


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
写在前面的话
在这篇文章中,我将讨论如何使用tshark显示特定的字段。并且我还将深入探讨如何提取和操纵这些字段。我们就从下面的图片开始吧! 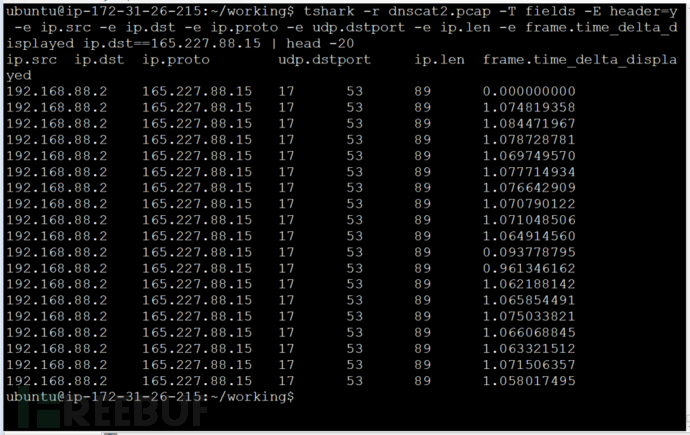
用Tshark读取文件
默认情况下,tshark将侦听本地接口,并从线路上抓取数据包。如果您有要处理的pcap文件,则可以使用“-r”命令。也可以通过“head”(仅显示指定数量的输出行)或“less”(一次显示一整页输出)来输出到屏幕上,例如:tshark -r interesting-packets.pcap | head默认情况下,“head”只会显示前10行,但您可以根据需要对其进行修改,例如上图我使用“head -20”查看前20行。
使用Tshark过滤流量
当我们在查看一个pcap文件时,通常我们会寻找某些特定特征。例如,我们需要查找与某些IP地址或服务相关的所有流量。我们可以使用捕获过滤器。但如果我们使用Wireshark,Wireshark捕获过滤器与tshark的工作方式略有不同。Tshark实际上使用Wireshark Display Filter语法进行捕获和显示。这非常酷,因为它提供了更多功能。tshark捕获过滤器的语法是:<field><operator><value>举个栗子:
ip.dst==192.168.1.10
ip.proto==17
tcp.flags.reset!=0
请注意,在第二个栗子中,我使用协议号(17)而不是协议名称(UDP)。这对于大多数过滤器来说都很常见。使用上面引用的Wireshark Display Filter语法页面来确定要使用的正确格式。在前两个示例中,我使用运算符“==”来匹配。请注意,在最后一个示例中,我使用“!=”表示不等于。您还可以使用大于(>>),小于(<<),等于或大于(> =)或小于或等于(<=)。这个学过编程应该都明白。但有一点,在最后一个示例中,我匹配单个位(TCP头的字节13中的复位位)。这意味着我需要确定我是否对正在打开的位(由“1”表示)或关闭(由“0”表示)。因此,最后一个示例的另一种方式是:tcp.flags.reset == 1如果你对与特定IP地址相关的流量感兴趣,我可以在上面的“-r”命令上加上一些东西:tshark -r interesting-packets.pcap ip.dst==192.168.1.10 | head
将Tshark重定向到新文件
有时,我们需要将现有的pcap文件重定向到新文件。例如,如果我想获取与特定IP地址关联的所有流量并将其放在不同的文件中以进行进一步分析,该怎么办?这时我要查看这个新文件,并进一步优化我的过滤。我们可以使用“-w”来创建一个新的文件。同样举个栗子:tshark -r interesting-packets.pcap -w interesting-host.pcap ip.dst==192.168.1.10 | head
选择Tshark输出哪些字段
默认情况下,tshark将输出每个数据包的简短摘要,这其中包括各种字段。还是一个栗子: 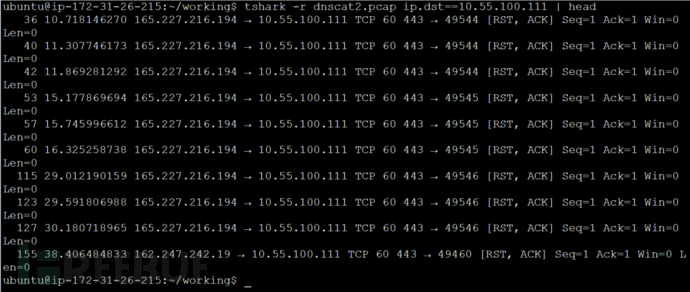 虽然这在执行快速解码时很方便,但如果我们希望查看的信息不在默认输出中呢?如果我们只想看到一个或两个字段而不是其他所有字段怎么办?幸运的是,tshark可以让我们指定我们希望看到的确切字段。使用命令
虽然这在执行快速解码时很方便,但如果我们希望查看的信息不在默认输出中呢?如果我们只想看到一个或两个字段而不是其他所有字段怎么办?幸运的是,tshark可以让我们指定我们希望看到的确切字段。使用命令“-T fields”来标识我们希望指定要查看的确切字段,而不是显示默认信息。然后可以使用“-e”来标识要打印的特定字段。我用“-e”的值是我之前提到的Wireshark显示过滤器。下面一个只打印源和目标IP地址的栗子:tshark -r interesting-host.pcap -T fields -e ip.src -e ip.dst ip.dst==192.168.1.10 | head这将产生类似于以下的输出: 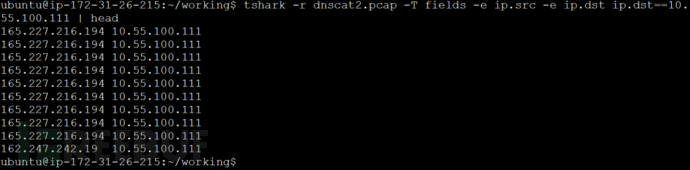 如果我想要把它组织起来,我可以添加
如果我想要把它组织起来,我可以添加“-E header = y”开关,如最最最上面的那张图所示。这将打印出第一行列标题。虽然如果您要将数据导入电子表格,这会超级好用,但如果您要用命令行操作数据,我建议不要这样做。这是因为列标题可能与数据混合在一起。
Tshark进行额外处理
