


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

- 关注
 本文由
创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
本文由
创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
*本文原创作者:0xExploit,属于FreeBuf原创奖励计划,禁止转载
1.概况
最近经常需要分析WEB访问日志,从中发现非法请求,然后做相应安全检查,为了方便,所以写了一个日志分析平台,支持提交iis,apapche,tomcat,ngnix等日志格式,代码使用python语言。
另外,文章中所有的截图、日志都是使用工具扫描自己搭建的环境产生的日志,不涉及到任何用户。
2.架构
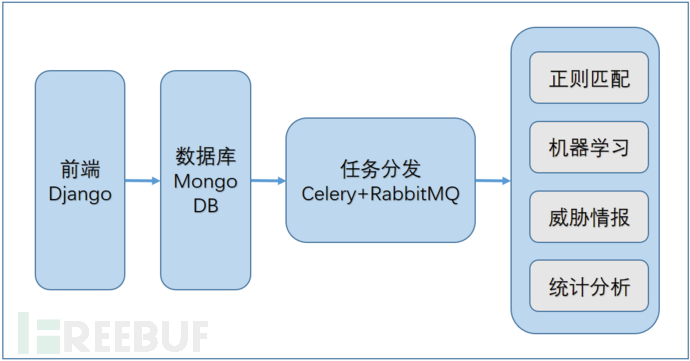
3.分析
3.1导入数据
这里并没有使用splunk之类的平台,而是根据日志的格式进行数据分割,然后存储到MongoDB中,比如apache的格式类似于
%h %l %u %t \"%r\" %>s %bweb访问日志的格式,类似于
1.1.1.1 - - [28/Oct/2017:01:58:11 +0800] "POST /admin/ HTTP/1.1" 200 14657这里需要注意的是,如果直接使用split按照空格分割的话,会存在一些问题,比如日志中的时间([28/Oct/2017:01:58:11 +0800])中间也是存在空格的,可以用DictReader定义quotechar读取数据。
下图是我定义的日志格式,包含了常用的参数
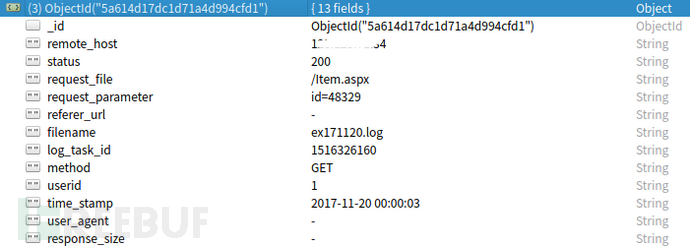
常规的WEB访问日志是没有POST日志的,所以能分析的内容都是基于GET参数、请求路径等,但是有些WAF日志是记录了所有的请求内容,可以用来丰富。
下面分别介绍下可以使用的功能
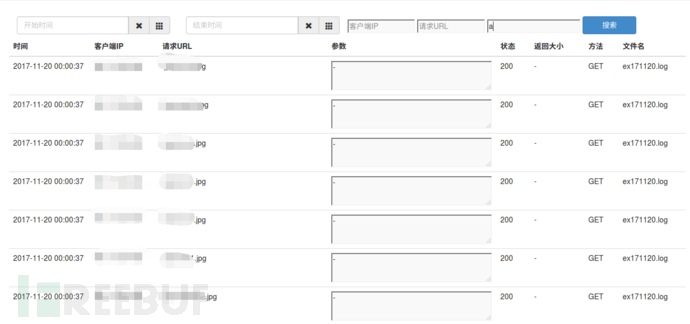
3.2数据查询
数据查询是最基础的功能,可以根据时间,ip等查询,这样就可以定义某个IP所有的行为,或者夜间某个时间点的访问日志
3.2正则匹配
正则匹配可能是WAF经常使用的规则,分析WEB访问日志时,也经常会用到,例如可执行脚本在上传目录下(例如/images/cmd.aspx),那么这个文件就很有可能是webshell,常规的还有attachments|images|css|uploadfiles等,还有一些解析漏洞的格式都可以用来匹配。

