


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

 thundersword
thundersword- 关注
 本文由
thundersword 创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
本文由
thundersword 创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
0x1.前言
这道题没做出来,但是比赛时有很多做出来的,最后才知道这是道原题,其实我应该想到的,因为赛方放了好几道原题,真的是,,,懒到家了,flag都不改一下的。
哦对,比赛时我确实怀疑是原题来着,奈何搜索引擎不给力,试了百度和谷歌都没有搜到【复现时发现用必应一下子搜到了,果然搜代码相关还是要用必应。】
但是发现这道题中的知识点我确实也不知道,所以正好复现学习一下。
中文中括号【】内是我写的内容,外面的则是引用原文博客。
然后下面就是对m1这道题的详细复现过程,其中遇到了很多问题,有些成功解决了,有些则没有,但也是磕磕绊绊的走过来了,如果我的文中有什么不正确或者不恰当的地方,还请各位师傅见谅,在评论区里指出来,也希望我们能够一起学习共同进步。
(ps:参奋郑号码被当作敏感词ban掉了,望师傅们理解)
0x2.复现过程
复现参考wp【个人博客】:http://www.glun.top/2020/10/05/ctf02/
1.深入zip明文攻击
首先这是一个压缩包,有密码保护,然后注释如下:
Password is longer than 16 bytes, and includes at least one number and one uppercase letter. Feel free to crack it if you can, probably with your high-performance quantum computer :)说是难以破解。
压缩包里面有“capture.pcapng”和“hint_for_capture.txt”,压缩算法都是Store,这很奇怪,因
为pcapng并非十分紧密的格式,压缩软件没有理由不压缩它。
1.1.查看压缩方法
010Editer
【不知道这个压缩算法怎么看,然后查了下,好像是从压缩包的头文件等信息看到的,我就用010Editer打开,成功找到了:】
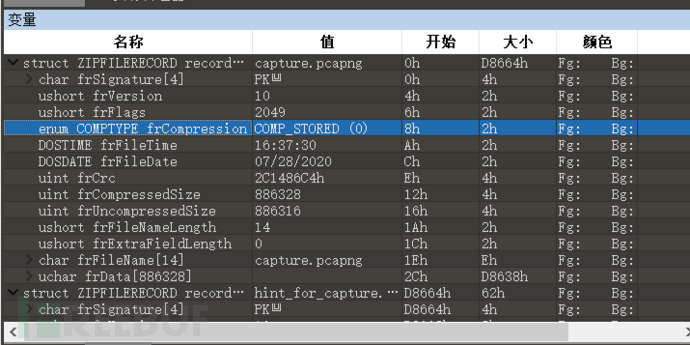
【所以这里的8个字节是0的话应该就代表以store方式存储,也就是未压缩格式吧,不知道有什么好用的工具可以一下子看出来没有】
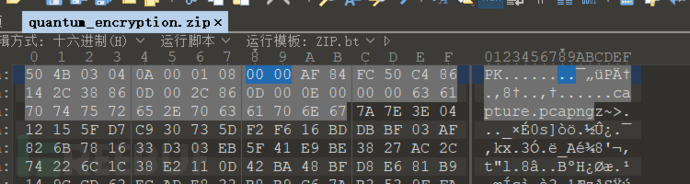
zipinfo
【没想到随便试了试还真找到了,linux自带命令zipinfo,可以清楚的列出文件大小、压缩方式、压缩率等信息,加-v还能显示详细参数,学到了:】
因此我们考虑ZIP明文攻击,只需要知道pcapng中至少 12 个字节(其中至少 8 个字节连
续)的内容即可破解。上网搜索pcapng的文件头格式:

【很不错的思路呢,不过前提是我在比赛中也能看懂文件头格式。。另外它这种文件格式是怎么找到的,直接在百度上搜索是找不到的,在谷歌上搜索“pcapng File Format”才找到了类似的图片,不过这个是在github上的项目,所以之后可以试试在github上搜索试试吧。】
红色部分是固定的:Block Type始终为 0 A0D0D0A;Block Total Length是小端存储的Header
长度,显然不会超过64KB,所以高两位都是 00 ;Byte-Order Magic在小端机器上始终为
4D3C2B1A;Major Version目前只有 1000 ;Minor Version目前只有 0000 。
这样可以知道文件中的 4 + 10 字节内容,满足明文攻击的要求。
其实蓝色部分也是可以猜出来的:Section Length是可选字段,大多数软件(比如WireShark)
在保存pcapng时会写入- 1 (即 8 个字节的FF)。
【这里的分析实在太强了,看了看应该是从这里http://pcapng.github.io/pcapng/draft-tuexen-opsawg-pcapng.html#name-recommended-file-name-exten分析的来的,全都是英文格式,Block Total Length虽然不知道为什么断定不超过64KB,不过随便打开了一个pcapng看了下,它的块长度连256B都没超过,由此,这样断定是有依据的,Block Total Length总长度是32位,总块长度不超过64KB意味着,Block Total Length的有效数字长度不超过16位,故高位两个字节都是00。另外对照了一下这个文档,Major Version按理说应该是1000的,不知道是哪里错了,先往下看解题方式吧。补充:看来是他写错了,验证确实是1000,已更正。】
