


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

- 关注
一. 软件供应链简介
1.1 软件供应链安全
软件供应链安全指的是确保软件供应链中的各个环节和组件不受恶意攻击或未经授权的篡改,以保证软件交付的完整性、可信性和可靠性。软件供应链是指涉及开发、测试、集成、部署等多个环节的软件开发和交付过程,其中包括了供应商、开发者、第三方库、依赖组件、工具和用户等各种参与者。
软件供应链安全面临多种威胁和风险,其中包括以下几个方面:
恶意代码注入:黑客可以在软件开发过程中注入恶意代码,这些代码可能会在软件运行时执行恶意操作,如窃取敏感信息、破坏系统功能等。依赖关系风险:软件通常会依赖于许多第三方库和组件,而这些依赖可能存在漏洞或被滥用。如果攻击者能够操纵或替换这些依赖,就可能导致整个软件链的安全问题。开发环境恶意篡改:黑客可以通过恶意修改开发工具、框架或编译器,来操纵或损害软件的构建过程,从而在软件中插入后门或漏洞。不安全的交付渠道:软件交付过程中,如果传输渠道不安全,攻击者可能利用中间人攻击、篡改软件包等手段,在传递过程中对软件进行恶意篡改或注入恶意代码。
二. 软件供应链安全与大模型结合点
由于大模型拥有一定的检测能力、生成能力、理解能力,与软件供应链安全摩擦出新的火花。软件供应链的威胁检测拥有了新的检测手段,大模型供应的代码安全性得到了注重,对软件供应链事件分析等高复杂度任务,大模型也有部分能力进行处理。
2.1 软件供应链漏洞检测
在软件供应链中,往往需要针对引入的他人代码进行安全检测,针对已知漏洞往往使用SCA技术来进行识别,针对未知漏洞需要加以静态分析、动态分析等技术判断代码质量,在大模型出现之后,有学者使用大模型对代码中的漏洞进行检测,本文主要研究目前学术界使用大模型的方法以及效果,不对研究细节进行探究。大模型目前在漏洞检测方面应用效果较好,将漏洞数据投喂大模型,表现出较好的检测效果,有学者研究大模型生成的代码的安全性,或使之更可靠。
Ferrag M A等人[7]创造了一种基于大型语言模型(LLMs)的创新模型架构SecureFalcon,用于软件漏洞检测和网络安全应用。SecureFalcon是在FalconLLM基础上进行微调优化训练而成的,通过区分易受攻击和非易受攻击的C代码样本来检测软件漏洞,具体架构如1所示。研究团队构建了一个新的训练数据集FormAI,利用生成式人工智能(AI)和形式验证的方法进行构建,以评估SecureFalcon的性能。研究结果显示,SecureFalcon在软件漏洞检测方面的准确率达到了94%,凸显了其在重新定义网络安全中的软件漏洞检测方法方面的重要潜力。
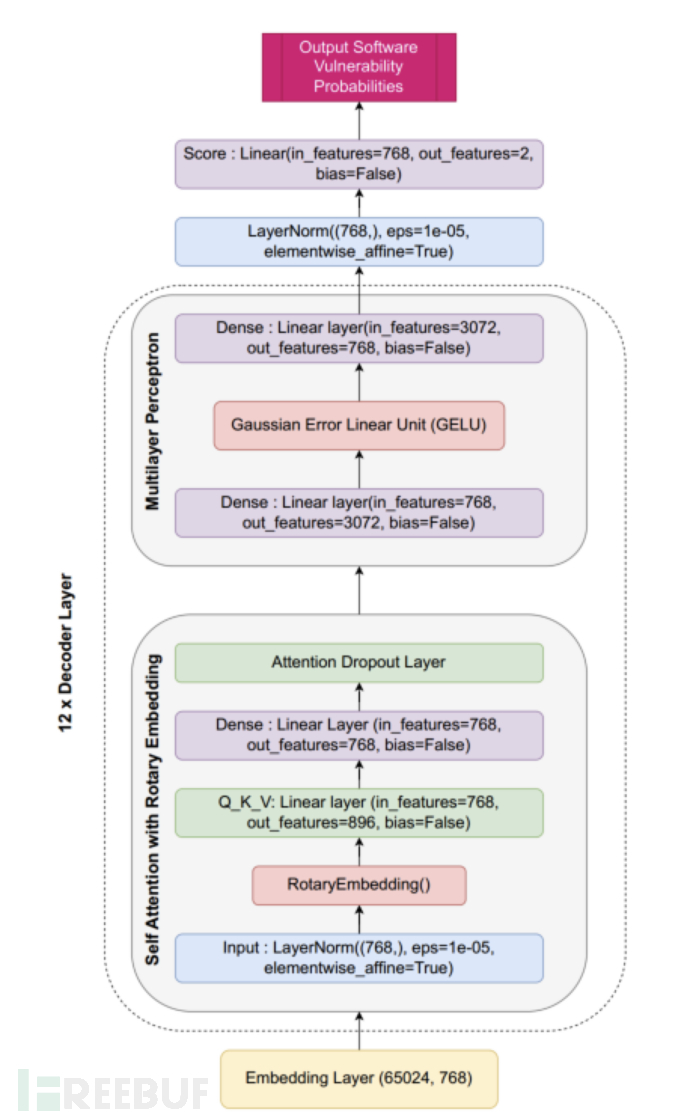
图1 SecureFalcon模型架构图
Bakhshandeh A等人[2]提出了使用ChatGPT进行Python漏洞检测的方法,将适当的提示以及易受攻击的数据提供给ChatGPT3.5,并将其与三种静态应用程序安全测试工具(Bandit、Semgrep和SonarQube)进行了比较。实验结果表明,ChatGPT具有降低误报率和漏报率的潜力,有望用于Python源码的漏洞检测。这为利用自然语言处理技术进行代码安全性分析提供了一种新的思路和方法。
