


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

 sec875
sec875- 关注
 本文由
sec875 创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
本文由
sec875 创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
企业安全SDLC之web技术侦察101
本文章适用于SDLC安全开发,web测试,渗透测试与利用开发。
如今的web是一个新技术新应用的聚合体,它们引入更多的安全问题与测试技巧 ------sec875
【本文属于第一部分:技术性侦察】
这些知识将帮助您发现更多的扫描工具所无法完成的测试,替换掉网上的POC,使用自己的脚本来安全测试,【第二部分:检测】。帮助开发人员,熟悉web安全的知识,引用安全的架构与思维来开发,在【第三部分:防御】。
本文引入参考资料错综复杂,大致参考资料如下:
推特UP主,油兔比UP主的材料以及推荐材料外链的外链的外链。
tryhackme场景
O'Reilly出版的《Web Application Security》
谷歌随缘遇到的材料
前置知识
需要企业级应用系统开发的初级认知,比如Java EE等
需要web安全与渗透测试的初级认知
需要观察力。需要去官网做数据关联。需要翻译英文单词。
需要感性的对待英文:名词(管它叫什么恐龙)与动词(注意力提高200%):王垠之《解密英语语法》
http://www.yinwang.org/blog-cn/2018/11/23/grammar
意识与认知
渗透测试人员使用各种预先构建的漏洞利用脚本进行操作是司空见惯的。
这些脚本或初始条件不对或带毒或不完善或具有缺陷或是个诱饵。
种种因素和需求表明:需要有人来构建利用脚本,识别利用脚本,检查利用脚本。
当我发现web安全漏洞时,可以简单的使用属于自己的POC来进行验证吗?
当自动化采集工具将数据收集回来之后,还是进一步的需要您来判断哪些数据有效。
知道的开发知识越多,侦察到的信息才能越多。否则没办法进一步来做信息收集。发现的漏洞更少。
观察,常规防御的绕过。
Web 应用程序之侦察
简单的侦察只需浏览 Web 应用程序并记录网络请求,从进入主页的每个功能点开始。注册,登录,验证码,重置密码?
我们应该假设仅能访问用户界面的一个子集。什么参数在定位其他用户界面?横向,纵向越权?什么参数代表着自己?找到这个也就可以表示,篡改它是不是就变成别人了?
增删改查?基于角色的访问控制?
我能测试认证与授权相关的漏洞吗?
从大局观来思考每一个功能点。我这测试账号本身就代表着组长,能查自己小组成员信息这算洞吗?
我们经常可以找到 API。它们与其他用户设置的权限进行比较。
如果我们具备逆向工程结构的适当技能,我们就不需要用户界面来了解应用程序如何运行应用程序的 API 以及这些 API 接受的payload。
网络应用映射
浏览源码,js文件,将API等端点都记录出来。具体实施请参考:https://shubs.io/
现代 Web 应用程序的结构
引入大量独立工作的个体程序,通过API组合成一个web应用聚合体。
现代与传统 Web 应用程序
十年前,大多数 Web 应用程序都是使用服务器端框架呈现 HTML/JS/CSS 页面。客户端简单的通过HTTP请求来更新。
此后不久,随着 Ajax(异步 JavaScript 和 XML)的兴起,Web 应用程序更频繁地使用 HTTP,允许通过 JavaScript 从页面会话中发出网络请求。
今天,通过网络协议进行通信的两个或多个应用程序。这是当今的 Web 应用程序与十年前的 Web 应用程序之间的主要架构差异。
通过 (REST) API 连接多个应用程序。这些 API 是无状态的。它们实际上并不存储有关请求者的任何信息。
浏览器中运行的客户端程序,请求自己的数据,初始引导完成后不需要重载页面。
部署到 Web 浏览器的独立应用程序与多个服务器进行通信的情况并不少见。
今天的应用程序实际上通常是许多独立但共生的应用程序协同工作的组合体。您可以私下称它为 web 3.0。
node.js 允许 javascript在服务器端运行,无需PHP等后端编程语言。
现代 Web 应用程序可能使用以下几种技术:
REST API,JSON or XML,JavaScript,SPA framework (React, Vue, EmberJS, AngularJS),认证与授权系统,多台服务器,多个 Web 服务器软件包(ExpressJS、Apache、NginX) ,多种数据库 (MySQL, MongoDB, etc.),客户端上的本地数据存储(cookie、Web 存储、IndexedDB)
其他技术需要参考:Stack Overflow,其他书籍等。
还有本地存储请求的缓存 API,以及作为客户端到服务器(甚至客户端到客户端)通信的 Web 套接字。浏览器打算完全支持称为 Web 程序集的汇编代码变体,允许使用非 JavaScript 语言在浏览器中编写客户端代码。
从历史发展来看,每一次新技术都带来新的黑客活动视线转移。因此除了传统的web安全漏洞以外,还一直在诞生在新的web漏洞。
REST APIs
Representational State Transfer:表象状态转移,获取资源
REST API 旨在构建高度可扩展 Web 应用程序。 将客户端与 API 分开,但遵循严格的 API 结构,使客户端应用程序可以轻松地从 API 请求资源,而无需调用数据库或执行服务器端逻辑本身。
https://en.维科.org/wiki/Representational_state_transfer
简而言之:用户访问 http://www.example.com/articles/21 与20 表面,表象,页面都不一样。得到不同资源,管这玩意儿叫 REST API。
21这个数字被用于表示状态转移。REST API 可以如此种URL一样简单设局。但也可以非常复杂的设局:基于URI,基于HTTP方法,基于HTTP媒体类型等。
REST APIs 本身没有官方标准,大家似乎没有非常痛苦的基于标准和定义来称呼API,尽管不严谨,但他们很聪明的将API都视为 REST ful ,实施时有 HTTP 、 URI 、 JSON 和 XML。
这并不意味着 REST API 不能执行身份认证和授权——相反,授权应该被标记化并在每个请求上发送。
每个端点都可以定义一个特定的对象或方法
/moderators/joe/logs/12_21_2018 与 GET, POST, PUT, and DELETE
修改版主账号?:PUT /moderators/joe
删除日志文件?:DELETE /moderators/joe/logs/12_21_2018
每一种状态转移组合表示着很多的信息量,诸如Swagger 等工具可以轻松集成到应用程序中并记录端点信息。
Swagger,一个自动 API 文档生成器,旨在与 REST API 轻松集成
过去,大多数 Web 应用程序使用简单对象访问协议 (SOAP) 结构的 API。 与 SOAP 相比,REST 有几个优点:
请求目标数据,而不是函数;轻松缓存请求;高度可扩展
SOAP API 必须使用 XML数据格式,但 REST API 可以接受任何数据格式,通常使用 JSON。 与 XML 相比,JSON 更轻量且更易阅读,这也使 REST 在竞争中具有优势。
观察一下两者的表示法,显而易见,json很简洁。

遇到的大多数现代 Web 应用程序要么使用 RESTful API,要么使用提供 JSON 的类 REST API。总而言之,现状用的都是REST API
REST API漏洞:https://www.油兔比.com/watch?v=YPzMTKsBMnI
JavaScript 对象表示法
将json轻松转成js对象。
REST是一种架构规范,它定义了HTTP动词如何映射到服务器上的资源(API端点和功能)。 今天大多数的API使用JSON作为其运输数据格式。
以下的 JSON:
{
"first": "Sam",
"last": "Adams",
"email": "sam.adams@company.com",
"role": "Engineering Manager",
"company": "TechCo.",
"location": {
"country": "USA",
"state": "california",
"address": "123 main st.",
"zip": 98404
} }
可以在浏览器中轻松解析为 JavaScript 对象:
const jsonString = `{
"first": "Sam",
"last": "Adams",
"email" "sam.adams@company.com",
"role": "Engineering Manager",
"company": "TechCo.",
"location": {
"country": "USA",
"state": "california",
"address": "123 main st.",
"zip": 98404
}
}`;
// https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/JSON/parse
// JSON.parse() 将json字符串解析为,JavaScript对象
const jsonObject = JSON.parse(jsonString);
熟悉通读 JSON 字符串,也就是说您需要结合实际功能点翻译json单词,把握每个字段的含义,将payload放进去看看有什么反应。 在短时间内对各种 API 进行渗透测试时,能够快速解析这些并找到特定的信息将非常有价值。
JavaScript
今天的 Web 服务器运行在 Python、Java、JavaScript、C++ 等之上。 JavaScript 不仅是一种编程语言,而且还是 Web 浏览器中客户端脚本的唯一编程语言。甚至还在物联网设备上运行。
变量和范围
在 ES6 JavaScript(最新版本)中,有四种定义变量的方法:
// global definition 全局变量
age = 25;
// function scoped 函数作用域
var age = 25;
// block scoped 块作用域
let age = 25;
// block scoped, without reassignment 块作用域,不能被分配
const age = 25;
块,代码块:
哒哒哒 {
哒哒哒.... 此处代码块
}
函数作用域
const func = function() {
if (true) {
// 代码块
var age = 25; } # var 范围定为函数而不是块
console.log(age); # 返回25 不是函数作用域 就返回undefined
};
ECMAScript 6(JavaScript 规范)引入了 let 和 const —— 两种实例化对象的方式,它们的行为与其他现代语言中的方式更相似。
通常,您应该始终努力在代码中使用 let 和 const 以避免错误并提高可读性。
let age = 25; 块作用域,不能被分配啥意思?就是不能再被分配新的内存地址了。
实例化对象,涉及生成一个新的内存地址指向它,不然怎么实例化。不能被分配表示,不能再给它赋值内存地址值了。赋值即发生实例化对象。
Functions函数
在 JavaScript 中,函数是对象。 可以使用变量和标识符对它们进行分配和重新分配。
这些都是函数
// anonymous function
function () {};
// globally declared named function
a = function() {};
// function scoped named function
var a = function() { };
// block scoped named function
let a = function () {};
// block scoped named function without re-assignment
const a = function () {};
// anonymous function inheriting parent context
() => {};
// immediately invoked function expression (IIFE)
(function() { })();
第一个函数是匿名函数——这意味着它在创建后不能被引用。 接下来的四个只是根据提供的标识符指定范围的函数。 这与我们之前为年龄创建变量的方式非常相似。 第六个函数是一个速记函数——它与其父函数共享上下文(稍后会详细介绍)。 最后一个函数是一种特殊类型的函数,您可能只会在 JavaScript 中找到,称为立即调用的函数表达式。 在加载并在其自己的命名空间内运行时立即触发的函数。
Context上下文
一种哲学思维:我们在日常生活中说R闪,或者说满屏的getshell。R闪的上下文源于英雄联盟,而满屏的getshell源于另一个梗的上下文故事里。这些表达现象称为:上下文。
成为一名优秀的 JavaScript 开发人员需要学习五件事:范围、上下文、原型继承、异步和浏览器 DOM。
JavaScript 中的每个函数都有自己的一组属性和属于它的数据。将此称为这些函数的上下文。
可以使用关键字 this 引用存储在函数上下文中的对象:
const func = function() {
this.age = 25;
// will return 25
console.log(this.age);