因此,把蓝色部分也算上的话,我们知道文件中的4+ 18 字节内容,对明文攻击绰绰有余了。
为了严谨起见,我们只使用十分确定的红色部分进行明文攻击。
1.2.深入明文攻击条件
【嗯。。这样说来,我还真不知道明文攻击所需要的字节长度到底是多少呢,只是用文件直接明文攻击,补一下这个知识点,这才在这篇博客上https://blog.csdn.net/q851579181q/article/details/109767425知道了之前一直不知道的一些知识,首先zip的已知明文攻击需要是ZipCrypto Deflate/Store这种加密方式才可以使用 ZIP已知明文攻击进行破解,而 AES256-Deflate/AES256-Store加密的文件不适用于明文攻击。然后深度的已知明文攻击的利用需要的具体要求如下:
至少已知明文的12个字节及偏移,其中至少8字节需要连续。连续的已知明文越大,攻击速度越快。
明文对应的文件加密方式为ZipCrypto Store(如果是ZipCrypto Deflate方式解密的数据是压缩的数据)
该方法对于ZIP加密的算法有要求,明文对应的文件加密方式需要为ZipCrypto Store。经测试,Winrar(v5.80)、7zip(v19.00)默认状态下加密使用的就是AES256算法,直接排除。360压缩(v4.0.0.1220)、好压(v6.2)使用的是ZipCrypto,不固定使用Store或Deflate(如果要固定使用ZipCrypto Store算法加密,可以在压缩的时候指定压缩方式为“存储”)。】
7z查看
【嗯,知道了这个我又有点懵逼了,那么怎么才能查看是ZipCrypto Store加密还是别的加密啊。。。后来发现用7z时可以看到这个加密算法:
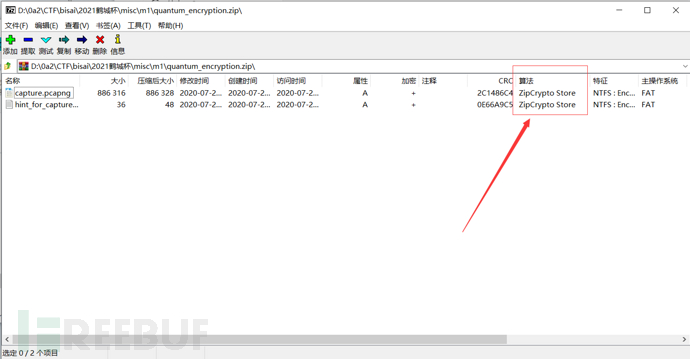
然后就想着命令行版的应该也可以的,于是就找到了:
7z l -slt quantum_encryption.zip

嗯,这样就有方法了,很方便】
1.3.实际攻击
【总而言之,好不容易看懂了,用命令解了下,两种方式都试了,第一种,加上了博客里说的那8字节的ff,果然爆破的也更快: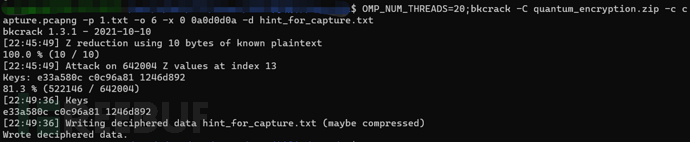
而不加上那8字节也可以爆破,只不过时间更长了一些:
最长端数据放入文件中
这个工具的不合理之处是必须有-p来指定文件,不能全部使用-x来指定,哈哈哈,所以必须要把一部分明文放在文件中,用以下命令来完成:
echo -n "00004d3c2b1a01000000"|xxd -r -p > 2.txt
得到内部密钥
所以内部密钥就是:
e33a580c c0c96a81 1246d892
注意这个内部密钥不是zip真正的密钥,但是我们可以利用这个内部口令来解压出其他文件。
用密钥提取文件
然后可以用-k和-d来解压缩:
这个-c不能和-d相同有点蛋疼。
bkcrack -C quantum_encryption.zip -c capture.pcapng -k e33a580c c0c96a81 1246d892 -d 1.pcapng
#解压那个pcapng文件
bkcrack -C quantum_encryption.zip -c hint_for_capture.txt -k e33a580c c0c96a81 1246d892 -d hint.txt
#解压那个txt文件
2.流量包分析
ok,也记录了一下,继续复现。
2.1.sqlmap注入流量包分析
这流量包居然还是sql注入,这次难度更上一层楼,居然是你咩咩的sqlmap注入,用了多线程的,所以注入结果是乱的,牛批,这道题原来这么难的吗?正好之前没有好好处理过这一块,这次一并复现了。
写了好长时间,终于对照着大佬写出来了脚本:
#!/user/bin/env python3
#encoding=utf-8
import re
from urllib.parse import unquote
inj_re=re.compile(r"bar' AND SUBSTR\(\(SELECT COALESCE\(CAST\(flag AS TEXT\),CAST\(X'20' AS TEXT\)\) FROM flags LIMIT 0,1\),(\d+),1\)>CAST\(X'([0-9a-f]+)' AS TEXT\) AND 'eVUz'='eVUz")
content=[666 for _ in range(200)]
with open('raw.txt','r') as f:
s=f.read()
a=s.split("\n\n")
i=0
while i < len(a):
req1=unquote(a[i])
req2=a[i+1]
i+=2
match=inj_re.search(req1)
