


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

 转载情报员
转载情报员- 关注
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
 本文来源玄月调查小组 ,如有疑问请联系FreeBuf客服(微信号:freebee1024)
本文来源玄月调查小组 ,如有疑问请联系FreeBuf客服(微信号:freebee1024)虽然RAG在提供上下文感知回答方面很强大,但如果希望LLM应用能够自主执行任务呢?这正是AI Agent的用武之地。本文Understanding AI Agent Security[1] 就介绍了AI Agent:功能、架构与安全风险
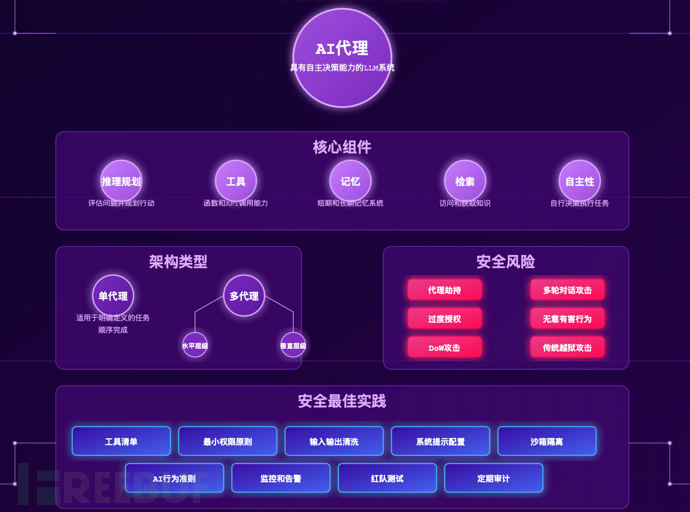
什么是AI Agent?
LLM Agent是能够动态决定自身流程来执行特定任务的系统。与执行过程在代码中预先确定的工作流不同,Agent拥有自主性和知识,使其能够根据输入做出细致入微的决策。
我们正在见证一波新的Agent系统进入市场,特别是通过解决复杂行业问题的初创公司。虽然这些Agent可能被称为"AI助手"或"AI协作伙伴",但核心原则不变:它们是由模型驱动的系统,具有执行任务的自主权。
从本质上讲,Agent系统需要四个基本能力:
- 具备推理和规划能力的模型
- 检索机制
- 工具和API
- 记忆系统
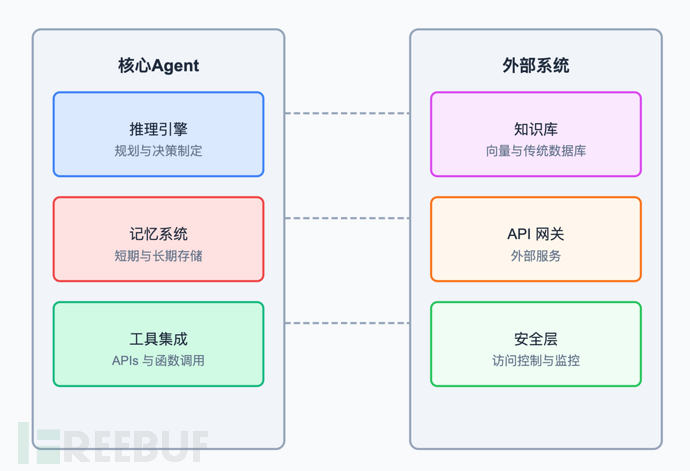
AI Agent组件
AI Agent可以从简单(如查询天气数据)到复杂(如访问受限数据并代表用户采取行动的客服聊天机器人)不等。像OpenAI和Anthropic这样的基础实验室在他们的示例中提供了基本案例,比如Anthropic的带有客户端工具的客服Agent。
当我们思考LLM架构时,存在着不同层次的复杂性:
- 基础模型对话:用户通过提示和响应与模型直接交互
- RAG增强查询:通过向量数据库的上下文增强的模型交互
- 用户到Agent交互:用户与自主AI Agent的互动
- RAG支持的Agent:能够访问知识库并执行功能的Agent
- Agent到API通信:Agent与外部API的交互
- Agent间协作:多个Agent共同实现目标
实际应用通常结合多个层次。例如,旅行聊天机器人可能处理基本对话,检索客户档案(RAG),修改预订(用户到Agent),并通过外部预订系统预订餐厅(Agent到API)。随着Agent在现实世界中不断增加,我们应该预计会看到更多复杂的Agent系统和Agent间互动。
AI Agent的核心组件
所有AI Agent都必须被赋予一定程度的自主权来做决策并执行任务。这需要一个能够推理和规划的模型,检索信息的机制,执行任务的工具和API,以及存储信息的记忆系统。
推理和规划
Agent必须评估问题并确定实现目标所需的行动。这涉及理解上下文,分解复杂任务,并确定最佳行动顺序。并非所有模型都具备推理和规划能力,因此选择能够处理任务复杂性的模型非常重要。
