


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

- 关注
 本文由
创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
本文由
创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
*本文作者:倚剑醉酒笑红尘,属于FreeBuf原创奖励计划,未经许可禁止转载
前言
日志分析在入侵检测中的应用越来越广泛,合适的使用日志,使日志产生巨大的价值,本文旨在探讨如何让日志的价值在安全领域发挥作用。
安全日志分析的目的意义
1.通过对企业内部的各项数据进行汇总关联分析,如防火墙、安全设备、WAF、HIDS等产生的攻击日志,关联killchain的上下文信息,感知可能正在发生的攻击,从而规避存在的安全风险;
2.安全检测:从不同角度维度检测系统内部的安全风险;
3.应急响应:从日志中还原攻击者的攻击路径,从而挽回已经造成的损失;
4.溯源分析:回溯攻击入口与方式;
5.安全趋势:从较大的角度观察攻击者更“关心”哪些系统;
6.安全漏洞:发现已知或未知攻击方法,从日志中发现应用0day、Nday;
数据安全分析图
要做数据安全分析,数据收集是基础,数据收集之后,就要对数据进行治理,数据治理的意义就是服务于数据分析阶段,而数据分析的源头在于收集了哪些数据。因此在数据分析过程中,这三个阶段是循环的过程。好比买菜、洗菜、炒菜。买菜的过程就是数据收集的过程,洗菜就是数据治理的过程,炒菜就是数据分析的过程。要做成什么菜,就需要买相应的食材,你要我用web日志分析勒索攻击,这......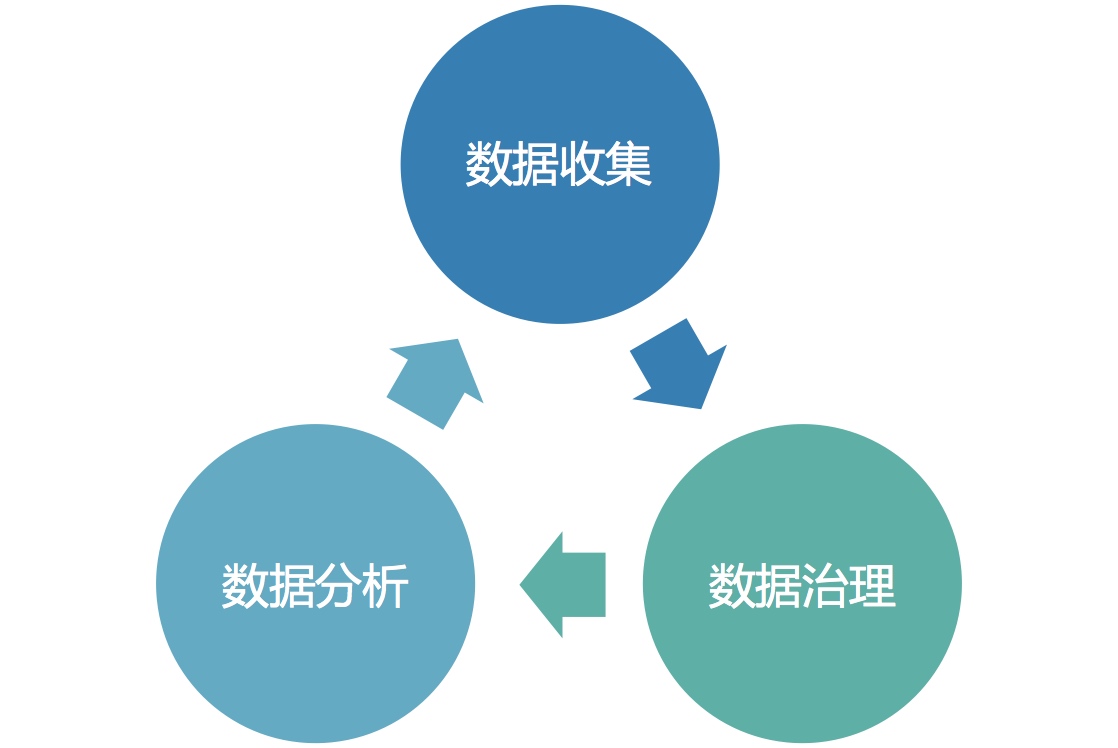
一、数据收集
基本上任何有关数据的工作第一步都是数据的收集,所以我们先买菜吧!通过爬虫也好,通过日志也好、通过旁路流量也好,都可以收集数据。数据收集阶段是数据治理阶段和数据分析阶段的基础。(买菜是洗菜和做菜的基础。)