if match and 'Content-Length: 5' in req2:
ind,hextxt=match.groups()
txt=int(hextxt,16)
#content[int(ind)-1]=txt
old=content[int(ind)-1]
if txt<old:
content[int(ind)-1]=txt
print(content)
test=[x for x in content if x!=666]
print(test)
print(''.join([chr(i) for i in test]))
然后运行得到的结果是:
[87, 94, 55, 63, 43, 65, 90, 99, 63, 84, 90, 68, 99, 104, 108, 66, 50, 35, 102, 79, 88, 62, 62, 67, 112, 69, 57, 72, 41, 104, 61, 101, 40, 41, 113, 106, 68, 95, 87, 124, 104, 85, 99, 74, 120, 68, 71, 69, 113, 119, 90, 103, 101, 94, 122, 60, 42, 36, 98, 52, 112, 110, 62, 76, 63, 117, 106, 73, 73, 90, 60, 104, 90, 75, 110, 120, 126, 116, 94, 55, 122, 51, 56, 117, 106, 60, 38, 85, 64, 84, 121, 111, 125, 95, 121, 108, 59, 119, 120, 73, 61, 97, 105, 114, 50, 120, 119, 80, 99, 70, 122, 50, 60, 63, 105, 61, 65, 52, 80, 45, 120, 84, 78, 72, 96, 115, 95, 51, 43, 43, 60, 40, 114, 96, 56, 116, 38, 106, 666, 666, 666, 666, 666, 666, 666, 666, 666, 666, 666, 666, 666, 666, 666, 666, 666, 666, 666, 666, 666, 666, 666, 666, 666, 666, 666, 666, 666, 666, 666, 666, 666, 666, 666, 666, 666, 666, 666, 666, 666, 666, 666, 666, 666, 666, 666, 666, 666, 666, 666, 666, 666, 666, 666, 666, 666, 666, 666, 666, 666, 666]
[87, 94, 55, 63, 43, 65, 90, 99, 63, 84, 90, 68, 99, 104, 108, 66, 50, 35, 102, 79, 88, 62, 62, 67, 112, 69, 57, 72, 41, 104, 61, 101, 40, 41, 113, 106, 68, 95, 87, 124, 104, 85, 99, 74, 120, 68, 71, 69, 113, 119, 90, 103, 101, 94, 122, 60, 42, 36, 98, 52, 112, 110, 62, 76, 63, 117, 106, 73, 73, 90, 60, 104, 90, 75, 110, 120, 126, 116, 94, 55, 122, 51, 56, 117, 106, 60, 38, 85, 64, 84, 121, 111, 125, 95, 121, 108, 59, 119, 120, 73, 61, 97, 105, 114, 50, 120, 119, 80, 99, 70, 122, 50, 60, 63, 105, 61, 65, 52, 80, 45, 120, 84, 78, 72, 96, 115, 95, 51, 43, 43, 60, 40, 114, 96, 56, 116, 38, 106]
W^7?+AZc?TZDchlB2#fOX>>CpE9H)h=e()qjD_W|hUcJxDGEqwZge^z<*$b4pn>L?ujIIZ<hZKnx~t^7z38uj<&U@Tyo}_yl;wxI=air2xwPcFz2<?i=A4P-xTNH`s_3++<(r`8t&j
拿到了一段奇奇怪怪的字符串。
2.2.base85加密
然后hint.txt的内容是:
you can get some base**-encoded data
说明结果是base系列加密,然后原wp中写到这个是base85加密,解密出来的结果是:
flag is md5("Sq1it3"+压缩包密码)
Hint: 密码是一个号,且出生年份恰有两个质因子
但是我试过了,我解出来的字符串并不能解密成功,是哪里错了呢?
