


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

1、Hive的架构和工作原理
Hive架构
Hive 是基于Hadoop之上的数仓,便于用户可以基于SQL(Hive QL)进行数据分析,其架构图如下:
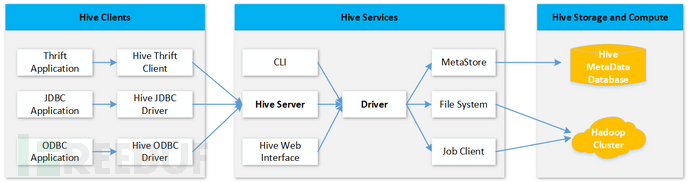
从上图可知,Hive主要用来将建立结构化数据库和后端分布式结构化文件的映射,以及把SQL语句转换为MapReduce(目前还支持Spark等执行引擎)任务,以便进行分布式查询分析。
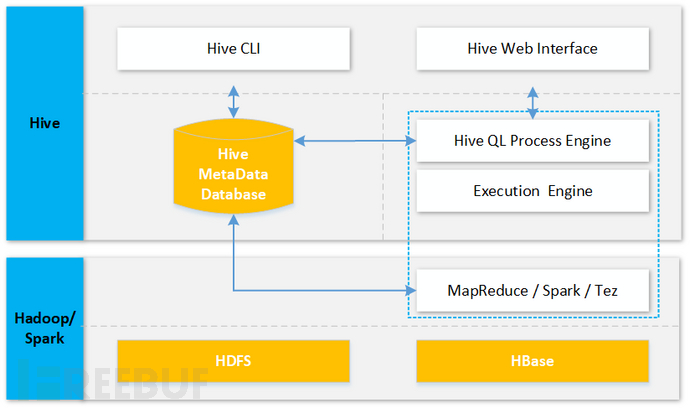
具体分布式文件的存储、分布式计算的执行等均由后端的Hadoop来承接,如下图所示:
2、Hive迁移方案
基于Hive的架构图可知,在新老两个Hive集群之间进行迁移时,需要迁移Hive 元数据以及存储在HDFS/HBase上的文件数据,并调整元数据以适应新集群环境。本文主要讨论Hive 元数据 和 HDFS的迁移。两部分数据的说明如下:
1、Hive 元数据:用来存储hive 关系型数据库和HDFS的映射关系;
2、HDFS文件:用来保存实际数据文件;
需要针对以上两部分数据,分别考虑迁移方案。
2.1 迁移准备
2.1.1 网络打通
通过专线或者VPN打通源集群和目标集群的网络,使得源集群中所有服务器可以和目标集群所有服务器通信,方便后续进行数据拷贝。
2.2 迁移步骤
2.2.1 先迁移HDFS文件
通常HDFS数据体量较大,迁移时间较长,所以建议先迁移HDFS文件
2.2.2 再迁移Hive 元数据
HDFS文件完成全量迁移后,即可以考虑大数据集群停止新的数据写入。停止数据写入后,即可开始迁移Hive 元数据以及迁移增量的HDFS数据(HDFS全量迁移期间很可能有新数据写入,业务团队根据数据写入情况评估)
2.3 迁移方案:
2.3.1 迁移HDFS数据
(1)迁移工具介绍
使用 HDFS DistCp 远程分布式复制数据到目标新集群。DistCp是一个专门用于集群内部和跨集群服务数据的工具,底层利用MapReduce把数据复制拆分为Map任务,进行分布式拷贝。2.8.5版本的官方参考资料:https://hadoop.apache.org/docs/r2.8.5/hadoop-distcp/DistCp.html
HDFS DistCp跨集群复制数据时主要需要指定的命令参数及其功能如下:
- i 忽略拷贝失败的MR任务,让远程拷贝可以执行结束。并会保存拷贝失败的日志。
- log <logdir> DistCp会在map的输出中记录所有被拷贝文件,当map任务失败并且被再次执行时,日志中不会保存改文件记录;(当前在hadoop 2.8.5版本中测试 -log 参数不生效)
- filters 过滤掉某些文件,支持正则表达式
- update
1)源和目标文件长度或内容不同:源文件覆盖目标文件;
2)目标侧文件不存在:拷贝源文件到目标集群
-delete 删除目标端有而源端没有的文件,-delete只有在使用 –update 或 –overwrite的时候生效。
(2)迁移准备
1)停止源和目标HDFS相关文件的写入操作
使用DistCp进行数据复制的前提是:源和目标HDFS中的文件都不能在写的状态,否则DistCp拷贝可能会失败。
2)本方案仅假设所有Hive对应的HDFS数据都存储在HDFS的 /apps/hive/warehouse/ 目录下,若Hive涉及外表或其他非存储在/apps/hive/warehouse/路径的文件,请依据相同方法进行迁移
(3)全量迁移
登录Master节点,切换到hadoop用户:
su hadoop
执行远程分布式全量数据拷贝:
hadoop distcp -i -log /home/hadoop/logs 源HDFS集群访问域名或IP:端口号/apps/hive/warehouse/ 目标HDFS集群访问域名或IP:端口号/apps/hive/warehouse/
(4)增量迁移
登录Master节点,切换到hadoop用户:
su Hadoop
执行远程分布式增量数据拷贝:
hadoop distcp -i -delete -log /home/hadoop/logs -update 源HDFS集群访问域名或IP:端口号/apps/hive/warehouse/ 目标HDFS集群访问域名或IP:端口号/apps/hive/warehouse/
2.3.2 HDFS数据一致性校验
HDFS数据迁移后,利用HDFS可以在3个层面进行数据一致性的校验:
a、校验 HDFS 数据目录文件数量是否一致
如果目录数、文件数、字节数均一致,则可以认为Hive对应的HDFS文件已经迁移完成,且数据一致
b、校验 HDFS 数据目录文件列表是否一致
若希望进一步校验是否所有文件都已迁移,则可以输出Hive对应的HDFS的数据目录和文件的列表,并对比是否一致
c、校验 HDFS 文件内容是否一致
在某些情况下,需要对单个文件的内容进行一致性校验。此时可以使用HDFS自带的checksum工具进行校验,若源和目标文件的checksum相同,则迁移完成且数据一致;否则需要分析原因,并重新进行迁移。
(1)校验 HDFS 数据总体是否一致
查看源和目标HDFS集群的目录数、文件数、字节数是否一致:
利用hadoop fs –count命令来统计目录数,文件数,字节数,当前场景可以使用到的命令参数如下:
-v displays a header line
-x excludes snapshots from the result calculation
即命令为:hadoop fs -count -v -x /apps/hive/warehouse
(2)校验 HDFS 目录和文件列表是否一致
对比源和目标HDFS集群的目录和文件列表是否一致:
利用hadoop fs –ls来输出目录和文件列表,并使用diff工具进行对比是否一致。当前场景hadoop fs –ls命令可以使用到的参数如下:
-R: Recursively list subdirectories encountered. 递归子目录,列出所有子文件目录和文件
-C: Display the paths of files and directories only. 输出结果不显示时间、副本数等与文件列表无关的信息列