针对敏感文件/目录的扫描则是判断文件的后缀、路径等,例如rar,bak,swp等
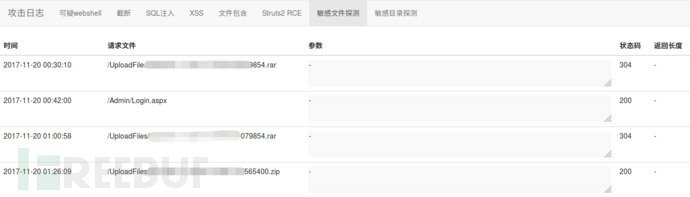
对于SQL注入、XSS等漏洞则是针对参数进行匹配,但是如果规则不够研究,可能会存在多个误报问题。
3.3机器学习
上面讲到,如果用正则匹配,那么会存在很多误报问题,所以我只定义了一部分严格的规则,保证匹配出来的一定是攻击的日志。对于其他的行为,则采用了机器学习模型机进行分类。
使用机器学习分类的重点和难点在于日志的收集和特征的选择;俗话说的好,正常总是基本相似,异常却各有各的异常,所以这里面的重点又到了异常日志的收集。
我从两个方面找了异常日志:
1.使用扫描器的模块扫描网站,比如使用SQLMAP扫描注入页面,那么WEB日志大多数都是SQL注入;或者使用WVS的XSS模块扫描页面,那日志里就有很多XSS的日志。
2.从GITHUB上搜索了很多个常用的poc和exp,然后进行分类。
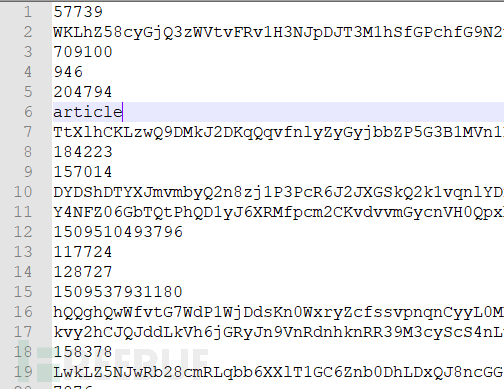
这里我用脚本将访问日志的路径都删除,只保留了参数的值,正常日志如下图:
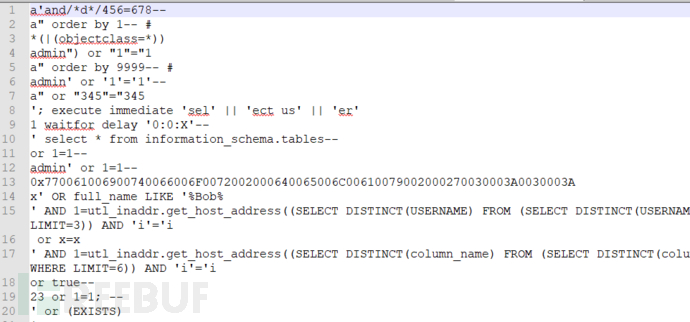
sql注入和xss的日志如下:
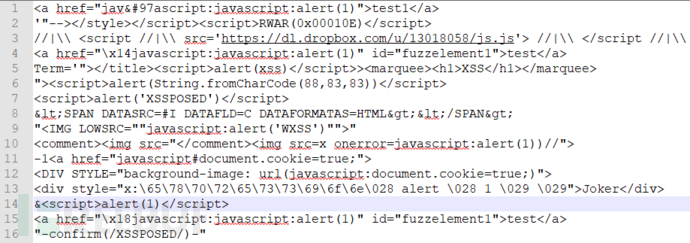
当然还有很多其他类型的日志,大家可以收集一下
使用TfidfVectorizer进行文本特征提取
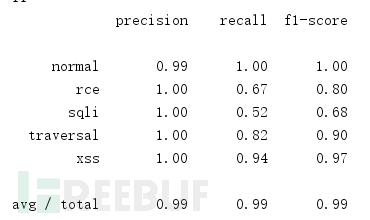
TfidfVectorizer(ngram_range=(2,2))然后用随机森林算法进行训练,准确率、召回率、F1参数
由于是第一个版本,所有还没有做过多的特征筛选和算法选择,后期慢慢改善算法。

3.4威胁情报
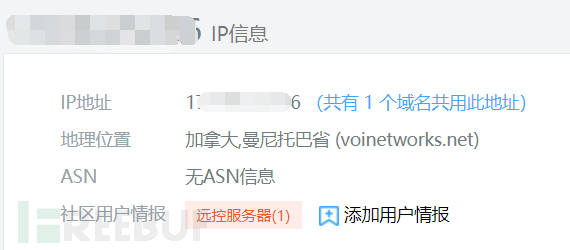
针对威胁情报,在日志分析中,主要用来分析IP,如果某个IP在一段时间内发生过情报,比如出现“远控服务器”,那么这个IP就应该被列为威胁IP,它的所有访问日志都应该被重点关注。所以把访问日志中所有的IP进行匹配一次,查看是否有恶意访问的信息
3.5统计分析
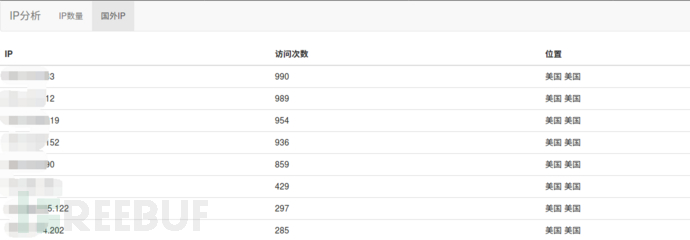
统计分析中主要是对IP和页面进行统计分析,比如一般的黑客访问都是用国外的代理IP访问,所以将国外的IP筛选出来,定位分析是否存在安全风险。
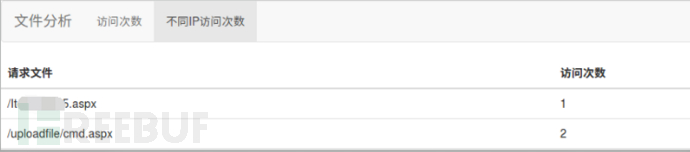
另外,针对webshell的访问,比较明显的特征是:由于webshell是孤岛存在,所以基本会被很少的IP访问,那么我们将某个页面被多少个IP访问过统计出来,数量少的可以着重分析。
4.总结
1.本文只是将WEB日志分析中常用的检查方法用python实现出来,但是仍然有很多不足,并且还有一些功能还没实现。
2.由于没有POST数据,所以分析存在很多局限性。
3.可以用机器学习的其他模型来尝试解决该问题。
4.欢迎大家指正,或者提供一些自己平时用到的分析方法,感谢感谢。
*本文原创作者:0xExploit,属于FreeBuf原创奖励计划,禁止转载
已在FreeBuf发表 0 篇文章
- 0 文章数
- 0 关注者