我将那个字符串base85编码得到了这样结果:
(用的这个工具网站,找了半天才找到个能编码解码中文的base85,就很神奇:http://www.gongjumi.com/Encode/Ascii85Base85)
Ao(mg+DGm>D.GLP,#`J9Bll-T/*2eLkIdeUN.pAsL?G4\.1/U[DKIo^jfaF%TRl6mYN33DjLD5R\
uXo(^$)YNjc?n>]Stp]Pi[\3kEMV#\[:G0^#jmMk+%:h\>82qWp$ggjdVq)XcN~>
不过这个网站好像是把这两行密文分别编码了,所以和我的密文应该不太一样,参考价值不大,但是它的长度也是138,和我密文的长度一模一样。
又找到另外一个网址,编码结果是一行https://cryptii.com/pipes/ascii85-encoding,长度也是138:
Ao(mg+DGm>D.GLP,#`J9Bll-T/*2eLkIdeUN.pAsL?G4\.1/U[DKIo^jfaF%TRl6mYN33DjLD5R\uXo(^$)YNjc?n>]Stp]Pi[\3kEMV#\[:G0^#jmMk+%:h\>82qWp$ggjdVq)XcN
哦呼,尝试解码我的密文的时候,这个网站提醒我存在不合法字符|xw等等,这么一说,好像确实,base85的字符只包含a-u的小写字母。
嗯。。。那是谁错了?我按照这个pcapng的报文里得到的结果如果不错,那是谁错了?得到的结果不是base85编码,但是就应该是base85编码才对,因为我试过了,最后的压缩包密码和wp中的是一样的。
都是:
32070119840810108X
但是这里部分就是不对,不理解。
这里的base85是真的不知道那里出问题了,如果有知道的师傅麻烦告诉一下,非常感谢。
唉,后面的部分复现也好麻烦啊,需要手动生成字典然后用john破解。。。】
3.破解压缩包口令
我们需要破解压缩包口令,考虑John the Ripper。首先用zip2john转换一下:
其中hint_for_capture.txt是压缩包中的纯ASCII文件而且比较小,用来加速破解过程。
已经知道压缩包密码是合法的(哔!)号。由于压缩包注释提到密码包括大写字母,可以推出
(哔!)尾号为X。通过分解质因数得到可行的出生年份列表:
3.1.生成合法(哔!)号字典
我们分析一下(哔!)的格式:
⚫ 前 6 位是区号,上网搜一下可以得到区号列表,全国的合法区号不超过 4000 个。
⚫ 然后 4 位是出生年份,我们从 2020 往下枚举。
⚫ 然后 4 位是出生月日,不超过 366 个。
⚫ 然后 3 位是当天的序号,只需要枚举两位,最后一位可以利用校验码唯一确定。
⚫ 最后 1 位是校验码,固定为X。
这样一来,密码的值域降低到了 1010 量级,可以进行破解了。
首先我们在网上搞一份(哔!)区号列表,存为id_prefix.txt,然后用C++写一个枚举合法
份证号的代码(编译选项-Ofast -march=native,不用Python因为太慢了)。【有错误,下面更改】上面这个代码的命令行参数是年份,将把该年的所有尾号为X的合法(哔!)号输出到stdout。
调用该程序生成字典,然后用john破解。脚本如下:
运行 4 分钟后得到密码:
计算md5(“Sq1it332070119840810108X”)即得到flag。


【看上去还是比较简单的,但是也比较繁琐,不过john这款工具总会用到的,不能逃避。
2个质因子的年份
首先是从1950年到2020年恰好拥有2个质因子的年份生成一下,原文复现时使用的是1920到2020,我就弄少一些吧,我觉得不会出一个(哔!)是个百岁老人甚至还没建国的出生日期吧。。。好吧,主要是我知道答案了,想省点劲,不过wp种是从后往前依次爆破的,聪明,那就无所谓了。
先是用的这个脚本:
>>> from libnum import factorize
>>> t=[]
>>> for x in range(1950,2020):
... sum=0
... s=factorize(x)
... for i in s:
... sum+=s[i]
... if sum==2:
... t.append(x)
...