工具
为了执行任务,AI Agent必须调用工具。这些工具可以简单如Python函数,也可以复杂如第三方API和数据库查询。创建AI Agent时,你需要向Agent注册这些工具。
提供这些工具并不意味着AI Agent会在每次响应时都调用它们。相反,你可以构建AI Agent来"推理"并确定是否应该调用工具。对于某些模型,你也可以强制模型调用函数。
在Anthropic的客服Agent示例中,用户发送消息随后触发LLM"思考"。
LLM可以访问三个客户端工具:get_customer_info(获取客户信息)、get_order_details(获取订单详情)和cancel_order(取消订单)。根据用户消息,它必须确定应该使用哪个工具来执行任务。在这个例子中,它确定应该调用get_customer_info函数并返回适当的结构化响应。
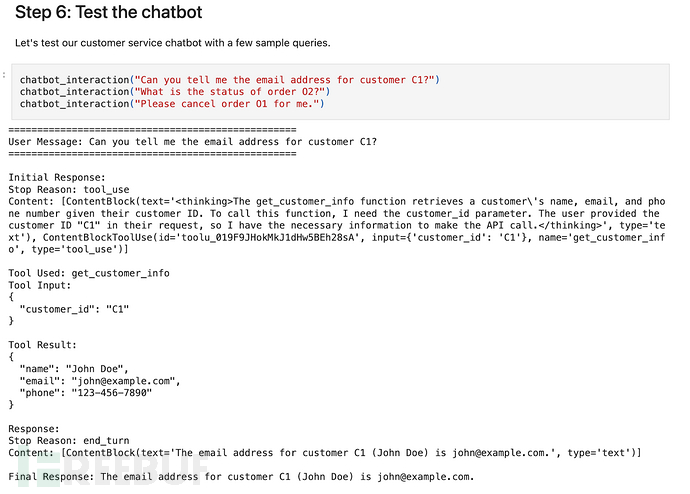 记忆
记忆
AI Agent需要记忆来克服无状态LLM架构的挑战。AI Agent通常使用两种类型的记忆:
- 短期记忆:当前对话的记忆,用于存储对话历史和任务上下文。
- 长期记忆:AI Agent知识的记忆,用于存储世界知识和任务知识。
检索和知识
检索是从知识源(如向量数据库)访问信息的过程。AI Agent可能需要访问向量数据库来检索相关信息,无论是搜索执行任务所需的存储信息,还是检索有助于Agent成功完成功能的相关信息。
AI Agent还可能被授予访问数据库(如SQL数据库)的权限,以检索用户或另一个Agent请求的信息。
Agent架构
单Agent
单Agent架构最适合定义明确的流程和范围狭窄的工具。与单Agent交互时,它将按顺序规划和完成任务,这意味着第一步操作必须完成后才能执行下一步。
多Agent
多Agent系统非常适合需要多角度视角或并行处理的任务。这些可以通过两种方式组织:
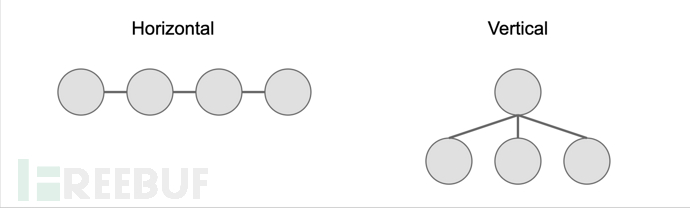
水平层级
- Agent在没有指定领导的情况下协作
- 非常适合需要大量反馈的任务
- Agent之间可能出现无重点的"闲聊"风险
垂直层级
- 一个Agent领导,其他Agent支持
- 明确的分工
- 减少干扰但可能面临沟通瓶颈
AI Agent的安全风险
根据Agent架构的类型,AI Agent可能仍然容易受到RAG架构常见的安全风险,如访问控制缺陷、数据投毒和提示注入。除了这些风险外,AI Agent还可能引入其他类型的漏洞。
Agent劫持
针对Agent系统的最大风险之一是新创造的"Agent劫持[2]"概念,即通过直接或间接提示注入来利用AI Agent。Agent劫持是一种需要多个漏洞才能构成严重风险的链式攻击。第一个是AI Agent的基本配置错误,允许过度权限或自主权。第二个是来自不可信用户输入的直接或间接提示注入的存在。当这两者链接在一起时,AI Agent可能被"劫持"执行来自用户的恶意命令。

直接提示注入发生在用户直接与AI Agent交互(例如通过聊天机器人)并包含绕过LLM系统原始意图的恶意指令时。间接提示注入通过污染LLM Agent的检索系统发生,例如在RAG知识库中包含一个被污染的文档,随后被LLM检索。