在数据收集阶段,我们要从数据分析的角度去思考,我们在做安全分析的时候,我们需要哪些数据,由此产生以下4问。
1.What 收集哪些数据
2.Where 数据在哪
3.How 如何去收集
4.All 数据接完了吗
1.1 What:收集哪些?
下面简单列出一些收集的日志,重点在于,收集的对象,它能产出哪些日志?
1.1.1 服务器日志服务器日志包括系统运行,账户认证,命令操作,系统运行等等日志。
1.1.2 流量检测日志流量检测设备通过旁路的方式分析全网流量,包括DNS请求,SMTP发送日志。
1.1.3 设备日志设备的种类很多,每一种设备都有自己检测的日志
网络设备:VPN,负载,代理服务器,路由,交换
安全设备:FW,IDS,IPS,AV,UTM,WAF,APT,抗DDoS
审计设备:数据库审计,上网行为,运维安全审计,内网审计系统
PC终端:杀毒软件
1.1.4 应用日志:Nginx,Tomcat,Jboss,Apache,Tuxedo,WebLogic
1.1.5 数据库日志:DB2,MySQL日志,Oracle日志,SQLserver
1.1.6 应用系统日志认证系统:堡垒机,电子签章,CA认证,身份服务引擎,无线网络控制
管理系统:数据库管理系统,数据交换系统
1.1.7 业务日志
1.1.8 ......
确定了收集哪些方面的数据后,然后就需要了解这些服务器设备有哪些日志,在数据安全分析时需要服务器及安全设备的哪些日志。
Linux系统日志介绍:
https://blog.csdn.net/leizi191110211/article/details/51580828
Windows事件日志介绍:
http://www.freebuf.com/vuls/175560.html
https://blog.csdn.net/coolhayy/article/details/1153298
https://blog.csdn.net/dongdongzzcs/article/details/7226364
FTP日志介绍:
Web日志介绍:
服务器上的日志可以参考链接去了解,具体设备的日志不便公开。
安全设备的日志需要注意,比如WAF、APT,在默认规则检测日志基础上,自定义策略的日志也尤为重要,尤其是在业务合规,弱口令检测等方面的策略日志。
1.2 Where 数据在哪?
个人觉得在寻找日志的过程中,应该进行望闻问切。
1.2.1 架构(wang)
常见Linux日志主要存放于/var/log/目录下;
Windows事件日志默认存放于C:\Windows\System32\winevt\Logs\;
一般网站我们只接负载的web日志;
多业务交互系统,我们需要接所有web日志;
1.2.2 制造(wen)
比如有些版本的中间件默认是没有web日志的,需要手动配置,有些设备的日志也需要配置。
1.2.3 问(wen)
额,这个当然是问甲方咯......