假设我们想从包中提取某些字段,并将它们移动到一个文件中进行进一步处理。我们应该做的第一件事是输出感兴趣的字段,但使用一致的分隔符,以便更容易地将值传递给其他工具。为此,我们将使用“separator”开关并将其设置为使用逗号。下面还是一个栗子:
tshark -r interesting-host.pcap -T fields -E separator=, -e ip.src -e
ip.dst ip.dst==192.168.1.10 | head
这将提供与上一个示例类似的输出,但输出值之间使用逗号而不是空格。最后,我们应该将输出重定向到文本文件,而不是输到屏幕上。通过这种方式,我们可以将该文件提供给其他工具进行处理。这里有一个例子:
tshark -r interesting-host.pcap -T fields -E separator=, -e
ip.src -e ip.dst ip.dst==192.168.1.10 > analyze.txt
这将生成一个文本文件,其中每行包含从单个数据包中提取的信息。该行将包含以逗号分隔的源和目标IP地址。
Tshark输出
我应该使用哪些工具来操纵数据取决于我想要什么样的数据。Linux有各种各样的文本处理工具,如cut,sort,uniq和grep。通过谷歌搜索,您可以找到大量有关使用这些工具的文章。但在这篇博客文章,我想介绍“R”命令,因为它支持我们进行一些统计分析。这是我用来生成类似于最最最上面的图的数据输出的命令,但在格式中,我可以用于信标分析:
tshark -r interesting.pcap -T fields -E separator=, -e ip.src -e ip.dst -e
ip.proto -e udp.dstport -e ip.len -e
frame.time_delta_displayed ip.dst==165.227.88.15 and udp.dstport==53 > analyze.txt
这产生了一个名为“analyze.txt”的文件,其中包含类似于以下内容的数据:
192.168.88.2,165.227.88.15,17,53,89,1.073288580
192.168.88.2,165.227.88.15,17,53,89,1.067193833
192.168.88.2,165.227.88.15,17,53,89,1.057524219
192.168.88.2,165.227 .88.15,17,53,89,1.085981806
192.168.88.2,165.227.88.15,17,53,89,1.072384382
接下来,我将使用“cut”来提取我感兴趣分析的数据列,然后使用R来确定数据集的最小值,最大值,平均值,标准差和方差:
cut -d ',' -f 5 analyze.txt | Rscript -e 'y <-scan("stdin", quiet=TRUE)'
-e 'cat(min(y), max(y), mean(y), sd(y), var(y), sep="\n")'
89
290
95.74
33.82236
1143.952
在上面的例子中,“cut”提取了5列,它是在每个会话中传输的数据量。然后它将这些值传递给“R”,它计算该数据集的最小值,最大值,平均值,标准偏差和方差。请注意,我的标准偏差远大于平均值和最小值之间的差异。这表示,我的大多数会话都接近最小89字节大小。这有点令人感兴趣,因为它表明这两个系统之间交换的大部分流量都涉及少量数据的会话。但并不是决定性的。我可以对会话时间进行类似的分析:
cut -d ',' -f 6 analyze.txt | Rscript -e 'y <-scan("stdin", quiet=TRUE)'
-e 'cat(min(y), max(y), mean(y), sd(y), var(y), sep="\n")'
0
2.088164
0.9999386
0.2973222
0.08840052
这是非常有趣的地方。请注意,会话之间的最大差距只有两秒多一点。这非常频繁。另请注意,与均值的方差仅为.08840052秒或约88毫秒。这告诉我们绝大多数的通信会话几乎完全相同。
最后的话
数据包分析有一个问题就是如何寻找到有用的数据位并忽略其他所有内容。但对于大多数数据包解码器中都有默认视图,但这也有不好的方面,因为您要么获得太多信息,要么信息不足。此外,虽然图形分析工具易于使用,但却难以利用其他工具或自动化分析。通过利用tshark输出特定字段的能力,您可以根据需要操作数据以执行深入分析。
*参考来源:activecountermeasures,由周大涛编译,转载请注明来自FreeBuf.COM
如需授权、对文章有疑问或需删除稿件,请联系 FreeBuf 客服小蜜蜂(微信:freebee1024)
 流量
流量






- 95 文章数
- 81 关注者