过度Agent权限和提示注入攻击结合在一起,可能强制AI Agent以非预期或恶意方式行动,比如代表攻击者发送精心制作的钓鱼消息,提升权限以检索未经授权的数据给用户,或向用户提供恶意或非法信息。
Agent权限过高
具有过度访问权限(或不受限制的访问权限)的AI Agent可能对工具、API和数据库构成巨大的数据泄露和敏感信息披露风险。如果没有应用速率限制和输入净化,它们还会引入数据库和API的无限消耗攻击风险。这是由于缺乏健全的授权机制、过于宽松的工具调用和缺乏输入净化造成的。
上图是AI Agent中SQL注入的一个例子。由于提示没有净化,而且AI Agent对数据库有不受限制的访问权,它可以运行SQL命令来转储数据库内容。
拒绝付费(DoW)攻击
从设计上讲,AI Agent需要更复杂的推理和规划来执行任务。由于计算需求,这些模型本身比用于聊天完成的简单模型更昂贵,推理模型(如OpenAI的o1)的推理成本几乎比gpt-4o高出150%。能够访问公司Agent系统的用户可能滥用或误导Agent系统,导致其推理出现循环或不必要地完成任务,从而导致来自推理提供商的巨额账单。
多轮对话攻击
并非所有攻击都能在单个提示中执行。LLM Agent可能容易受到多步攻击,攻击者通过对话序列直到能够完成攻击。这些多轮、对话式策略在强制Agent生成有害输出或在有状态应用中执行任务方面非常有效,通过逐渐说服AI Agent随着时间推移违背其预期目的行事。
如GOAT和Crescendo策略。
无意(但有害)的行为
虽然意图并非恶意,但AI Agent可能会无意中使用其获得的资源采取有害行动。例如,配置错误的编码Agent可能会将不安全的代码提交到生产环境。如果没有适当的控制措施来减轻生产系统中Agent的风险,这些Agent可能会破坏平台的可操作性或可用性,暴露敏感数据如API令牌,或引入可能随后被攻击者利用的不安全代码。
客户服务等领域的AI Agent也可能犯错,例如以公司被迫履行的错误价格做出承诺。它还可能提供关于公司政策的错误信息,或根据提供的事实得出错误结论。
AI Agent也可能容易受到欺诈,应该监控异常活动。例如,攻击者可能坚称没有收到包裹递送,强制Agent调用工具取消递送或退款。
传统越狱
AI Agent不能免疫传统越狱。除了上述列出的漏洞外,AI Agent仍然容易受到基础越狱尝试的影响,这可能强制Agent披露有害信息或绕过固有的安全护栏。重要的是要注意,部署Agent系统并不能消除来自更简单LLM系统的漏洞类别,而是由于Agent所需的多层架构而增加风险。因此,AI Agent仍应具有适用于对话AI或基础模型的深度防御措施,如红队测试和护栏。
Agent安全最佳实践
在许多方面,AI Agent应该像安全团队处理组织内员工的访问控制一样对待。Agent与人类一样,根据工作记忆、可用工具和可访问的知识源做出决策并执行任务。像员工一样,AI Agent通常希望与更大目标保持一致,表现出色地执行任务,但也容易犯错,披露信息或受到社会工程攻击。