Omar M等人[10]提出了一种新颖的基于Transformer的漏洞检测框架VulDetect。现有的深度学习模型,如卷积神经网络(CNN)和长短期记忆网络(LSTM),虽然能够准确识别易受攻击的代码模式,但需要大量计算资源,导致实时部署的可行性不高。为此,Omar M等人通过对预训练的大型语言模型(GPT)在多个易受攻击代码基准数据集上进行微调,提出了一种基于Transformer的漏洞检测框架VulDetect,具体检测架构如图2所示。实证结果显示,该框架能够以高达92.65%的准确率识别易受攻击的软件代码。与两种最先进的漏洞检测技术SyseVR和VulDeBERT相比,Omar M等人提出的技术表现更优。这一研究为基于Transformer的漏洞检测方法提供了新的思路,并取得了令人满意的实验结果。
图2 VulDetect检测器检测过程图
Cheshkov A等人[5]基于真实世界数据集,使用CWE漏洞的二元分类和多标签分类任务进行了评估。由于ChatGPT模型在编程挑战和高层次代码理解等其他基于代码的任务中表现良好,因此Cheshkov A等人选择了该模型进行评估。然而,Cheshkov A等人发现ChatGPT模型在代码漏洞检测的二元分类和多标签分类任务中表现不如一个普通分类器。
Zhang C等人[18]研究了使用ChatGPT进行漏洞检测的性能,并通过设计不同的提示信息来改进模型的性能。与之前的研究相比,Zhang C等人充分考虑到了大型语言模型(LLM)的特点,并提供了针对漏洞检测的具体提示设计。在基本提示的基础上,通过引入结构和顺序辅助信息来改进提示设计,并利用ChatGPT记忆多轮对话的能力,设计了适合漏洞检测的提示。研究团队在两个漏洞数据集上进行了大量实验,证明了使用加强版的提示信息进行漏洞检测的有效性。同时,还对使用ChatGPT进行漏洞检测的优点和缺点进行了分析。这一研究为利用ChatGPT进行漏洞检测提供了新的思路和改进方法。
Chen Y等人[4]制作了一种新的漏洞源代码数据集,对使用深度学习和LLMs等11种模型进行对比,研究结果如图3所示,由于高误报率、低F1得分以及难以检测复杂CWE,深度学习在漏洞检测方面仍然不够成熟。基于深度学习模型泛化挑战仍是重要难点。增加训练数据量可能不会进一步提高深度学习模型在漏洞检测方面的性能,但可能有助于提高对未见项目的泛化能力。Chen Y等人证明了大型语言模型(LLMs)是基于机器学习的漏洞检测的有希望的研究方向,在实验中表现优于具有代码结构特征的图神经网络(GNNs)。
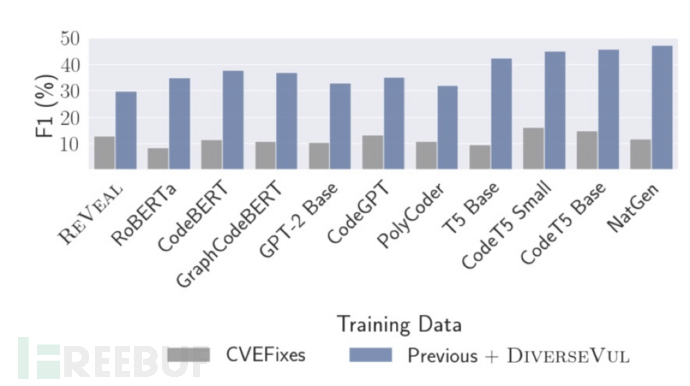
图3 11种模型对比结果图