>>> t
[1954, 1957, 1959, 1961, 1963, 1966, 1967, 1969, 1977, 1981, 1982, 1983, 1985, 1991, 1994, 2005, 2018, 2019]
然后发现根本没有包含正确答案1984,,,打印了一下看看:
>>> factorize(1984)
{2: 6, 31: 1}
。。。。原文要求是这样的:
flag is md5("Sq1it3"+压缩包密码)
Hint: 密码是一个号,且出生年份恰有两个质因子
我还以为它说的2个质因子是真的只有两个呢,你倒是说成2种啊!这不引起歧义吗,真是的。
于是:
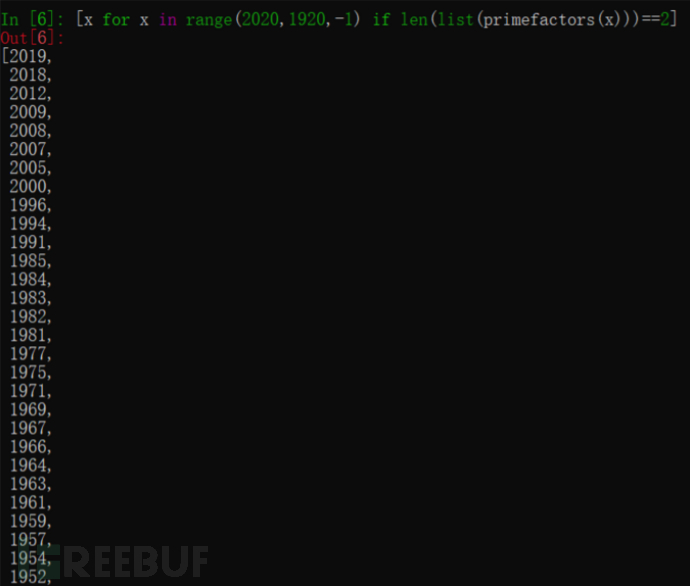
>>> [x for x in range(1950,2020) if len(factorize(x))==2]
[1952, 1954, 1957, 1959, 1961, 1963, 1964, 1966, 1967, 1969, 1971, 1975, 1977, 1981, 1982, 1983, 1984, 1985, 1991, 1994, 1996, 2000, 2005, 2007, 2008, 2009, 2012, 2018, 2019]
全国的区号列表
然后是全国的区号列表,找了找终于在github上找到了:验证中国 前6位对应地区码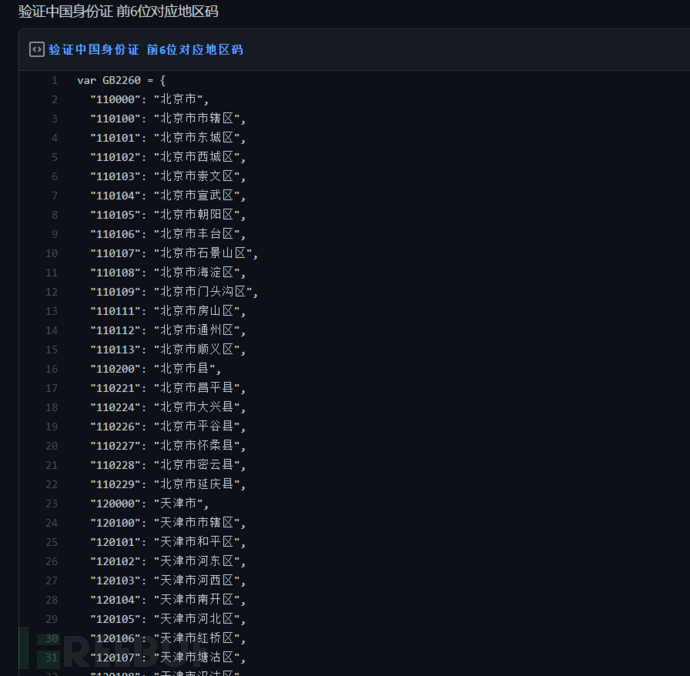
正确的区号是320701来着,嗯,里面有,没问题。
是json格式的,拷下来用python生成一个纯粹的列表吧
>>> import json
>>> f=open('json区号.txt','r')
>>> a=json.dump(f)
>>> list(a)[0]
'110000'
>>> with open('id_prefix.txt','w') as f2:
... for i in a:
... _=f2.write(i+'\n')
>>> f.close()
然后我打开自己删了下最后的换行,共3645行。
3.2.编写字典生成代码
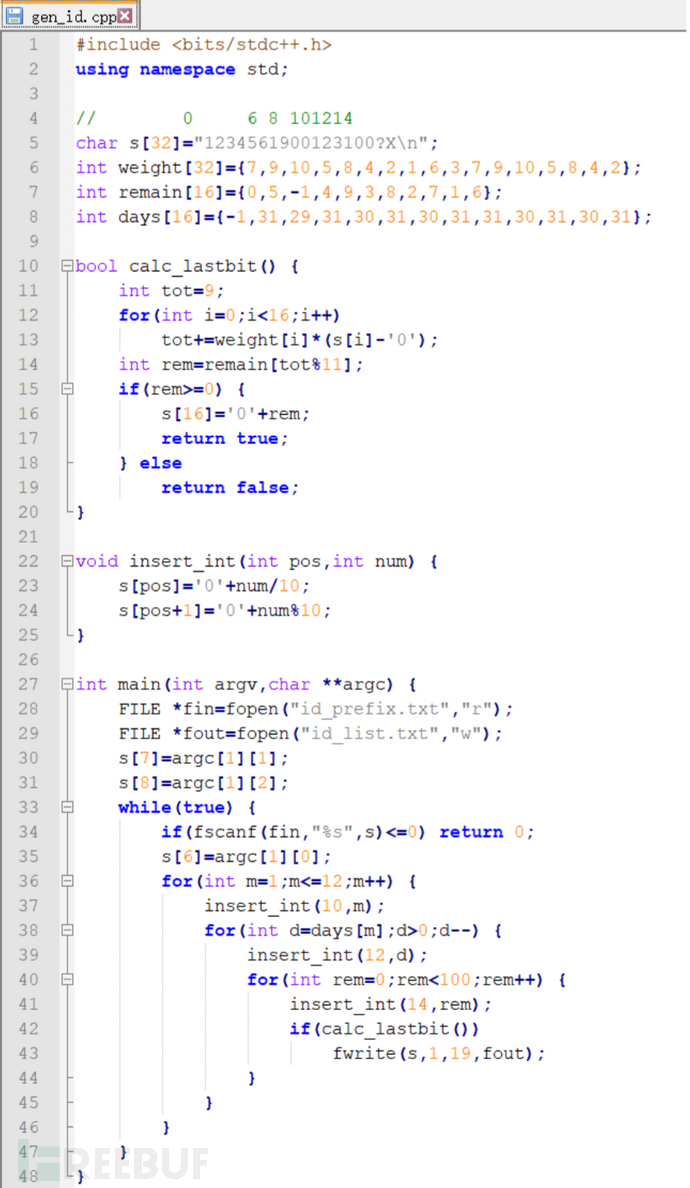
先是直接照着wp中的代码抄了一边,我是个无情的抄代码机器。。。【然后他的代码好像少了一行,添加上去,已修正代码:】:
#include <bits/stdc++.h>
using namespace std;
char s[32]="1234561900123100?X\n";
int weight[32]={7,9,10,5,8,4,2,1,6,3,7,9,10,5,8,4,2};
int remain[16]={0,5,-1,4,9,3,8,2,7,1,6};
int days[16]={-1,31,29,31,30,31,30,31,31,30,31,30,31};
bool calc_lastbit()
{
int tot=9;
for(int i=0;i<16;i++)
tot+=weight[i]*(s[i]-'0');
int rem=remain[tot%11];
if(rem>=0)
{
s[16]='0'+rem;
return true;
}
else
