


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

- 关注
 本文由
创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
本文由
创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
一、什么是PE文件
PE文件,全称为可执行可移植(Portable Executable)文件,是一种常见的可执行文件格式,通常用于Windows操作系统上的程序和库。
二、入口点以及基地址
入口点(Entry Point):
入口点是PE文件中的一个特定函数或指令,它是程序在运行时启动执行的地方。当操作系统加载一个PE文件并启动它时,它会从入口点开始执行代码。入口点通常位于PE文件的代码节(Code Section)中,并由操作系统负责调用。
基地址(Base Address):
基地址是PE文件在内存中加载时的起始地址。当PE文件被加载到内存中运行时,操作系统会为该文件分配一块连续的内存区域,基地址即为此内存区域的起始地址。基地址通常是由操作系统动态分配的,以确保不同的程序之间不会发生地址冲突。
区别:
入口点是程序开始执行的地方,即程序在内存中执行的第一个指令或函数。
基地址是PE文件在内存中加载时的起始地址,用于确定文件在内存中的位置。基地址加上相对虚拟地址(Relative Virtual Address,RVA)可以计算出在内存中的实际物理地址。
总之,入口点是程序执行的起点,而基地址则是文件在内存中的位置。操作系统负责加载PE文件到内存并执行程序,入口点和基地址都是确保程序正常执行的重要概念。
三、PE文件解析
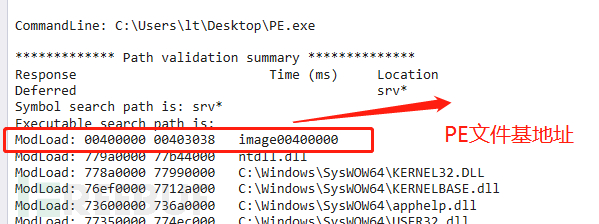
用windbg加载PE文件时候,会给出当前基地址也就是image_base,如下图:
1.MS-DOS头部:
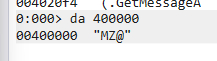
每个PE文件都是以一个DOS程序开始的,也称之为MS-DOS头部,其结构体为IMAGE_DOS_HEANDER,其首字节是MZ字符,如下图:
IMAGE_DOS_HEANDER结构体中有俩个比较重要的变量:
E_magic以及e_lfanew
E_magic 也就是dos头部,代表是个dos文件,其特征值为:0x4d5a 对应的定义为#define
IAMGE_DOS_SIGNATURE 也就是MZ俩个字母
E_lfanew:PE文件头偏移位置(RVA地址)这个地址指向的值为50 45 也就是PE俩个字母
2.PE文件头:
MS-DOS头部之后,紧接着就是PE文件头,其结构体为:IMAGE_NT_HEADER,其中包含许多PE加载器能用到的重要字段,在PE文件分析中占据最重要的比重。
PE文件头地址计算方式为:imagebase+e_lfanew(文件偏移位置),其结构体包含的变量为:
+0h signature (指向的是PE字符) +4h IMAGE_FILE_HEANDER (指向的是一些PE文件的基本信息) +18H IMAGE_OPTIONAL_HEANDER32 (指向PE文件详细信息)
在这里只介绍一些重要字段内容:
对于 IMAGE_FILE_HEANDER 其中比较重要的一个变量为:+14h SizeOfOptionalHeader 指向的是 IMAGE_OPTIONAL_HEANDER32大小。如下图,就是SizeOfOptionalHeader的值:

其中红框地方就是+14h 也就是IMAGE_OPTIONAL_HEANDER32 大小,50 45 00 00是IMAGE_NT_HEADER结构体中第一个内容,也就是signature,后边直到18h为止都是IMAGE_FILE_HEANDER内容,而到了0x18h之时就是IMAGE_OPTIONAL_HEANDER32的起始偏移地址。
对于IMAGE_OPTIONAL_HEANDER32,本次要分析的输入表就是在此结构体的0x78h偏移处,也就是
datadirectory[16]结构(注:其偏移地址是相对于PE文件头开始的,也就是从IMAGE_NT_HEADER开始,而不是相对于DOS头开始的)。
3.DataDirectory[16]:
数据目录表,在window中有一个结构体:IMAGE_DATA_DIRECTORY来形容这个字段,数据目录表由多个IMAGE_DATA_DIRECTORY构成,其结构体为:
IMAGE_DATA_DIRECTORYDOWRD virtualAddress 数据块的地址(RVA:相对地址)其映射到内存中的地址计算方法为:image_base+RVA DWORD size 数据块长度(决定了此时在内存中当前表大小
对于IMAGE_DATA_DIRECTORY 举俩个常见的例子 :
+78h就是export table (导出表)其结构体为:IMAGE_DIRECTORY_ENTRY_EXPORT
输出表含义:
输出表(Export Table)是一种数据结构,用于存储可执行文件中所包含的函数、变量或其他符号的导出信息。输出表允许其他程序(如动态链接库 DLL 或其他可执行文件)在运行时访问和调用这些导出的函数或符号。
这段话就说明了这个数据目录表的含义了:最主要的就是对DLL文件有用,说明了dll中对外提供函数的信息。
输出表在动态链接库(DLL)中特别有用,因为它允许其他程序在运行时加载并调用这些库中的函数。例如,如果一个DLL中的某个函数被导出,并且其他程序需要使用该函数,它可以通过加载该DLL并查找导出表中的函数地址来实现。
+80h就是第二个数据目录表:也就是import table(输入表):IMAGE_DIRECTORY_ENTRY_IMPORT
输入表:显而易见就是输出表的反向含义,也就是我们在编程时候经常要引用其他库函数,比如window自带库,kernel.dll等等,这个表就存储了我们要导入的其他函数(外部的一些函数库),这个在我们进行逆向分析时候特别有用,从外部库引入的函数能让我们更直观的去从宏观分析当前程序是要做什么,有什么目的。
输入表(Import Table),用于存储可执行文件或DLL中引用其他模块(如DLL)中的函数或符号的信息。导入表允许程序在运行时解析和调用其他模块中的函数。
从IMAGE_DATA_DIRECTORY中 我们就可以定位到当前程序的输入表地址,查找引入的函数信息了。
4.区块表:
如下图是一个PE文件的简单结构和在内存中的映射图:
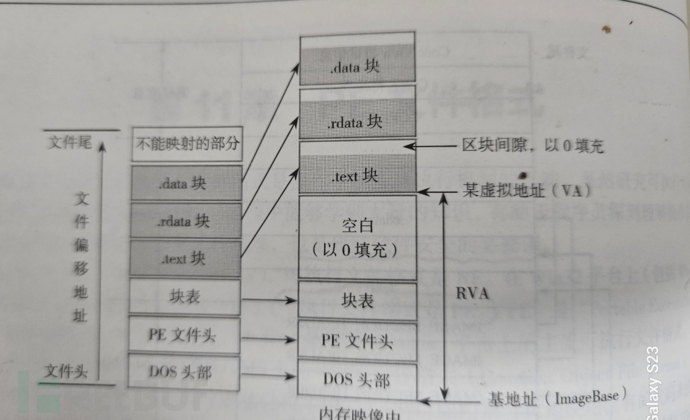
上图就是当前一个PE文件的大致结构,从图中可以知道,PE文件头之上就是区块表这个结构了。
区块表含义:
块表(Section Table)是一种数据结构,用于存储可执行文件的各个段(section)的信息。每个段都对应于PE文件中的一个内存段,可以包含代码、数据、资源等内容。块表记录了这些段的属性和在文件中的位置,从而操作系统和加载程序可以正确地将文件映射到内存中。
块表中的每个条目表示一个段,包含了以下重要的信息:
段名称:每个段都有一个名称,通常是一个ASCII字符串,用于标识段的用途。例如,代码段、数据段、资源段等。
段的虚拟内存地址:每个段在虚拟内存中的起始地址,用于加载程序将段映射到内存。
段在文件中的偏移地址:每个段在PE文件中的起始位置,用于加载程序从文件中读取段的内容。
段的大小:每个段的大小,即包含的字节数。
段的属性:每个段的特定属性,如是否可执行、可读、可写等。
也就是块表这个结构中存储的就是比如.text .radata .data等数据块的信息
其结构体为:IMAGE_SECTION_HEANER
Name:一个 8 字节字段,保存节的名称。例如,“.text”表示代码,“.data”表示初始化数据。 VirtualSize:加载到内存时该节的大小。 VirtualAddress:该节数据开始的虚拟地址(在内存中)。 SizeOfRawData:磁盘上该节数据的大小(在 PE 文件中)。 PointerToRawData:指向文件中节数据开头的文件指针(偏移量)。 Characteristics:描述节的各种属性的标志,例如它是否包含代码或数据,是否可写、可读等。
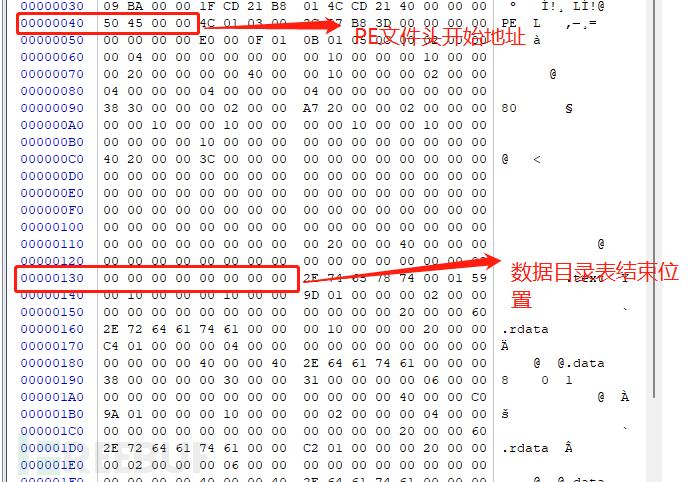
关于具体的结构体含义先不做过多的分析,目前只需要记住一个变量:name 就是区块结构体中第一个变量,大小为BYTE8 8个字节大小,这个名字就是当前的块名,如下图:
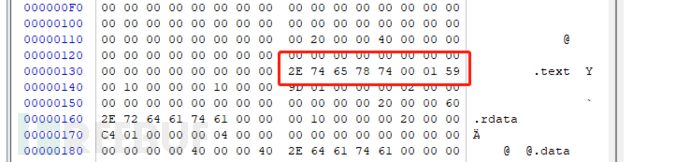
如上图所示当前红框位置就是第一个块表中的name 也就是.text块,其计算方法为:
PE文件头开始位置+F0(最后一个数据目录表的偏移起始位置)+8h(当前数据目录表大小)
为什么是这样的计算方式,这里大致说明下:数据目录表是PE文件头最后一个变量,紧接着就是区块表,一共有16个这样的结构变量,最后一个偏移量是F0,大小为8,所以PE文件头位置+F0+8就是区块表的起始位置,如下图:
关于一些常见区块的含义:
.text 默认的代码区块,内容全部是指令代码。
.data 默认的读\写区块,全局变量,静态变量一般放在这里。
.rdata默认的只读数据区块。
.idata 用于存储可执行文件中引用其他模块(如DLL)中函数和符号的信息。这使得程序可以在运行时解析并调用其他模块中的函数。
.edata 用于存储可执行文件中的函数、变量或其他符号的导出信息,使其他程序可以在运行时访问和调用这些导出的内容。这个区块通常会被合并到.text区块中。
区块对齐值:
PE文件中,区块对齐有俩种,第一种是磁盘对齐,第二种是内存对齐。
比如对于磁盘对齐,每一个区块的开始位置都是对齐值的整数。假如.text第一个字节在400h处,长度为90h,此时.text内容在的区间为400~490h之间,假设对齐值为200h,那么到下一个区块,比如idata区块处,text与idata之间的值必须是200h的倍数,那么此时idata开始的地址为600h,此时490~600h之间的间隙是要用00h填充的。这就是区块的对齐值
IMAGE_OPTIONAL_HEANDER32结构体中fileAlignment定义了磁盘的区块对齐值。其计算方式为PE文件头开始地址+3ch。
PE文件头开始地址就是0x4550出现的地址,3ch就是在IMAGE_OPTIONAL_HEANDER32结构体中fileAlignment偏移地址,这样就会顺利计算出来磁盘的区块对齐值:

第二个就是内存对齐值,也就是IMAGE_OPTIONAL_HEANDER32结构体中sectionalignment值,偏移量为38h,也就是为1000h 在这个例子中