Ahmad B等人[1]研究了一种名为FLAG的新方法,旨在协助人工调试员识别和定位代码中的安全和功能缺陷。FLAG基于生成式人工智能,特别是大型语言模型(LLMs)的词法能力。该方法输入一个代码文件,然后提取并重新生成文件中的每一行代码以进行自我比较。通过将原始代码与LLM生成的替代代码进行比较,可以将显著差异标记为异常,以供进一步检查,其中包括与注释的距离和LLM的置信度等特征也有助于这种分类,具体如图4所示。这减少了设计人员对代码的检查搜索空间。与该领域的其他自动化方法不同,FLAG不依赖于编程语言,可以处理不完整(甚至无法编译)的代码,并且不需要创建安全属性、功能测试或规则定义。Ahmad B等人探讨了帮助LLMs进行这种分类的特征,并评估了FLAG在已知漏洞上的性能。研究人员使用C、Python和Verilog的121个基准测试,每个基准测试都包含已知的安全或功能弱点。Ahmad B等人使用OpenAI的code-davinci-002和gpt-3.5-turbo两种最新的LLMs进行实验,他们的方法也可以被其他模型使用。FLAG能够识别出101个缺陷,并将源代码的搜索空间减少到12%-17%。
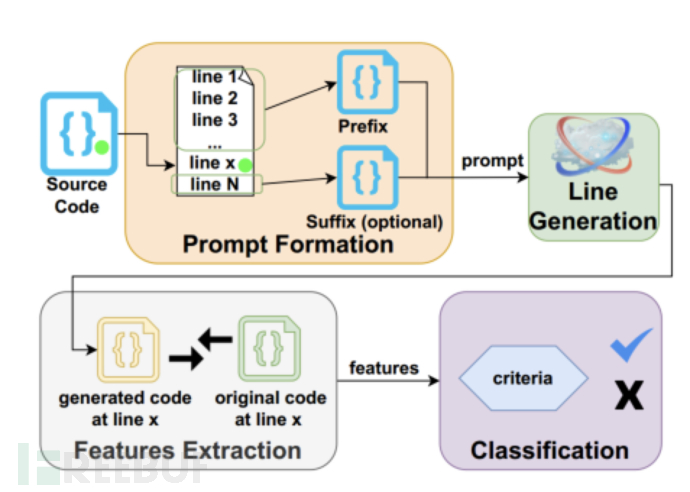
图4 FLAG查询代码行异常过程图
Deng Y等人[6]研究了一种名为FuzzGPT的技术,旨在改进使用大型语言模型(LLMs)进行深度学习库模糊测试的能力。传统的技术需要人工设计生成器,并确保生成的程序在语法和语义上是有效的,而FuzzGPT通过利用LLMs的内在能力(包括微调和上下文学习)将这个过程完全自动化,同时具有普适性和适用性。LLMs生成的程序往往遵循与它们训练语料库中的典型程序相似的模式和标记,而模糊测试则偏向于涵盖边界情况或不太可能人工产生的异常输入。为了解决这个问题,FuzzGPT提出了一种新的方法,利用历史的Bug触发程序作为参考,以引导LLMs合成不寻常的程序测试用例用于模糊测试,具体实现方法如图5所示。Deng Y等人介绍了FuzzGPT在不同LLMs上的应用,重点关注了强大的GPT风格模型:Codex和CodeGen。此外,还展示了最近的ChatGPT的指导跟随能力在有效进行模糊测试时的潜力。通过在两个流行的深度学习库(PyTorch和TensorFlow)上进行的实验研究,FuzzGPT表现出比之前的TitanFuzz更好的性能,检测到76个Bug,其中49个被确认为以前未知的Bug,包括11个高优先级的Bug或安全漏洞。总结起来,FuzzGPT利用LLMs的能力自动生成异常输入程序用于深度学习库的模糊测试,提高了Bug检测的效果。它通过引导LLMs合成不寻常的程序,并利用历史Bug触发程序作为参考,提高了模糊测试的覆盖率和发现率。
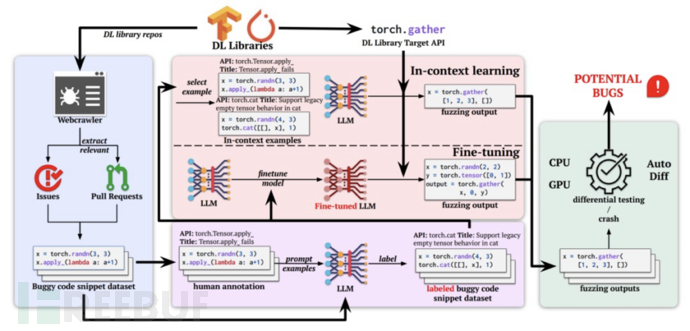
图5 FuzzGPT实现方法图
2.2 大模型供应代码的安全性检查
大模型能够为人们编写代码提供以下几种方式的帮助:
自动完成:大模型可以根据输入的部分代码,预测并推荐接下来可能的代码片段。这对于减少编码过程中的手动敲击和减少常见代码片段的输入时间非常有用。
错误修正:大模型可以检测到潜在的语法错误、逻辑错误或潜在的错误做法,并提供相关建议和修复策略。这可以帮助开发人员更快地发现和纠正错误,提高代码的质量和可靠性。
代码生成:大模型可以根据开发人员提供的高级指令或意图,生成相应的代码。使用这种方式,开发人员可以通过提供高级描述,而无需冗长的手动编码来实现复杂的功能或任务。
