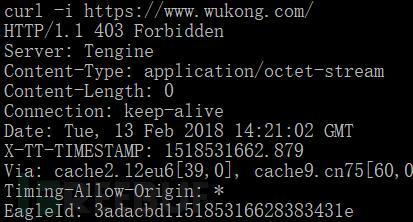
我们看到https头中说明悟空用的服务器是nginx变种淘宝的Tengine,但是屏蔽了版本信息(安全工作做的还是挺到位的)。
Via段信息可能是某个CDN厂商信息(小编瞎猜测的)。
Timing-Allow-Origin: * 表示允许任何资源都可以服务器看到的计时信息。
我们还看到,我们用curl 访问时,返回了 403 Forbidden,说明服务器对客户端限制了。接着下一节我们将介绍如何通过设定User Agent信息获得服务器的信任。
通过设置User Agent 和Porxy代理突破服务限制
上一步骤中我们用curl直接被悟空服务给403拒绝了,我们猜测是服务器根据User Agent给禁止掉了。这时候该怎么办?好办,我们给它一个浏览器的User Agent信息就好了。
设置User Agent信息很简单,用curl -A "XXX" ,XXX表示User Agent信息就行。比如对悟空首页,我们给它喂个 Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.0) 伪装成IE 6,悟空小姐姐立马就驯服了。
curl -I -A 'Mazilla/4.0 (compatible;MSIE 6.0;Windows NT5.0) ' www.wukong.com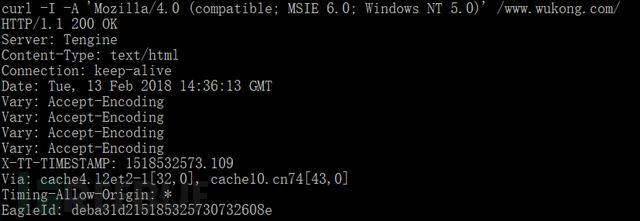
妥妥的,200 OK。
有时候由于你机器访问太频繁,比如爬虫大批量爬数据时候,你的IP可能被服务器探测到访问不正常,当成恶意攻击,或不正常访问被防火墙,WAF等给封掉。这时候就需要一个武器Porxy代理来隐藏到我们的实际地址,骗取服务器的信任。
代理设置也简单,给curl加个-x参数,随后紧跟代理服务器地址即可:
curl -x l14.115.140.25:3128 -A
'Mazilla/4.0 (compatible;MSIE 6.0;Windows NT5.0) ' www.wukong.com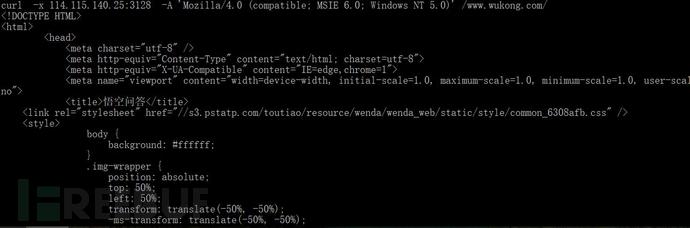
当然问题是你没有代理服务器,代理服务器地址怎么找,我只说一句"诸事不宜,找度娘"。
还有curl结果也能配合shell管道和其他神器对获取的信息进行处理,比如grep:
curl -x l14.115.140.25:3128 -A 'Mazilla/4.0 (compatible;MSIE 6.0;Windows NT5.0) ' www.wukeng.com |grep 悟空
以上是我们对抓的悟空首页的内容最筛选,搜索包含"悟空"字串的行。对信息处理然后入库,这是做一个爬虫获取信息的一个必须步骤,业界有个专门名字叫ETL数据清洗,没有这个过程,获取到都是垃圾数据。
设置访问域名的主机头突破服务器端限制
在某些情况下服务器可能禁止通过IP直接访问,或者与需要通特定的域名、主机头才能访问你需要访问的内容,但是此域名DNS还不没有解析,或者DNS解析的域名是多个IP,按不同地域解析到不同的地址,不同地址显示内容不一样,或者有访问控制,不能到你需要的IP,你需要让它解析成你需要的特定IP。
可能有些朋友会说那你直接设置hosts文件不就得了。回答正确。设置hosts确实可以(比如通过设置hosts访问一些国外网站啥的)。但是略嫌繁琐,其实上curl完全可以很便捷的自己设置。
在curl里通过设置Http头信息的主机头为你的域名,而将你URL中的域名改成你IP即可。
curl --header "Host:www.freebuf.com" http://127.0.0.1在较新版本的curl还支持一个为例子显示下:--resolve的选项,可以直接用来指定对url的解析
curl --resolve www.freebuf.com:80:127.0.0.1 http://www.freebuf.com注意语法格式。