};
// will return undefined
console.log(this.age); # 对一个没玩过英雄联盟的人说R闪,R闪。他肯定undefined
许多编程错误都是由于上下文难以调试造成的——尤其是当某些对象的上下文必须传递给另一个函数时。JavaScript 针对这个问题引入了一些解决方案,以帮助开发人员在函数之间共享上下文:
// create a new getAge() function clone with the context from ageData
// then call it with the param 'joe'
const getBoundAge = getAge.bind(ageData)('joe'); #同一个函数getAge()的ageData属性与它的数据,肯定都是上下文
// call getAge() with ageData context and param joe
const boundAge = getAge.call(ageData, 'joe');
// call getAge() with ageData context and param joe
const boundAge = getAge.apply(ageData, ['joe']);
另一个帮上下文的新增功能是箭头函数,也称为速记函数。 从父函数继承上下文共享给子函数,而无需显式调用/应用或绑定:
// global context
this.garlic = false;
// soup recipe
const soup = { garlic: true };
// standard function attached to soup object
soup.hasGarlic1 = function() { console.log(this.garlic); } // true
// arrow function attached to global context #箭头函数上下文
soup.hasGarlic2 = () => { console.log(this.garlic); } // false
掌握这些管理上下文的方法将使基于 JavaScript 的服务器或客户端的侦察变得更加容易和快捷。 您甚至可能会发现一些由这些复杂性引起的特定于语言的漏洞。
原型继承 prototypal inheritance
原型继承仅用于JavaScript中。
与许多建议使用基于类的继承模型的传统服务器端语言不同,JavaScript 被设计为具有高度灵活的原型继承系统。
不幸的是,因为很少有语言使用这种类型的继承系统,所以它经常被开发人员忽视,其中许多人试图将它转换为基于类的系统。
这里有一个隐式的生成原型对象的例子:
/*
* A vehicle pseudoclass written in JavaScript. 车辆伪类。
*
* This is simple on purpose, in order to more clearly demonstrate
* prototypal inheritance fundamentals. 原型继承基础。
*/
const Vehicle = function(make, model) {
this.make = make;
this.model = model;
this.print = function() {
return `${this.make}: ${this.model}`;
};
};
const prius = new Vehicle('Toyota', 'Prius'); # 还会隐式的生成 __proto__ 的单独对象
console.log(prius.print());
当在 JavaScript 中创建任何新对象时,还会创建一个名为__proto__的单独对象。 对象Vehicle 默认继承原型__proto__
这允许在对象之间进行比较,例如:
const prius = new Vehicle('Toyota', 'Prius');
const charger = new Vehicle('Dodge', 'Charger'); # 还会隐式的生成 __proto__ 的单独对象,原型对象
/*
* As we can see, the "Prius" and "Charger" objects were both
* created based off of "Vehicle".
*/
prius.__proto__ === charger.__proto__;
通常,开发人员会修改对象上的原型,从而导致 Web 应用程序功能发生混乱。 最值得注意的是,在运行时随时可以更改原型属性。
与更严格设计的继承模型不同,JavaScript 继承树可以在运行时更改。 因此,对象可以在运行时变形,整个原型都更新:
const prius = new Vehicle('Toyota', 'Prius');
const charger = new Vehicle('Dodge', 'Charger');
/*
* This will fail, because the Vehicle object
* does not have a "getMaxSpeed" function.
*
* Hence, objects inheriting from Vehicle do not have such a function
* either.
*/
console.log(prius.getMaxSpeed()); // Error: getMaxSpeed is not a function
/*
* Now we will assign a getMaxSpeed() function to the prototype of Vehicle,
* all objects inheriting from Vehicle will be updated in real time as
* prototypes propagate from the Vehicle object to its children.
*/
Vehicle.prototype.getMaxSpeed = function() { # 变形:分配getMaxSpeed(),整个原型都更新
return 100; // mph
};
/*
* Because the Vehicle's prototype has been updated, the
* getMaxSpeed function will now function on all child objects.
*/
prius.getMaxSpeed(); // 100
charger.getMaxSpeed(); // 100
在深入研究 JavaScript 安全性时,理解原型尤其重要,因为很少有开发人员完全理解它们。 此外,由于原型在修改时会传播给子代,因此在基于 JavaScript 的系统中发现了一种特殊类型的攻击,称为原型污染 prototype pollution 。 这种攻击涉及对父 JavaScript 对象的修改,无意中改变了子对象的功能。
原型污染漏洞:https://www.油兔比.com/watch?v=Z6CtDSx8C5k CVE-2021-23329
异步
由于浏览器必须定期与服务器通信,并且请求和响应之间的时间是非标准的(考虑有效负载大小、延迟和服务器处理时间),因此 Web 上经常使用异步来处理此类变化。
在同步编程模型中,操作按它们发生的顺序执行。 例如:
console.log('a');
console.log('b');
console.log('c');
// a
// b
// c
在异步编程模型中,解释器每次可能以相同的顺序读取这三个函数,但可能不会以相同的顺序解析。
异步日志记录功能的示例:
// --- Attempt #1 ---
async.log('a');
async.log('b');
async.log('c');
// a
// b
// c
// --- Attempt #2 ---
async.log('a');
async.log('b');
async.log('c');
// a
// c
// b
// --- Attempt #3 ---
async.log('a');
async.log('b');
async.log('c');
// a
// b
// c
不是强制一个接一个地完成请求,而是同时启动所有请求
在处理网络编程时,请求通常需要花费不同的时间、超时和不可预测的操作。 在基于 JavaScript 的 Web 应用程序中,这通常是通过异步编程模型处理的,而不是简单地等待请求完成后再启动另一个请求。 好处是巨大的性能改进,可以比同步替代方案快几十倍。
异步请求以前用回调,如今用异步函数(本质就是,承诺。)
在旧版本的 JavaScript 中,这通常是通过一个称为 回调 callbacks 的系统来完成的:
const config = {
privacy: public,
acceptRequests: true
};
/*
* First request a user object from the server. # 请求user
* Once that has completed, request a user profile from the server. # 请求profile
* Once that has completed, set the user profile config. #请求设置profile
* Once that has completed, console.log "success!"
*/
getUser(function(user) {
getUserProfile(user, function(profile) {
setUserProfileConfig(profile, config, function(result) {
console.log('success!');
});
});
});
虽然回调非常快速和高效,但与同步模型相比,它们很难阅读和调试。
后来的编程哲学建议创建一个可重用的对象,一旦给定的函数完成,它就会调用下一个函数。 这些被称为承诺 promises,它们在今天的许多编程语言中都有使用:
const config = {
privacy: public,
acceptRequests: true
};
/*
* First request a user object from the server.
* Once that has completed, request a user profile from the server.
* Once that has completed, set the user profile config.
* Once that has completed, console.log "success!"
*/
const promise = new Promise((resolve, reject) => { # 观察这里,多了一个可重用的对象
getUser(function(user) {
if (user) { return resolve(user); }
return reject();
});
}).then((user) => { # 这里发生了重用
getUserProfile(user, function(profile) {
if (profile) { return resolve(profile); }
return reject();
});
}).then((profile) => { # 这里发生了重用
setUserProfile(profile, config, function(result) {
if (result) { return resolve(result); }
return reject();
});
}).catch((err) => {
console.log('an error occured!');
});
自己搜一下,手册做数据关联

前面的两个示例都完成了相同的应用程序逻辑。 区别在于可读性和组织性。 基于承诺的方法可以进一步分解,垂直增长而不是水平增长,并使错误处理更容易。 Promise 和回调是可互操作的,可以一起使用,这取决于程序员的喜好。
处理异步的最新方法是异步函数。 与普通函数对象不同,这些函数旨在使处理异步变得轻而易举。
考虑以下异步函数:
const config = {
privacy: public,
acceptRequests: true
};
/*
* First request a user object from the server.
* Once that has completed, request a user profile from the server.
* Once that has completed, set the user profile config.
* Once that has completed, console.log "success!"
*/
const setUserProfile = async function() { # 异步函数
let user = await getUser();
let userProfile = await getUserProfile(user);
let setProfile = await setUserProfile(userProfile, config);
};
setUserProfile();
您可能会注意到这更容易阅读——太好了,这就是重点!