也就是这样的关系,在磁盘中,.text起始值为400h 那么对应到内存中便是1000h ,.idata磁盘起始值为600h 那么对应到内存中就是2000h。
这就是磁盘对齐值以及内存对齐值的基础理解,具体不同的pe文件要进行不同的分析,但是大致思路都是这样的。这里不再过多进行描述。
5.输入表(导入表)
import_table,其对应的directorydata结构体为:IMAGE_DIRECTORY_ENTRY_IMPORT 接下来我们就要解析这个结构体中的内容和含义。
输入表在PE文件头中以一个IMAGE_IMPORT_DESCRITOR(IID)数组开始,每个PE文件连接的DLL都有一个这样的数组。IID结束标志为最后一个单元为NULL。例如某个PE引入了俩个dll文件,那么就会有俩个IID结构来描述当前俩个DLL文件,并且最后会以一个全部为0的IID结构结束。
IID结构体如下所示:typedef struct _IMAGE_IMPORT_DESCRIPTOR {
union {
DWORD Characteristics;
DWORD OriginalFirstThunk;
} DUMMYUNIONNAME;
DWORD TimeDateStamp;
DWORD ForwarderChain;
DWORD Name;
DWORD FirstThunk;
} IMAGE_IMPORT_DESCRIPTOR;关于IID结构体中各个成员的含义介绍如下:
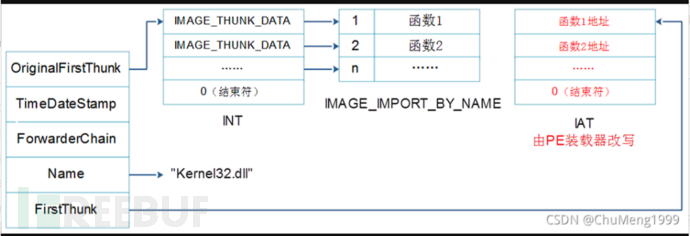
1.OriginalFirstThunk,RVA,指向输入名称表(简称INT),INT是一个类型为IMAGE_THUNK_DATA结构的数组,同样的,通过在数组末尾附加一个空的IMAGE_THUNK_DATA结构来表示数组的结束,每一个输入的函数都有一个对应的IMAGE_THUNK_DATA结构;
2.TimeDateStamp,DLL的时间日期标志,通常忽略;
3.ForwarderChain,通常忽略,不作讲解;
4.Name,RVA,指向DLL的名字,如“User32.dll”;
5.FirstThunk,RVA,指向输入地址表(简称IAT),IAT也是一个类型为IMAGE_THUNK_DATA结构的数组,同样的,通过在数组末尾附加一个空的IMAGE_THUNK_DATA结构来表示数组的结束,每一个输入的函数都有一个对应的IMAGE_THUNK_DATA结构。
在这个结构体中 我们需要注意的只有三个内容:OriginalFirstThunk、Name、FirstThunk
OriginalFirstThunk指向的INT是IMAGE_THUNK_DATA,OriginalFirstThunk指向的是INT(也叫提示名表)不可更改,也就是其指向的是真实的IMAGE_THUNK_DATA 结构,其值是以RVA形式存储的。
而FirstThunk经过加载器直接加载到内存中后,直接指向的是函数地址(在内存中的直接地址,不算是以RVA的形式存储的),FirstThunk在PE加载的时候,是可以被PE加载器修改的,在PE加载到内存中的时候,加载器会用函数的真实入口地址去填充FirstThunk,所以FirstThunk指向的的是真实的函数地址,也就是IAT。
IMAGE_THUNK_DATA结构体为:typedef struct _IMAGE_THUNK_DATA32 {
union {
DWORD ForwarderString;
