


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

- 关注
一、 背景
随着信息化进入3.0阶段,越来越呈现出万物数字化、万物互联化,基于海量数据进行深度学习和数据挖掘的智能化特征。数据安全正式站在了时代的聚光灯下,隆重登场。计算机行业的安全是一个由来已久概念,我们比较认可雷万云博士对于信息安全发展阶段的划分,认为截止到目前,信息安全大致经历了5个时期。
第一个时期是通信安全时期,其主要标志是1949年香农发表的《保密通信的信息理论》。在这个时期主要为了应对频谱信道共用,解决通信安全的保密问题。
第二个时期为计算机安全时期,以二十世纪70-80年代为标志《可信计算机评估准则》(TCSEC)。在这个时期主要是为了应对计算资源稀缺,解决计算机内存储数据的保密性、完整性和可用性问题。
第三个时期是在二十世纪90年代兴起的网络安全时期,在这个时期主要为了应对网络传输资源稀缺,解决网络传输安全的问题。
第四个时代是信息安全时代,其主要标志是《信息保障技术框架》(IATF)。在这个时期主要为了应对信息资源稀缺,解决信息安全的问题。在这个阶段首次提出了信息安全保障框架的概念,将针对OSI某一层或几层的安全问题,转变为整体和深度防御的理念,信息安全阶段也转化为从整体角度考虑其体系建设的信息安全保障时代。
信息是有价值的数据,随着海量、异构、实时、低价值的数据从世界的各个角落,各个方位扑面而来,人类被这股强大的数据洪流迅速的裹挟进入了第五个时期,也就是目前所处的数据安全时代。
二、 大数据安全的矛盾和目标
在大数据时代,安全面临着如下矛盾亟待解决:
1、数据的收集方式的多样性、普遍性和技术应用的便捷性同传统的基于边界的防护措施之间的矛盾;
2、数据源之间、分布式节点之间甚至大数据相关组件之间的海量、多样的数据传输和东西向数据传输的监控同传统的传输信道管理和南北向数据传输监控之间的矛盾;
3、数据的分布式、按需存储的需求同传统安全措施部署滞后之间的矛盾;
4、数据融合、共享、多样场景使用的趋势和需求同安全合规相对封闭的管理要求之间的矛盾;
5、数据成果展示的需要同隐蔽安全问题发现之间的矛盾。因此,大数据的安全防护不仅要基于传统的OSI整体防御体系,还要打造基于数据生命周期安全防护策略。
数据安全防护工作的目标会根据安全责任主体不同导致侧重点有所差异,但大致可以分为三个层次:
1、涉及国家利益、公共安全、军工科研生产等数据,会对国计民生造成重大影响的国家级数据,这类数据需要强化国家的掌控能力,严防数据的泄露和恶意使用。
2、涉及行业和企业商业秘密、经营安全的数据,必须保障数据机密性、完整性、可用性和不可抵赖性。
3、涉及用户个人和隐私的数据,在用户知情同意和确保自身安全的前提下,保障信息主体对个人信息的控制权利,维护公民个人合法权益。
三、 数据全生命周期安全管理
数据全生命周期安全这个概念颇具争议,有人认为很多公司都是先有业务后有安全,安全部门面对的是海量的存量数据,日均增长上百张的数据表,利用数据、使用数据人员基数不断膨胀而且流动变化巨大,老板承担巨大的社会和经济方面的压力亟需安全部门做出成绩的急迫心情,这种情况下如何实现数据分类分级?
首先,要对数据进行分类分级的前提是良好的数据治理效果。我们当时面对的挑战是整合了全国31个省、340+市公司的各种数据,数据部门的小伙伴花费了整整一年的时间梳理清楚4门28类数据,实现了日均接入数据超过400T,数据质量高达80%以上的数据治理目标,形成“七步走”的数据治理方法和数据质量评价体系,为数据分类分级和数据安全防护奠定了坚实基础。
其次,面对数以千计的数据访问人员,访问近7000台服务器的庞大集群,平台部门也是花费了1年时间将平台集群划分为数据接入区、开发测试区、核心生产区和DMZ区,将数据访问人员按照不同的职能权限限定在相应的区域,初步建立了平台的访问控制机制,为数据安全的管控提供了关键一环。
我们的数据安全是建立在各部门辛苦工作的基础之上,从实践的经验来看,围绕数据生命周期建立数据安全体系是完全可行的。