1.2.4 config(qie)
看配置文件。
1.3 How:如何收集?
1.3.1 rsyslog
Linux主机日志一般情况下以syslog方式发送,Linux syslog依据两个重要的文件:/etc/syslogd守护进程和/etc/rsyslog.conf配置文件。
如果我们配置
*.info @127.0.0.1(日志服务器IP)
即把info级别以上日志发到平台。除了Linux,AIX主机,RHLinux,SUSE 主机都有各自配置方法。
Linux由于版本不同和配置不同,服务器发送的日志并不统一,且通过对/etc/rsyslog.conf进行配置,会产生不同的日志。配置的时候可选择日志类型及日志优先级等。这里不做详述,可参考以下链接。
1.3.2 ftp、scp?、rsync?
ftp的方式目前很少接触,因为不实时。但目前平台大多都支持通过SSH账号密码去定时取数据。
1.3.3 filebeat,logstash,Agent
这种方式会一定程度上给服务器带来性能压力。好处在于发送服务器中的日志时可以给日志打标签。
Windows事件日志主要就是通过这种方式发送1.3.4 JDBC、ODBC
目前遇到的两个认证系统需要通过JDBC,ODBC去同步数据。
1.3.5 API
这个不用多说,看情况。
1.4 ALL
收集范围是否完全?数据收集是否冗余?数据收集是否缺失?
这个阶段是我们需要不断重复去思考的问题!比如:交换机镜像流量,是收集核心交换数据,还是接入交换数据,收集的过程中,会不会产生重复的流量。Web日志,是接负载的日志,还是接中间件日志等问题。
1.5 系统调研
在数据收集过程中,对于what,where,how,all的问题,还是需要我们更细致的去了解业务系统。
包括
1.系统资产:IP分布,域名,服务器,设备等资产信息;
2.系统功能:承载业务,使用对象,业务交互流程;
3.系统架构:系统规模,系统应用架构,系统网络架构;
4.系统组件:软件,应用组件,开发语言,数据库。
二、数据治理
数据收集上之后,属于原始数据,对于小型数据平台,可能直接就存储于ES了。对于大型数据分析平台而言,日志都是发送到采集器上,由采集器对日志进行初步处理后,再将处理过的日志发到数据平台。数据治理部分的工作,就需要去考虑如何处理这些数据,也就是洗菜的工作。数据的洗菜部分,我简单总结了一下,包括:
1.数据的冗余
2.数据的挑选
3.数据的质量
4.数据的分类
5.数据的含义
6.数据的变量
7.数据的可用性
8.数据的完整性
2.1 数据的冗余
数据收集的时候,我们提到过冗余的问题,那时关心的是收集了重复的数据,在数据治理过程中对于已收集重复的数据进行处理。比如web日志如果负载和中间件的日志全接,且接了多个系统的web日志,假若我们要了解某个IP大量访问404的情况,一定会产生误报和不准确。
2.2 数据的挑选
数据的挑选,挑选出可用的日志,挑选出重要的日志,挑选出日志中重要的字段。比如服务器登录成功会有以下几类左右的日志,如下:
1. Ape 26 09:52:03 centos-linux sshd[14613]: Accepted password for root from 10.211.55.2 port 25048 ssh2 (/vat/log/secure)
2. Apr 26 03:13:24 centos-linux sshd[2711]: Accepted publickey for root from 10.211.55.2 port 54392 ssh2: RSA 97:9e:ec:0b:d8:65:7b:49:99:09:19:0f:81:1a:4c:00 (/vat/log/secure)
3. Apr 26 03:13:24 centos-linux sshd[2711]: pam_unix(sshd:session): session opened for user root by (uid=0) (/vat/log/secure)
4. Apr 26 03:14:48 centos-linux su: pam_unix(su:session): session opened for user admin by root(uid=0) (/vat/log/secure)
5. Apr 26 03:15:11 centos-linux su: pam_unix(su:session): session opened for user root by root(uid=1000) (/vat/log/secure)
6. Apr 26 03:08:59 centos-linux sshd[2396]: Failed password for root from 10.211.55.2 port 54355 ssh2 (/vat/log/secure)
7. \ ssh:nottyroot 10.211.55.2K??Z (/vat/log/btmp)
8. Apr 26 10:50:01 centos-linux systemd: Starting Session 3 of user root. (/vat/log/messages )
9. root pts/1 10.211.55.2 Wed Jan 17 14:36 still logged in (/vat/log/wtmp)
10. type=USER_LOGIN msg=audit(1524691564.652:475): pid=4327 uid=0 auid=0 ses=22 subj=unconfined_u:unconfined_r:unconfined_t:s0-s0:c0.c1023 msg='op=login id=0 exe="/usr/sbin/sshd" hostname=10.211.55.2 addr=10.211.55.2 terminal=/dev/pts/1 res=success’(/vat/log/audit/audit.log)