DWORD Function;
DWORD Ordinal;
DWORD AddressOfData;
} u1;
} IMAGE_THUNK_DATA32;可以看出,该类型仅有的一个成员u1是一个联合体(union),而联合体内的类型都是DWORD,所以IMAGE_THUNK_DATA的大小是4字节。当该类型的最高位为1时,表示函数以序号的方式进行输入,这时候低31位的值就表示函数的序号;当该类型的最高位为0
时,表示函数以名字的方式进行输入,这时候值就表示一个指向IMAGE_IMPORT_BY_NAME结构的RVA。
所以此时我们得知INT指向了IMAGE_IMPORT_BY_NAME 这个结构体,
IMAGE_IMPORT_BY_NAME 得结构体如下:typedef struct _IMAGE_IMPORT_BY_NAME {
WORD Hint; 函数序号
BYTE Name[1]; 函数名字
} IMAGE_IMPORT_BY_NAME, *PIMAGE_IMPORT_BY_NAME;这里借用csdn大佬做的图片,也就是PE加载器没有加载PE至内存时调取函数的流程(FirstThunk还没有被加载器更改)此时关于从kernel.dll取函数名的俩种方式,也就是INT以及IAT取址方式:

WinDbg调试输入表:
下边就是具体实践,教你如何用windbug去调试pe程序获取当前程序的IMAGE_DIRECTORY_ENTRY_IMPORT 相关信息,也就是获得输入表(dll相关信息)。
使用windbg实际调试IAT以及INT 观察导入表的结构(加载器把PE加载至内存中了)
1.获取导入表的directorydata表信息
根据上边IMAGE_DATA_DIRECTORY结构体的定义我们可以得知
DOWRD virtualAddress 数据块的地址(RVA:相对地址)其映射到内存中的地址计算方法为:image_base+RVA DWORD size 数据块长度(决定了此时在内存中当前表大小)
所以此时我们就要知道对于导入表 import table 他这个俩个变量的值大小,这样可以便于我们确认当前导入表的起始地址以及结束地址。
首先此时我们第一个要确定的就是确定导入表的datadirectory 在32位系统中,导入表的偏移地址为80h(注意这个便宜地址是基于pe文件头开始的,而不是dos头部)。
所以此时在windbg中获取datadirectory结构体的步骤为:获取PE文件头位置,然后+80 导入表偏移位置即可,即如下图
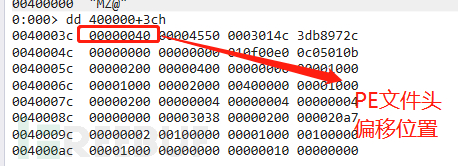
先获取PE文件头偏移量:image_base+3cH:
获取导入表的偏移量(RVA)以及其结构体的值
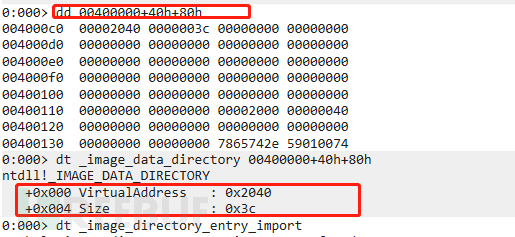
directorydata偏移地址是以PE文件头为基准的,也就是PE文件头地址+偏移地址才是directorydata的地址,从下图我们就得到了当前IID结构体的RVA ,然后通过VA(IID内存地址)=image_base+RVA 得出来当前IID地址,也就是下图400000+2040。
简单解释下400000+40h+80h的含义:
1.此处00400000 是image_base 也就是基地址40h是pe文件头的偏移地址其计算方式是image_base+03ch(也就是e_lfanew值为03h)。