文档和注释:大模型可以帮助编写文档和注释,提供关于代码功能、参数和用法的提示和建议。这可以改善代码的可读性,并帮助其他开发人员更好地理解和使用代码。
然而大模型供应的代码也会伴随着一些列的安全问题,有学者研究大模型生成的代码质量,或如何调教大模型生成更加安全可靠的代码。
为此,Tony C等人[16]提出了一个名为LLMSecEval的数据集,其中包含150个自然语言提示,可用于评估这些模型的安全性能。这些提示是针对MITRE的Top 25 Common Weakness Enumeration(CWE)排名中列出的各种安全漏洞的代码片段的自然语言描述。数据集中还提供了安全实现示例,以便对比分析LLMs生成的代码。最后,Tony C等人展示了如何利用LLMSecEval来自动评估由自然语言描述自动生成的代码片段的安全性。
Copilot是使用大模型基于开源GitHub代码进行训练的语言模型,但由于代码经常存在漏洞,因此考虑到Copilot处理的大量非审查代码,该语言模型肯定会从易受攻击的有缺陷代码中学习。Pearce H等人[21]研究通过在与高风险网络安全弱点相关的场景下提示Copilot生成代码,并从MITRE的“Top 25”常见弱点枚举(CWE)清单中选择。通过探索Copilot在弱点多样性、提示多样性和领域多样性等三个不同的代码生成方面的表现,共产生89个不同的场景,生成1,689个程序。最终发现大约40%的程序存在漏洞。
Perry N等人[12]进行了第一项大规模用户研究,考察用户与AI代码助手在不同编程语言下解决各种安全相关任务的互动的代码安全性。总体而言,发现有AI助手(基于OpenAI的codex-davinci-002模型)的参与者编写的代码明显不够安全,而没有AI助手的参与者编写的代码更加安全。此外,有AI助手的参与者更容易相信他们编写的代码是安全的,相比之下没有AI助手的参与者则相对较少。此外,还发现对AI的信任程度较低且更多地与提示语言和格式进行交互(例如重新表述、调整温度),所提供的代码中安全漏洞较少。最后,为了更好地指导未来基于AI的代码助手的设计,对参与者的语言和互动行为进行了深入分析,并将用户界面发布为工具,以便未来进行类似的研究。
Khoury R等人[9]通过实验来探究ChatGPT生成的代码究竟是否安全的问题,具体地要求ChatGPT生成一些程序,并评估所得源代码的安全性。并进一步探讨了通过适当的提示是否可以促使ChatGPT改善安全性,并讨论了使用AI生成代码的伦理方面的问题。结果表明,ChatGPT意识到潜在的漏洞,但往往生成的源代码对某些攻击不够健壮。在研究中,对ChatGPT从GPT-3.5系列的模型微调后生成的代码进行了安全性评估实验。具体而言,要求ChatGPT生成5种不同编程语言(C、C++、Python、html和Java)的21个程序,然后评估生成的程序并询问ChatGPT代码中是否存在任何漏洞。发现,在多个情况下,ChatGPT生成的代码远低于大多数场景下的最低安全标准。事实上,当被询问生成的代码是否安全时,ChatGPT能够识别出不安全。然而,如果明确要求,聊天机器人在许多情况下可以提供更安全的代码版本。