最常用的就是我们判断登录源IP是否来自堡垒机,是否属于运维网等,是否有root用户的登录等,因此我们需要挑选出合适的日志用来做判断。不然把这些日志都当做登录日志进行范式化,那么规则在生效的时候肯定又会有重复的告警。所以我们挑出合适的日志进行范式化,进行应用。
Apr 26 03:13:24 centos-linux sshd[2711]: Accepted publickey for root from 10.211.55.2 port 54392 ssh2: RSA 97:9e:ec:0b:d8:65:7b:49:99:09:19:0f:81:1a:4c:00 (/vat/log/secure)
同时,登录失败的日志也是如此,一次登录失败,会产生3条不同的登录失败日志,我们当然没必要每类登录失败日志去用。
2.3 数据的质量
数据的质量问题!当收集的数据质量不符合安全分析的标准时,我们就需要返工进行加固,加固后的数据则需重新收集。前面我们提过,web日志中,有的中间件默认不产生日志,需要我们手动去配置,且各web日志加固的方法也不一样,加固需要的参数也不一样,但是,我们在数据分析阶段需要的web日志,却需要所有类型的web日志格式统一,参数统一的。举个例子,jboss7.0以下的web日志默认不产生,配置时,假设我们没有配置UA,或者漏掉了状态码,就不好玩了,或者Nginx有状态码,Tomcat没有状态码这种情况。 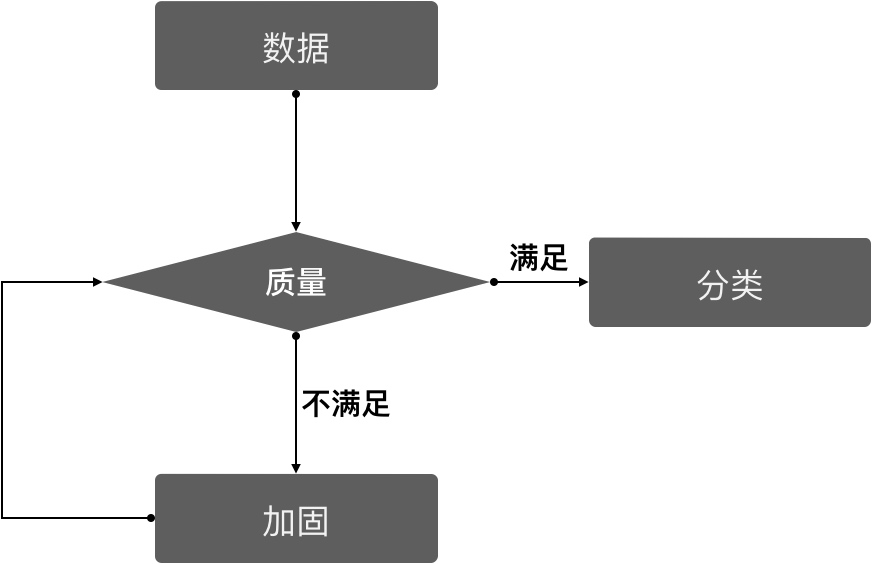
Nginx:61.144.119.65 - - [29/May/2017:22:01:32 +0800] "GET /page/1 HTTP/1.1" 200 6403 "http://www.baidu.com" "Scrapy/1.1.2 (+http://scrapy.org)"
Tomcat:10.211.55.2 - - [11/Mar/2018:22:30:14 +0800] "GET /page/1 HTTP/1.1" 200 11250
IIS:2005-01-0316:44:57 218.17.90.60GET/page/1 -218.17.90.60Mozilla/4.0+(compatible;+MSIE+6.0;+Windows+NT+5.2;+.NET+CLR+1.1.4322)20000
Jboss:10.211.55.2 - - [11/Mar/2018:22:30:14 +0800] "GET /page/1HTTP/1.1" 200 11250
有关web日志的加固,可以参考以下链接:
同样,Windows系统默认不会记录重要的事件日志,如进程和命令行日志、PowerShell日志和Windows驱动程序框架日志。监控的方法很多,以下是sysmon的使用。
https://docs.microsoft.com/en-us/sysinternals/downloads/sysmon
2.4 数据的分类
这个容易,将收集上来的各类日志进行分类,说白了,就是明明白白的了解,都收了哪些种类的日志上来。
