


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

 星环科技官方
星环科技官方- 关注
Sophon是一款包含数据分析和机器学习建模的一系列智能分析软件。基于本软件,您可以快速完成从特征工程、模型训练到模型上线的机器学习全生命周期开发工作。为了帮助您快速入门,本文将以精准市场营销模型应用实验为例来展示Sophon Base的使用过程。
关于Sophon Base
Sophon包含3个主要模块:Sophon Base、Sophon Edge、Sophon KG。其中Sophon Base 数据科学基础平台具备完整的数据探索、多数据源接入、实验调度、智能分析、用户资产以及平台管理等功能;为用户提供完整的模型上线闭环,全流程图形化帮助用户更加便捷地对线上服务进行管理,实现模型价值。
实验背景
某家企业希望开拓新用户进行精准的市场营销,但企业只知道市场营销方案对过去的用户是否产生效果。用人工甄别的方式筛选现有用户将消耗大量的人力资源。
通过建立精准市场营销模型,让企业可以运用过往用户数据来预测营销方案是否会对现有用户产生效果,从而锁定潜在用户,提高邮件、短信营销的转化率,减少企业营销行为的成本。
在本实验中,我们将以精准市场营销为案例背景,展示如何使用Sophon Base来完成精准市场营销模型的训练、测试、预测、上线与实际应用。
数据集
Sophon Base平台在数据样例中为该实验提供了两个样例数据集,分别为包含过去用户信息的数据集pastcompaigndata与包含现在用户信息的数据集newcompaigndata。
在实验开始前,先浏览数据集pastcompaigndata中的字段以及取值: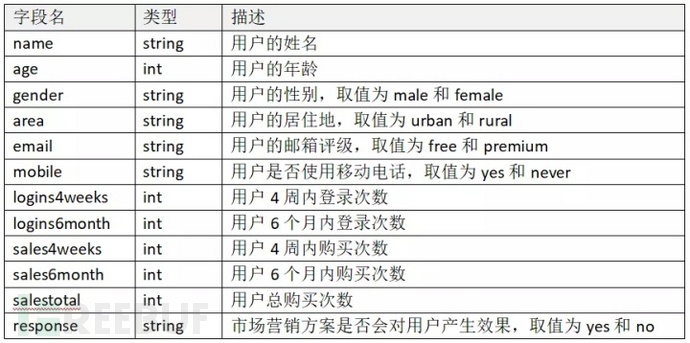
数据集pastcompaigndata字段
在本实验中,“response”以外的字段将作为模型的输入,“response”字段将作为模型的输出。