设置POST表单实现web认证
curl支持多种http方法,当然post表单也是没有问题的,对于简单的post表单认证,我们可以直接用这种方法登陆认证,然后从系统获取有用的信息,或者写成小脚本做密码暴力破解,当然由于curl不支持多线程,所以也没有啥优势。
我简单说说用curl post提交表单的例子。
基本格式如下:
curl -d "user=name&pass=pass" 登陆URL
比如小编以自己机器上的itop为例子显示下:
curl http://192.168.21.111/itop240/pages/ui.php|grep input
我们先用curl直接获取登陆页面的信息,用grep搜索input 然后就能找到用户名和密码所在的行,找到用户名表单名为auth_user ,密码的为auth_pwd。然后用这两个字段结合用户名密码构建表单,进行访问。
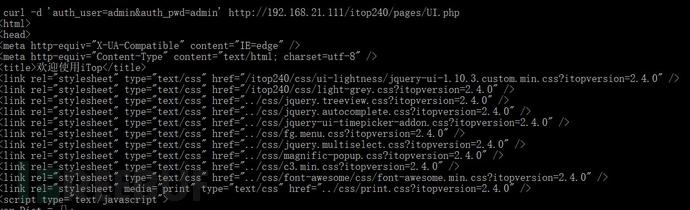
可以看到我们已经成功完成的认证,获取了认证后页面的信息。
保存cookie信息和调用cookie实现利用cookie获取信息
我们知道web中cookie中保存了我们的认证信息,这样当我们在此访问页面时候可以免去重复输入用户名密码的过程。
curl中 选项-D 文件名 ,就是表示把认证的cookie保存到命名的文件中去
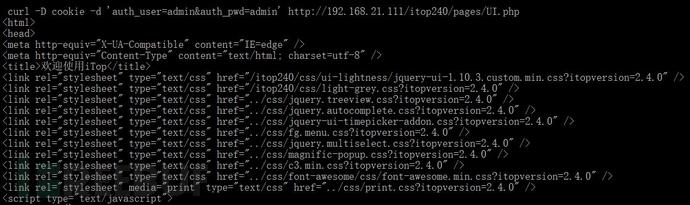
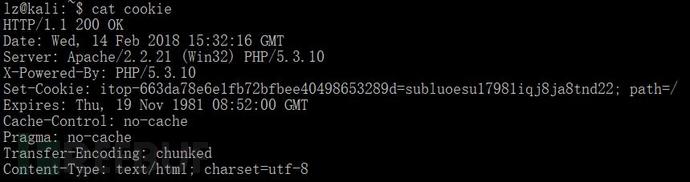
cat cookie信息如下:
保存后cookie后下次访问就可以用 -b来调用cookie信息,不用输入用户名密码也就可以获得页面的内容了。
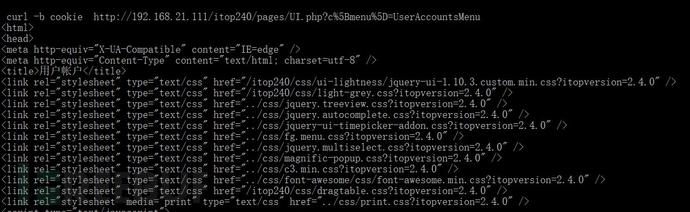
比如我们用-b调用上次保存的cookie信息,然后直接访问后台账号管理页面就直接出信息了。
然后我们试着不加载cookie文件再试一把,如下图
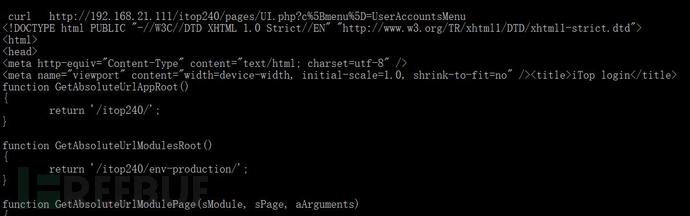
可见又跳回到登陆页面去了。
指定referer来欺骗服务器端放爬虫机制
有些服务器启动一定反爬错误,比如你没有通过前置页或者列表页的跳转,而直接去从内容页也获取信息。从访问日志可以判断你来源的referer地址是否为跳转页面,如果不是会限制你访问。这是常见Web防盗链机制。
为了对付这种限制,我们可以在curl里通过设定-e 用来指出referer地址:
curl -e 'http://www.freebuf.com' http://www.freebuf.com/news/164109.html
这样,就能够服务器会认为我们是从www.freebuf.com首页通过链接访问到的。
利用curl进行文件上传
比如下面一个上传文件的表单:
<form method="POST" enctype='multipart/form-data' action="upload.php">
<input type=file name=upload>
<input type=submit name=press value="OK">
</form>
我们简单用:
curl --form upload=你本地的文件路径和名字 --form press=OK 网站Url,就能实现文件的上传。利用curl用用户名密码通过sftp、scp下载远程用户目录下的文件;用MLSD命令获取远程ftp的文件列表
关于这个我们不多说,列出两例子供大家参考。
curl -O -u user:password sftp://example.com/~/file.txt
curl -O -u user:password scp://example.com/~/file.txt注意参数和上文说过的-O参数啥意思?还记得么?