return false;
}
void insert_int(int pos,int num)
{
s[pos]='0'+num/10;
s[pos+1]='0'+num%10;
}
int main(int argv,char **argc)
{
FILE *fin=fopen("id_prefix.txt","r");
FILE *fout=fopen("id_list.txt","w");
s[7]=argc[1][1];
s[8]=argc[1][2];
s[9]=argc[1][3];//原作者的图片中没有这一行
while(true)
{
if(fscanf(fin,"%s",s)<=0) return 0;
s[6]=argc[1][0];
for(int m=1;m<=12;m++)
{
insert_int(10,m);
for(int d=days[m];d>0;d--)
{
insert_int(12,d);
for(int rem=0;rem<100;rem++)
{
insert_int(14,rem);
if(calc_lastbit())
fwrite(s,1,19,fout);
}
}
}
}
}
看了下发现了一些不对劲的地方。。。weight数组设定了32位大小,但是其中只有17位数字,remain数组设定了16位大小,但是只用了11位的空间,这是为了使空间分配的更为合理吗?不太懂。
合法(哔!)检验方法
然后calc_lastbit()函数就是为了检测生成的(哔!)号是否合法的判断函数,但是这里并没有判断最后一位,猜测这个函数只能判断结尾为X的(哔!)号的正误,算了,先这样吧,之后用到其他的生成的话再找(哔!)号校验规则吧。。。开玩笑的,还是找下好好了解下吧:http://www.woshipm.com/pmd/350196.html
主要步骤一张图就可以解释:
这样就懂了,(哔!)号中倒数4个数中的前3个是当天的序号,最后一位是校验位,现在最后1位确定为X,那么只需要余数为2便说明校验成功。
但是遍历前3位的话就需要遍历0~999这1000个数字,从中选择满足条件的数字,这里这个代码用了一个巧妙的办法来较少这个过程,这应该也是一种算法,但是我不太清楚,这里就按照我的理解来了。
分析化简算法
首先余数确定为2,如果tot确定为9的话,那么remain序列的值便是固定的。
生成那个remain序列的代码写出来了,不过还是有些不清楚:
>>> for i in range(0,11):
... for x in range(9,-9,-1):
... if (9+2+i+x*2)%11==0:
... print(i,x);break
...
0 0
1 5
2 -1
3 4
4 9
5 3
6 8
7 2
8 7
9 1
10 6
首先tot为什么要为9,有什么好处吗?
我遍历一下其他可能性。
然后发现tot=10的时候生成的序列便是0~10的乱序,而tot=9的时候则是生成-1~9的乱序,tot=8时则会生成-2~8的乱序,依此类推。
额。。。。我懂了,设置的时候只能设置0~9,因为是一位10进制数啊。。。所以tot一定为9。
好吧,总而言之明白这个怎么用的了,总之tot为9生成脚本就是:
remain=[]
for i in range(0,11):