数据集newcompaigndata包含除了“response”以外的所有字段。因此,您需要使用数据集pastcompaigndata训练市场营销模型并测试。训练出的模型将读取newcompaigndata中的用户信息,并预测营销方案是否会对这些用户产生效果。
浏览完数据集的字段后,您已经知道该实验近似监督学习中的二分类问题。本实验将选择随机森林算法来训练模型。因为该数据集字段较多,这也意味着它具有较高的维度;字段的取值较少,“gender”、“area”、“email”、“mobile”等字符串字段只有两种取值。而随机森林计算开销小,性能强大,擅长处理高维度的数据;同时字符串字段取值划分较少,随机森林产生的属性权值具有可信度。在训练结束后,随机森林能够给出哪些字段比较重要。
开始实验
在创建项目之前,本文默认您的sophon平台及各种配置文件已经成功安装,正常运行,并且您已成功注册sophon 用户。
进入项目首页,点击“+新建项目”以新建一个项目:
新建项目
在新建项目对话框中配置项目参数: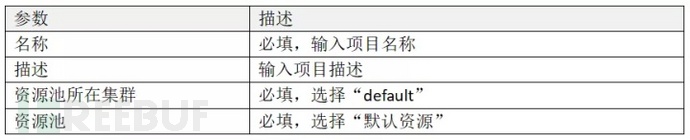
参数配置完成后,点击“确认”以创建项目。
在项目首页,点击创建好的项目,进入项目详情页面。该页面包含实验、数据集、SQL编辑、特征、代码、Notebook、模型、运行历史、API模型服务、工作流等数据。
点击左侧的实验,点击实验,并新建空白实验:
点击实验,并新建空白实验
在新建空白实验页面,填写实验的名称与保存位置,点击确定以创建实验。实验创建后会自动进入该实验界面。
数据导入
在左侧算子选择中点击“数据集”>“数据样例”>pastcompaigndata,将pastcompaigndata拖动至右侧工作区:
拖动pastcompaigndata
选中pastcompaigndata,右键菜单>“查看数据”,可以预览数据集的内容,看到结果如下: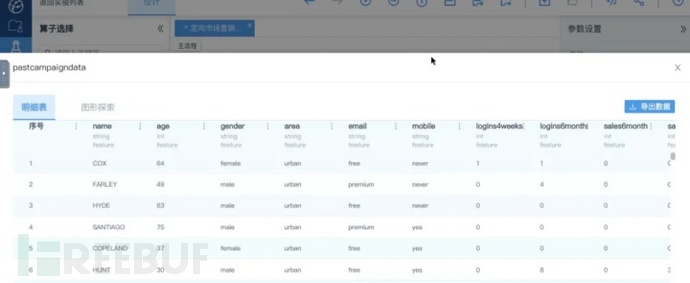
预览pastcompaigndata数据