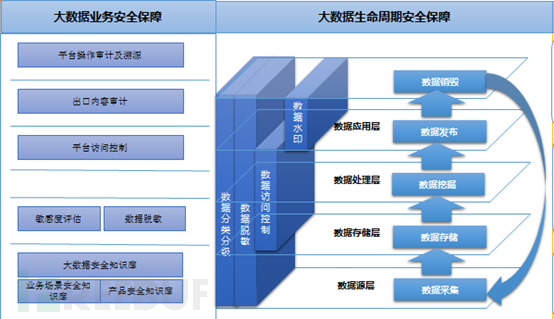
四、 数据产生/采集环节的安全技术措施
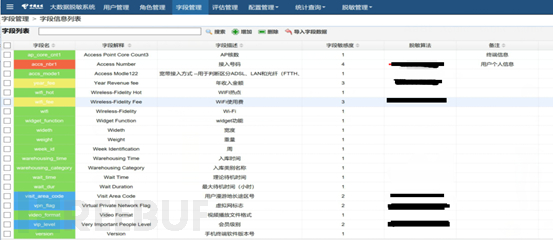
1、数据分类分级系统
元数据的分类分级管理在大数据环境下要依靠自动化手段来保障效率,由于数据表的新增和变更的速度过快,对每个表进行分类分级的方式是无法实现的,我们采用的是对字段进行敏感的评级的方式,根据元数据的分类分级的敏感的等级和可能的应用场景制定不同的脱敏策略。
2、信道加密技术
数据传输环节主要通过信道加密技术保障数据保密性,可以通过HTTPS、VPN 等技术建立加密传输链路,这项技术比较成熟,就不在这里展开了。
五、 数据存储环节的安全技术措施
1、数据脱敏系统
对于敏感度高、价值高的数据进行脱敏是数据存储和使用前提条件,数据脱敏后会和原始数据形成算法、密钥或对照表的映射关系,只要同时获取脱敏数据和映射关系后才能正确得到真实数据,可以提升数据窃取的机会成本。
提到脱敏就不得不提到数据tokenization(令牌化)和MASK概念了,tokenization的思路是对数据使用某种算法的混淆,比如对于某个手机号码13300000000,混淆后可能会把该号码变成18910001234,保持了号码某些属性的一致或可用,但这种方法只能适用少量数据的开发和测试环境下,无法避免大量数据的重复攻击和比对攻击,在真实使用的案例中要严格数据的应用范围。
而MASK的方式就是遮挡,比如上面的手机号码13300000000遮挡后可能变成133****0000,将归属地的信息隐藏,这种方式在数据可视化环境中已经大范围使用,在大数据环境中存在关联其他信息和猜解攻击的风险。
同样,对数据进行全盘加密的方式也是不可取的,Hadoop生产集群通常都有上千个节点,集群间、组件间频繁进行加密和解密操作计算和性能开销是无法支撑业务的发展的。对部分数据字段的脱敏既可以有效降低数据操作开销,也可以将业务必须的字段按需保留下来,实现《网络安全法》要求的无法还原成特定个人的合规要求。
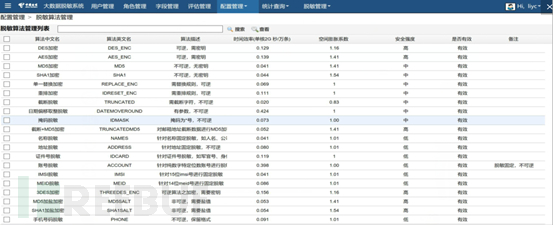
2、eUID编码技术
随着手机实名制的推广,手机号与个人用户信息的弱关联程度越来越高,手机号在一定程度可以作为某些场景下的个人标识,而且各个种类的数据也需要有主键将其关联起来。我们设计了eUID(esurfing Unique Identifier)天翼唯一标识, eUID作为各表和真实数据同脱敏数据之间的“转接桥梁”,在开发和使用过程中使用脱敏后的数据,降低数据肩窥风险。同时也首次实现跨行业不同用户ID的匹配互通模型和基于布隆过滤器(Bloom filter)的数据交换方案,其空间效率和查询时间都远远超过业界普遍的算法而且误识别率低。
3、数据安全域
数据安全域是采用传统的分域隔离的概念解决虚拟化环境下东西向流量管控的问题,该内容偏重于管理层面,也是由无序到有序的过程,就不在这里展开了。
六、 数据处理环节的安全技术措施
1、平台操作审计系统
大数据平台内,不同部门不同权限不同身份的操作者遵循不同策略访问不同资源、组件和设备,产生大量操作行为,产生算法复杂度至少是Ο(n3)的关系网络,节点数量越大,每增加一个节点的,这个关系网络的复杂度要从Ο(n3)转变为Ο(n3 +n),这个数量有可能趋向于天量。所幸的是,我们做了良好的分域、分角色的管理,不会出现某个角色访问所有节点的情况,可以将关系复杂度由Ο(n3)降低到Ο(m*n2),其中这个m是个常量。因此,对于平台的操作审计是可行的。
平台操作审计系统收集角色在hadoop组件(如HDFS、Hive、Hbase)和虚拟机、宿主机上的操作日志,使用身份关联模型将不能直接进行角色判定的两个标识操作,通过比较与两个标识有直接或间接关联的若干个标识,综合评价后进行的关联。如判断两个不同体系的账户的某一次操作是否是同一个人,需要通过对用户账户的分析、行为操作、访问终端等方式进行综合分析评定。根据角色的权限和访问策略,使用K-means算法和UEBA(用户与实体行为分析)技术分析和建立角色行为基线,并对角色日常操作进行自动化的操作审计及判断,发现异常或敏感操作,并实现准实时告警功能,在机器学习的驱动下,或许会带来新的惊喜。