#官方参考文档(Hadoop2.8.5):https://hadoop.apache.org/docs/r2.8.5/hadoop-project-dist/hadoop-common/FileSystemShell.html#ls
在源和目标集群分别执行如下命令:
在源集群切换到root用户,执行:hadoop fs -ls -R -C /apps/hive/warehouse > srcfilelist
在目标集群切换到root用户,执行:hadoop fs -ls -R -C /apps/hive/warehouse > dstfilelist
得到文件和目录列表后,放到同一台机器上,使用diff命令进行比较:
当前场景可使用到的diff 命令相关重要参数:
-s --report-identical-files Report when two files are the same
--normal Output a normal diff.
#当源和目标集群文件列表相同时
[root@P4anyrQH-Master1 ~]# diff srcfilelist dstfilelist -s --normal
Files srcfilelist and dstfilelist are identical
#当源和目标集群文件列表不同时
[root@P4anyrQH-Master1 ~]# diff srcfilelist dstfilelist -s --normal
65,66c65
< /apps/hive/warehouse/user_info_db.db/user_tbl_ext_skewed_list_bucketing/age=34/000000_1
< /apps/hive/warehouse/user_info_db.db/user_tbl_ext_skewed_list_bucketing/age=35
---
> /apps/hive/warehouse/user_info_db.db/user_tbl_ext_skewed_list_bucketing/age=40
其中“65,66c65”中c前后分别为,源文件与目标文件内容不同的行,所在的行数
< 代表源文件与目标文件不同的内容
> 代表目标文件与目标文件不同的内容
(3)校验 HDFS 文件内容是否一致
对比源和目标HDFS文件内容是否一致:
利用HDFS自带的checksum命令hadoop fs -checksum来校验单个文件checksum
#官方参考文档(Hadoop2.8.5):https://hadoop.apache.org/docs/r2.8.5/hadoop-project-dist/hadoop-common/FileSystemShell.html#checksum
举例:
#查看源端文件MD5值
[hadoop@P4anyrQH-Master1 logs]$ hadoop fs -checksum /apps/hive/warehouse/user_info_db.db/user_tbl_ext/000000_0
/apps/hive/warehouse/user_info_db.db/user_tbl_ext/000000_0 MD5-of-0MD5-of-512CRC32C 0000020000000000000000000a59f8a9ab89996e42566969734e21ee
#查看目标端文件MD5值
[root@iQotdoaa-Master1 ~]# hadoop fs -checksum /apps/hive/warehouse/user_info_db.db/user_tbl_ext/000000_0
/apps/hive/warehouse/user_info_db.db/user_tbl_ext/000000_0 MD5-of-0MD5-of-512CRC32C 0000020000000000000000000a59f8a9ab89996e42566969734e21ee
#MD5值相同表示
2.4 Hive元数据迁移方案
因Hive 元数据中存储了与HDFS路径相关的信息,所以Hive的元数据的迁移工作分为两部分:
1、迁移Hive 元数据数据到新集群;
2、修正Hive 元数据中与HDFS路径相关的信息;
2.4.1 迁移Hive元数据
1)迁移Hive元数据
Hive 的 元数据 通常存储在MySQL中,主要有以下两种方式进行迁移
(1)在线迁移:
主从同步的迁移方案,解决了元数据迁移的全量+增量的问题
(2)离线迁移:利用mysqldump进行导入导出
离线迁移MySQL的简要操作步骤如下:
(1)使用离线迁移前,需要先确保源集群不再写入元数据。即停止Hive库、表、视图等相关的写操作
(2)从源集群导出元数据
mysqldump -hlocalhost -uhive -p --databases hive > hive_bk.sql
(3)导入元数据到目标集群
mysql -hlocalhost -uhive –p
mysql> source hive_bk.sql
2)校验新老集群Hive 元数据一致性
利用MySQL自带表级checksum工具,建议同版本之间使用,并且大数据量的表做checksum会对库的性能有一定影响,建议测试评估后使用。此处京东云团队对此封装了checksum工具,可以方便进行数据库级别的对比。使用说明如下:
# 下载 checksum 工具
wget "https://mysql-documents.s3.cn-north-1.jdcloud-oss.com/checksum_table" -O ./checksum_table
注意:此工具需安装在一台服务器上,并确保此服务器可以和源和目标MySQL均可通信
# 授权
chmod +x checksum_table
# 数据校验
# --ws 并发度
./checksum_table --src-host mysql-xxx.rds.jdcloud.com --src-user 'user-xxx' --src-pass 'password-xxx' --dest-host mysql-xxx.rds.jdcloud.com --dest-user 'user-xxx' --dest-pass 'password-xxx' --ws 30 --database 'dbname-xxx'
eg:
# source checksum: 源表 checksum 值
# dest checksum: 目的表 checksum 值
# result: 校验结果
+--------+-------+-----------------+---------------+--------+
| schema | table | source checksum | dest checksum | result |
+--------+-------+-----------------+---------------+--------+
| dbtest | tb_1 | 1081724441 | 1081724441 | true |
+--------+-------+-----------------+---------------+--------+
如果出现数据库表的checksum结果为false的情况,可以使用如下方法进行数据修复:
# 下载 mysqldump 工具
# mysql-5.5
wget "https://mysql-documents.s3.cn-north-1.jdcloud-oss.com/mysqldump55" -O ./mysqldump55
# mysql-5.6
wget "https://mysql-documents.s3.cn-north-1.jdcloud-oss.com/mysqldump56" -O ./mysqldump56
# mysql-5.7
wget "https://mysql-documents.s3.cn-north-1.jdcloud-oss.com/mysqldump57" -O ./mysqldump57
# mysql-8.0
wget "https://mysql-documents.s3.cn-north-1.jdcloud-oss.com/mysqldump80" -O ./mysqldump80
# 修复数据
./mysqldump57 -hhost -P3306 -uuser -p'' --set-gtid-purged=OFF database table | mysql -hhost -uuser -p'' -D database
2.4.2 修正Hive元数据中与HDFS路径相关的信息
1)元数据中与HDFS路径相关的表
经调研,元数据中与HDFS路径相关的信息主要保存在如下元数据表中:
(1)DBS
该表存储Hive中所有数据库的基本信息,包括数据库的存储位置
mysql> select * from dbs;
+-------+-----------------------+-------------------------------------------------------------------------------+--------------+------------+------------+
| DB_ID | DESC | DB_LOCATION_URI | NAME | OWNER_NAME | OWNER_TYPE |
+-------+-----------------------+-------------------------------------------------------------------------------+--------------+------------+------------+
| 1 | Default Hive database | HDFS://P4anyrQH-Master1.jcloud.local:8020/apps/hive/warehouse | default | public | ROLE |
| 6 | NULL | HDFS://P4anyrQH-Master1.jcloud.local:8020/apps/hive/warehouse/user_info_db.db | user_info_db | root | USER |
+-------+-----------------------+-------------------------------------------------------------------------------+--------------+------------+------------+
2) rows in set (0.00 sec)
(2)SDS
该表存储文件存储的基本信息:包括表/分区表/分桶表的存放位置
#查询文件的存储信息,此处只展示Location
mysql> select * from SDS;
+------------------------------------------------------------------------------------------------------------------------------------------------+-
| LOCATION |
+------------------------------------------------------------------------------------------------------------------------------------------------+-
| HDFS://P4anyrQH-Master1.jcloud.local:8020/apps/hive/warehouse/user_info_db.db/user_tbl_internal |
| HDFS://P4anyrQH-Master1.jcloud.local:8020/apps/hive/warehouse/user_info_db.db/user_tbl_ext |
+------------------------------------------------------------------------------------------------------------------------------------------------+-
(3)SKEWED_COL_VALUE_LOC_MAP
该表存储表、分区倾斜列对应的文件路径
#查询skewed table的倾斜列的存储路径信息:
mysql> select * from SKEWED_COL_VALUE_LOC_MAP;