我们知道ftp服务器都提供一个MLSD命令。通过FTP客户端发送MLSD命令,可以得到服务器端的文件信息:如文件创建时间,修改时间,文件大小及文件所有者。
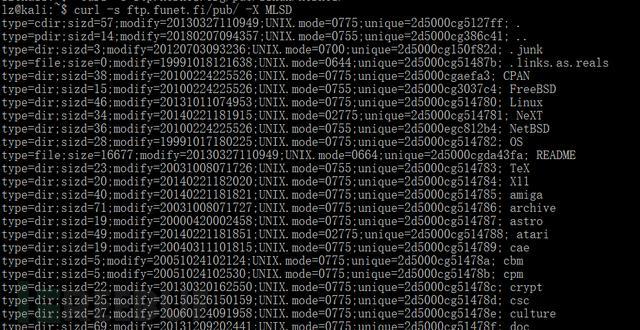
我们对其用perl单行处理下获得,仅仅有文件的列表:
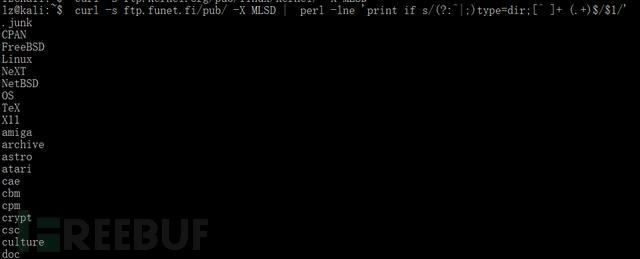
curl测试不安全的HTTP请求
最后我们说下如何用curl 获取服务器启用的HTTP请求方法,判断是否启用了补全的方法。命令如下:
除标准的GET和POST方法外,HTTP请求还使用其他各种方法。
包括PUT,DELETE,COPY,MOVE,SEARCH,PROPFIND,TRACE等,这些方法一般很少用的到,需要在服务器端限制访问。如果没有限制的话,吃瓜群众有可能利用他对你进行攻击哦。
curl -i -X 方法 测试的URL
curl -v -X 方法 测试的URL查看响应的 Allow: GET, HEAD, POST, PUT, DELETE, OPTIONS信息来判读:
比如
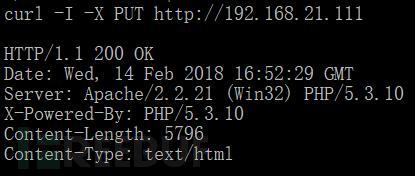
表示PUT方法可以使用,不安全。
curl -I -X PUT http://www.freebuf.com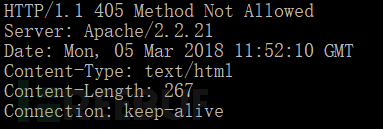
这种返回非 20X的基本都是OK的。
但是我们发现了个问题,大家看到了没有freebuf的主页用的apache,而且apache版本没有做屏蔽哦。
马上搜索了下,发现这个版本好像蛮多漏洞哦。
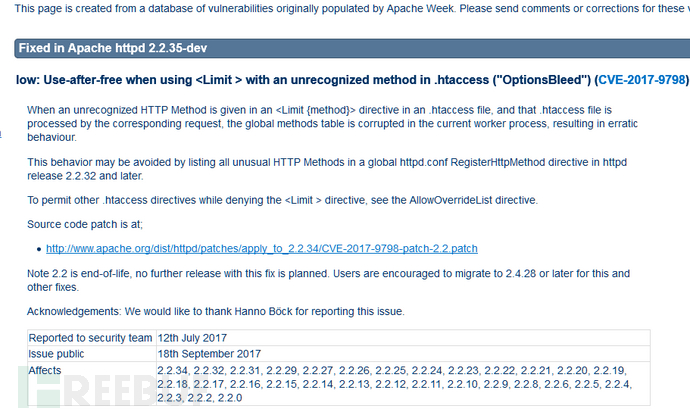
ok,不多说了,freebuf的运维同学赶紧做下版本屏蔽哦
已在FreeBuf发表 0 篇文章
- 0 文章数
- 0 关注者