数据的分类和数据收集过程中进行联动,会产生很好的效果。比如,在服务器上以syslog方式发日志到平台,在设备上以syslog方式发日志到平台,对于平台而言,它收集到的是一锅粥的日志,啥都有,没有分类,过滤。了解过的同学肯定会说,这是范式化的问题啊,那么问题来了,如果我们事先给日志已经分好类,那么在制造日志的时候,或发出日志的时候打上标签,比如在第一个字段,比如日志的格式等地方,这样就解决了范式化问题的第一个难点:认出日志。
2.5 数据的含义
这条日志说了个啥?这个字段会有什么样的取值?其实这也是数据分析的基础问题,日志的翻译!比如web日志,在做数据安全分析前,至少我们需要知道每个字段的含义是什么。比如安全设备日志,每个字段是什么含义。大家可以尝试翻译以下服务器日志,每个字段是什么含义。
audit日志
type=USER_CMD msg=audit(1520403540.680:98): pid=2517 uid=1000 auid=1000 ses=1 subj=unconfined_u:unconfined_r:unconfined_t:s0-s0:c0.c1023 msg='cwd="/home/admin" cmd=73797374656D63746C2072657374617274206D6172696164622E73657276696365 terminal=pts/0 res=failed’
type=USER_LOGIN msg=audit(1520961520.820:1163): pid=21186 uid=0 auid=0 ses=83 subj=unconfined_u:unconfined_r:unconfined_t:s0-s0:c0.c1023 msg='op=login id=0 exe="/usr/sbin/sshd" hostname=10.211.55.2 addr=10.211.55.2 terminal=/dev/pts/1 res=success'
Cron日志
/USR/SBIN/CRON[21091]: (root) CMD (/usr/bin/shoot -f /tmp/AWM.txt &>/dev/null; mv /tmp/AWM.txt /tmp/M416.txt.old)
新建用户日志
Mar 16 23:07:08 centos-linux useradd[7515]: new user: name=admin, UID=1000, GID=1000, home=/home/admin, shell=/bin/bash
2.6 数据的变量
在数据翻译的过程中,我们是要对一类日志进行翻译,因此对于这一类日志,某个字段的变化取值就是需要我们关系的。比如web日志中,method的取值:GET,POST,PUT,HEAD,DELETE,MOVE,COPY......状态码的取值:1xx,2xx,3xx,4xx,5xx请求大小,时间,url,UA,refer这些信息都是我们关心的。数据库日志,数据库审计日志,系统日志等每类日志的字段变量取值。