异步函数将函数转换为承诺 promises。 承诺内的任何方法调用都将停止在该函数内进一步执行,直到方法调用解决为止。 异步函数之外的代码仍然可以正常运行。
本质上,异步函数将一个普通函数变成了一个 promise。
浏览器 Browser DOM
DOM使用分层表示数据管理现代浏览器的状态。
DOM window object如下所示

JavaScript 是一种编程语言,与任何优秀的编程语言一样,它依赖于强大的标准库。 与其他语言中的标准库不同,这个库被称为 DOM。 DOM 提供经过良好测试且性能良好的例行功能,并在所有主要浏览器中实现,因此无论在何种浏览器上运行,您的代码都应该具有相同或几乎相同的功能。
与其他标准库不同,DOM 的存在不是为了填补语言中的功能漏洞或提供通用功能(即 DOM 的次要功能),而是主要提供一个通用接口,从该接口定义代表 Web 的分层节点树 页。 您可能不小心调用了一个 DOM 函数并假设它是一个 JS 函数。 这方面的一个例子是 document.querySelector() 或 document.implementation。
组成 DOM 的主要对象是window and document,每个对象都在一个名为 WhatWG 的组织维护的规范中仔细定义。
DOM标准:https://dom.spec.whatwg.org/
并非所有与脚本相关的安全漏洞都是由不正确的 JavaScript 造成的,有时可能是由不正确的浏览器 DOM 实现造成的 .
SPA框架
较旧的网站通常建立在结合了操作 DOM 的临时脚本和大量重复使用的 HTML 模板代码的基础上。这不是一个可扩展的模型,虽然它适用于向最终用户提供静态内容,但不适用于提供复杂的、逻辑丰富的应用程序。
当时的桌面应用软件功能强大,允许用户存储和维护应用程序状态。过去的网站不提供此类功能,尽管许多公司更愿意通过 Web 交付其复杂的应用程序,因为它提供了从易用性到防止盗版的许多好处。
单页应用程序 (SPA) 框架旨在弥合网站和桌面应用程序之间的功能差距。 SPA 框架允许开发复杂的基于 JavaScript 的应用程序,这些应用程序存储自己的内部状态,并由可重用的 UI 组件组成,每个组件都有自己的自我维护生命周期,从渲染到逻辑执行。
SPA 框架在当今网络上猖獗,支持最大和最复杂的应用程序(如 Facebook、Twitter 和 YouTube),其中功能是关键,并提供接近桌面的应用程序体验。
当今一些最大的开源 SPA 框架是 ReactJS、EmberJS、VueJS 和 AngularJS。 这些都是建立在 JavaScript 和 DOM 之上的,但从安全和功能的角度来看,它们都带来了额外的复杂性。
认证和授权系统
身份验证系统告诉我们“joe123”实际上是“joe123”而不是“susan1988”。
授权用于描述系统内部的流程,用于确定“joe123”可以访问哪些资源,而不是“susan1988”。
Authentication 认证
早期的身份验证系统。 例如,HTTP 基本身份验证通过在每个请求上附加 Authorization 标头来执行身份验证。 标头由包含 Basic:<base64-encoded username:password>的字符串组成。 服务器接收用户名:密码组合,并在每次请求时对照数据库进行检查。 显然,这种类型的身份验证方案有几个缺陷——例如,凭据很容易以多种方式泄露,从通过 HTTP 破坏的 WiFi 到简单的 XSS 攻击。
后来的认证发展包括摘要认证,它使用加密哈希而不是 base64 编码。 在摘要式身份验证之后,出现了大量用于身份验证的新技术和架构,包括那些不涉及密码或需要外部设备的技术和架构。
今天,大多数 Web 应用程序从一套身份验证架构中进行选择,具体取决于业务的性质。 例如,OAuth 协议非常适合希望与大型网站集成的网站。 OAuth 允许主要网站(例如 Facebook、Google 等)向合作伙伴网站提供验证用户身份的令牌。 OAuth 对用户很有用,因为用户的数据只需要在一个站点上更新,而不是在多个站点上更新——但 OAuth 可能很危险,因为一个被入侵的网站可能会导致多个被入侵的配置文件。
HTTP 基本认证和摘要认证今天仍然被广泛使用,摘要更受欢迎,因为它对拦截和重放攻击有更多的防御。 这些通常与 2FA 等工具结合使用,以确保身份验证令牌不会受到损害,并且登录用户的身份没有改变。
Authorization授权
授权系统更难分类,因为授权在很大程度上取决于 Web 应用程序内部的业务逻辑。 一般来说,设计良好的应用程序有一个集中的授权类,负责确定用户是否可以访问某些资源或功能。
如果 API 写得不好,他们将在每个 API 的基础上实施检查,手动仿造授权功能。
通常,如果您可以看出应用程序在每个 API 中重新实现了授权检查,那么该应用程序很可能有多个 API,这些 API 仅仅由于人为错误而导致检查不够充分。
一些应始终进行授权检查的常见资源包括设置/配置文件更新、密码重置、私人消息读取/写入、任何付费功能和任何提升的用户功能(例如审核功能)。
Web Servers
Apache 是开源的,已经开发了大约 25 年,几乎可以在每个 Linux 发行版以及一些 Windows 服务器上运行。
Apache 最大的竞争对手是 Nginx。 Nginx 运行着大约 30% 的 Web 服务器,并且正在快速增长。
尽管 Nginx 可以免费使用,但其母公司(目前为 F5 Networks)使用付费+ 模式,支持和附加功能需要付费。
Nginx 用于具有大量唯一连接的高容量应用程序,Nginx 架构每个连接的开销要少得多。
Microsoft IIS,尽管由于昂贵的许可证以及与基于 Unix 的开源软件 (OSS) 包缺乏兼容性,基于 Windows 的服务器的普及程度有所下降。 在处理许多 Microsoft 特定技术时,IIS 是 Web 服务器的正确选择,但对于试图在开源之上构建的公司来说可能是一种负担。
服务器端数据库
一旦客户端将要处理的数据发送到服务器,服务器通常必须保留这些数据,以便在以后的会话中可以检索到这些数据。 从长远来看,将数据存储在内存中是不可靠的,因为重启和崩溃可能会导致数据丢失。 此外,与磁盘相比,随机存取存储器相当昂贵。
在磁盘上存储数据时,需要采取适当的预防措施,以确保数据能够可靠、快速地检索、存储和查询。 当今几乎所有的 Web 应用程序都将用户提交的数据存储在某种类型的数据库中——通常根据特定的业务逻辑和用例来改变所使用的数据库。
SQL 数据库仍然是市场上最流行的通用数据库。 SQL 查询语言是严格的,但可靠快速且易于学习。 SQL 可用于从存储用户凭据到管理 JSON 对象或小图像 blob 的任何事情。 其中最大的是 PostgreSQL、Microsoft SQL Server、MySQL 和 SQLite。
当需要更灵活的存储时,可以使用无模式 NoSQL 数据库。 MongoDB、DocumentDB 和 CouchDB 等数据库将信息存储为松散结构的“文档”,这些文档灵活且可以随时修改,但在查询或聚合方面并不那么容易或高效。
在当今的 Web 应用程序环境中,还存在更高级和特定的数据库。 搜索引擎通常使用自己的高度专业化的数据库,这些数据库必须定期与主数据库同步。 这方面的一个例子是广受欢迎的 Elasticsearch。
每种类型的数据库都带有独特的挑战和风险。 SQL 注入是一种众所周知的漏洞原型,当查询未正确形成时,它可以有效地对抗主要 SQL 数据库。 但是,如果黑客愿意学习数据库的查询模型,则几乎任何数据库都可能发生注入式攻击。
考虑到许多现代 Web 应用程序可以同时使用多个数据库是明智的,而且经常这样做。 具有足够安全的 SQL 查询生成的应用程序可能没有足够安全的 MongoDB 或 Elasticsearch 查询和权限。 这是一种查询与权限上的又一道保障。
客户端数据存储
传统上,由于技术限制和跨浏览器兼容性问题,客户端上存储的数据最少。 这正在迅速改变。 许多应用程序现在将重要的应用程序状态存储在客户端上,通常以配置数据或大型脚本的形式存储,如果每次访问都必须下载它们会导致网络拥塞。
在大多数情况下,称为本地存储的浏览器管理的存储容器用于存储和访问来自客户端的键/值数据。 本地存储遵循浏览器强制的同源策略 (SOP),可防止其他域(网站)访问彼此的本地存储数据。 即使浏览器或选项卡关闭,Web 应用程序也可以保持状态于本地存储中。
称为会话存储的本地存储子集的操作相同,但仅在选项卡关闭之前保留数据。 这种类型的存储可以在数据更关键时使用,如果另一个用户使用同一台机器,则不应保留。
基于本地存储的渗透测试于本人翻译的《渗透测试:web存储(用户体验)》在安全客上面,还未处于发布状态,后半部分的翻译还在改进中。
在架构不佳的 Web 应用程序中,客户端数据存储也可能会泄露敏感信息,例如身份验证令牌或其他机密。
最后,对于更复杂的应用程序,当今所有主要的 Web 浏览器都提供了对 IndexedDB 的浏览器支持。 IndexedDB 是一个基于 JavaScript 的面向对象编程 (OOP) 数据库,能够在 Web 应用程序的后台异步存储和查询。
因为 IndexedDB 是可查询的,所以它提供了比本地存储更强大的开发人员界面。 IndexedDB 可用于基于 Web 的游戏和基于 Web 的交互式应用程序(如图像编辑器)。
您可以通过在浏览器开发者控制台中键入以下内容来检查您的浏览器是否支持 IndexedDB:if (window.indexedDB) { console.log('true'); }.
子域名
每个域上的多个应用程序
子域名枚举在于查找:基于主域应用的其他服务是否托管或命名于其他子域中。如果您还发现其他不规则命名或者与主站毫无头绪的服务,您就要考虑考虑怎么一回事儿了。开发偷偷留的接口?历史遗留?部门交接发生的纰漏?