数据探索
接下来进行数据探索操作。点击左侧工具栏的数据集按钮进入数据集界面:
数据集按钮
在数据集界面,点击上方的样例按钮,在下方查找到pastcompaigndata数据集样例: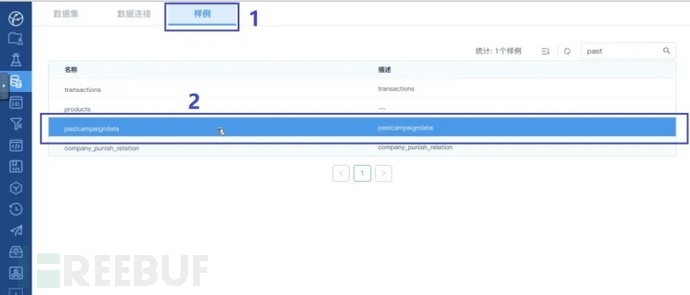
数据集界面
点击该样例后可以进入样例的详情页面,点击上方的图形探索按钮,切换至图形探索页面进行数据探索。
拖动左侧数据列至右侧维度、指标、交叉分类等操作框中来进行绘图。点击上方的统计分析按钮,切换至统计分析页面进行统计分析;勾选数据列,点击“分析”,即可得到数据集的整体统计分析结果。
数据预处理
我们可以通过搭建算子来快速完成数据的预处理工作。
在左侧选择“预处理”>“字符串”>“字符串索引”算子并拖动至工作区,将数据源的output连接至“字符串索引”算子的input。
在左侧选择“预处理”>“元信息”>“设置角色”算子并拖动至工作区,将“字符串索引”算子右侧的output连接至“设置角色”算子的input。
在左侧选择“预处理”>“其他”>“样本切分”算子并拖动至工作区,将“设置角色”算子的output连接至“样本切分”算子的input。
您也可以在搜索框中直接输入名称搜索算子,对应的算子会被检索出来。
算子连接完成后如图所示: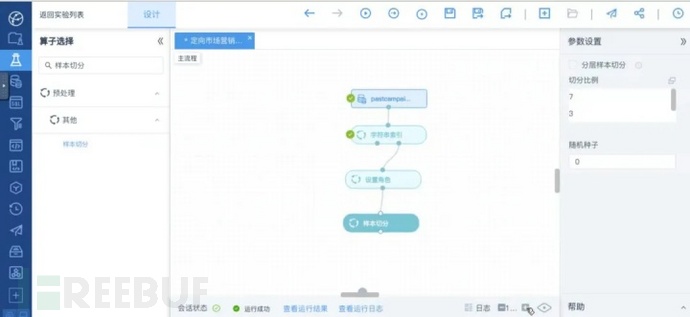
预处理算子连接
点击选中“字符串索引”算子,在右侧进行参数设置: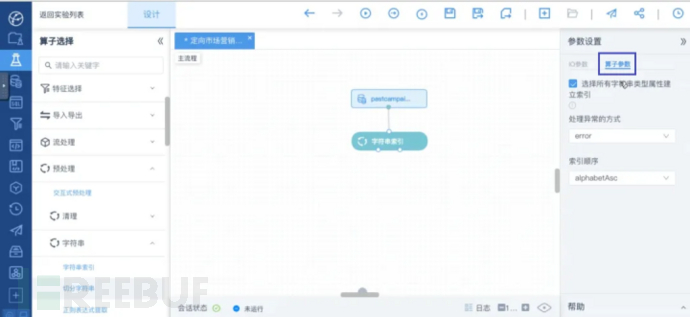
“字符串索引”算子>算子参数
先点击右侧的算子参数,并设置参数:
之后点击左侧的IO参数,然后点击属性子集右侧的按钮,进入选择属性页面:
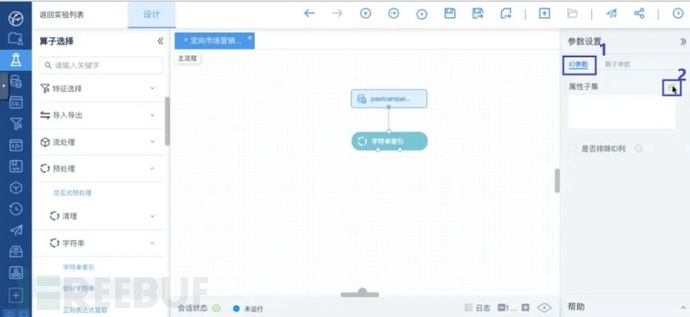
“字符串索引”算子>IO参数设置
在选择属性页面的左侧勾选“gender”、“area”、“email”、“mobile”、“response”这五个属性。然后点击右侧的向右按钮来选中这五个属性,点击确定来完成选择: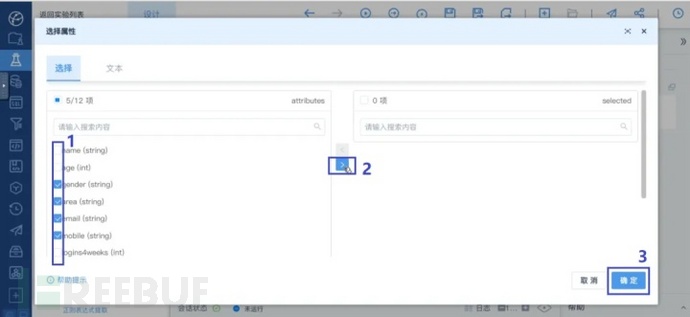
