


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
一、代码扫描的目标
网上关于代码扫描的介绍无一不是在推荐基于语法语义分析的代码扫描工具,典型的代表就是fortify、Checkmarx。总结起来观点无非是, 目前市面上有基于正则表达式和基于语义分析的两种检测方式,基于正则表达式的传统代码安全扫描方案的缺陷在于其无法很好的“理解”代码的语义,而是仅仅把代码文件当作纯字符串处理。静态扫描商用产品都运用了语义分析、语法分析等程序分析技术静态分析层负责对代码文件进行“理解”,完成语义、语法层面的分析。能进行完整数据流分析,通过分析污点传播进行漏洞判定。
之前也使用过fortify进行自动化代码扫描,由于误报率太高导致推送给业务方的漏洞代码不被重视,也使安全部门的权威性受损。业务方不可能从众多的代码结果中排查出漏洞代码,所以不得不放弃fortify(fotify做代码审计辅助工具还是不错的)。另外一个原因是,fortify没法自定义扫描规则,当有内部特定代码风险的时候无法编写规则扫描,带来了一定的不便利性。
基于以上两点问题,对于代码扫描有了新目标。首先扫描准确性要高,其次要能灵活的自定义规则。经过分析发现,再厉害的语法语义扫描器也避免不了误报,最大难点在于扫描器根本无法识别过滤函数的有效性。静态代码扫描要解决这个问题除非用AI来解决,这是云舒的观点我非常赞同,等有一天AI能向人一样阅读代码的时候这个问题可能会解决吧。所以决定采用基于正则表达式的代码扫描器,我们可以扫一些代码规范类的问题。例如:不规范函数、SQL语句拼接、redis和MongoDB未授权访问、数据库连接信息硬编码、DEBUG 模式未关闭、fastjson远程代码执行漏洞的特定代码等等。虽然扫描来的这些问题不一定是漏洞但一定是代码风险也是不规范的写法,这样业务方也更容易接受。对于漏洞类型的代码可以交给运行态代码检测工具iast去发现,iast的缺点就是需要依靠第三方测试流量可能面临覆盖面不全的尴尬境地,所以需要结合静态代码使用。