假设我们正在尝试映射 MegaBank 的 Web 应用程序,以便更好地执行由该银行赞助的黑盒渗透测试。 我们知道 MegaBank 有一个应用程序,用户可以登录并访问他们的银行账户。 此应用程序位于 https://www.megabank.com。
我们特别好奇 MegaBank 是否有任何其他可访问互联网的服务器链接到 megabank.com 域名。 我们知道 MegaBank 有一个漏洞赏金计划,该计划的范围相当全面地涵盖了主要的 megabank.com 域。 因此,megabank.com 中任何易于发现的漏洞都已得到修复或报告。 如果出现新的漏洞,我们将争分夺秒地在漏洞赏金猎人之前找到它们。
正因为如此,我们想寻找一些更容易的目标,这些目标仍然能让我们在它受到伤害的地方击中 MegaBank。 这是一个纯粹由企业赞助的道德测试,但这并不意味着我们不能玩得开心。
我们应该做的第一件事是执行一些侦察并用附加到 megabank.com 的子域列表填充我们的 Web 应用程序地图。 因为 www 指向面向公众的 Web 应用程序本身,所以我们可能对此不感兴趣。 但是,大多数大型消费公司实际上都拥有与其主域相关联的各种子域。 这些子域用于托管从电子邮件到管理应用程序、文件服务器等的各种服务。

浏览器的内置网络分析工具
最初,我们可以简单地通过查看 MegaBank 中的可见功能并查看后台发出的 API 请求来收集一些有用的数据。 这通常会给我们一些容易实现的结果。 要查看这些请求,我们可以使用我们自己的 Web 浏览器的网络工具,或者更强大的工具,如 Burp、PortSwigger 或 ZAP。像这样的免费网络分析工具比 10 年前的许多付费网络工具强大得多。
只要您使用三大浏览器(Chrome、Firefox 或 Edge)中的一种,您就会发现它们随附的开发工具非常强大。 事实上,浏览器开发工具已经发展到如此地步,您无需购买任何第三方工具即可轻松成为一名熟练的黑客。 现代浏览器提供了用于网络分析、代码分析、带有断点和文件引用的 JavaScript 运行时分析、准确的性能测量(也可以用作旁道攻击中的黑客工具),以及用于执行较小安全和兼容性审计。
以Chrome为例:
点击network标签
我这里还用火狐访问来一起观察 https://www.reddit.com/
最有趣的结果通常来自网络选项卡下的 XHR 选项卡,它会显示任何 HTTP POST、GET、PUT、DELETE 和其他针对服务器的请求,并过滤掉字体、图像、视频和依赖文件(不选择即过滤掉了) . 您可以单击左侧窗格中的任何单个请求以查看更多详细信息。

点击Preview可以看见API响应包的格式化版本。

其他功能自己看看这里不枚举
利用公共记录
今天,存储在网络上的信息量很大
从类似这些公共库中寻找:搜索引擎;社交媒体帖子;归档应用程序,例如 archive.org;图像搜索和反向图像搜索
寻找类似以下内容:
• GitHub 存储库的缓存副本,这些副本在再次变为私有之前意外公开
• SSH 密钥
• 不面向公众的 DNS 列表和 URL
• 详细介绍不打算上线的未发布产品的页面
• 托管在网络上但不打算被搜索引擎抓取的财务记录
• 电子邮件地址、电话号码和用户名
• 子域名
搜索引擎缓存
过滤掉不感兴趣的子域名
site:reddit.com -inurl:www
site:mega-bank.com -inurl:www -inurl:mobile
社交媒体
大多数人不会认为通过社交媒体数据为渗透测试查找子域是不道德的。但是,在将来使用这些 API 进行更有针对性的侦察时应该考虑最终用户的感受。
以 Twitter API 作为侦察示例。所需的概念可以应用于任何其他主要社交媒体网络。
Twitter API
Twitter 提供了许多用于搜索和过滤数据的产品。 这些产品在范围、功能集和数据集方面有所不同。 这意味着您想要访问的数据越多,请求和过滤数据的方式越多,您需要支付的费用就越多。 在某些情况下,甚至可以针对 Twitter 的服务器而不是本地执行搜索。 请记住,出于恶意目的这样做可能违反了法律,因此这种用法应该仅限于授权的白帽子。

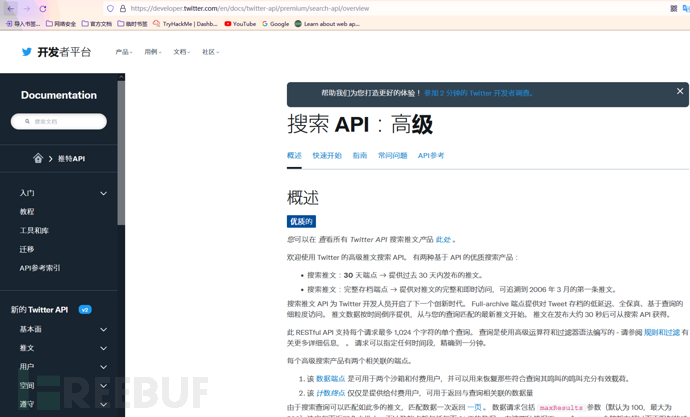
我们可以使用这个 API 来构建一个 JSON,其中包含指向 *.mega-bank.com 的链接,以便进一步子域侦察。 Twitter 搜索 API 进行查询,需要:
• 已注册的开发者帐户
• 已注册的应用程序
• 包含在您的请求中的不记名令牌以验证您的身份
查询这个 API 非常简单,尽管文档很分散,缺乏示例而难以理解:
curl --request POST \
--url https://api.twitter.com/1.1/tweets/search/30day/Prod.json \
--header 'authorization: Bearer <MY_TOKEN>' \
--header 'content-type: application/json' \
--data '{
"maxResults": "100",
"keyword": "mega-bank.com"
}'
默认情况下,该 API 对关键字进行模糊搜索。 对于精确匹配,您必须确保传输的字符串本身用双引号括起来(使用\来转义)。 双引号可以通过以下形式通过有效的 JSON 发送:
"keyword": "\"mega-bank.com\""
为何此 API 的结果可能会导致发现以前未知的子域? 这些通常与主应用程序不同的服务器的营销活动:广告跟踪器,甚至招聘活动以及其他商业利益之间的交集而留下的信息。
Zone Transfer Attacks
您可以将其翻译为:区域转移,传输,传送攻击
浏览面向公众的 Web 应用程序并分析网络请求只会让您走到这一步。 我们还想找到附加到 MegaBank 的子域,这些子域未以任何方式链接到公共 Web 应用程序。
DNS 允许web应用更改自己的服务器 IP 地址,用户可以连续访问 https://www.mega-bank.com 而不必担心请求将解析到哪个web服务器。
DNS 系统非常依赖其与其他 DNS 服务器同步 DNS 记录更新的能力。 DNS 区域传输是 DNS 服务器共享 DNS 记录的标准化方式。
关于DNS前置知识:可以参考本人的另一篇文章中的片段 https://www.anquanke.com/post/id/243935

区域文件通常包含不容易访问的 DNS 配置数据。正确配置的它只授权其他DNS服务器的请求。如果配置错误,谁都能看了。
我们需要假装我们是一个 DNS 服务器并请求一个 DNS 区域文件,就好像我们需要它来更新我们自己的记录一样。
假设,我们需要首先找到与 https://www.mega-bank.com 关联的 DNS 服务器。
host -t mega-bank.com
响应的名称服务器如下:
mega-bank.com name server ns1.bankhost.com
mega-bank.com name server ns2.bankhost.com
向主机发出区域传输请求非常简单
host -l mega-bank.com ns1.bankhost.com
-l 标志表明我们希望从 ns1.bankhost.com 获取 mega-bank.com 的区域传输文件以更新我们的记录。
如果请求成功,它真的返回数据了,则表明 DNS 服务器安全性不高,您将看到如下结果:
Using domain server:
Name: ns1.bankhost.com
Address: 195.11.100.25
Aliases:
mega-bank.com has address 195.250.100.195
mega-bank.com name server ns1.bankhost.com
mega-bank.com name server ns2.bankhost.com
mail.mega-bank.com has address 82.31.105.140
admin.mega-bank.com has address 32.45.105.144
internal.mega-bank.com has address 25.44.105.144
区域转移攻击很容易阻止,您会发现许多应用程序都已正确配置以拒绝这些尝试。 因此这种现象百年难遇。
暴力破解子域
作为发现子域的最终措施,可以使用蛮力策略。但对于更成熟和安全的 Web 应用程序,必须非常智能地构建蛮力。(基于速率限制,基于性能下降,基于正则表达式的防御记录规则自动拉黑等。)
可能导致您的 IP 地址被服务器或其管理员记录或禁止。
一般来说,您可以将每个网络请求拉长 50 到 250 毫秒的延迟。 雇佣云服务,日复一日的收集。
蛮力算法生成一个子域,然后向<subdomain-guess>.mega-bank.com发出请求。 如果我们收到响应,会将其标记为活动子域。
我们熟悉的最重要的语言是 JavaScript。 JavaScript 不仅是当前可用于 Web 浏览器中客户端脚本的唯一编程语言,而且由于 Node.js 和开源社区,它还是一种极其强大的后端服务器端语言。
让我们使用 JavaScript 分两步构建一个蛮力算法。
生成潜在子域的列表。
遍历该子域列表,每次 ping 以检测子域是否有效。
记录活动的子域,对未使用的子域不做任何处理。
使用以下方法生成子域:
/*
* A simple function for brute forcing a list of subdomains
* given a maximum length of each subdomain.
*/
const generateSubdomains = function(length) { #函数定义 子域名长度
/*
* A list of characters from which to generate subdomains.
*
* This can be altered to include less common characters
* like '-'.
*
* Chinese, Arabic, and Latin characters are also
* supported by some browsers.