Sandoval G等人[13]讨论了使用大型语言模型(LLMs)作为人工智能编码助手的影响,特别是最近的研究显示LLMs可能会提供含有网络安全漏洞的建议。研究者进行了一项安全驱动的用户研究,通过此研究考察了学生程序员在LLMs的协助下编写代码时的情况。他们要求参与者在C语言中实现单向链接列表结构,并对完成的代码进行了功能和安全性方面的评估,使用了手动和自动方法来检查代码。结果显示,在这种低层次的C语言中使用指针和数组操作时,LLMs的使用对安全影响很小,参与者编写出的代码的安全漏洞率不会比未经过AI协助的控制组高出10%。研究者还发现,63%的漏洞源于人类编写的代码,36%的漏洞位于给出的建议中。
Storhaug A等人[15]提出了一种新的漏洞约束解码方法,以减少由基于transformer的大型语言模型(LLM)生成的代码中存在的漏洞数量。通过使用一个小型的标记漏洞代码数据集,对LLM进行微调,使其在生成代码时包含漏洞标签,充当嵌入式分类器。然后,在解码过程中,禁止模型生成这些标签,以避免生成存在漏洞的代码。该方法的评估选择了以以太坊区块链智能合约(SCs)的自动完成为案例研究,因为SC安全性要求严格。首先,在从2,217,692个SC中去除重复后,使用186,397个以太坊SC对具有60亿参数的GPT-J模型进行了微调,微调过程使用了十个GPU,耗时超过一周。结果显示,微调后的模型可以生成具有平均BLEU(双语评估协助下的理解)得分为0.557的SCs。然而,自动完成的SC中的许多代码都存在漏洞。通过使用包含不同类型漏洞的176个SC中漏洞行之前的代码来自动完成代码,Storhaug A等人发现超过70%的自动完成代码存在安全问题。因此,Storhaug A等人进一步在其他941个包含相同类型漏洞的易受攻击SC上进行了微调,并应用了漏洞约束解码。微调过程只需四个GPU,耗时仅一个小时。然后,再次自动完成了176个SC,并发现该方法可以识别出62%的待生成代码存在漏洞,并避免生成其中的67%,表明该方法可以有效地避免自动完成代码中的漏洞。
Pearce H等人[11]研究了利用大型语言模型(LLMs)来修复程序中的网络安全漏洞。该团队使用了多个商用和开源的LLMs,以及自己训练的模型,对多种合成、手工制作和真实世界的安全漏洞场景进行了测试,并检查了设计合适提示用于引导LLMs生成修复后的不安全代码的挑战。虽然该方法在修复方面表现出了很大的潜力,例如在手工制作或合成数据时,LLMs可以共同修复100%的测试场景,但在评估大量历史真实世界示例代码时,其功能正确性尚存在着一些挑战。
2.3 大模型与其他软件供应链安全技术结合点
软件物料清单 (SBOM) 通过提供软件开发中不可或缺的组件和依赖项的详细清单,成为确保软件供应链安全的关键支柱。然而,共享 SBOM 存在大量挑战,包括潜在的数据篡改以及软件供应商在披露SBOM全面信息方面参差不齐。这些障碍阻碍了 SBOM 的广泛采用和使用,凸显了对更安全、更灵活的 SBOM 共享机制的需求。