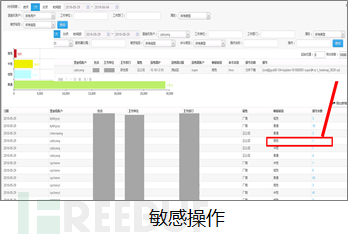
2、数据访问控制体系
Hadoop平台采用了SASL的认证机制,提供了Anonymous(无须认证)、Plain(采用base64位加密明文传输,没有用到加密算法)、Digest-Md5(采用基于MD5提供的安全服务)和Kerberos认证方法。无论是Apache体系的ranger、knox组件还是CDH的sentry组件,都以Kerberos为基础。目前各种安全组件都存在一定适配性问题,如sentry目前只支持HDFS、HIVE等少数几种组件,ranger需要对Hadoop的版本有一定要求等问题。同时,动态的访问需求也给运维小伙伴带来极大的困扰,因此在实际的工作中,我们只是小规模的试用。
七、 数据应用环节的安全技术措施
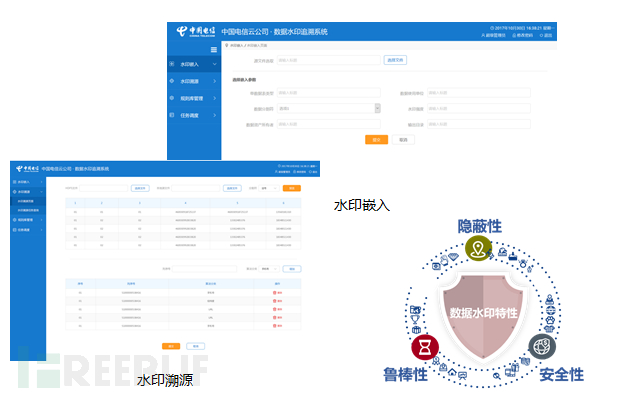
1、数据水印系统
大数据环境下,数据以多种样式存放,数据一旦泄露如何定位溯源是一个难题,传统的在图片放置明暗水印的方式是无法应对文本格式的溯源需求的。我们设计开发数据水印算法,在日常的业务数据中通过算法编码生成和插入伪数据记录,这些伪数据记录符合该类数据相关字段属性,如数字、价格、姓名或邮箱地址等,形成数据水印。将数据水印采用均匀分布的方式自动化地插入对应数据集合中,以实现数据所有者标记,保障数据所有者权益,同时追踪数据滥用情况,确保了数据发布和销毁阶段及数据泄露后的回溯分析需求,该技术于2015年申请国家发明专利。
2、出口审计系统
电信通过BDCSC(bigdata customer service center)平台为2B用户提供4+1的产品服务,为确保输出接口符合规范和不包含敏感数据,我们设计并实现了出口审计系统,该系统可以对接口输出数据进行自动解密、模式匹配、异常发现等功能,能够及时发现出口数据的泄露风险。
八、 数据销毁环节的安全技术措施和其他技术
1、数据销毁
在数据销毁环节,安全目标是有两个,一是《网络安全法》要求数据可删除权,二是数据在物理层面的永久删除、不可恢复。在技术层面上有比较成熟的技术,这里就不展开了。
2、数据陷阱技术
特意提一下这个技术是因为偶尔听说有厂家正在大范围使用,该技术的原理是指制作一个数据钩子,将钩子埋置在数据集合中,如果有人触碰了该集合,便捕获访问者操作和其他攻击行为,很有趣的一种思路。
3、数据地图
对于安全、数据、运维部门来说,十分渴望了解数据都分布在平台的哪些角落,哪些是高敏感数据资产,数据被哪些人使用,这些人拥有的权限是什么,数据的传递路径是什么,数据表的继承和血缘关系是什么,因此,如何拼接成一个可视化的数据地图,根据地图进行相应的干预和操作应该会成为一个巨大需求。
4、ObserveIT系统
ObserveIT是一款优秀的操作审计系统,能够将Linux和windows的操作以文本的方式记录下来,以视频的方式展示出来,甚至可以还原windows环境下快捷键操作,审计人员可以通过设置操作规则和检索关键字的方式发现异常、高危操作。
5、其他的其他
分布式环境下的数据完整性验证、数据标签、区块链、细粒度访问控制、数据溯源等技术。同时,使用大数据安全技术来进行网络安全入侵检测、安全态势感知、网络攻击取证、威胁情报分析等安全应用研发也是今后需要研究的重点。
九、 小结
大数据时代,使得安全的重心终于回到安全的本质:数据的安全问题上。数据流如水流,无法阻挡且无处不在,在新的挑战面前,以边界防御为主的铁布衫方式越来越显得力不从心,只有内外兼修、苦练内功、在技术、法规和管理方面共同发力方可守卫数据的安全。
*本文作者:smoonsoso,转载请注明来自FreeBuf.COM
- 0 文章数
- 0 关注者