


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

- 关注
 本文由
创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
本文由
创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
闲谈:
刚开始学习SIEM、态势感知这类产品的时,翻阅老外们的文章总是谈什么真阳性,假阳性告警、告警疲劳,当时在国内资料中没找到很合理的解释,慢慢就淡忘这件事了。随着慢慢深入工作,感觉大概理解了这些概念并且有了一些新的领悟。心血来潮写了这篇文章,想给刚接触SIEM类产品的新同学做一下科普吧,希望你看完本文后能不再对所谓"误报"无从先下手,从而缓解你的告警疲劳。
SIEM介绍:
既然要讲SIEM的告警疲劳,简单介绍一下SIEM。
概述:
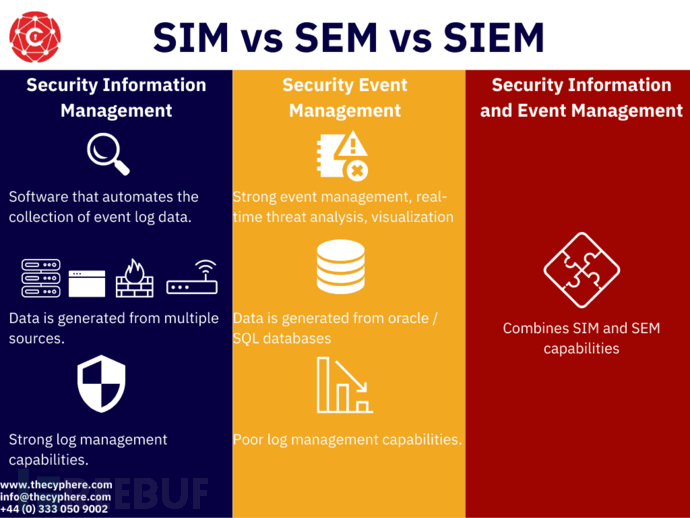
SIEM(Security Information and Event Management),安全信息和事件管理。
先简单讲一下其他概念。
SIM(Security Information Event Management):安全信息管理,也称日志管理,用于日志的长周期存储、日志分析,报告输出。
SEM(Security Event Management):安全事件管理,用于事件关联,告警监控,通知管理。
其实这样就不难理解,实际上SIEM=SIM+SEM,即SIEM类产品融合了两者的功能:该产品用于收集日志数据并进行长期存储,将收来的数据进行标准化处理,并通过日志搜索,关联告警,可视化图表,报告输出,告警通知等功能来提供安全事件的监测,调查,分析,响应的能力。
告警疲劳:
鉴于SIEM强大的数据采集存储、标准化能力,关联分析等能力,分析师将各种各样的数据源日志接入SIEM,其中包括了防火墙、行为管理、终端杀毒、IDS/IPS、WAF、VPN、堡垒机、3A、NDR、EDR、应用数据等等等。
本身当一个企业(默认是大型企业,如果是小型企业,我相信你也不会用SIEM这种产品)在做安全的基础建设时,铺的安全设备的数量就很多,随之而来告警的数量也会翻倍。更由于等保合规等要求,可能实际设备类型也会变得足够多,告警类型涉猎就更广泛。当两者碰撞起来就会造成海量告警。
实际海量告警对于分析师理论上也应该不足为惧,因为本身SIEM有标准化和关联的能力,理想状态下,其实告警不应该很多。但是以目前工作来看,理想终归是理想,目前现状依旧是有效告警被淹没在海量无效告警中。
告警疲劳的表面现象:
简单总结一句话:有效的告警(值得分析的告警)被淹没在海量无效告警(“误报”或不值得分析的告警)中,从而导致分析师力不从心,分析效率下降,对告警产生疲劳.
常表现出的现象如下:
- 上级监管部门通报XXX告警,我们的安全设备捕获到该攻击,但是SIEM的“误报”太大,我们还没分析到这个告警。
- 本身这个安全设备在没发送给SIEM时,我们长期优化后,这个设备的告警已经足够精准,“误报”已经足够少了,为什么接入SIEM后这个设备的告警量比原来多这么多?
- 由于现象一和二间接导致不如直接监控安原来全设备,但是推动SIEM建设又不得不用SIEM,导致陷入死循环。
误报:
既然聊到告警疲劳,肯定要涉及到误报。肯定要这里细心的同学可能发现,上面的"误报"我都打了引号。
这里讲一下工作来我对误报本质的看法。
个人观点:“误报”其实是甲乙双方对攻击认知的不同。
目前的安全设备规则库中已经很少那种写的很粗并且逻辑错误的误报了。像:单纯只匹配了个select就告警sql注入了。这种现象已经很少了,如果还存在,你应该推动你的安全设备的规则库进行升级啦或者你该思考一下你采购的安全设备了。
至于为什么说是双方认知的不同,举一个例子:
某天,作为分析师的你接到通知,NDR没有告警a.php。你经过分析,这次攻击行为没有payload,并没有成功,只是一次扫描尝试行为。
问题来了,甲方认为这是一种对攻击的漏报行为,设备出现问题。而你与厂商沟通,厂商的回复是:这是一种爬虫行为或这扫描尝试行为,这种行为不存在攻击特征,不应该告警。因为这种行为没有明显攻击特征,当有明显的payload或者代码执行特征,NDR一定会有代码执行或者webshell等告警。这种单纯的爬虫或者尝试的行为,不应该告警,如果这种都告警,会导致有海量告警。而且把这些无分析意义的扫描告警进行告警出来交给分析师来判断,这是一种不负责任的行为。
这个故事就是我所谓双方对攻击的认知不同,至于谁对谁错,见仁见智吧。至于为什么讲这个故事,是希望在工作中多思考事物的两面性,有些所谓的误报真的是误报么?所以我不是很喜欢国内用一个“误报”来一言蔽之,相比之下,我更倾向于国外对告警的分类,倒不是因为国外的月亮圆,只是说这种分类较为科学。
SIEM的告警分类:
国外对告警的分类,个人觉得应该是基于机器学习中的True positives(TP,真正)、True negatives(TN,真负)、False positives(FP,假正)、False negatives(FN,假负)的方法进行的分类。
即他们经常所谓的:
- 真阳性(True Positive),系统检测到了真实存在的攻击,即告警判断为异常告警。
- 伪阳性(False Positive),系统检测到了不存在的攻击。即告警判断为误报。
- 真阴性(True Negative),系统没有检测到真实存在的攻击。即告警判断为正常告警。
- 伪阴性(False Negative),系统检测不到真实存在的攻击。即告警误判为正常告警。