*/
const charset = 'abcdefghijklmnopqrstuvwxyz'.split(''); #枚举字符集
let subdomains = charset;
let subdomain;
let letter;
let temp;
/*
* Time Complexity: o(n*m)
* n = length of string
* m = number of valid characters
*/
for (let i = 1; i < length; i++) { # 核心部分 生成子域 1-4的长度
temp = [];
for (let k = 0; k < subdomains.length; k++) {
subdomain = subdomains[k];
for (let m = 0; m < charset.length; m++) {
letter = charset[m];
temp.push(subdomain + letter);
}
}
subdomains = temp
}
return subdomains; }
const subdomains = generateSubdomains(4); #这里给了子域名长度为4,运行定义的函数
现在,使用这个子域列表,我们可以开始查询顶级域例如 mega-bank.com。 为此,我们将编写一个简短的脚本,利用 Node.js 中提供的 DNS 库——一个流行的 JavaScript运行环境(runtime)。
要运行此脚本,您只需要在您的环境中安装最新版本的 Node.js(它是基于 Unix 的环境,如 Linux 或 Ubuntu):
const dns = require('dns');
const promises = [];
/*
* This list can be filled with the previous brute force
* script, or use a dictionary of common subdomains.
*/
const subdomains = [];
/*
* Iterate through each subdomain, and perform an asynchronous 异步DNS查询
* DNS query against each subdomain.
*
* This is much more performant than the more common `dns.lookup()`
* because `dns.lookup()` appears asynchronous from the JavaScript,
* but relies on the operating system's getaddrinfo(3) which is
* implemented synchronously.
*/
subdomains.forEach((subdomain) => {
promises.push(new Promise((resolve, reject) => {
dns.resolve(`${subdomain}.mega-bank.com`, function (err, ip) {
return resolve({ subdomain: subdomain, ip: ip });
});
}));
});
// after all of the DNS queries have completed, log the results
Promise.all(promises).then(function(results) {
results.forEach((result) => {
if (!!result.ip) {
console.log(result);
}
});
});
首先导入Node DNS库。 然后我们创建一个数组 promises,它将存储一个 promise 对象列表。承诺 Promise是一种在 JavaScript 中处理异步请求的更简单的方法,并且在每个主要的 Web 浏览器和 Node.js 中都得到了原生支持。
在此之后,我们创建另一个名为 subdomains 的数组,该数组应填充我们从第一个脚本生成的子域。
接下来,我们使用 forEach() 运算符轻松遍历 subdomains 数组中的每个子域。 这相当于 for 迭代,但在语法上更优雅。
在子域迭代的每个级别,我们将一个新的 promise 对象推送到 promises 数组。 在这个 promise 对象中,我们调用了 dns.resolve,它是 Node.js DNS 库中的一个函数,它尝试将域名解析为 IP 地址。 我们推送到承诺数组的这些承诺只有在 DNS 库完成其网络请求后才会解析。
最后, Promise.all 块只在数组中的每个承诺都已被解析(完成其网络请求)时才接受一组承诺对象和结果(calls .then())。 双 !! 结果中的运算符指定我们只想要返回定义的结果,因此我们应该忽略不返回 IP 地址的尝试。
如果我们包含一个调用reject() 的条件,我们还需要在末尾使用一个catch() 块来处理错误。 DNS 库会引发许多错误,其中一些错误可能不值得中断我们的暴力破解。 为简单起见,示例中省略了这一点,但如果您打算进一步研究此示例,这将是一个很好的练习。
此外,我们使用 dns.resolve 与 dns.lookup ,因为尽管两者的 JavaScript 实现都是异步解析的(无论它们被触发的顺序如何),但 dns.lookup 依赖的本机实现是建立在同步执行操作的 libuv 上的。 我们可以很容易地将这两个脚本组合成一个程序。 首先,我们生成潜在子域的列表,然后我们执行异步蛮力尝试解析子域:
const dns = require('dns');
/*
* A simple function for brute forcing a list of subdomains
* given a maximum length of each subdomain.
*/
const generateSubdomains = function(length) {
/*
* A list of characters from which to generate subdomains.
*
* This can be altered to include less common characters
* like '-'.
*
* Chinese, Arabic, and Latin characters are also
* supported by some browsers.
*/
const charset = 'abcdefghijklmnopqrstuvwxyz'.split('');
let subdomains = charset;
let subdomain;
let letter;
let temp;
/*
* Time Complexity: o(n*m)
* n = length of string
* m = number of valid characters
*/
for (let i = 1; i < length; i++) {
temp = [];
for (let k = 0; k < subdomains.length; k++) {
subdomain = subdomains[k];
for (let m = 0; m < charset.length; m++) {
letter = charset[m];
temp.push(subdomain + letter);
}
}
subdomains = temp
}
return subdomains; }
const subdomains = generateSubdomains(4);
const promises = [];
/*
* Iterate through each subdomain, and perform an asynchronous
* DNS query against each subdomain.
*
* This is much more performant than the more common `dns.lookup()`
* because `dns.lookup()` appears asynchronous from the JavaScript,
* but relies on the operating system's getaddrinfo(3) which is
* implemented synchronously.
*/
subdomains.forEach((subdomain) => {
promises.push(new Promise((resolve, reject) => {
dns.resolve(`${subdomain}.mega-bank.com`, function (err, ip) {
return resolve({ subdomain: subdomain, ip: ip });
});
}));
});
// after all of the DNS queries have completed, log the results
Promise.all(promises).then(function(results) {
results.forEach((result) => {
if (!!result.ip) {
console.log(result);
}
});
});
字典攻击
可以通过使用字典攻击而不是蛮力攻击来进一步加快进程。从最常见的子域列表中提取。
一个名为 dnscan 的流行开源 DNS 扫描器附带了互联网上最受欢迎的子域列表,该列表基于来自超过 86,000 个 DNS 区域记录的数百万个子域。
https://github.com/rbsec/dnscan
const dns = require('dns');
const csv = require('csv-parser');
const fs = require('fs');
const promises = [];
/*
* Begin streaming the subdomain data from disk (versus
* pulling it all into memory at once, in case it is a large file).
*
* On each line, call `dns.resolve` to query the subdomain and
* check if it exists. Store these promises in the `promises` array.
*
* When all lines have been read, and all promises have been resolved,
* then log the subdomains found to the console.
*
* Performance Upgrade: if the subdomains list is exceptionally large,
* then a second file should be opened and the results should be
* streamed to that file whenever a promise resolves.
*/
fs.createReadStream('subdomains-10000.txt')
.pipe(csv())
.on('data', (subdomain) => {
promises.push(new Promise((resolve, reject) => {
dns.resolve(`${subdomain}.mega-bank.com`, function (err, ip) {
return resolve({ subdomain: subdomain, ip: ip });
});
}));
})
.on('end', () => {
// after all of the DNS queries have completed, log the results
Promise.all(promises).then(function(results) {
results.forEach((result) => {
if (!!result.ip) {
console.log(result);
}
});
});
});
API分析
子域发现之后的下一个逻辑侦察技能就是API分析。
此应用程序使用哪些域? 如果此应用程序具有三个域(例如,x.domain、y.domain 和 z.domain),我应该知道它们中的每一个可能都有自己独特的 API 端点。
查找 API 是在发现子域之后了解 Web 应用程序结构的第二步。 此步骤将为我们提供开始理解公开 API 的用途所需的信息。 当我们了解 API 为何会通过网络公开时,我们就可以开始了解它如何适合应用程序以及它的业务目的是什么。
端点发现
通常,API 将遵循 REST 格式或 SOAP 格式。 REST 正变得越来越流行,并且被认为是当今现代 Web 应用程序 API 的理想结构。
我们可以使用浏览器中的开发人员工具。 如果我们看到许多类似这样的 HTTP 请求:
GET api.mega-bank.com/users/1234
GET api.mega-bank.com/users/1234/payments
POST api.mega-bank.com/users/1234/payments
可以很安全地假设这是一个 REST API。 请注意,每个端点指定一个特定的资源而不是一个功能。
此外,我们可以假设嵌套的资源支付属于用户 1234,这告诉我们这个 API 是分层的。 这是 RESTful 设计的另一个明显标志。
如果我们查看随每个请求发送的 cookie,并查看每个请求的标头,我们可能还会发现 RESTful 架构的迹象:
POST /users/1234/payments HTTP/1.1
Host: api.mega-bank.com
Authorization: Bearer abc21323 # 观察这里,认证token
Content-Type: application/x-www-form-urlencoded
User-Agent: Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/1.0 (KHTML, like Gecko)
在每个请求上发送令牌是 RESTful API 设计的另一个标志。 REST API 应该是无状态的,这意味着服务器不应跟踪其请求者。
一旦我们知道这确实是一个 REST API,我们就可以开始对可用端点进行逻辑假设。
REST 架构支持的 HTTP 动词如下:
POST Create
GET Read
PUT Update/Replace
PATCH Update/Modify
DELETE Delete
使用架构规范支持哪些 HTTP 动词,可以查看针对特定资源的请求。 然后我们可以尝试使用不同的 HTTP 动词向这些资源发出请求,并查看 API 是否返回任何有趣的内容。
HTTP 规范定义了一种特殊的方法,该方法仅用于提供有关特定 API 动词的信息。 此方法称为 OPTIONS,应该是我们对 API 执行侦察时的首选方法。 我们可以轻松地从终端发出 curl 请求:
curl -i -X OPTIONS https://api.mega-bank.com/users/1234
burp HTTP动词直接修改为OPTIONS也是一样的。
一般而言,OPTIONS 仅适用于专门指定供公众使用的 API。 因此,虽然这是一个简单的第一次尝试,但对于我们尝试测试的大多数应用程序,我们需要一个更强大的发现解决方案。 很少有企业应用程序公开 OPTIONS。
让我们继续使用一种更可能的方法来确定可接受的 HTTP 动词。 我们在浏览器中看到的第一个 API 调用如下:
GET api.mega-bank.com/users/1234
我们现在可以将其扩展为:
GET api.mega-bank.com/users/1234
POST api.mega-bank.com/users/1234
PUT api.mega-bank.com/users/1234
PATCH api.mega-bank.com/users/1234
DELETE api.mega-bank.com/users/1234
考虑到上面的 HTTP 动词列表,我们可以生成一个脚本来测试我们理论的合法性。
暴力破解 API 端点 HTTP 动词可能会产生删除或更改应用程序数据的副作用。 在对应用程序 API 执行任何类型的暴力尝试之前,请确保您已获得应用程序所有者的明确许可。
我们的脚本有一个简单的目的:使用给定的端点(我们知道这个端点已经接受至少一个 HTTP 动词),尝试每个额外的 HTTP 动词。 在针对端点尝试每个额外的 HTTP 动词后,记录并打印结果:
/*
* Given a URL (cooresponding to an API endpoint),
* attempt requests with various HTTP verbs to determine
* which HTTP verbs map to the given endpoint.