“字符串索引”算子>IO参数设置>属性子集
“是否排除ID列”保持默认值不勾选。至此,“字符串索引”算子的参数设置完成。
点击选中“设置角色”算子,在右侧设置参数:
点击额外的角色设置右侧的按钮,进入额外的角色设置页面: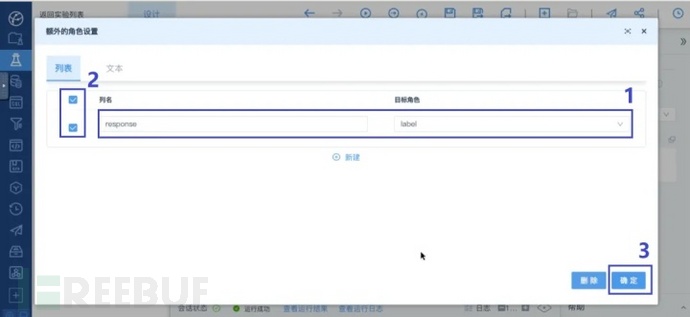
“设置角色”算子>额外的角色设置
在额外的角色设置页面里,先选择列名为“response”,目标角色为“label”。然后勾选该列。最后点击确定完成设置。至此,设置角色算子的参数设置完成。
点击选中“样本切分”算子,在右侧设置参数。点击切分比例右侧的按钮进入切分比例页面,如图示将切分比例设置为7:3,70%的数据作为训练集,30%的数据作为测试集: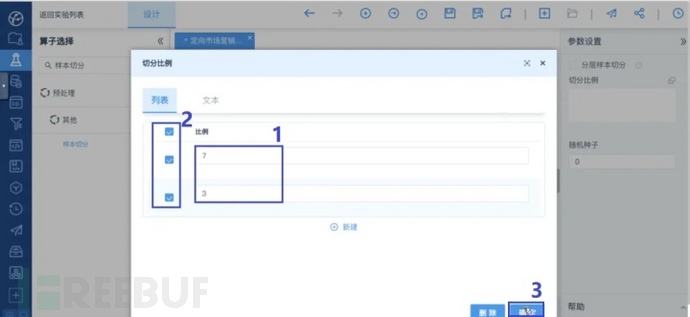
“样本切分”算子>切分比例
勾选比例后点击确定来完成设置。不勾选“分层样本划分”,随机种子设置为0。至此,数据预处理完成。
模型训练
在左侧选择“机器学习”>“分类”>“随机森林”算子并拖动至工作区,将“样本切分”算子的partition1连接至“随机森林”算子的train set。
在左侧选择“导入导出”>“模型写入”算子并拖动至工作区,将“随机森林”算子的model连接至“模型写入”算子的model。
算子连接完成后如图所示:
模型算子连接
点击选中“随机森林”算子,在右侧设置参数。
算子参数: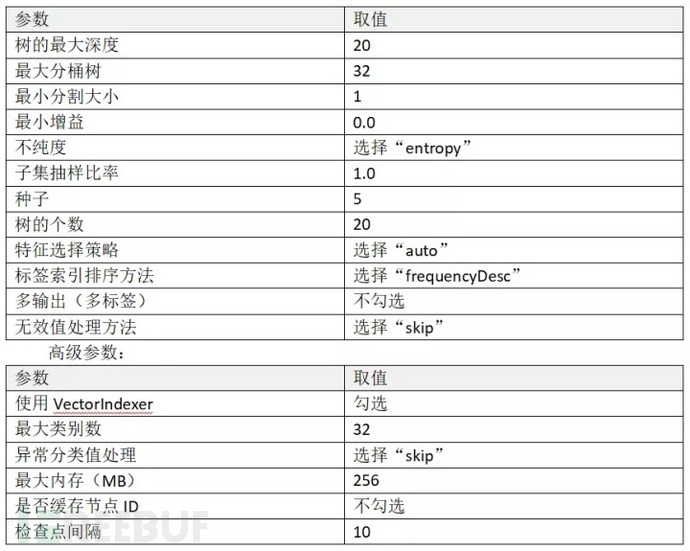
值得注意的是,随机森林中的树一般会设置的比较深,以尽可能地降低偏差。本文中“随机森林”算子的参数设置仅供参考,您可以对算法模型设置不同参数调试来得到多个训练结果,根据训练结果来构建性能最佳的模型。
