


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

数据安全怎么做:数据分类分级
 大超
大超- 关注
99+
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
数据安全怎么做:数据分类分级
 本文由
大超 创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
本文由
大超 创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
前言
近期国家出台了《中华人民共和国数据安全法》草案篇,其中,从国家法律层面强调对数据要进行分级分类保护,那到底如何进行数据的分级分类保护呢?
目前国家层面的文章除了在今年2月27日发布的《工业数据分类分级指南(试行)》,并无其他国家层面的指导文件,但是分级分类这个词对于所有做安全的同仁们并不陌生,国际上的ISO27001和NIST等规范皆有提及,国内的地方和行业上也有相应的指南发出,如贵州省的《政府数据 数据分类分级指南》、金融行业的《金融数据安全 数据安全分级指南(送审稿)》和《证券期货业数据分类分级指引》等。那落地到企业层面如何制定呢,今天跟大家分享下“数据分类分级”在企业中的实践。
下述内容,仅代表个人观点,仅供参考。
什么是数据分类分级
将它拆分成三部分进行理解。
数据:指任何以电子或者非电子形式对信息的记录。
数据分类:根据组织数据的属性或特征,将其按照一定的原则和方法进行区分和归类,并建立起一定的分类体系和排列顺序,以便更好地管理和使用组织数据的过程。
数据分级:按照一定的分级原则对分类后的组织数据进行定级,从而为组织数据的开放和共享安全策略制定提供支撑的过程。
数据分类分级的价值和意义
通过对数据的分类分级,识别数据对组织的具体价值,确定以何种适当的策略,保护数据的完整性、保密性和可用性。
例如,一般公司把数据分为绝密、机密、秘密和公开四种类型,很明显,超过公开级别的数据都是敏感数据,它们具有不同的价值,组织需要采取不同的额外投入和特定策略等来管理数据,规避因敏感信息的未经授权访问给组织造成重大损失的可能。
比如:绝密级数据必须使用AES256加密,访问和使用需数据安全治理小组审批方可使用;机密级数据必须使用AES256加密,访问和使用需要CTO审批;秘密级别数据必须使用AES256加密,访问和使用需部门负责人审批;公开数据使用可使用明文存储,访问和使用需直属领导审批即可。
落地实践
对于事件推动支撑层面,个人推崇“三分技术、七分管理、细节把控、管理先行”,而标准化的制度和流程是落实管理思维的关键工具和手段之一。
1、制定数据分类分级管理制度
将数据分类分级工作落实到组织管理制度中,形成标准化,明确以下内容:
1)制度目的、范围2)数据分类分级工作中涉及到的组织及职责3)数据分类分级工作的原则4)组织数据的具体分类概述将组织数据划分为三类:
- 用户数据类
- 业务数据类
- 公司数据类
5)组织数据的具体分级概述将组织数据分为五个级别:
- 绝密(G1)这是极度敏感的信息,如果受到破坏或泄漏,可能会使组织面临严重财务或法律风险,例如财务信息、系统或个人认证信息等。
- 机密(G2):这是高度敏感的信息,如果受到破坏或泄漏,可能会使组织面临财务或法律风险,例如xinyongka信息, PII或个人健康信息(PHI)或商业秘密等。
- 秘密(G3):受到破坏或泄漏的数据可能会对运营产生负面影响,例如与合作伙伴和供应商的合同,员工审查等。
- 内部公开(G4):非公共披露的信息,例如销售手册,组织结构图,员工信息等。
- 外部公开(5):可以自由公开披露的数据,例如市场营销材料,联系信息,价目表等。
6)各个级别组织数据的使用及防护原则7)各个级别组织数据的权限开通、提取等管理流程
不同级别的数据制定不同的数据访问权限或提取等管理审批流程
2、制定数据资产分类分级清单