*/
const discoverHTTPVerbs = function(url) {
const verbs = ['POST', 'GET', 'PUT', 'PATCH', 'DELETE'];
const promises = [];
verbs.forEach((verb) => {
const promise = new Promise((resolve, reject) => {
const http = new XMLHttpRequest();
http.open(verb, url, true)
http.setRequestHeader('Content-type', 'application/x-www-form-urlencoded');
/*
* If the request is successful, resolve the promise and
* include the status code in the result.
*/
http.onreadystatechange = function() {
if (http.readyState === 4) {
return resolve({ verb: verb, status: http.status });
}
}
/*
* If the request is not successful, or does not complete in time, mark
* the request as unsuccessful. The timeout should be tweaked based on
* average response time.
*/
setTimeout(() => {
return resolve({ verb: verb, status: -1 });
}, 1000);
// initiate the HTTP request
http.send({});
});
// add the promise object to the promises array
promises.push(promise);
});
/*
* When all verbs have been attempted, log the results of their
* respective promises to the console.
*/
Promise.all(promises).then(function(values) {
console.log(values);
});
}
这个脚本在技术层面上运行的方式同样简单。 HTTP 端点返回状态代码以及它们发送回浏览器的任何消息。 我们实际上并不关心这个状态码是什么。 我们只想看到一个状态码。 我们针对 API 发出许多 HTTP 请求,每个 HTTP 动词一个请求。 大多数服务器不会响应未映射到有效端点的请求,因此我们还有一种情况,如果请求在 1 秒内没有收到响应,我们将返回 –1。 一般来说,1 秒(在这种情况下为 1,000 毫秒)对于 API 响应来说是足够的。 您可以根据自己的用例向上或向下调整。 承诺全部解析后,您可以查看日志输出以确定哪些 HTTP 动词具有关联的端点。
认证机制
猜测 API 端点所需的负载形状比仅仅断言 API 端点存在要困难得多。 最简单的方法是分析通过浏览器发送的已知请求的结构。除此之外,我们必须对 API 端点所需的形状进行有根据的猜测并手动测试它们。
可以自动发现 API 端点的结构,但任何不涉及分析现有请求的尝试都将很容易被检测和记录。
通常最好从几乎可以在每个应用程序中找到的通用端点开始:登录、注册、密码重置等。这些通常采用与其他应用程序类似的有效载荷,因为身份验证通常是基于标准化设计的方案。
每个具有公共 Web 用户界面的应用程序都应该有一个登录页面。但是,他们对您的会话进行身份验证的方式可能会有所不同。
了解您正在使用哪种类型的身份验证方案很重要,因为许多现代应用程序都会随每个请求发送身份验证令牌。这意味着如果我们可以对所使用的身份验证类型进行逆向工程并了解令牌如何附加到请求,那么分析依赖于经过身份验证的用户令牌的其他 API 端点将更加容易。
目前有几种主要的身份验证方案在使用,其中最常见的如表所示。 自己翻译一下,帮叔省点工作量。。
数据包表象在第二列,第三列与第四列为优劣势。请务必弄清此图说的内容,否则您能测个der。。

如果我们登录 https://www.mega-bank.com 并分析网络响应,登录成功后可能会看到如下内容:
GET /homepage
HOST mega-bank.com
Authorization: Basic am1lOjEyMzQ=
Content Type: application/json
乍一看,我们可以看出这是 HTTP 基本身份验证,因为发送的是基本授权标头。 此外,字符串 am1lOjEyMzQ= 只是一个 base64 编码的用户名:密码字符串。 这是格式化用户名和密码组合以通过 HTTP 传送的最常见方法。
在浏览器控制台中,我们可以使用内置函数 btoa(str) 和 atob(base64) 编解码 base64。
这里没必要复现,操作太简单了。大致看看吧。有问题留言。
/*
* Decodes a string that was previously encoded with base64.
* Result = joe:1234
*/
atob('am1lOjEyMzQ=');
由于此机制的不安全性,基本身份验证通常仅用于强制实施 SSL/TLS 流量加密的 Web 应用程序。 这样,凭证就无法在空中截获——例如,在一个粗略的商场 WiFi 热点。
从对这个登录/重定向到主页的分析中要注意的重要一点是,我们的请求确实经过了身份验证,并且它们通过Authorization: Basic am1lOjEyMzQ= 来授权访问。如果我们遇到一些资源没有返回任何数据,应该首先尝试增加授权的标头。并与先认证再发起请求的数据包做比较,观察有何不同。
端点形状
形状:就是这些端点API都是什么样儿。。这些端点API期望接收到什么键值对。
在找到多个子域和这些子域中包含的 HTTP API 之后,您应该开始确定每个资源使用的 HTTP 动词并将该调查的结果添加到您的 Web 应用程序地图中。 一旦您有了子域、API 和形状的完整列表,您可能会开始想知道如何才能真正了解任何给定 API 期望的有效负载类型。
常见形状
API都找不到,还测个啥子。。
许多 API 期望有效载荷形状在行业中很常见。 例如,作为 OAuth 2.0 流的一部分设置的授权端点可能需要以下数据:
{
"response_type": code,
"client_id": id,
"scope": [scopes],
"state": state,
"redirect_uri": uri
}
由于 OAuth 2.0 是广泛实施的公共规范,因此通常可以通过将有根据的猜测与可用公共文档相结合来确定要包含在 OAuth 2.0 授权端点中的数据。
OAuth 2.0 授权端点中的命名约定和范围列表可能因实现的不同而略有不同,但整体负载形状不应如此。
OAuth 2.0 授权端点的示例可以在 Discord(即时消息)公共文档中找到。 Discord 建议对 OAuth 2.0 端点的调用结构如下:
https://discordapp.com/api/oauth2/authorize?response_type=code&client_id=157730590492196864&scope=identify%20guilds.join&state=15773059ghq9183habn&redirect_uri=https%3A%2F%2Fnicememe.website&prompt=consent
其中 response_type、client_id、scope、state 和 redirect_uri 都是官方规范的一部分。
Facebook 的 OAuth 2.0 公开文档非常相似,建议对相同功能提出以下要求:
GET https://graph.facebook.com/v4.0/oauth/access_token?