点击选中“模型写入”算子,在右侧设置参数。如果您还没有导出过模型,您可以在右侧勾选“创建新模型文件”并为你的新模型命名。如果您已经导出过模型,您可以不勾选“创建新模型文件”并选择一个已有的模型,实验执行后,导出的模型会自动覆盖选择的模型。
通过“模型写入”算子,我们可以导出并保存训练完的模型。
性能验证
我们需要对训练完的模型进行验证与评估。
在左侧选择“验证与评估”>“应用模型”算子并拖动至工作区,将“随机森林”算子的model连接至“应用模型”算子右侧的model。同时将“样本切分”算子的partition2连接至“应用模型”算子左侧的input。
在左侧选择“验证与评估”>“性能(二分类)”算子并拖动至工作区,将“应用模型”算子的output连接至“性能(二分类)”算子的input。
算子连接完成后如图所示: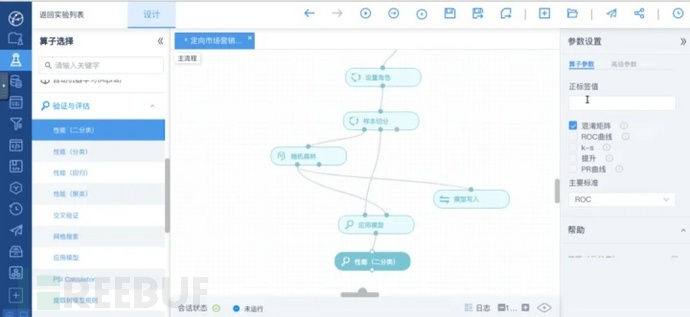
性能验证算子连接
点击选中“性能(二分类)”算子,在右侧设置参数,此处您可以根据自己的实际需要选择评估标准: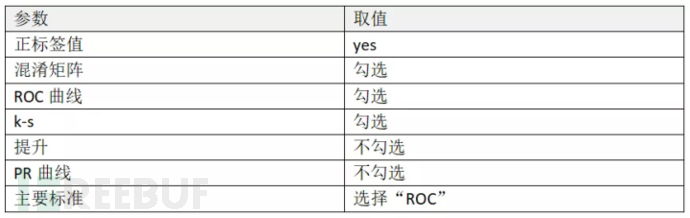
将“性能(二分类)”算子的output连接至result,点击上方的执行按钮,输出训练模型的测试结果,对得到的测试结果进行分析:

混淆矩阵
测试集中有119个“yes”样本与157个“no”样本。为方便理解,分别称它们为真样本与假样本。
如果一个真样本被预测为真,我们称其为真阳性(TP);一个真样本被预测为假,我们称其为假阴性(FN);以此类推,一个假样本被预测为真,我们称其为假阳性(FP);一个假样本被预测为假,我们称其为真阴性(TN)。
您可以通过召回率和精准率来初步评估模型的好坏。召回率体现了所有正样本中被识别出的正样本的比例,精准率体现了所有预测为正的样本中预测正确的比例。召回率与精准率可以由以上四个数字得出:召回率=TP / (TP + FN)、精准率= TP / (TP + FP)。
根据混淆矩阵中的信息,您可以知道:有115个真阳性,10个假阳性,4个假阴性,147个真阴性,召回率为0.966、精准率为0.920。可以看出该模型无论是召回率还是精准率都较高。