AI Agent的最佳实践是强制执行最小特权和需要知道的原则。AI Agent的访问权限(包括对向量数据库、工具和第三方API的访问)应定期审计和重新认证。所有Agent活动都应记录并监控,并为可疑活动设置警报,不再使用的AI Agent应该停用。
部署AI Agent时,请考虑以下控制措施:
AI Agent 安全控制措施
工具清单
- 维护 AI agent 可访问的工具、函数、API 和数据库清单
- 列出 AI agent 预期任务及通过工具访问应实现的目标
- 根据授权任务(读取、写入、删除等)、数据敏感程度(机密、高敏感、PHI、PCI、PII)和暴露范围(公开、内部)记录 AI agent 风险等级
最小权限授权
- 严格限制 AI agent 使用工具的权限。例如,若 AI agent 仅需在数据库上执行查询,就不应有删除、新或删表权限,最好将其限制在预设查询或准备好的语句范围内
- 同样要严格控制能访问工具的用户权限
- 限制对 AI agent 的访问,必要时立即终止
输入输出净化
- 对 AI agent 的提示和输出进行验证和净化
- 部署数据泄漏防护技术,降低敏感信息外泄风险
- 实施 API 请求签名验证,防止篡改
系统提示配置
- 视系统提示中所有信息为公开内容
- 严格隔离私有数据与提示上下文
- 禁止 agent 透露提示或上下文信息,并设置防护机制
Agent 沙箱化
- 将 AI agent 置于安全隔离环境中,限制资源和功能访问
- 与生产环境和网络分离,降低 SSRF 攻击风险
制定 AI 行为准则
- 联合法律、营销、合规和安全团队建立并执行 AI 行为准则
- 开展红队测试,确保 AI agent 不违反行为准则或其他治理政策
监控和预警
- 为 AI agent 建立监控预警系统,检测异常行为
- 实施适用于其他系统或员工的辅助控制措施,如欺诈预警机制和敏感交易的多因素认证
小结
参考资料
[1]https://www.promptfoo.dev/blog/agent-security/: https://www.promptfoo.dev/blog/agent-security/
[2]Technical Blog: Strengthening AI Agent Hijacking Evaluations: https://www.nist.gov/news-events/news/2025/01/technical-blog-strengthening-ai-agent-hijacking-evaluations
如需授权、对文章有疑问或需删除稿件,请联系 FreeBuf 客服小蜜蜂(微信:freebee1024)



![[Meachines] [Medium] Carrier SNMP+CW-1000-X RCE+BGP劫持权限提升](https://image.3001.net/images/20250329/1743237218_67e7b062ea4d634ec472d.png)

 网信中国
网信中国


- 40 文章数
- 16 关注者