client_id={app-id}
&redirect_uri={redirect-uri}
&client_secret={app-secret}
&code={code-parameter}
找到 HTTP API 的形状并不是一件复杂的事情。虽然许多 API 实现了 OAuth 等通用规范,但组织内部逻辑实现时不会使用通用的规范。键值对会出现衍生体。
特定应用的形状
特定于应用程序的形状比基于公共规范的形状更难确定。
要确定 API 端点预期的有效负载的形状,您可能需要依赖多种侦察技术,并通过反复试验慢慢了解端点。
不安全的应用程序可能会在响应包中提示 HTTP 错误消息。
例如,假设您使用以下正文调用 POST https://www.mega-bank.com/users/config:
{
"user_id": 12345,
"privacy": {
"publicProfile": true
}
}
响应包 HTTP 状态代码,可能是 401 未授权或 400 内部错误。 甚至返回的内容中还有描述auth_token 未提供之类的消息,那么恭喜您,发现了缺少的参数。
在具有正确 auth_token 的字段请求中,您可能会收到另一条错误消息:publicProfile 只接受“auth”和“noAuth”作为参数。 那么恭喜您,发现了字段的值怎么填。
但更安全的应用程序可能只会抛出一般性错误,您将不得不转向其他技术。 暂时放弃这里的测试方法。
如果您有特权帐户,您可以使用 UI 对您的普通帐户尝试相同的请求,然后再对另一个帐户尝试相同的请求,以确定它们形状的区别在哪。
识别第三方依赖
在应用程序代码中使用此类第三方依赖项并非没有风险,而且第三方依赖项通常不像内部代码那样经过安全审查。
在侦察过程中,您可能会遇到许多第三方集成,并且您将要非常注意依赖项和集成方法。 通常,这些依赖关系会变成攻击媒介; 有时此类依赖项中的漏洞是众所周知的,您甚至可能不必自己准备攻击,而是能够从常见漏洞和暴露 (CVE) 数据库复制攻击。
检测客户端框架
通常,开发人员不会构建复杂的 UI 基础架构,而是利用维护良好且经过良好测试的 UI 框架。 这些通常以 SPA 库的形式出现,用于处理复杂的状态、用于修补 JavaScript 语言中跨浏览器的功能漏洞的纯 JavaScript 框架(Lodash、JQuery),或者作为用于改善网站外观的 CSS 框架(Bootstrap、 Bulma)。
如果你能确定版本号,你通常可以在网络上找到适用的 ReDoS、Prototype Pollution原型污染 和 XSS 漏洞的组合(尤其是那些没有更新的旧版本)
检测 SPA 框架
网络上最大的 SPA 框架是(排名不分先后):
• EmberJS (LinkedIn, Netflix)
• AngularJS (Google)
• React (Facebook)
• VueJS (Adobe, GitLab)
这些框架中的每一个都引入了非常特殊的语法和顺序,以说明它们如何管理 DOM 元素以及开发人员如何与框架交互。 并非所有框架都这么容易检测。 有些需要指纹识别或高级技术。 当版本给你时,一定要把它写下来。
EmberJS
EmberJS 很容易检测,因为当 EmberJS 引导时,它会设置一个全局变量 Ember,可以很容易地在浏览器控制台中找到它。
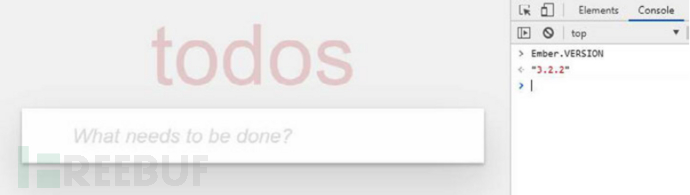
Ember 还使用 ember-id 标记所有 DOM 元素以供其内部使用。 这意味着,如果您使用 Ember 通过 Developer tools → Elements 选项卡查看任何给定网页中的 DOM 树,您应该会看到许多包含 id=ember1、id=ember2、id=ember3 等的 div。每一个 div 应该包裹在 class="ember-application" 父元素中,通常是 body 元素。
Ember 可以轻松检测正在运行的版本。 只需引用一个附加到全局 Ember 对象的常量:
// 3.1.0
console.log(Ember.VERSION);
AngularJS
旧版本的 Angular 提供了一个类似于 EmberJS 的全局对象。 全局对象名为 angular,版本可以从其属性 angular.version 派生。 AngularJS 4.0+ 去掉了这个全局对象,这使得确定 AngularJS 应用程序的版本变得有点困难。 您可以通过检查控制台中是否存在 ng 全局来检测应用程序是否正在运行 AngularJS 4.0+。
要检测版本,您需要做更多的工作。 首先,获取 AngularJS 应用程序中的所有根元素。 然后检查第一个根元素的属性。 第一个根元素应该有一个属性 ng-version ,它将为您提供您正在调查的应用程序的 AngularJS 版本:
// returns array of root elements
const elements = getAllAngularRootElements();
const version = elements[0].attributes['ng-version'];
// ng-version="6.1.2"
console.log(version);
React
React 可以通过全局对象 React 识别,并且像 EmberJS 一样,可以通过常量轻松检测其版本:
const version = React.version;
// 0.13.3
console.log(version);
您可能还会注意到类型为 text/jsx 的脚本标签引用了 React 的特殊文件格式,该文件格式在同一文件中包含 JavaScript、CSS 和 HTML。 这是一个你正在使用 React 应用程序的致命赠品,并且知道组件的每个部分都源自单个 .jsx 文件可以使调查单个组件变得更加容易。
VueJS
与 React 和 EmberJS 类似,VueJS 公开了一个具有版本常量的全局对象 Vue:
const version = Vue.version;
// 2.6.10
console.log(version);
如果您无法检查 VueJS 应用程序上的元素,可能是因为该应用程序被配置为忽略开发人员工具。 这是一个附加到全局对象 Vue 的切换属性。
您可以将此属性翻转为 true 以便再次开始在浏览器控制台中检查 VueJS 组件:
// Vue components can now be inspected
Vue.config.devtools = true;
检测 JavaScript 库
有太多的 JavaScript 帮助程序库无法计算,其中一些公开全局变量,而另一些则在雷达下运行。 许多 JavaScript 库使用顶级全局对象来命名它们的函数。 这些库很容易检测和迭代。

Underscore and Lodash 使用符号 $ 公开全局变量,而 JQuery 使用 $ 命名空间,但除了主要库之外,您最好运行查询以查看加载到页面中的所有外部脚本。
我们可以利用 DOM 的 querySelectorAll 函数快速找到所有导入页面的第三方脚本的列表:
/*
* Makes use of built-in DOM traversal function
* to quickly generate a list of each <script>
* tag imported into the current page.
*/
const getScripts = function() {
/*
* A query selector can either start with a "."
* if referencing a CSS class, a "#" if referencing
* an `id` attribute, or with no prefix if referencing an HTML element.
*
* In this case, 'script' will find all instances of <script>.
*/
const scripts = document.querySelectorAll('script');
/*
* Iterate through each `<script>` element, and check if the element
* contains a source (src) attribute that is not empty.
*/
scripts.forEach((script) => {
if (script.src) {
console.log(`i: ${script.src}`);
}
});
};
调用这个函数会给我们这样的输出:
getScripts();
VM183:5 i: https://www.google-analytics.com/analytics.js
VM183:5 i: https://www.googletagmanager.com/gtag/js?id=UA-1234
VM183:5 i: https://js.stripe.com/v3/
VM183:5 i: https://code.jquery.com/jquery-3.4.1.min.js
VM183:5 i: https://cdnjs.cloudflare.com/ajax/libs/d3/5.9.7/d3.min.js
VM183:5 i: /assets/main.js
从这里我们需要单独直接访问脚本以确定订单、配置等。
检测 CSS 库
通过对检测脚本的算法稍加修改,我们还可以检测 CSS:
/*
* Makes use of DOM traversal built into the browser to
* quickly aggregate every `<link>` element that includes
* a `rel` attribute with the value `stylesheet`.
*/
const getStyles = function() {
const scripts = document.querySelectorAll('link');
/*
* Iterate through each script, and confirm that the `link`
* element contains a `rel` attribute with the value `stylesheet`.
*
* Link is a multipurpose element most commonly used for loading CSS
* stylesheets, but also used for preloading, icons, or search.
*/
scripts.forEach((link) => {
if (link.rel === 'stylesheet') {
console.log(`i: ${link.getAttribute('href')}`);
}
});
};
同样,此函数将输出导入的 CSS 文件列表:
getStyles();
VM213:5 i: /assets/jquery-ui.css
VM213:5 i: /assets/boostrap.css
VM213:5 i: /assets/main.css
VM213:5 i: /assets/components.css
VM213:5 i: /assets/reset.css
检测服务器端框架
一些脚本可能会随着初始条件不同而失效
检测客户端(浏览器)上运行的软件比检测服务器上运行的软件要容易得多。 大多数情况下,客户端所需的所有代码都被下载并存储在通过 DOM 引用的内存中。 某些脚本可能会在页面加载后有条件地或异步地加载,但只要触发正确的条件,这些脚本仍然可以访问。
标头检测
一些配置不安全的 Web 服务器包在其默认标头中暴露了过多的数据。比如,X-Powered-By 标头,旧版本的 Microsoft IIS 上默认启用此功能。
X-Powered-By: ASP.NET
Server: Microsoft-IIS/4.5
X-AspNet-Version: 4.0.25
聪明的管理员禁用这些标头,将它们从默认配置中删除。
默认错误消息和 404 页面
一些流行的框架没有提供非常简单的方法来确定版本号。 如果这些框架是开源的,比如 Ruby on Rails,那么您也许能够通过指纹识别来确定使用的版本。
Git 版本控制的历史版本,提交的特定修改可用于识别版本号。
大多数服务器有自己的默认错误消息和 404 页面,如果Web 应用程序框架不提供或者不配置404页面,则显示的是服务器的默认错误页面。
可以翻一翻git版本文件,在仓库里面搜一搜,对比一下404页面的差异性
https://github.com/rails/rails


看看每次版本修改的内容,比如
• 2017 年 4 月 20 日—命名空间 CSS 选择器添加到 404 页面
• 2013 年 11 月 21 日 - U+00A0 替换为空格
• 2012 年 4 月 5 日 - 移除了 HTML5 类型属性
数据库检测
如果将数据库错误消息直接发送到客户端,则可以使用与检测服务器包类似的技术来确定数据库。通常情况并非如此,因此您必须找到其他的发现路线。
可以使用的一种技术是主键扫描。大多数数据库支持“主键”的概念,它指的是表 (SQL) 或文档 (NoSQL) 中的键,它在对象创建时自动生成并用于在数据库中快速执行查找。
如果您可以确定一些主要数据库的默认主键是如何生成的,除非默认方法已被改掉,您很有机会确定数据库类型。
以流行的 NoSQL 数据库 MongoDB 为例。 默认情况下,MongoDB 为每个创建的文档生成一个名为 _id 的字段。 _id 键是使用低冲突散列算法生成的,该算法始终生成长度为 12 的十六进制兼容字符串。此外,MongoDB 使用的算法在其开源文档中可见。
https://oreil.ly/UdX_v
文档告诉我们以下内容:
• 用于生成这些 id 的类称为 ObjectId。
• 每个id 正好是12 个字节。
• 前4 个字节表示自Unix 纪元(Unix 时间戳)以来的秒数。
• 接下来的5 个字节是随机的。
• 最后3 个字节是一个以随机值开头的计数器。
ObjectId 示例:507f1f77bcf86cd799439011。
了解 MongoDB 主键的结构后,我们希望查看 HTTP 流量并分析我们找到的具有相似外观的 12 字节字符串的有效负载。
这通常很简单,您会以请求的形式找到主键,例如:
GET users/:id # 其中 :id 是主键
PUT users, body = { id: id } # 其中 :id 是主键
GET users?id=id # 其中 id 是主键但在查询参数中
有时,id 会出现在您最不期望它们的位置,例如在元数据中或在有关用户对象的响应中:
{
_id: '507f1f77bcf86cd799439011',
username: 'joe123',
email: 'joe123@my-email.com',
role: 'moderator',
biography: '...'