不管怎么说能发现潜在风险并且业务方能接受整改,那么我们的目的就达到了。
二、为什么不选fortify
代码扫描器一般的扫描逻辑是围绕寻找Source和Sink展开。Source 是污染源,有害数据的入口点。Sink 是程序执行造成危害的部分。接下来追踪污染路径,确定Source–Path–Sink重点看下传进来的参数有没有做有效过滤,逻辑再现攻击,如果入参到最终执行函数都是可通行的那么一般都是有漏洞的。
Fortify会产生误报的原因,对于Source函数和Sink这些都是系统自定义函数,fortify有足够的实力可以整理出来各个语言的入口函数和执行函数列表并形成规则。但是对于过滤函数却显得无能为力了,主要原因是过滤规则千奇百怪通过静态代码的语义分析根本无法识别是否做了有效过滤。
例如,对于xss漏洞在不同场景就有不同的过滤方法,输出到html、js、css、富文本等这些过滤规则就各式各样,如果不是人为去审计代码靠程序很难分析出来是否做了有效过滤。
这里通过一个扫描案例来分析fortify误报的原因。
这里选取WebGoat的代码作为测试代码。
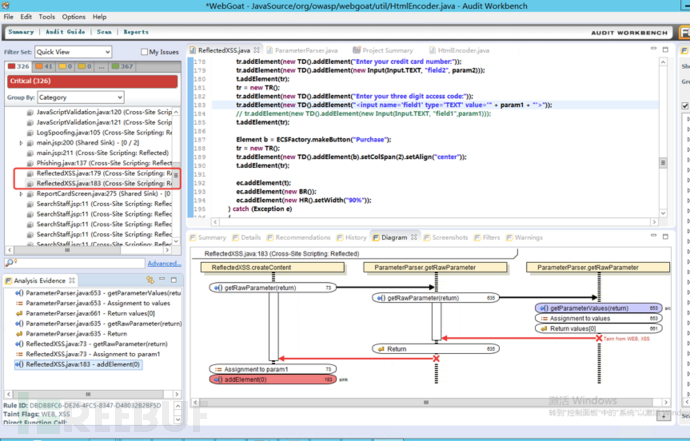
(1)这里扫描识别出来是xss漏洞代码,并且数据流向也画出来了。咋一看fortify还挺强大的。
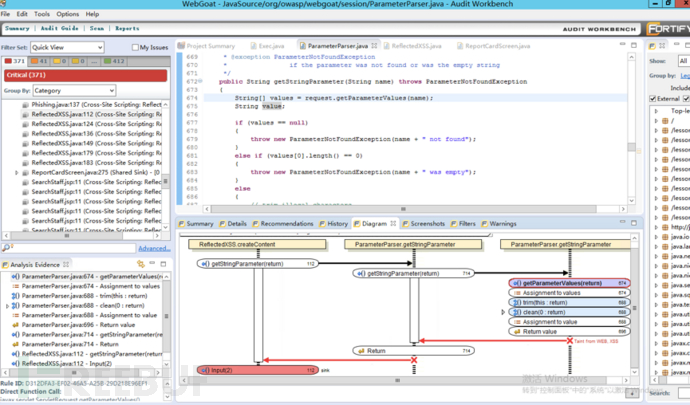
(2)增加过滤函数,并对恶意参数进行过滤
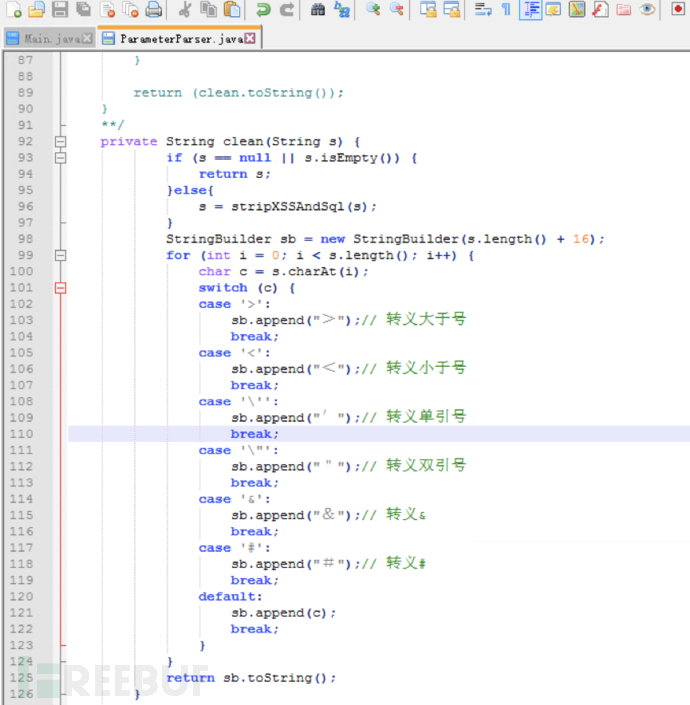
(3)再次使用fortify扫描,对恶意参数已经做了有效过滤仍然报出xss漏洞,显然这是误报。
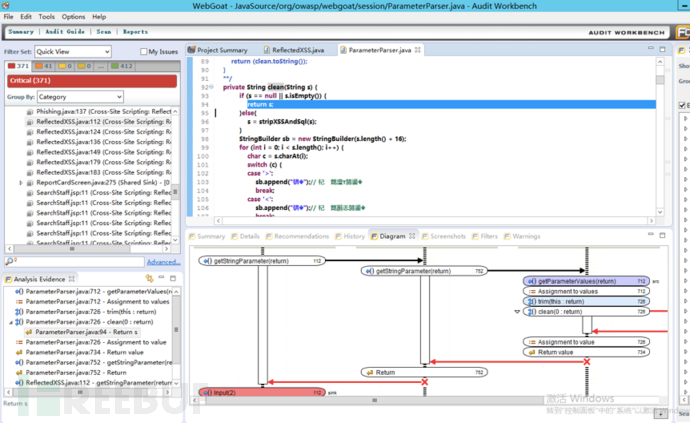