61.144.119.65 - - [29/May/2017:22:01:32 +0800] "GET /page/1 HTTP/1.1" 200 6403 "http://www.baidu.com" "Scrapy/1.1.2 (+http://scrapy.org)"
2.7 数据的可用性
其实2.1-2.6,我们都在从技术层面去处理日志,但在实际情况中,总会出些问题,导致数据会突然的中断发生。
1.数据的一致性比如IP的区域确认,端口的服务对应等情况。
2.数据的精确性web日志的源IP均为F5的IP。
3.数据的完整性数据缺失,字段缺失,日志发送中出错缺失,不适当的配置缺失等。
4.数据的时效性服务器的时间有问题的时候,发到平台的原始数据里的时间也是不对的,比如我在nginx日志发现某IP发起SQL注入后,我想在服务器中查看bash日志,结果服务器的时间不准确,导致数据内的时间在两年前,当然人肯定是看得出来,但是规则呢,机器学习呢,他们认的不就是这个时间。有时候,我们用发到平台的时间做判断标准,但这个过程中,发的时间,延迟等问题,都会导致我们判断规则失效。
5.数据的实体统一性比如最可恨的就是,各家厂商的APT设备,有的厂商在日志中是请求内容或事件内容,有的厂商tm的是ASSIC码。对于日志中是ASSIC的厂商,我真的想吐槽,你们的研发真的懒。
三、数据分析
买菜、洗菜的目的就是为了炒菜,大数据安全分析平台的核心价值体系就在于数据分析,合理的数据分析会给企业带来巨大的价值。在这个模块中,我自己也是在摸索中前行,在絮叨这篇时,我希望从这么几方面絮叨。
3.1 安全架构
自适应架构高大上的地方就不谈了,预测、防护、检测、响应。其实在做好各方面防护的基础上,客户最需要的是检测及响应能力,单方面的检测和响应很普遍,WAF有报警,主机IDS有报警,PC终端有报警,APT有报警,但是关联起来的能力......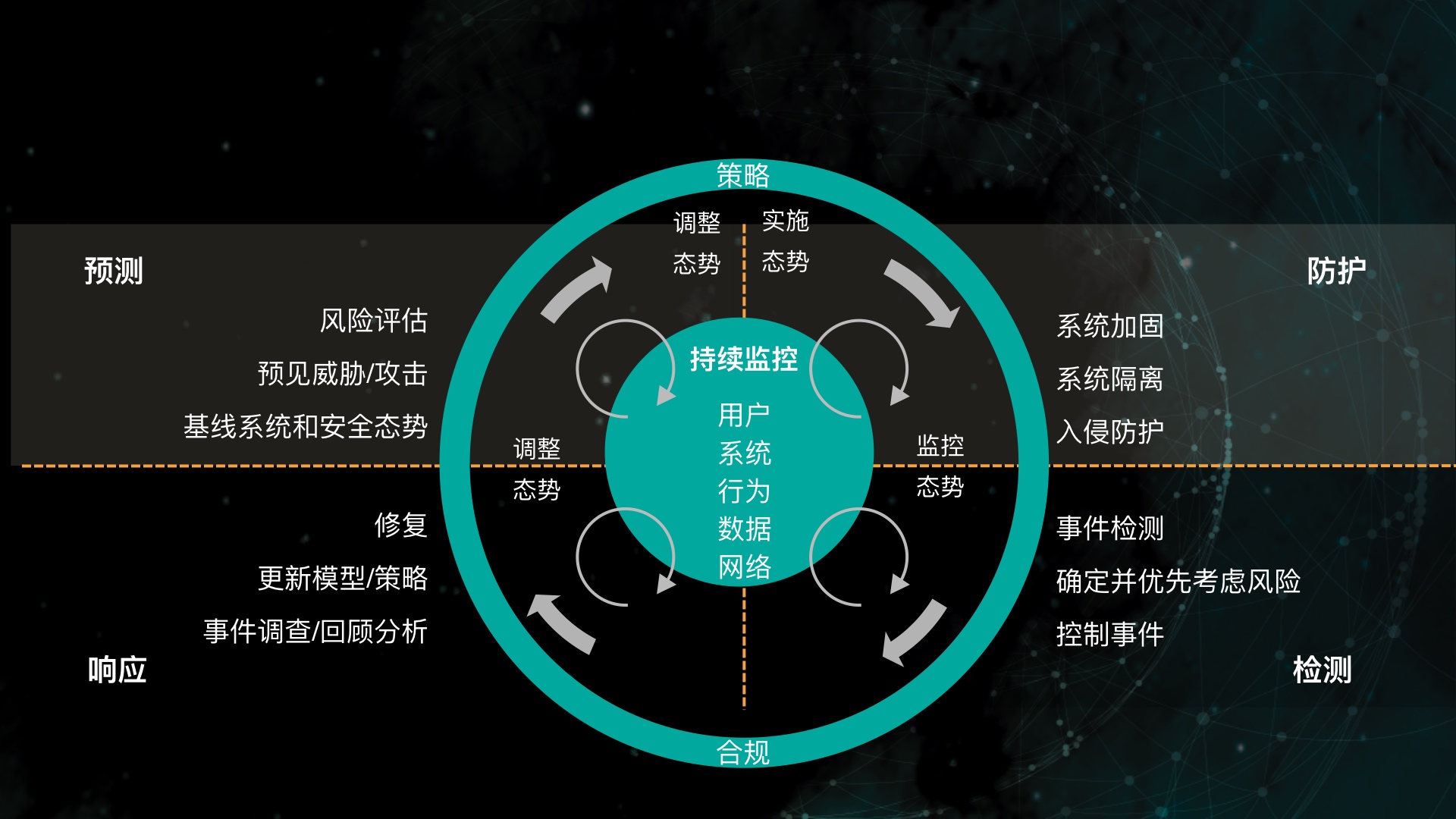
3.2 态势感知
道哥语录:
全⾯、快速、准确的感知过去、现在、未来的安全威胁,帮助客户第一次「看清楚」⾃己和这个世界。
让数据在线,基于数据分析,多个事件源之间的关联,连接不同的数据,从而创造新的价值,试图反馈全局的情况,试图还原事件过程
个人也是深受启发,在应急时,在渗透时,在安全加固时,不管是web日志,流量日志,主机日志,都多多少少会留下蛛丝马迹。如果我们利用这些日志,设置下各种检测锚点,是不是就可以快速的检测出哪里出现了异常。
3.3 应用场景
应用场景简单列举例。
1.业务安全风险注册,登录,交易,查看报表,文件下载,数据传输,后台管理等等偏业务的安全风险。
2.主机安全风险异常登录,敏感操作,异常进程/服务,异常cron任务,启动项异常,权限异常,敏感文件等等安全风险。
3.内网安全风险主机外联,异常DNS解析,异常NTP解析,钓鱼端口访问,敏感端口范围,内网扫描探测等等安全风险。