}
无论您如何找主键,如果您可以确定该值确实是来自数据库的主键,那么您就可以开始研究数据库并尝试找到与其键生成算法相匹配的特征值。
通常这足以确定 Web 应用程序正在使用什么数据库,但如果您遇到多个数据库使用相同主数据库的情况,有时您可能需要将其与另一种技术(例如,强制错误消息)结合使用 密钥生成算法(例如,连续整数或其他简单模式)。
识别应用程序架构中的弱点
在整个侦察过程中,您都在应该将发现记于笔记,因为某些 Web 应用程序非常庞大,以至于探索其所有功能可能需要数月时间。侦察期间的文档记录,价值性不言而喻。
理想情况下,笔记中应该存在:
• Web 应用程序中使用的技术
• 按 HTTP 动词列出的 API 端点列表
• API 端点形状列表(如果有)
• Web 应用程序中包含的功能(例如,评论、身份验证、通知)等)
• Web 应用程序使用的域
• 找到的配置(例如,内容安全策略或 CSP)
• 认证/会话管理系统
设计需求比代码审计更重要。大多数漏洞源于设计不当。
Web 应用程序中的大多数漏洞源于设计不当的应用程序架构,而不是编写不当的方法。 当然,将用户提供的 HTML 直接写入 DOM 的方法肯定存在风险,并且可能允许用户上传脚本(如果不存在适当的清理)并在另一个用户的机器上执行该脚本(XSS)。
有些应用程序存在数十个 XSS 漏洞,而同行业中其他类似大小的应用程序几乎为零。 最终,应用程序的架构和该应用程序内的模块/依赖项的架构是极可能出现漏洞的薄弱点。
安全与不安全架构的信号
单个 XSS 漏洞可能是编写不当的方法的结果。 但是多个漏洞可能是应用程序架构薄弱的前兆信号。
假设两个简单的应用程序,它们允许用户向其他用户发送消息(文本)。 其中一个应用程序容易受到 XSS 攻击,而另一个则不然。
当向 API 端点发出存储评论的请求时,不安全的应用程序可能不会拒绝脚本; 它的数据库可能不会拒绝该脚本,并且可能不会对表示消息的字符串执行适当的过滤和清理。 最终,它被加载到 DOM 中并被评估为 DOM 测试消息<script>alert('hacked');</script>,从而导致脚本执行。
需要在应用开发前就要意识到什么功能点上面,需要过滤掉什么数据,检查什么数据,该功能点如果有输出,还应该进行检查或者编码等。
如果应用程序架构本质上不安全,即使是由精通应用程序安全的工程师编写的应用程序,最终也可能存在安全漏洞。
这是因为安全的应用程序在功能开发之前和过程中实现了安全性,而具有中等安全性的应用程序在功能开发时实现了安全性,而不安全的应用程序可能不会实现任何安全性。
如果开发人员必须在前面示例中的即时消息 (IM) 系统上编写 10 个变体,时间跨度为 5 年,那么每个实现很可能都不同。 每个实现之间的安全风险将大体相同。 这些 IM 系统中的每一个都包括以下功能:
• 用于编写消息的 UI
• API 端点接收刚刚编写和提交的消息
• 用于存储消息的数据库表
• 用于检索一条或多条消息的 API 端点
• 用于显示一条或多条消息的 UI 代码
应用程序代码如下所示: 以下大概类似的变体代码具有相似的安全问题。是给大家仔细观察的,而不是占据文章空间的。您应该思考功能点,观察安全性。并在成长过程里,发现,哦,原来我需要结合各种具体的功能点,查看代码那些实施的地方,是否存在安全设计。从输入流到输出流并结合功能点,业务逻辑,角色,甚至整个程序的目的性而综合思考。
client/write.html
<!-- Basic UI for Message Input 消息输入UI-->
<h2>Write a Message to <span id="target">TestUser</span></h2>
<input type="text" class="input" id="message"></input>
<button class="button" id="send" onclick="send()">send message</button>
client/send.js
const session = require('./session');
const messageUtils = require('./messageUtils');
/*
* Traverses DOM and collects two values, the content of the message to be
* sent and the username or other unique identifier (id) of the target
* message recipient.
*
* Calls messgeUtils to generate an authenticated HTTP request to send the
* provided data (message, user) to the API on the server. 将值给服务器API端点
*/
const send = function() { # 您能发现API端点接口吗?
const message = document.querySelector('#send').value;
const target = document.querySelector('#target').value;
messageUtils.sendMessageToServer(session.token, target, message);
};
server/postMessage.js 服务器端接收
const saveMessage = require('./saveMessage');
/*
* Recieves the data from send.js on the client, validating the user's
* permissions and saving the provided message in the database if all
* validation checks complete.
*
* Returns HTTP status code 200 if successful.
*/
const postMessage = function(req, res) { # 您能发现没有安全性的检查吗?
if (!req.body.token || !req.body.target || !req.body.message) {
return res.sendStatus(400);
}
saveMessage(req.body.token, req.body.target, req.body.message)
.then(() => {
return res.sendStatus(200);
})
.catch((err) => {
return res.sendStatus(400);
});
};
server/messageModel.js
const session = require('./session');
/*
* Represents a message object. Acts as a schema so all message objects
* contain the same fields.
*/
const Message = function(params) {
user_from: session.getUser(params.token),
user_to: params.target,
message: params.message
};
module.exports = Message;
server/getMessage.js
const session = require('./session');
/*
* Requests a message from the server, validates permissions, and if
* successful pulls the message from the database and then returns the
* message to the user requesting it via the client.
*/
const getMessage = function(req, res) {
if (!req.body.token) { return res.sendStatus(401); }
if (!req.body.messageId) { return res.sendStatus(400); }
session.requestMessage(req.body.token, req.body.messageId) .then((msg) => {
return res.send(msg);
})
.catch((err) => {
return res.sendStatus(400);
});
};
client/displayMessage.html
<!-- displays a single message requested from the server -->
<h2>Displaying Message from <span id="message-author"></span></h2>
<p class="message" id="message"></p>
client/displayMessage.js
const session = require('./session');
const messageUtils = require('./messageUtils');
/*
* Makes use of a util to request a single message via HTTP GET and then
* appends it to the #message element with the author appended to the
* #message-author element.
*
* If the HTTP request fails to retrieve a message, an error is logged to
* the console.
*/
const displayMessage = function(msgId) {
messageUtils.getMessageById(session.token, msgId) .then((msg) => {
messageUtils.appendToDOM('#message', msg);
messageUtils.appendToDOM('#message-author', msg.author);
})
.catch(() => console.log('an error occured'););
};
保护这个简单应用程序所需的许多安全机制,可以而且很可能被抽象到应用程序架构中,通过调用的方式,而不是在这些代码里直接实施正则等过滤器。
以 DOM 注入为例。 UI 中内置的一个简单方法如下所示,可以消除大多数 XSS 风险:
import { DOMPurify } from '../utils/DOMPurify';
// makes use of: https://github.com/cure53/DOMPurify #看这里,消毒
const appendToDOM = function(data, selector, unsafe = false) {
const element = document.querySelector(selector);
// for cases where DOM injection is required (not default)
if (unsafe) {
element.innerHTML = DOMPurify.sanitize(data); #DOMPurify.sanitize 就叫被抽象到应用程序架构中
} else { // standard cases (default)
element.innerText = data;
}
};
简单地围绕这样的功能构建应用程序将大大降低代码库中出现 XSS 漏洞的风险。
我能bypass 过滤器吗?那么战争就转移到了这里 https://github.com/cure53/DOMPurify
这种观察尤为重要,首先让您感同身受的就是,开发有没有掌握这种调用安全设计中抽象性的应用程序架构。
像前面的 appendToDOM 方法这样的机制是安全应用程序架构的信号。
缺乏这些安全机制的应用程序更有可能包含漏洞。 这就是为什么识别不安全的应用程序架构对于发现漏洞和确定代码库改进的优先级很重要。
多层安全
在前面的一个示例中,我们在输入点增加了消毒程序架构 DOMPurify.sanitize(),但我们需要考虑到多个层面的防御,包括横向和纵向。
• API POST
• 数据库写入
• 数据库读取
• API 获取
• 客户端读取
• 以及数据的输出点
其他类型的漏洞也是如此,例如 XXE 或 CSRF——每个漏洞都可能是由于一层以上的安全机制不足而导致的。
例如,假设一个假设的应用程序(如消息传递应用程序)在 API POST 层添加了安全机制,消除 XSS 风险。 现在可能无法通过 API POST 层部署 XSS。
但是,在以后的持续开发中,可能会开发和部署另一种发送消息的方法。如果新的 API 端点没有提供安全机制,则又可以从这里部署XSS进来。
如果开发人员实现多个位置的安全改进机制,例如 API POST 和数据库写入阶段,数据输出阶段。那么新的攻击就可以得到缓解。
最安全的 Web 应用程序是:在许多层引入了安全机制并将默认不安全的配置都改进。而不安全的 Web 应用程序仅在一层或两层引入了安全机制。因为您永远也不会知道,哪里属于高风险高危害的地方,因此,将有问题的地方都改进,来拉长防御的宽度。如果您具备这种侦察意识,就能优先考虑从什么地方开始检测了。因为它更有可能被利用。
采用和改造
总而言之,组织可能有自己的原因开造轮子。
一个安全设计的组件:需要在数学、操作系统或硬件方面具有深厚专业知识的功能。这包括数据库、进程隔离和大多数内存管理。 不可能成为所有方面的专家。因此建议使用优秀的开源组件。
总结
感谢师傅们很有耐心的看到了这里。
我们还会再见面的。
共勉。
已在FreeBuf发表 28 篇文章
如需授权、对文章有疑问或需删除稿件,请联系 FreeBuf 客服小蜜蜂(微信:freebee1024)
 渗透测试
渗透测试





- 28 文章数
- 52 关注者