Xia B等人[17]针对这些挑战提出了一种新颖的解决方案,通过引入区块链支持的 SBOM 共享架构,架构细节图6所示,利用可验证的凭证来允许选择性披露。这种策略不仅提高了安全性,而且提供了灵活性。此外,Xia B等人扩大了 SBOM 的范围以涵盖人工智能系统,从而创造了人工智能物料清单(AIBOM)这一术语。这一扩展的动机是人工智能技术的快速发展以及跟踪人工智能软件和系统的谱系和组成的需求不断升级。Xia B等人的解决方案的评估表明了所提出的 SBOM 共享机制的可行性和灵活性,为保护(AI)软件供应链提供了一种新的解决方案。
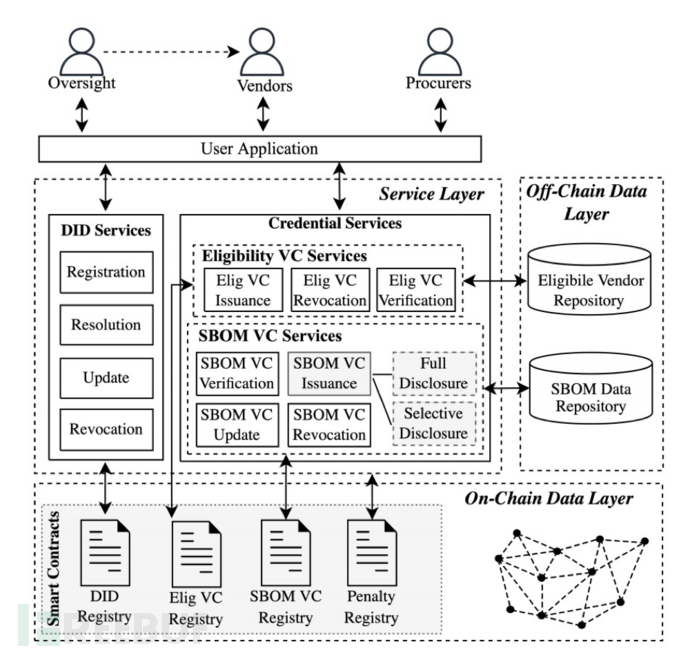
图6 区块链应用在Sbom架构图
"软件供应链事故"指的是发生在软件供应链中的安全事件或漏洞。软件供应链是一个涉及多个环节的过程,包括软件的开发、测试、交付和维护等阶段。如果在这些环节中存在安全漏洞或被恶意攻击,就会导致软件供应链事故。
Singla T等人[14]使用大型语言模型(LLMs)来分析历史上发生的软件供应链事故。他们使用LLMs来复制Cloud Native Computing Foundation(CNCF)成员对69起软件供应链安全。失败的手动分析过程,分析过程如图7所示。为了对这些故障进行分类,作者为LLMs开发了一些提示,包括四个维度:威胁类型、意图、性质和影响。研究结果表明,GPT 3.5对这些维度的分类准确率平均为68%,而Bard的准确率为58%。研究结果表明,LLMs可以有效地对软件供应链事件进行分类、描述,但尚不能取代人工分析师的角色。
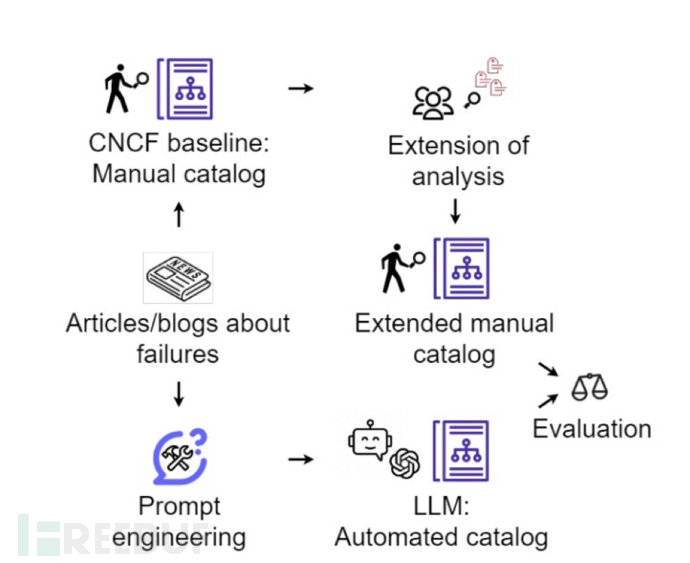
图7 使用大模型分类软件供应链事件过程图
在软件供应过程中,检测供应代码进行漏洞检测具有重大意义,静态分析工具是最常用的,并且具有固有的误报率,对开发人员的生产力提出了严峻的挑战。大型语言模型 (LLM) 为这些长期存在的问题提供了一个有希望的解决方案。FalconLLM 在识别复杂模式和复杂漏洞方面显示出巨大潜力。
第三方包在软件供应链中供应关系非常庞大,Chen T等人[3]提出了一种名为VulLibGen的生成方法,旨在解决现有SCA漏洞报告中缺乏记录受影响库名称列表的问题。该方法利用大型语言模型(LLM)的巨大进展,通过漏洞的描述来生成与之相关的可能受影响的库名称列表,以实现高准确性。VulLibGen还包括输入扩充技术,用于帮助识别训练过程中未出现的零样本受影响库,以及后处理技术,用于处理VulLibGen的错误识别。Chen T等人使用三种最新的漏洞识别方法对开源数据集VulLib进行了评估,结果显示VulLibGen的平均F1得分为0.626,而其他方法仅为0.561。通过后处理技术,VulLibGen的F1@1平均改进率为9.3%。
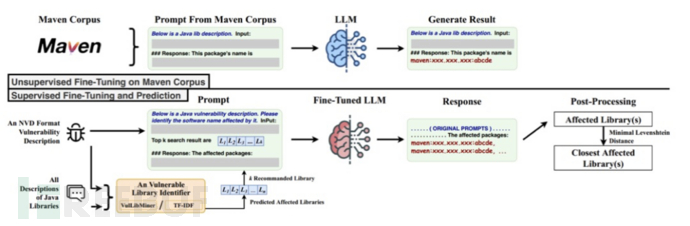
图8 使用大模型分析供应链漏洞影响的组件列表过程图