+-------+--------------------+---------------------------------------------------------------------------------------------------------------------+
| SD_ID | STRING_LIST_ID_KID | LOCATION |
+-------+--------------------+---------------------------------------------------------------------------------------------------------------------+
| 38 | 11 | HDFS://P4anyrQH-Master1.jcloud.local:8020/apps/hive/warehouse/user_info_db.db/user_tbl_ext_skewed_list_bucketing/age=34 |
| 38 | 12 | HDFS://P4anyrQH-Master1.jcloud.local:8020/apps/hive/warehouse/user_info_db.db/user_tbl_ext_skewed_list_bucketing/age=23 |
+-------+--------------------+---------------------------------------------------------------------------------------------------------------------+
(4)SERDE_PARAMS
该表存储序列化的一些属性,其KV属性信息PARAM_VALUE中可能会涉及存储路径信息,默认无
(5)TABLE_PARAMS
该表存储序列化的一些属性,其KV属性信息PARAM_VALUE中可能会涉及存储路径信息,默认无
2)修正Hive 元数据的方法
(1)元数据修正方式一
人工更新元数据库MySQL表中 HDFS 路径相关内容(推荐)。具体操作为在Hive元数据库所在的MySQL中执行以下SQL语句:
update SDS set location = (select replace(location, '<old path prefix>', '<new path prefix>') ) where location like '%<old path prefix>%';
update DBS set DB_LOCATION_URI = (select replace(DB_LOCATION_URI, '<old path prefix>', '<new path prefix>') ) where DB_LOCATION_URI like '%<old path prefix>%';
update SKEWED_COL_VALUE_LOC_MAP set LOCATION = (select replace(LOCATION, '<old path pre-fix>', '<new path prefix>') ) where LOCATION like '%<old path prefix>%';
update SERDE_PARAMS set PARAM_VALUE = (select replace(PARAM_VALUE, '<old path prefix>', '<new path prefix>') ) where PARAM_VALUE like '%<old path prefix>%';
update TABLE_PARAMS set PARAM_VALUE = (select replace(PARAM_VALUE, '<old path prefix>', '<new path prefix>') ) where PARAM_VALUE like '%<old path prefix>%';
(2)元数据修正方式二
若是mysqldump出 x.sql 文件,且文件不大,可以使用文本编辑器直接批量替换<old path prefix>为<new path prefix>
(3)元数据修正方式三
使用 hive metatool 更新元数据中 HDFS 路径
参考资料:https://cwiki.apache.org/confluence/display/Hive/Hive+MetaTool
hive --service metatool -updateLocation <new-loc> <old-loc>
#此命令明前只更新DBS/SDS两个表中的HDFS路径相关信息;缺少对表 SKEWED_COL_VALUE_LOC_MAP/SERDE_PARAMS/TABLE_PARAMS 的修改;
适合没有使用 skewed table 倾斜表,并且SERDE_PARAMS/TABLE_PARAMS属性值中无HDFS路径信息的场景;
2.5 迁移验证
2.5.1 基础验证
构造基础查询语句进行验证,例如:
select * from 表名 limit 100;
可以构造这样的一批select 语句存入 sel.sql,进行批量执行,并把结果写入文件result,进行校验:
hive -f sel.sql > result
2.5.2 业务验证
挑选一批业务常用的Hive语句存入test.sql,然后分别在新老集群执行并将结果输出到文件中。
hive -f test.sql > result_src
hive -f test.sql > result_dst
test.sql举例:
[hadoop@P4anyrQH-Master1 ~]$ cat test.sql
use user_info_db;
select * from user_tbl_ext;
select * from user_tbl_internal;
使用diff对比两个hive集群执行结果是否相同:
[root@P4anyrQH-Master1 ~]# diff result_src result_dst -s –normal
文件相同时,diff命令输出:
Files result_src and result_dst are identical
如需授权、对文章有疑问或需删除稿件,请联系 FreeBuf 客服小蜜蜂(微信:freebee1024)






- 51 文章数
- 3 关注者