for x in range(9,-9,-1):
if (9+余数+i+x*2)%11==0:
print(i,x);remain.append(x);break
print(remain)
此时每次只需要遍历100个数字,从1000次降低到100次,最后一个数字直接算出,其中有十分之一的数字被舍去。
十分巧妙。
之后再使用这个脚本来生成其他合法份的字典的话也简单,查一下上面的那个表,看一下最后一位对应的余数,然后用tot为9生成脚本生成一下remain序列替换掉c++中的remain序列即可。
运行代码
好了好了,终于搞的差不多了,继续复现。
用devc++编译器编译了一下试试,可以成功生成。
尝试了一下随便生成了一个年份的所有(哔!)号,是真的离谱,就生成了一个就2.14G,有够多的。
看来这个代码分别来爆破是正确的,验证了一下:
倒数第2位是4的没有,说明成功运行了。【后来发现还是有错误的,我明明测试的是1984,怎么是1980的年份,他少了一行代码,上面已更正】
3.3.使用john爆破密码
ok,按照之前的shell代码,来爆破吧。
哦对,还少了一步,john一般是用来爆破一些密码散列的。
安装john
john的项目地址:https://github.com/openwall/john
而爆破其他的密码,比如说zip,就需要用john项目中的一些脚本来转换一下,正如文章中所说的:
需要用zip2john转换一下,他这里用的是windows的,我下载下来源码,编译运行一下即可。
git clone https://github.com/openwall/john.git
cd john/src
./configure && make
不过kali自带的,一般不需要安装吧。
编译用了好长时间,好了之后可以run目录找到执行文件。
问题是我的john编译好了可以运行,但是zip2john却编译失败了,不理解。
生成好字典之后我用ARCHPR爆破试了下,还是蛮快的,4s就得到了结果,果然字典爆破还是快啊,当然只是1984一个年份,可惜它不能命令行使用啊,不然就可以直接用了。
zip2john转换zip
然后zip2john没有。。。那就去网上找一个吧。
找到了。。。另外注意一下,zip2john必须在它原来的目录下运行,也就是在run文件夹下运行,不能复制到其他地方运行,不然就没有回显。。。。
ok,然后执行:
这里它的-o居然不是指定输出文件,就很阴间,必须用大于号>,-a是可选项,如果知道压缩包的一部分明文能加速爆破过程,这里当然是加上。
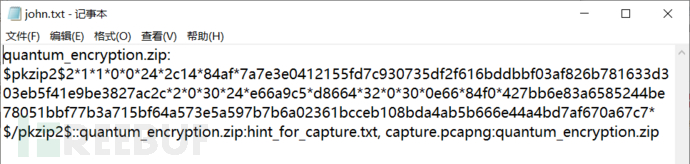
然后得到john.txt。
爆破bat批处理脚本
然后照着写一个bat脚本,我刚注意到这是bat不是shell。。。。
@echo off
for %%i in (1994 1991 1985 1984 1983) do (
echo cracking %%i
gen_id.exe %%i
john-1.9.0-jumbo-1-win64\run\john.exe --wordlist=id_list.txt --fork=10 john.txt
)
我这里稍微改一下,让它不要爆破那么多年份,少爆破几个,另外线程也加到了10个。
实际操作
第一次爆破失败了,没爆破出来吗?