抛砖引玉,分享一个分类分级思路:整体数据分类分为三大类数据,分别为用户数据类、业务数据类和公司数据类,三个一级数据分类又可以进一步细分到二级和三级数据,基于最细化的层级,给其定义相应的数据价值级别,进而汇总形成组织整体的数据分类分级清单,用以指导组织整体的数据治理和数据分类分级的实际工作。
1)数据分类
a)用户数据分类
用户数据即公民个人信息类,这类数据在全球已经有了比较清晰的规范要求和说明,这点可以参考相关标准进行制定分类。
- 国内数据可参考两个:
《网络安全法》中,公民个人信息,是指以电子或者其他方式记录的公民的姓名、出生日期、shenfenzheng号码、个人生物识别信息、职业、住址、电话号码等个人身份信息,以及其他能 够单独或者与其他信息结合能够识别公民个人身份的各种信息。《信息安全技术 个人信息安全规范》GB/T 35273—2020中如下清单:
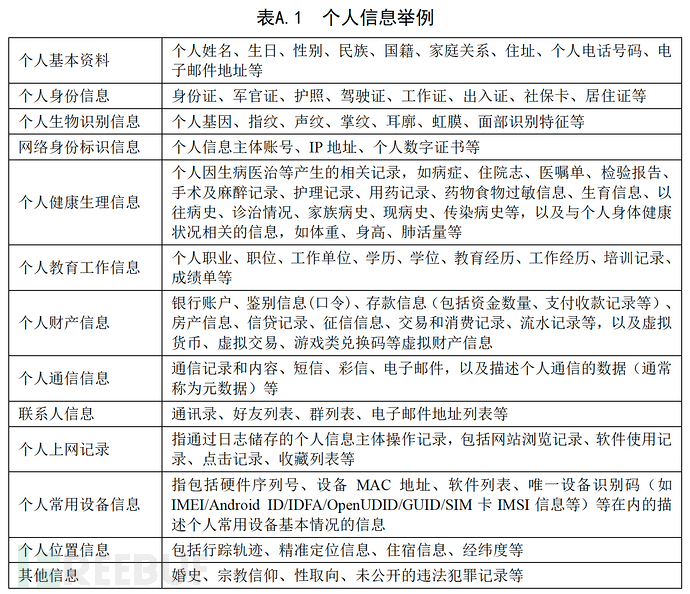
- 国外数据可参考两个:
NIST 800-122中对个人信息的定义:个人识别信息是“由代理机构维护的有关个人的任何信息,包括(1)任何可用于区分或追踪个人身份的信息,例如姓名,社会保险号,出生日期和地点,母亲的姓氏或生物特征记录; (2)与个人链接或可链接的任何其他信息,例如医学,教育,财务和就业信息。 PII的示例包括但不限于:名称,例如全名,娘家姓,母亲的娘家姓或别名;个人识别号,例如社会安全号(SSN),huzhao号,jiazhao号,纳税人识别号或金融帐户或xinyongka号;地址信息,例如街道地址或电子邮件地址;个人特征,包括照片图像(尤其是面部或其他识别特征),指纹,笔迹或其他生物特征数据(例如,视网膜扫描,语音签名,面部几何形状);与上述内容之一相关或可链接的个人信息(例如,出生日期,出生地点,种族,宗教,体重,活动,地理指标,就业信息,医疗信息,教育信息,财务信息)。GDPR中对个人数据的定义:“个人数据”是指与已识别或可识别的自然人(以下简称“数据主体”)有关的所有信息;可以将自然人视为可识别的人,可以直接或间接地对其进行识别,特别是通过分配给诸如姓名,识别号,位置数据,在线标识符或一个或多个表示身体的特殊特征的标识符,该自然人的生理,遗传,心理,经济,文化或社会身份;
b)业务数据分类
业务相关的数据,与组织的业务形态息息相关,比如:淘宝京东更多的是订单物流、商品详情数据等;爱奇艺优酷更多的是视频类数据等;除此之外,还有包含一些通用类数据,比如市场数据、业务分析数据等。可以找业务PO沟通了解,业务特性决定,不细写。
c)公司数据分类
公司数据主要包含人事数据、财务数据、法务数据、采购数据、日志数据、代码数据、制度数据等二级数据分类,二级数据可以分为两类,一类为通用数据类,如日志、制度等;一类为定制数据类,如人事、财务等。
每个二级类别数据细分不细写,举一个定制数据类制定例子,比如人事数据。
可以找人事系统的产品经理或研发获取系统的数据信息表,通过查看数据信息表可以清楚的看到人事系统会使用哪些数据,三级分类如公司、员工信息、部门、职位等。
样例如下,仅供参考:
| 数据分类 | 数据分级 | ||||||
| 一级分类 | 二级分类 | 三级分类 | G1 | G2 | G3 | G4 | G5 |
| 公司数据 | 人事数据 | 员工认证数据:账号密码、身份验证token | √ | ||||
| 员工个人隐私数据:shenfen证、手机号、yinhang卡号 | √ | ||||||
| 员工个人非隐私数据:入职日期、职级 | √ | ||||||
| 员工家庭数据:与员工关系、性别 | √ | ||||||
| 员工教育信息:学校名称、学位、毕业类型 | √ | ||||||
2)数据分级
数据也是对数据定性分析的过程,在为各类数据分配级别时,我们需要考虑以下问题:
数据泄漏或破坏相关的合规风险是什么?数据泄漏或破坏相关的组织经济风险是什么?数据泄漏或破坏相关的软件成本和硬件成本是什么?数据泄漏或破坏相关的组织品牌及舆论影响成本是什么?