以上为国外的概念,是不是听的云里雾里。如果结合新冠来理解呢?
即:
- 真阳性:检测到感染新冠,并且真的感染,小阳人。(真实攻击行为。)
- 假阳性:检测感染新冠,其实并未感染,假阳人。(检测为攻击行为,其实为误报。)
- 真阴性:未感染新冠,正常人。(真正意义上的攻击失败,或业务正常平稳运行无告警)
- 伪阴性:检测到未感染新冠,实际已经感染,漏检或未检但已感染。(漏报攻击行为,或检测到攻击失败但实际上已经攻击成功)
理论上说,优秀的安全建设通过长期运营,真阳性告警应该最少,大部分为真阴性告警。不存在伪阴性告警,假阳性告警特别少。
而实际国内安全运营的现状:
大量伪阴性告警,即由于数据采集不全面、不做BAS检测、长期不做非HW的红蓝对抗而过分信任设备而漏报的攻击行为。
巨量的真阴性告警,即攻击失败的扫描器探测,端口扫描,爬虫等。
巨量的假阳性告警,即安全设备检测规则不严谨或不切合业务导致的误报,SIEM开箱自带的规则不适配导致的告警,一些失效的威胁情报告警等。
大量的“良性”的真阳性告警,即由于某些原因无法推进整改的大量弱口令告警,违规的办公软件的远控告警,开发人员为了偷懒写的脚本导致的SSH暴破等。
少量的“恶性”的真阳性告警,即真正攻击者的恶意攻击行为,已导致失陷。
PS:其实真阳性告警,并不存在良性与恶性的区分,对于攻击者而言有机可乘的都是薄弱点。这样说,仅是为了做区分。
SIEM告警疲劳的根本原因:
讲完告警的分类,和运营的现状,总结一下告警疲劳的根本原因。
结合工作经验,总结为以下几个原因:
- 不评估数据源的数据质量,无脑的将各种设备的日志,无脑接入SIEM,导致很多垃圾数据进入内置SIEM规则,导致大量无效告警。
- 安全设备不推动规则优化升级,导致规则版本低,或者某些检测逻辑不正确的规则不进行优化调整或关闭。
- SIEM内置的开箱规则,不评估数据源和规则的触发条件,导致大量的无效告警.
- 运营过程中,发现的业务某些问题不进行推动,也不对这些告警进行优化或抑制处理,导致告警量无法下降.
- SOAR未充分发挥其作用,只用来封IP,下线终端等,其实SOAR也可以处理一些低危告警,或者将某些告警进行威胁级别升级。
告警疲劳的解决方案:
- 减少假阳性告警的数量。
- 优化安全设备的规则,定期推动规则库的升级。对于检测逻辑不正确的规则反馈厂商整改或进行关闭。
- 对接入SIEM的数据源的字段质量进行评估,提供有效字段的数据酌情考虑接入SIEM。
- 对SIEM开箱规则进行评估,对于无效或不适用现场的规则的阈值及时间窗口等进行调整或关闭。减少告警数量的同时,也能减少引擎的压力。
- 及时更新威胁情报,或者考虑建设多源威胁情报。
- 检查SIEM上是否收到了安全设备上已经优化过的告警误报,排查原因。(有些安全设备未将白名单的日志进行单独区分,发送日志时也会将加白的告警一股脑发送出去。)
- 抑制“良性"的真阳性告警的数量。
- 对于段时间内无法推进解决的真正问题,进行告警抑制。(一般的SIEM工具都有该功能,一般叫做告警抑制或者告警归并。即单位时间窗口内,以某个条件作为分组条件,只产生一条告警。)
- 还是推荐积极推动业务整改某些真正的问题,例如明文传输,弱口令,违规行为等。
- 抑制真阴性告警的数量。
- 对于真正的”攻击失败“,端口扫描或扫描器的低危探测行为或爬虫等进行告抑制。
- 充分发挥SOAR的作用。
- 对于真正的”攻击失败“,用SOAR来处理关闭case或进行威胁级别降低,或者将某些“恶性”的真阳性告警进行威胁级别提升。
- 尽量减少或真正意义上不存在伪阴性告警。
- 可以进行BAS检测或红蓝对抗,并进行复盘,将攻击手法沉淀为规则。
总结:
SIEM的告警疲劳是业内的一个难题.告警疲劳会对分析师的分析效率造成巨大影响,并且有效告警被淹没到无效告警中,同时也会导致安全问题无法暴露,影响企业的安全.
如果你也面临文中提到的问题,可以参考文中的观点,或发散思维,提供更好的解决方法进行分享。群策群力,共同进步!
PS:非常感谢你能看到这里,以上为个人观点,欢迎一起交流讨论,:)
已在FreeBuf发表 0 篇文章
- 0 文章数
- 0 关注者