2.40h就是e_lfanew也就是pe文件头偏移值,400000+40h就是pe文件头起始位置,80h是输入表的偏移位置,那么400000+40h+80h就是输入表的起始位置,这样我们就直接通过windbg dt _image_data_directory 400000+40+80 拿到了输入表的信息,也就是
RVA (相对虚拟地址)为2040 导入表数据大小为3c
此时我们就可以直接去寻找关于导入表(IID)的地址信息了(这里有个需要注意的点就是在寻找导入表地址时候是要找映射到内存中的VA 虚拟地址,VA计算方法为:VA=image_base+RVA)。也就是400000+2040
此时在windbg中获取IID结构体数值指令为:

此时我们要注意的就是在标记的地方有连续五个00000000 ,根据上述刚刚说过的知识点:也就是IID结构结束标志。
2.分析IID结构体FirstThunk
前边我们说到了,FirstThunk经过加载器直接加载到内存中后,直接指向的是函数地址(在内存中的直接地址,不算是以RVA的形式存储的),FirstThunk在PE加载的时候,是可以被PE加载器修改的,在PE加载到内存中的时候,加载器会用函数的真实入口地址去填充FirstThunk,所以FirstThunk指向的的是真实的函数地址,也就是IAT。
此时windbg已经加载了PE文件,那么此时FirstThunk已经被修改了,所以此时FirstThunk直接指向的是函数的地址,如下图:
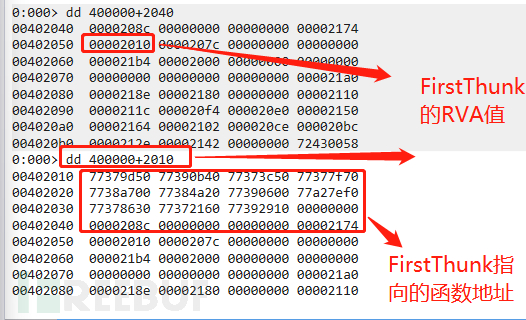
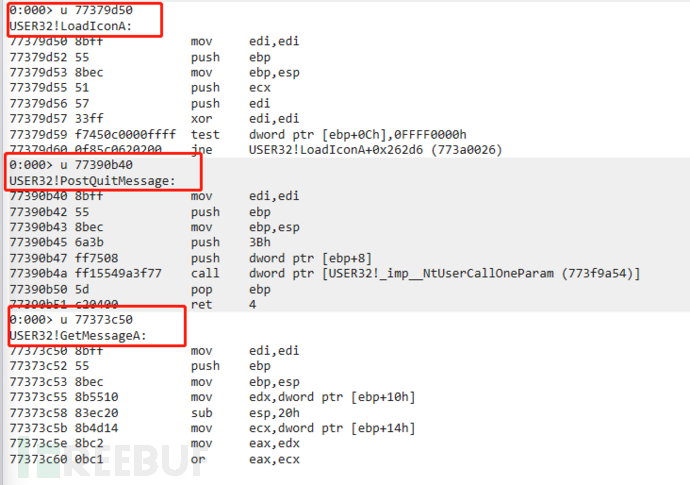
由上边IID结构体可以得知,FirstThunk是在第五个DWORD位置,也就是上图中的00002010(RVA值)
所以通过dd 400000+2010就可以直接拿到了导入函数的直接地址,其函数名字也可以拿到,如下:
3.分析OriginalFirstThunk
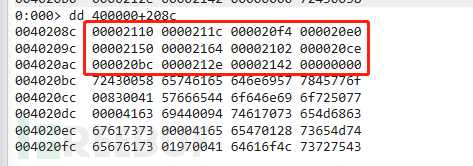
首先获取当前OriginalFirstThunk的RVA值,如下图:

上边说到:对于OriginalFirstThunk来说,其值最高位为1时,表示函数以序号的方式进行输入,这时候低31位的值就表示函数的序号;最高位为0时,表示函数以名字的方式进行输入,这时候值就表示一个指向IMAGE_IMPORT_BY_NAME结构的RVA。
所以此时我们从windbg去获取当前最高位,如下图:
可以看出来当前最高位均为0,所以此时他是指向的是IMAGE_IMPORT_BY_NAME
上文也说到,但对于IMAGE_IMPORT_BY_NAME来说,其第二个值Name[1]就是函数名字,我们分析PE导入表的目的是为了获取其导入函数名字,也就是获取其name值,我们先尝试再windbg中,直接获取当前IMAGE_IMPORT_BY_NAME的名字尝试下看是否能成功获取到,如下图:
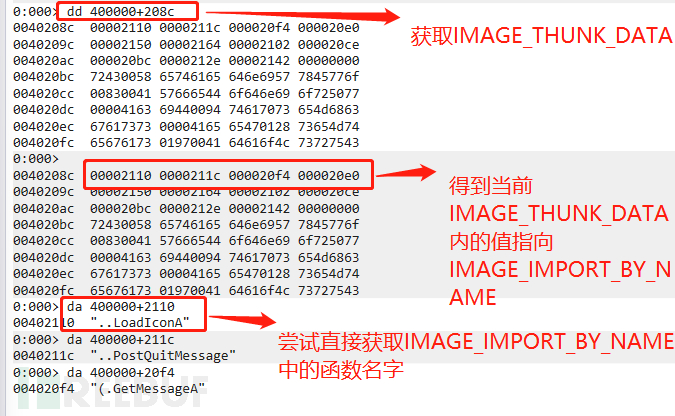
此时发现,每次获取的函数名前总有多余的俩个字节,此时我们进行调试时候前移俩个字节,就会发现我们以OriginalFirstThunk的RVA形式获取到了当前导入函数名字:

此时我们就得到了当加载器把PE文件加载至内存中后整个调取导入表函数的流程图(还是引用了CSDN大神的图片)。如下:
由此通过windbg分析PE文件函数导入表的流程已经结束。
已在FreeBuf发表 0 篇文章
如需授权、对文章有疑问或需删除稿件,请联系 FreeBuf 客服小蜜蜂(微信:freebee1024)
- 0 文章数
- 0 关注者