4.外网攻击风险web攻击类,当然凭web日志分析web攻击比较粗糙,比较WAF分析的是request请求,而web日志没有request的所有信息,优势在于统计分析和机器学习。
3.4 数据安全分析理论
《数据驱动安全》这本书的开篇有如下一张图,说是数据安全分析中的技能图。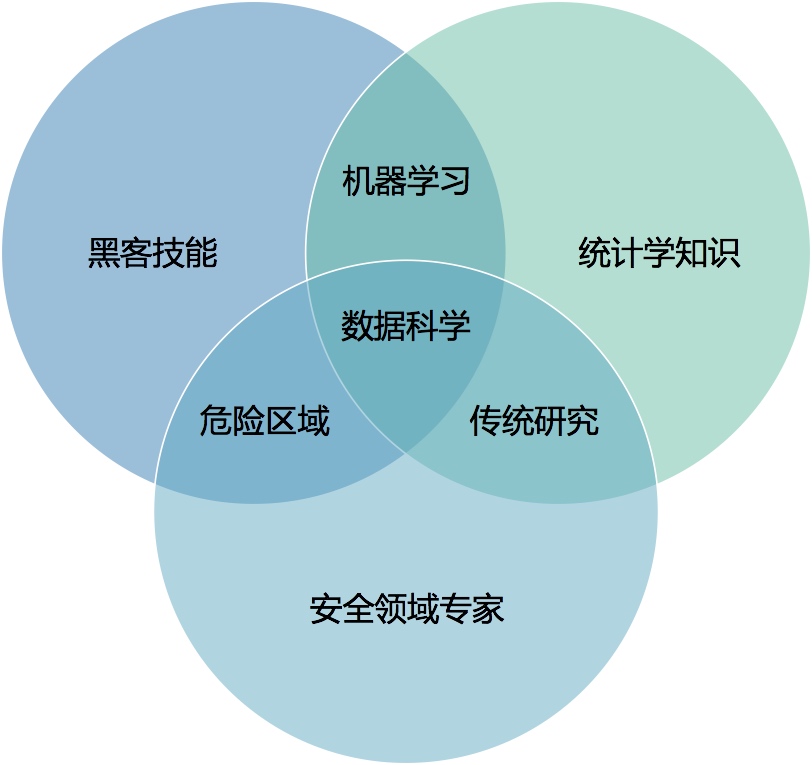
3.4.1 黑客技能
并不是每个人都是大黑客的,甲方企业也不需要大黑客。这里我理解的黑客技能为安全攻防角度的了解,未知攻焉知防,一直都在说的话题。我理解为发生安全问题时,攻击者的思维和防护者的思维的对弈,这里的黑客技能就是防护者的思维。举个例子,一个Struts2系统被攻击,web日志和WAF会记录,突破web层面时,黑客会在服务器上做什么?执行命令,访问敏感文件,远程下载木马,安装黑客工具等操作,假设在内网漫游时,内网探测,内网扫描,后台登录等行为。综上理想状态下的行为,都有相应的日志记录,我们是否可以埋下检测锚点呢?
这里就要提到几个理论知识:
3.4.2 安全领域专家
这里我理解为大安全。如等保,分保,27001,PCI等大方面的了解,有助于我们在管理方面和技术方面合理的设置检测。
3.4.3 统计学知识
A. WAF能检测request请求的所有信息,你web日志只有其中几个信息,靠URL中的正则就判断攻击,太草率了吧。
B. 额,我们可以做统计,做溯源啊。
A. 也是哦,统计联动WAF,不就好很多了。
当然这只是一个小case,企业内部需要做统计的数据点很多,比如DNS,NTP,账户,交易等太多太多。
3.4.4 机器学习
这个技术能力达不到,接触的很少,只从大佬口中了解过一些学习判断算法,区域分布,统计分析,历史行为啊,给安全先行大佬们递茶。
http://www.freebuf.com/column/173876.html
3.4.5 其他
其他的从字面意思我也没搞懂......
3.5 数据安全分析方法实践
3.5.1 规则分析
单一规则与关联规则单一规则就是利用单一日志的某一字段判断安全问题,或控制某一个字段变的情况下计数等情况,就是利用单一日志做的检测规则。关联规则就是将多个数据源进行一定场景下的关联,比如ftp爆破了,成功后大量下载文件了。这些不便细说,可以私下细聊。
3.5.2 威胁情报
这个不多说,内网DNS请求的域名都发送到威胁情报了,然后根据返回进行判断。
3.5.3 统计学方法
统计404的IP,统计404的URL,统计攻击者的历史行为......
3.6.4 用户行为分析
3.6.5 机器学习
四、总结
其实以上都是在大数据安全平台项目中做安全数据分析时的项目经验的简单总结,对于底层的平台架构了解的还是比较少,重点还是在数据分析方面,这过程中还是有很多坑。希望能给其他同学一些思想帮助,也希望和其他同学分享更多更细致的安全分析场景,希望圈内大佬给出建议。
*本文作者:倚剑醉酒笑红尘,属于FreeBuf原创奖励计划,未经许可禁止转载
已在FreeBuf发表 0 篇文章
- 0 文章数
- 0 关注者