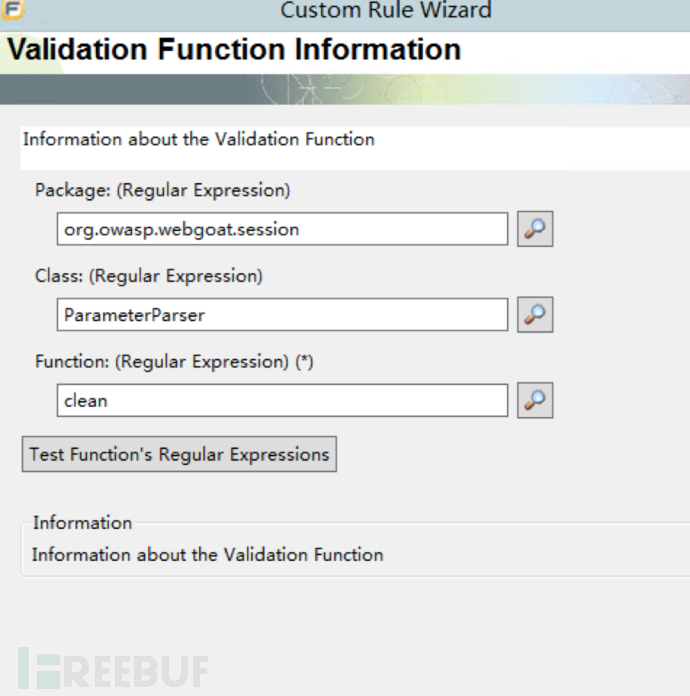
(4)将过滤函数添加到过滤规则明白中去,相当于告诉fortify这个函数做了有效过滤。
右键添加规则
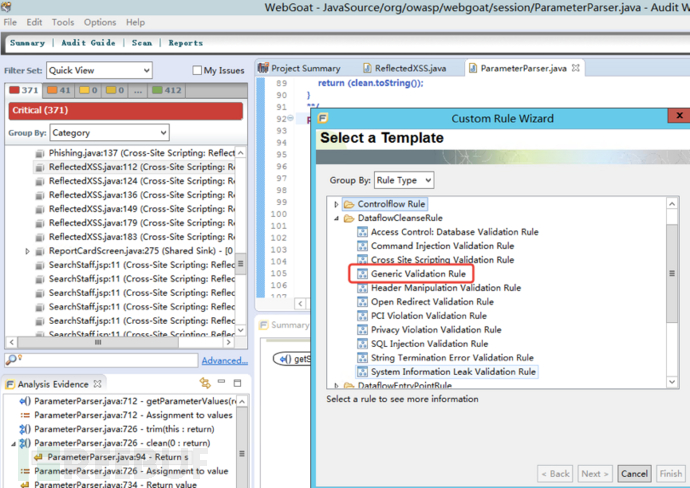
(5)再次使用fortify扫描代码,误报解除。上图扫描出来6个xxs漏洞,下图扫描出来2个,上图中过滤函数添加fotify规则白名单的代码不再扫出来xss漏洞。
三、基于正则扫描原理分析
工欲善其事必先利其器,理解好一个器具的使用最好的方式就是理解其代码运行的原理,这样才能做到灵活应变。
这里以MongoDB未授权访问漏洞为例来讲解代码扫描原理。
如果没有对MongoDB访问进行认证,或者没有按照官方标准的写法来认证的话,我们都认为是有安全风险的。
MongoDB未认证&Java原生API访问MongoDB:
public void init(){
client = newMongoClient("192.168.23.24", 27022);
dataBase =client.getDatabase("duanjt");
collection =dataBase.getCollection("teacher");
}
// 插入一条数据
@Test
public void insert() {
Document doc = new Document();
doc.append("name", "李四");
doc.append("addr", "重庆");
doc.append("likes", Arrays.asList("排球", "篮球"));// 数组
collection.insertOne(doc);// 插入数据时会自动创建数据库和**
System.out.println("success");
}
MongoDB认证&JavaAPI接口调用:
MongoClient client= null;
try {
MongoCredentialcredential = MongoCredential.createCredential(“username” , “dbname”, “pwd”);
ServerAddress addr= new ServerAddress(“ip”, port);
client = newMongoClient(addr, Arrays.asList(credential));
DB db =client.getDB(MongoDBCfg.DB_SP2P);
// 以下可以对db进行相关操作
} catch (Exceptione) {
} finally {
if (client != null){
client.close();
}
}
这里通过正则的分组表达式将规则分为定位规则(定位执行函数),前置规则(一般是入参函数的规则,如果有写了前置规则和定位规则就必须两条规则都匹配到才能说明有代码风险),防御规则(防御函数的规则,如果能识别出来这条规则就可以认为不存在代码风险)
代码扫描逻辑:
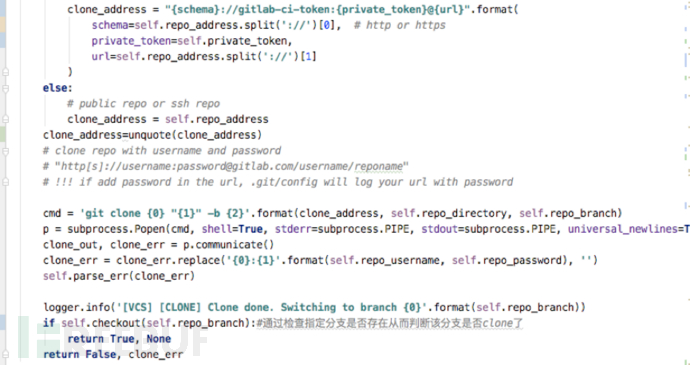
1) 首先下载项目的git仓库代码并将其存储到指定的目录,便于接下来进行代码扫描。
2)扫描准备工作获取代码基本信息
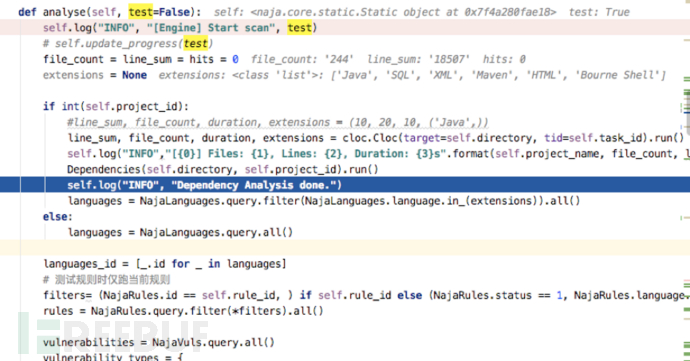
通过cloc命令将项目的基本代码信息解析出来。例如统计有多少行代码,有多少种类型的扩展文件,有多少个文件等。
同时在Dependencies类里面会使用mvn dependency:tree去分析项目的依赖jar包的大版本和小版本从而形成应用资产,便于出现jar依赖漏洞(如fastjson)的时候快速排查哪些应用存在漏洞依赖。
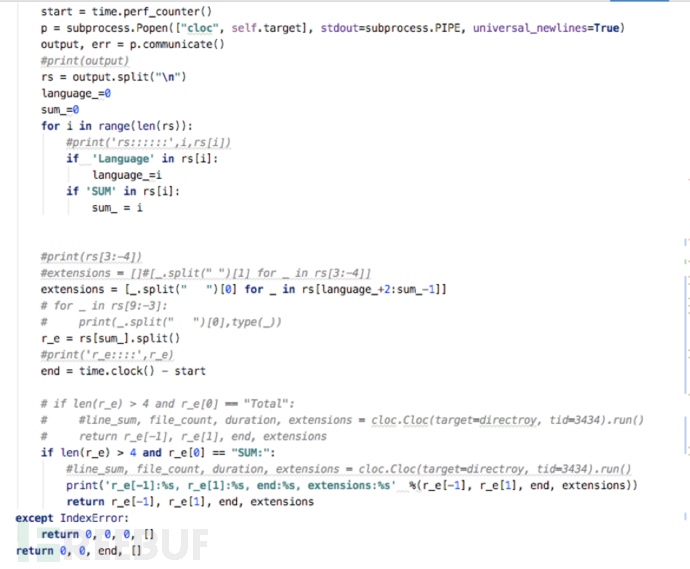