您也可以使用ROC曲线来评估模型的性能。ROC曲线可以反映模型在选取不同阈值时其命中率与误判率的趋势走向。
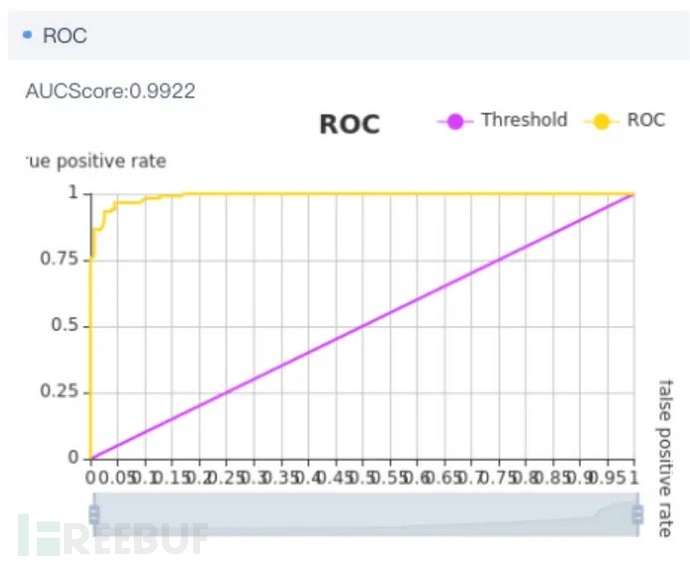
ROC曲线
其中,命中率即真正类率(true postive rate TPR),等同于召回率。TPR越大,预测正类中预测正确的比例越高;误判率即负正类率(false postive rate FPR)。FPR越小,误判率越低,预测正类中实际负类越小。在ROC曲线中,FPR作为横轴而TPR作为纵轴。
在ROC曲线图中的四个顶点有其特殊的含义。
第一个点,(0,1),即FPR=0,TPR=1,这是最完美的诊断,它将所有样本都正确分类。第二个点,(1,0),即FPR=1,TPR=0,最糟糕的分类器,它成功避开了所有正确答案。第三个点,(0,0),即FPR=TPR=0,即FP=TP=0,所有样本均被预测为假样本。第四个点,(1,1),所有的样本均被预测为真样本。
一个好的分类模型的ROC曲线应尽可能靠近点(0,1),为了精确地评价分类器的好坏,您可以参考AUC值。AUC值为ROC曲线下的面积,该值越大意味着当前模型准确率越高。从上图可以看到,黄色的线即ROC曲线。它与点(0,1)之间的距离非常近;AUC值为0.9922,接近1,可以看出训练出的模型效果很好。
在执行实验后,您训练完成的模型已经被导出,可以在模型界面查看该模型的详细信息。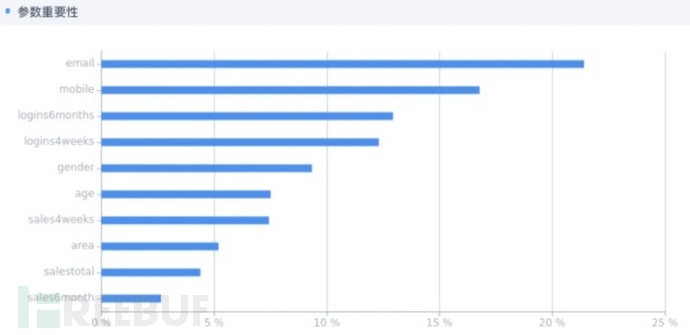
模型参数重要性
在详细信息中,我们可以看到该模型给出的参数重要性。可以看到在用户信息中,用户使用邮箱的评级与用户使用移动电话的频率都对用户的营销结果有着较大的影响;而用户6个月内的销售次数与用户总销售次数对结果的影响较小。
使用模型来预测结果
您已经得到了训练完成的模型,现在可以用它来预测营销方案对现在的用户是否产生效果。