Jin M等人[8]针对软件开发生命周期中缺陷的引入、识别和解决等问题,提出了一种基于Transformer的程序修复框架InferFix。该方法结合Retriever-Transformer编码器模型和Generator-大型语言模型,通过增加语义类型注释和从外部检索的语义相似修复来细化程序修复过程,有错误的commit由 Infer 静态分析器检测到,该分析器用于制作一个提示,其中包含错误类型注释、位置信息、相关语法层次结构 (eWASH)在大模型的支持下修复严重安全和性能缺陷,修复过程由图9所示。Jin M等人构建了InferredBugs作为测试数据集,经过实验证明,InferFix比强大的LLM基线方法表现更好,C#生成修复的Top-1准确率为65.6%,Java为76.8%。同时,Jin M等人还讨论了InferFix在Microsoft的部署情况,将其与Infer整合,提供端到端的解决方案以自动化软件开发流程。
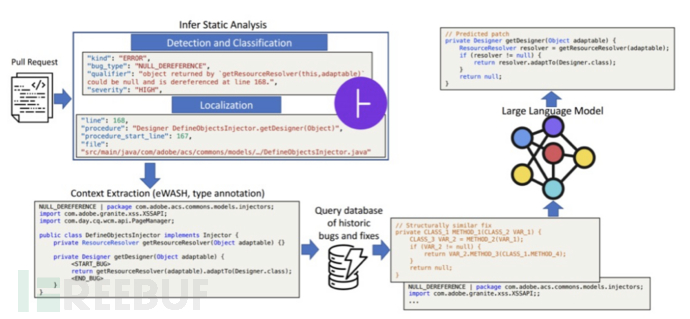
图9 使用大模型解决软件开发工作流缺陷自动化过程图
三. 总结
在漏洞检测方面,多个团队对大模型以及普通静态分析检测方法、最新深度学习检测方法进行比较,绝大部分团队的实验结果中对大模型检测效果非常优秀,甚至高达92.65%的准确率,但有实验结果表明基于ChatGPT和GPT-3的大模型在分类任务上表现不如一个普通分类器。最新部分团队,对大模型的改进结构进行漏洞检测优化。有研究团队甚至将大模型使用在FUZZ测试工具优化方面,使用历史的Bug触发程序作为参考,引导变异种子的生成,将源代码的搜索空间减少到12%-17%。
大模型在生成代码方面,在容易触发漏洞场景下,2021年,所生成的代码40%含有漏洞,在2022年,有人实验论证生成的代码远低于大多数场景下的最低安全标准,而有人研究结果为63%的漏洞源于人类编写的代码,36%的漏洞位于给出的代码中,认为生成的代码优于人工代码。很多试验结果表明,虽然给出很多不安全的代码,但是在明确要求下,大模型能够写安全的代码;大模型能够认识到自己的漏洞代码有危害并加以纠正。
因此有人对大模型在写代码方面进行纠正微调,使用漏洞代码生成负标签,在大模型解码过程中,不允许生成含有这些标签的代码;有团队添加提示词,设计、引导大模型对自己生成的漏洞代码进行修改,并达到100%修复的效果。
针对软件供应链安全其他方面,大模型的供应链也需要保护,例如:维护AIBoms;大模型能够对软件供应链事件进行分类(威胁类型、意图、性质和影响),但仍然不能帮助人们对事件进行分析;大模型在软件开发生命周期中能够对缺陷的引入进行识别和解决,但是准确率一般。大模型还能够针对使用的第三方软件进行缺陷检测,但效果只比经典静态分析方法好一点。
将大模型应用于软件供应链安全领域目前处于初步尝试阶段,但经过测试,总体已取得不错的效果,假以时日进行调整优化,大模型能发挥出超常的水平。在未来大模型能够在软件供应链逻辑漏洞方面发挥出更大的优势,例如在软件集成过程对于他人API误用造成的逻辑漏洞;将模型进行调用图生成、理解等定向训练,降低静态分析固有的误报率;或扮演安全培训工程师的角色,定向生成特殊场景的漏洞代码及相关文档,完成对开发人员的培训。
参考文献
[1]. Ahmad B, Tan B, Karri R, et al. FLAG: Finding Line Anomalies (in code) with Generative AI[J]. arXiv preprint arXiv:2306.12643, 2023.