3)遍历代码规则扫描文件,这里使用grep命令进行文件扫描。
首先这里会扫描定位规则,扫描出来定位规则后,后面会进一步判断前置规则和防御规则多条件判断是否存在代码风险。
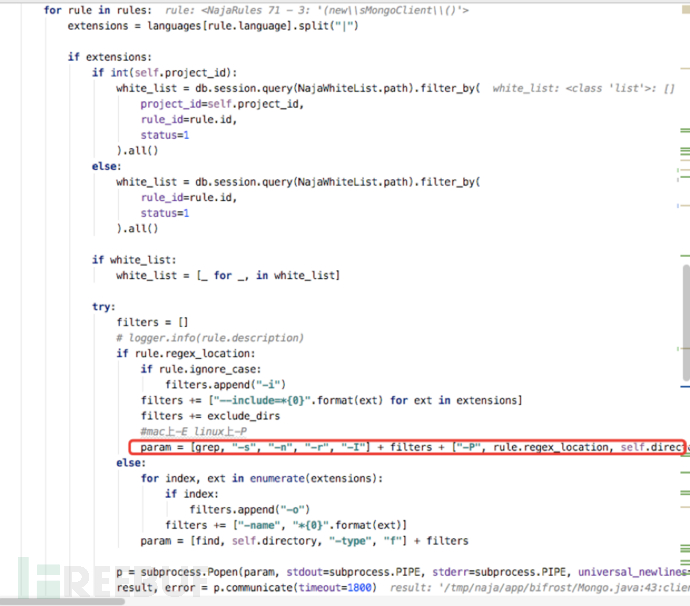
4)开始匹配前置规则或者防御规则。
如果只写了定位规则且匹配到了说明有代码风险,可以是一些配置类的规则,比如csrf开关是否关闭、DEBUG模式未关闭等。
如果写了前置规则和定位规则,要两个规则都能匹配到才能说明有代码风险。可以是一些需要判断前置条件的规则,比如Cookie不安全存储、HTTP Response Splitting等。
如果写了防御规则,只要防御规则生效说明没有代码风险,比如本文分析的MongoDB未授权访问漏洞就用到了防御规则。
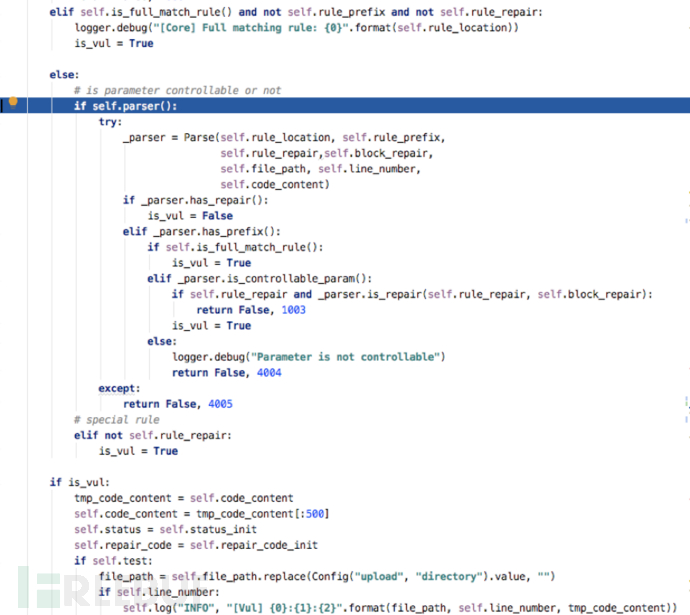
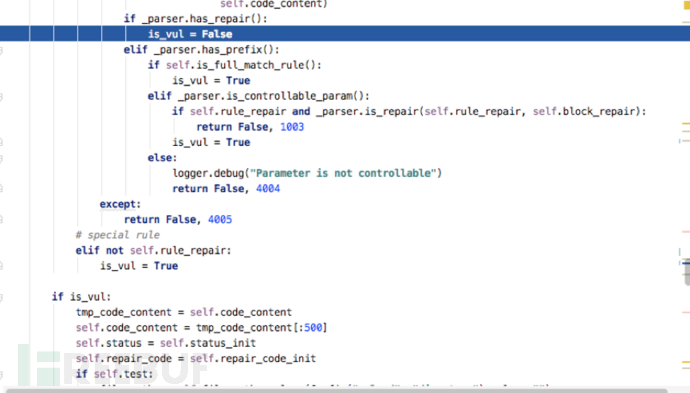
在前面匹配到了定位规则(MongoClient(\s*)\((\s*)\"\w*\")后,这里由匹配到了防御规则MongoCredential\.createScramSha1Credential\(
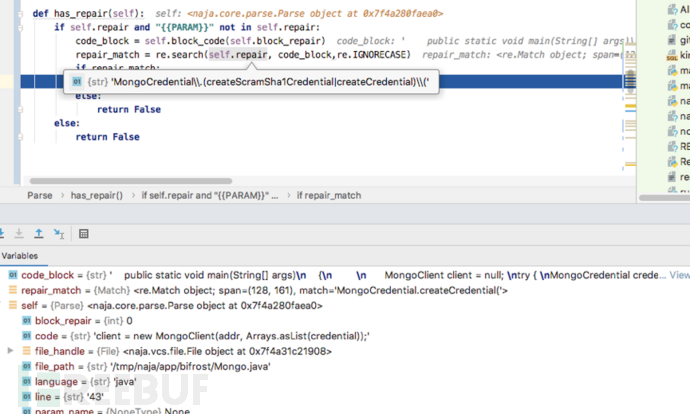
由于匹配到了防御规则所以这里is_vul=False可以判断没有代码风险。
如果采用Java原生API访问MongoDB没有认证代码,那么这里就无法匹配到防御规则因此is_vul=True,说明业务方没有对MongoDB进行鉴权,因此可以判定为存在代码风险。
*本文作者:hackeryeah,转载请注明来自FreeBuf.COM
如需授权、对文章有疑问或需删除稿件,请联系 FreeBuf 客服小蜜蜂(微信:freebee1024)







- 6 文章数
- 32 关注者