新建一个新实验。点击左侧实验按钮进入实验页面,点击实验,新建空白实验。进入实验后在左侧是算子选择中点击数据集,点击数据样例,选择newcompaigndata。此部分与上一个实验操作基本相同,不再重复。
将newcompaigndata拖动至右侧工作区并预览数据: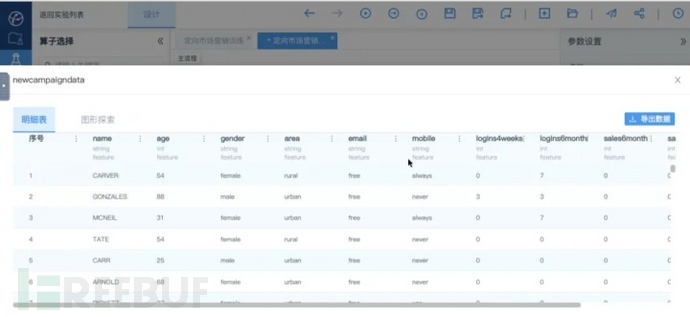
预览newcompaigndata数据
在左侧选择“预处理”>“字符串”>“字符串索引”算子并拖动至工作区,将数据源的output连接至“字符串索引”算子的input。
在左侧选择“预处理”>“元信息”>“设置角色”算子并拖动至工作区,将“字符串索引”算子的output连接至“设置角色”算子的input。
算子连接完成后如图所示:
预处理算子连接
点击选中“字符串索引”算子,在右侧设置参数。newcompaigndata没有“response”字段,选择属性时去除“response”,其余设置与上一个实验相同,不再重复。
点击选中“设置角色”算子,在右侧设置参数: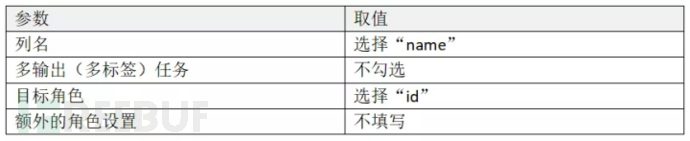
在左侧选择“模型”,选择之前导出的模型算子并拖动至工作区。
在左侧选择“验证与评估”中的“应用模型”算子并拖向右侧工作区,将模型算子的model连接至“应用模型”算子右侧的model。同时将“设置角色”算子的output连接至“应用模型”算子左侧的input。
算子连接完成后如图所示: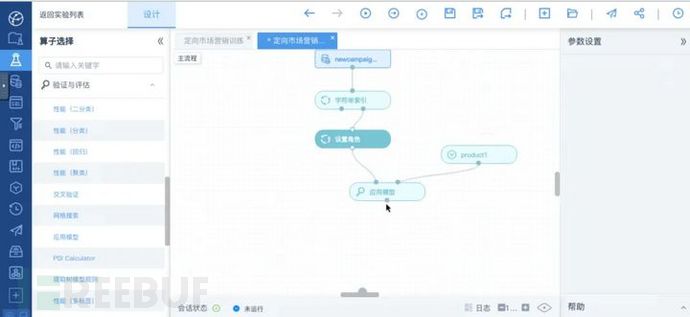
模型算子连接
模型服务部署
如果希望您训练出的模型可以投入使用,您可以选择部署您的模型服务。模型服务部署分为2个步骤,模型上架(模型管理)及模型上线(服务管理)。
在预测实验右上方点击模型上架按钮,会弹出“模型上架”对话框。
在第一步选择模型服务中填写参数: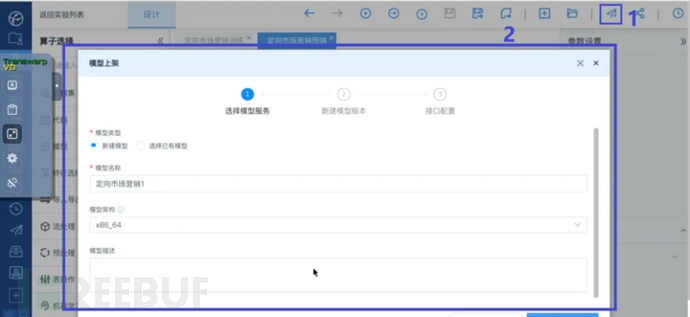
模型上架页面>选择模型服务
模型上架页面>选择模型服务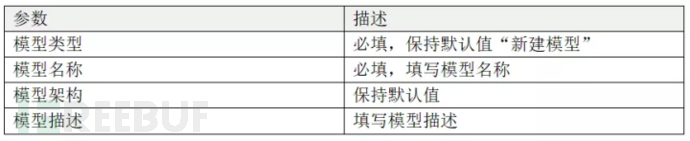