[2]. Bakhshandeh A, Keramatfar A, Norouzi A, et al. Using ChatGPT as a Static Application Security Testing Tool[J]. arXiv preprint arXiv:2308.14434, 2023.
[3]. Chen T, Li L, Zhu L, et al. VulLibGen: Identifying Vulnerable Third-Party Libraries via Generative Pre-Trained Model[J]. arXiv preprint arXiv:2308.04662, 2023.
[4]. Chen Y, Ding Z, Chen X, et al. DiverseVul: A New Vulnerable Source Code Dataset for Deep Learning Based Vulnerability Detection[J]. arXiv preprint arXiv:2304.00409, 2023.
[5]. Cheshkov A, Zadorozhny P, Levichev R. Evaluation of ChatGPT Model for Vulnerability Detection[J]. arXiv preprint arXiv:2304.07232, 2023.
[6]. Deng Y, Xia C S, Yang C, et al. Large language models are edge-case fuzzers: Testing deep learning libraries via fuzzgpt[J]. arXiv preprint arXiv:2304.02014, 2023.
[7]. Ferrag M A, Battah A, Tihanyi N, et al. SecureFalcon: The Next Cyber Reasoning System for Cyber Security[J]. arXiv preprint arXiv:2307.06616, 2023.
[8]. Jin M, Shahriar S, Tufano M, et al. Inferfix: End-to-end program repair with llms[J]. arXiv preprint arXiv:2303.07263, 2023.
[9]. Khoury R, Avila A R, Brunelle J, et al. How Secure is Code Generated by ChatGPT?[J]. arXiv preprint arXiv:2304.09655, 2023.
[10]. Omar M. Detecting software vulnerabilities using Language Models[J]. arXiv preprint arXiv:2302.11773, 2023.
[11]. Pearce H, Tan B, Ahmad B, et al. Examining zero-shot vulnerability repair with large language models[C]//2023 IEEE Symposium on Security and Privacy (SP). IEEE, 2023: 2339-2356.
[12]. Perry N, Srivastava M, Kumar D, et al. Do users write more insecure code with AI assistants?[J]. arXiv preprint arXiv:2211.03622, 2022.
[13]. Sandoval G, Pearce H, Nys T, et al. Lost at c: A user study on the security implications of large language model code assistants[J]. arXiv preprint arXiv:2208.09727, 2023.
[14]. Singla T, Anandayuvaraj D, Kalu K G, et al. An Empirical Study on Using Large Language Models to Analyze Software Supply Chain Security Failures[J]. arXiv preprint arXiv:2308.04898, 2023.
[15]. Storhaug A, Li J, Hu T. Efficient Avoidance of Vulnerabilities in Auto-completed Smart Contract Code Using Vulnerability-constrained Decoding[J]. arXiv preprint arXiv:2309.09826, 2023.
[16]. Tony C, Mutas M, Ferreyra N E D, et al. LLMSecEval: A Dataset of Natural Language Prompts for Security Evaluations[J]. arXiv preprint arXiv:2303.09384, 2023.
[17]. Xia B, Zhang D, Liu Y, et al. Trust in Software Supply Chains: Blockchain-Enabled SBOM and the AIBOM Future[J]. arXiv preprint arXiv:2307.02088, 2023.
[18]. Zhang C, Liu H, Zeng J, et al. Prompt-Enhanced Software Vulnerability Detection Using ChatGPT[J]. arXiv preprint arXiv:2308.12697, 2023.
- 0 文章数
- 0 关注者