示例:
将身份验证、组织财务报表等定义为G1级别将个人敏感信息等定义为G2级别将组织结构、个人一般信息等定义为G3级别将组织邮箱等定义为G4级别将组织对外公kai信息等定义为G5级别
3、制定数据使用规范
a)数据提取
关键点
- 区分范围:对内or对外使用
- 区分量级:提取数据量的多少
- 区分级别:数据的敏感级别
基于上述三个方面细化制定数据提取流程。
b)权限开通
基于库、表、字段的敏感级别,制定不同的权限审批流程,且基于最小化权限开通方式,理想状态基于字段开通,正常情况基于表进行开通,特殊情况基于库进行开通。举例如下,仅供参考:
- G1级别数据:需要部门负责人、数据归属团队、数据安全团队、内审、法务、数据安全治理小组审批方可开通
- G2级别数据:需要部门负责人、数据归属团队、数据安全团队、内审、法务审批方可开通
- G3级别数据:需要部门负责人、数据归属团队、数据安全团队审批,抄送内控和法务方可开通
- G4级别数据:需要部门负责人和数据归属团队审批方可开通
- G5级别数据:需要部门负责人审批方可开通
4、数据分类分级落地推广
1)制度发布
数据分类分级是数据治理工作的核心之一,制度需要至少经过公司技术委员会、数据治理小组、法务、内控、CTO等过会认可,然后通过内部平台、邮件、安全意识推广等多维度方式广而告之。
目的:从制度发起阶段就形成上到下的执行模式,从公司战略层引领执行层工作。
2)制度落地
数据治理相关策略落地,需要找准数据落点和出点。
举例:
公司生产核心数据在生产网的mysql库中,通过数据同步等方式给到大数据中心负责的hive,mysql作为组织的系统交互数据落点,hive作为数据访问、提取、分析等的起点。
基于现状,选择在hive层面落地数据分类分级工作,通过半自动化方式进行打标签。
实现逻辑:
基于hive建立一个数据层面的数据地图和权限申请审批系统,底层为mysql库。数据地图是数据层面的全景系统,可以查询数据库、表、字段的相关信息,并通过半自动化的方式对数据进行打标签工作,通用类字段以自动化方式打标签入库,非通用类字段以手动方式打标签入库。系统成熟后可实现自动化分类分级打标签工作。数据使用方可以基于数据地图上的库、表、字段和敏感级别信息进行数据访问权限申请,不同的级别数据权限走不同的数据申请流程。
除此之外,基于hive维护出来的敏感信息级别清单,可以反向推动生产mysql数据的治理工作,如敏感信息进行存储加密或脱敏、使用的脱敏等工作。
5、验证和评估
1)人工验证和评估
通过人工检查的方式,定期review数据打标签的正确性、敏感数据的存储使用状态等。
2)自动化验证和评估
基于数据分类分级清单和基于hive维护出来的敏感信息级别清单,制定敏感信息发现规则,主动识别静态数据和动态数据,自动发现和告警未按照策略要求防护的数据。(此处会在之后的数据识别章节详细介绍)
总结
数据分类分级是组织数据治理和数据安全的核心任务之一,是将信息安全性融入到数据价值中并确保有效保护的手段。
引用郭峰老师的一段话,对于数据安全从业者,你要多问自己下述问题:组织有多少数据,数据如何分布?什么是敏感数据,敏感数据在哪里?谁有权访问组织的数据?是否采取了适当的持续的防护、监控、告警等措施?这些问题都值得我们深思和解决,而今天聊的数据分类分级正是解决的第二个问题。
最后,感谢雪峰老师的悉心指导!
相关参考:
大超
安全是一种修行~
已在FreeBuf发表 13 篇文章
本文为 大超 独立观点,未经授权禁止转载。
如需授权、对文章有疑问或需删除稿件,请联系 FreeBuf 客服小蜜蜂(微信:freebee1024)
如需授权、对文章有疑问或需删除稿件,请联系 FreeBuf 客服小蜜蜂(微信:freebee1024)
被以下专辑收录,发现更多精彩内容
+ 收入我的专辑
+ 加入我的收藏
 大超的数据安全专栏
大超的数据安全专栏
 安全营养液
安全营养液
 自学
自学
 安全建设
安全建设
 企业运营安全
企业运营安全
 数据安全
数据安全
展开更多
相关推荐






大超 LV.4
安全是一种修行~
- 13 文章数
- 209 关注者
数据安全怎么做:跨境数据的思考
2021-05-07
数据安全怎么做:静态敏感数据治理
2020-12-09
数据安全怎么做:个人信息保护法解读
2020-11-01
文章目录