全部填写完成后点击“下一步”。在第二步新建模型版本中填写参数: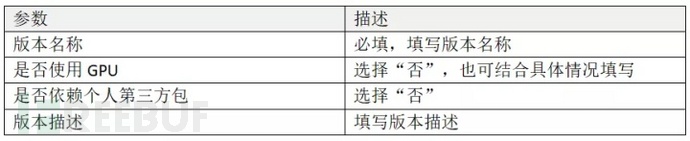
全部填写完成后点击“下一步”。
在第三步接口配置中填写参数。先在“给上架的模型设置输入”中勾选newcampagindata。之后勾选“基础数据数据集”右侧的“全选”。最后点击“上架”以上架模型: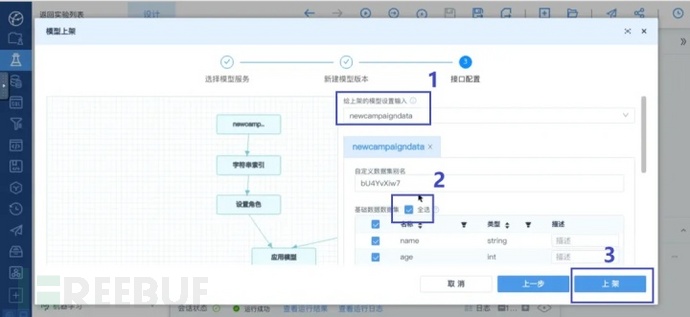
模型上架页面>接口配置
上架后点击左侧工具栏的“模型服务”按钮进入模型管理页面:
左侧工具栏的“模型服务”按钮
在模型管理页面找到刚才上架的模型,点击版本管理按钮进入版本管理页面: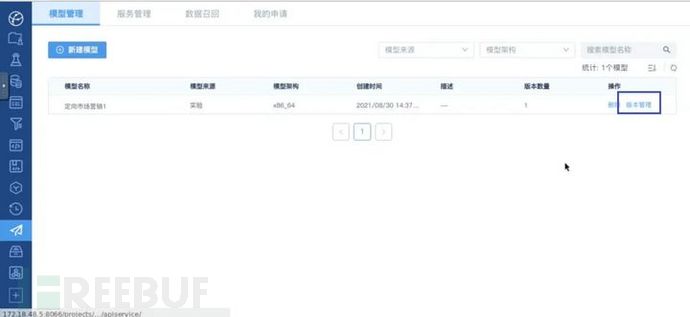
模型管理页面
在版本管理页面中,点击上线按钮进入上线模型服务页面: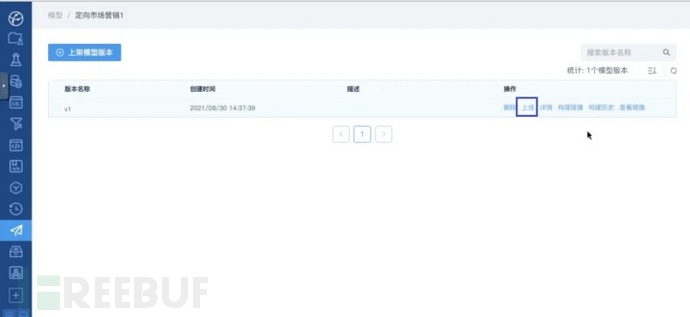
版本管理页面
在上线模型服务页面中设置参数:

参数设置完成后,点击上线按钮。
点击左侧工具栏的模型服务按钮进入模型服务界面,点击上方的服务管理按钮进入服务管理页面。在该页面可以看到刚刚上线的模型。
服务管理页面
可以点击测试连接按钮测试连接状态。如果API有返回代表连接成功,无返回代表连接失败。模型刚上线时会显示连接失败,请稍后再尝试测试连接。
小结
本文通过精准市场营销模型的训练、测试、预测、上线与实际应用为您展示了Sophon Base的使用流程。在Sophon Base的帮助下企业可以简单快速地训练出模型并得到模型的预测结果,根据预测结果,企业能够及时调整营销方案、筛选目标用户、辅助领导者进行决策。将模型上架后开发人员可以直接使用API对新用户进行筛选,最终实现企业对特定用户进行精准市场营销的目的。
如需授权、对文章有疑问或需删除稿件,请联系 FreeBuf 客服小蜜蜂(微信:freebee1024)






- 169 文章数
- 3 关注者