为啥呢?本以为是文件名的问题,就把hint.txt改为了hint_for_capture.txt再生成john文件,结果和上次的john文件一模一样,那说明问题不在这里啊,好奇怪啊。
哦哦,我再次运行时他说已经没有密码可以爆破,所以是已经爆破出来了的意思。
这个也没有什么明显的显示吗。。。
找到了,有够不明显的。。。:
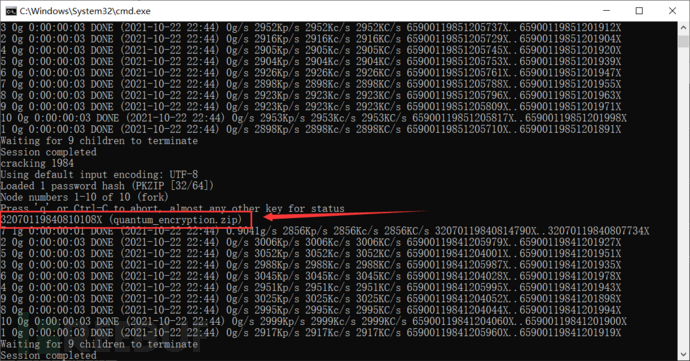
不过还好,john还有个show参数:
>john-1.9.0-jumbo-1-win64\run\john.exe --show john.txt
quantum_encryption.zip:32070119840810108X::quantum_encryption.zip:hint_for_capture.txt, capture.pcapng:quantum_encryption.zip
问题是如果是按照wp上那样子爆破,如果没看到的话岂不是不知道终止一直运行到结束也不知道爆破成功了没有吗?
欸?也不对,后面如果爆破出来的话它会提示你没有密码可爆破了,这就可以了:
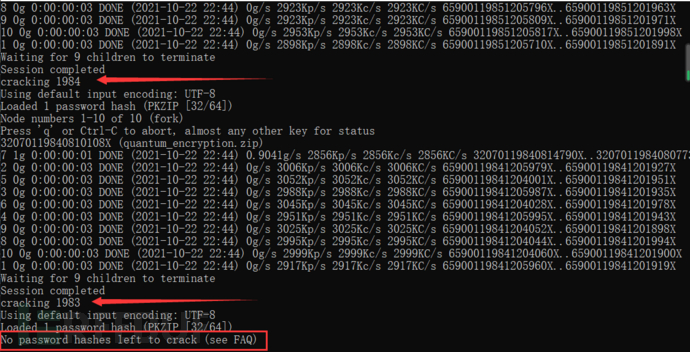
另外它的第一个是主进程,密码总是显示在那个上面应该是。
嘛,总算是尝试了一次john破解压缩包密码的全程,舒服了。
总的来说,主要部分还是在字典部分,如果所有的可能值都在同一个字典文件中的话那么直接用ARCHPR爆破就行了,当然用john也可以,不过更为麻烦些。
另外就是像这道题这样,需要爆破不同的时间年份,每一个年份生成的字典文件都是2GB+,这样来上几十个份这谁受的住啊,所以依次产生,依次爆破。
就像这样写个bat批处理就可以了。
0x3.参考
http://www.glun.top/2020/10/05/ctf02/
https://pcapng.github.io/pcapng/
https://blog.csdn.net/q851579181q/article/details/109767425
https://www.woshipm.com/pmd/350196.html
已在FreeBuf发表 9 篇文章
如需授权、对文章有疑问或需删除稿件,请联系 FreeBuf 客服小蜜蜂(微信:freebee1024)





- 9 文章数
- 30 关注者